-
-
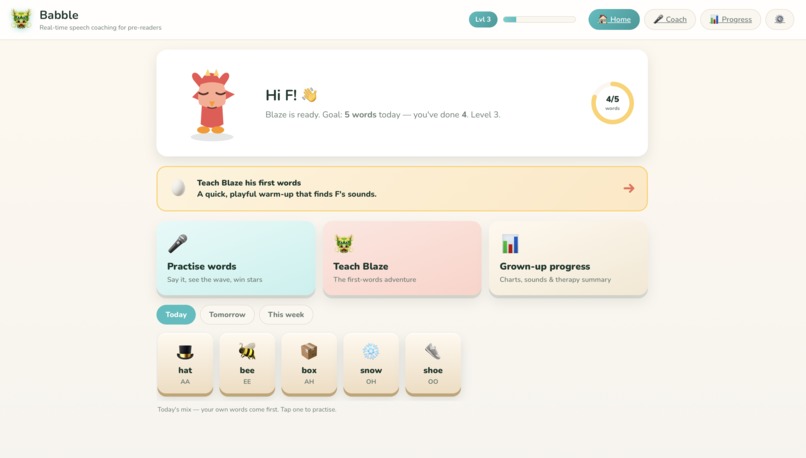
Dashboard
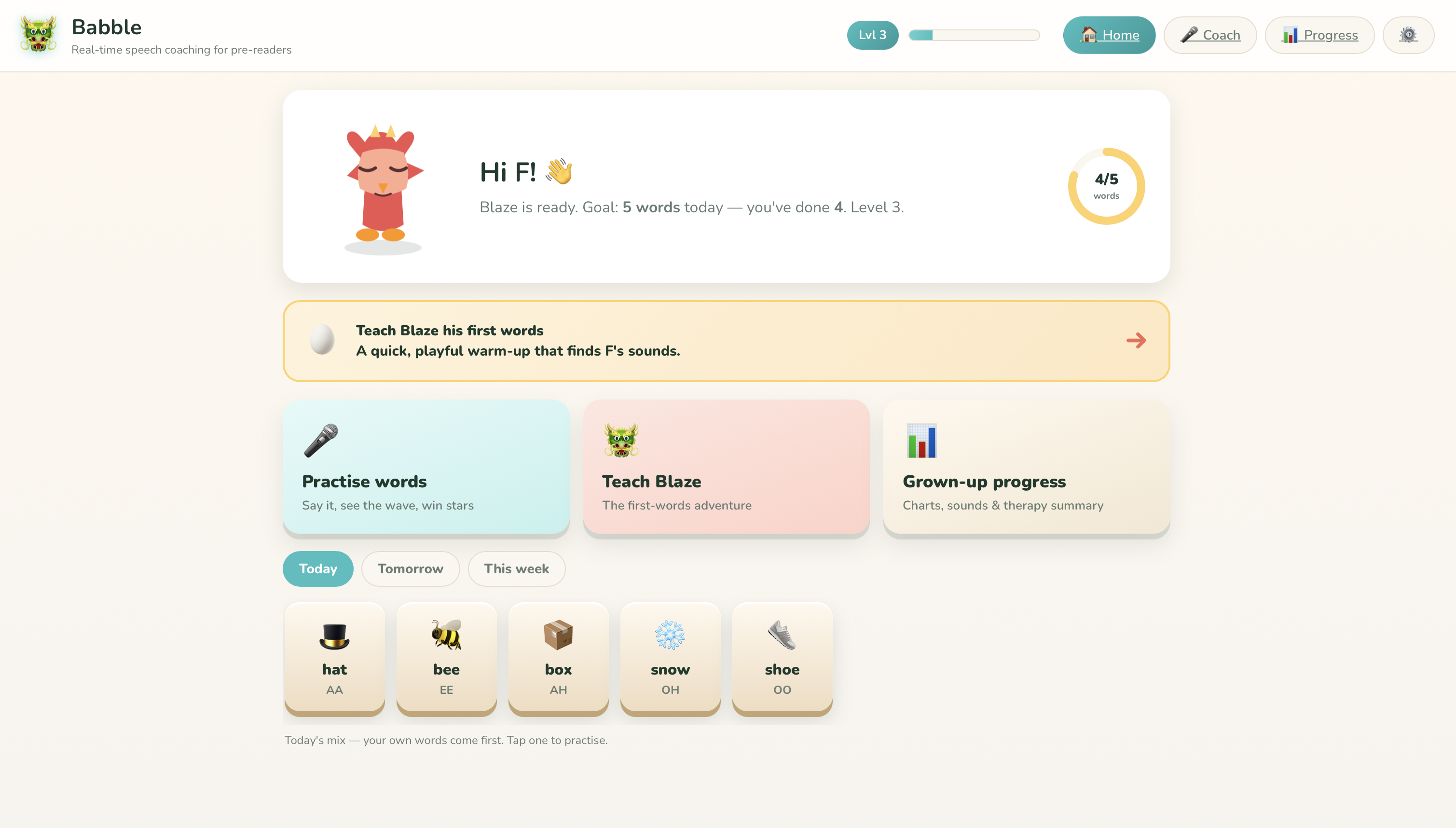
🐉 Babble — real-time speech coaching for pre-readers
Live demo: https://babble-help.vercel.app
Babble teaches a kid to talk by letting them teach a baby dragon to talk. Say a word, and Babble listens, scores it, and turns every attempt into XP — while quietly building an honest early screen of which speech sounds are solid and which need practice.
Inspiration
About 1 in 12 U.S. children has a speech, language, voice, or swallowing disorder (NIDCD), but speech-language pathologists (SLPs) are scarce, expensive, and booked out for months. The therapy itself is mostly high-frequency, low-stakes practice — say the word, get feedback, repeat — which is exactly what software is good at, and exactly what a 4-year-old will only do if it feels like a game. We wanted something a parent could open on any device, with no login and no cost, that gives a child instant feedback and gives a grown-up something real to bring to a therapist.
What it does
- A child speaks a word; Babble transcribes it, scores the attempt 0–100, and rewards XP and levels — think Duolingo for pronunciation.
- "Teach Blaze his first words" — a phoneme screener disguised as teaching a just-hatched dragon to talk. It covers the major English sounds and generates an honest, parent-facing report (which sounds are clear vs. need practice) with mouth-position cues — explicitly labeled as a playful screener, not a clinical diagnosis.
- A live progress dashboard whose chart auto-zooms from hours → days → months as practice accumulates, plus an SLP-ready summary you can export as CSV.
- A 40-word library with a daily Today / Tomorrow / This-week rotation, an "add your own word" feature, and dictionary look-ups (real phonetics, a kid-friendly definition, tap-to-hear audio) — with a hidden "deep cut" obscure definition for the curious.
- Installs and runs offline as a PWA, on phone or tablet.
How we built it
Babble is a 100% client-side PWA — no backend, no accounts, all data in localStorage. The stack is Vite + React + TypeScript with plain CSS.
The grader is honest about what it is. The browser's Web Speech API transcribes the spoken word, then a Levenshtein fuzzy match turns it into a score, where an exact word (or accepted homophone) is 100:
$$ \text{score} = 100 \times \left(1 - \frac{\text{lev}(\text{heard},\ \text{target})}{\max(|\text{heard}|,\ |\text{target}|)}\right) $$
We also hand-wrote a small DSP engine (LPC formant estimation + FFT) that powers the live "interference wave" visualization and an offline fallback grader for browsers without speech recognition. It scores a vowel by its distance \(d\) in formant space through a Gaussian reward:
$$ r(d) = e^{-d^2 / 2\sigma^2} $$
The diagnostic infers per-sound results from word-level evidence only (a sound is "clear" if any whole screener word containing it was said correctly), then writes the results back into the child's profile to personalize practice. The dictionary feature uses the free Dictionary API, cached locally so it keeps working offline.
What we learned
- The Web Speech API is shockingly good on kids' voices — but it returns word-level transcripts only, with no per-phoneme confidence. That one fact shaped the whole product: we infer at the level the evidence actually supports instead of inventing numbers.
- A real amount of speech science — formants, the vowel space, why /s/ and /ʃ/ are late-developing sounds — even though most of it ended up powering the visuals rather than the grade.
- Tiny CSS rules have huge consequences: a single
1frvsminmax(0, 1fr)was the difference between a usable phone layout and a broken one.
Challenges we ran into
- Resisting a fake "AI moat." Our first instinct was formant matching with cosine similarity as the grader. It looked great in a demo and was unreliable on real children. We pivoted: Web Speech grades, the DSP became the visualization and the offline fallback — and we deliberately don't claim a metric we don't compute.
- Honesty in the data. Early builds shipped seeded/fake stats. We ripped them out so every point on the dashboard is a real thing the child said, and we label the screener as non-clinical.
- Two consumers, one microphone. Speech recognition and our audio recorder both want the mic, which made the slow-motion replay clips tricky.
- Merging two prototypes — a real speech engine and a polished kid-facing shell — into one coherent product.
- PWA + responsive gotchas: orientation lock, safe-area insets, and the grid-width bug above.
What's next
On-device per-phoneme acoustic scoring, more languages, and a parent/SLP portal for securely sharing the progress reports.
Built With
- canvas
- css
- dsp-(lpc-+-fft)
- free-dictionary-api
- github
- google-fonts
- html
- javascript
- localstorage
- mediarecorder-api
- pwa
- react
- react-router
- recharts
- service-workers
- typescript
- vercel
- vite
- vite-plugin-pwa
- vitest
- web-audio-api
- web-speech-api
- workbox

Log in or sign up for Devpost to join the conversation.