-

Phonics Logo
-
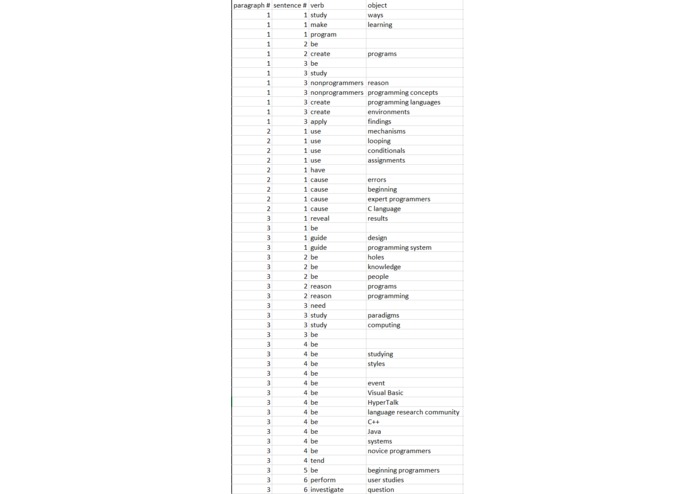
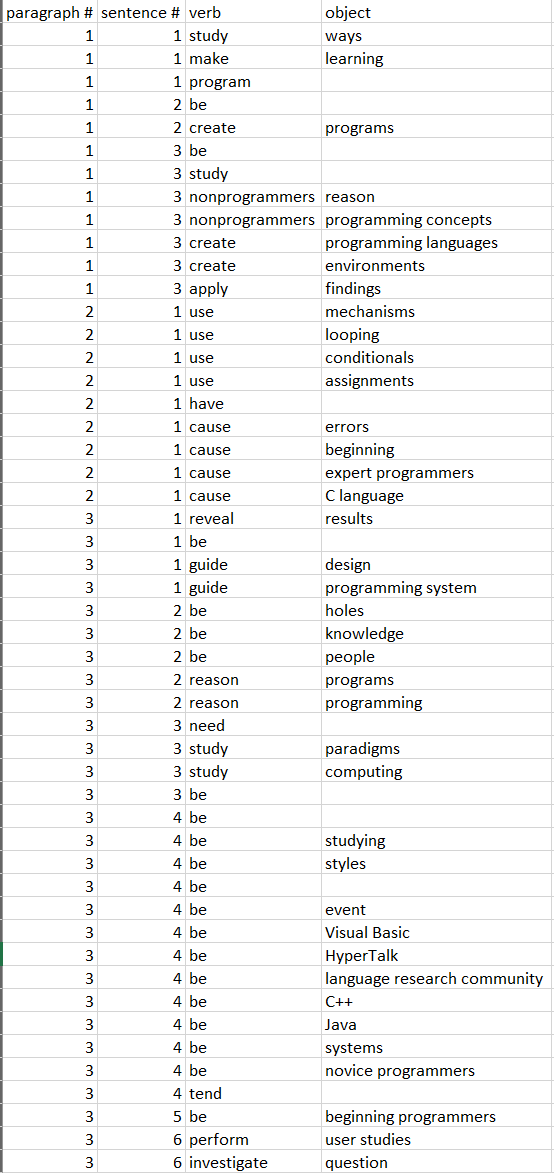
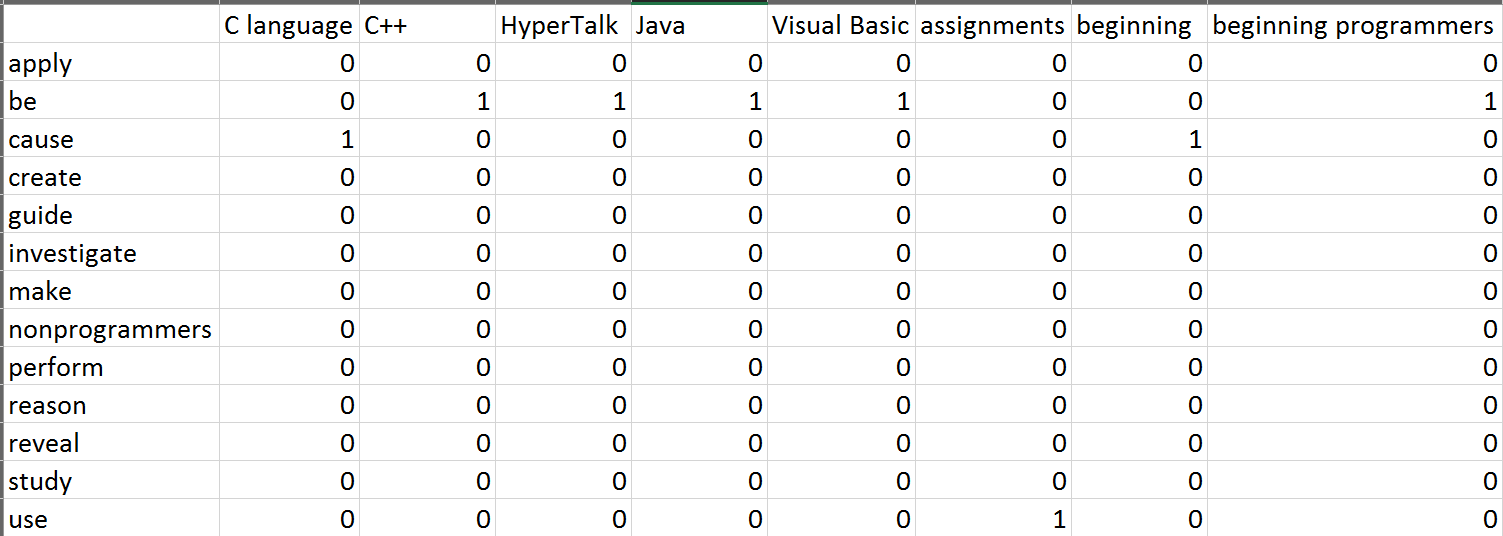
Challenge Part 1: Verb-to-Object Combinations Table
-

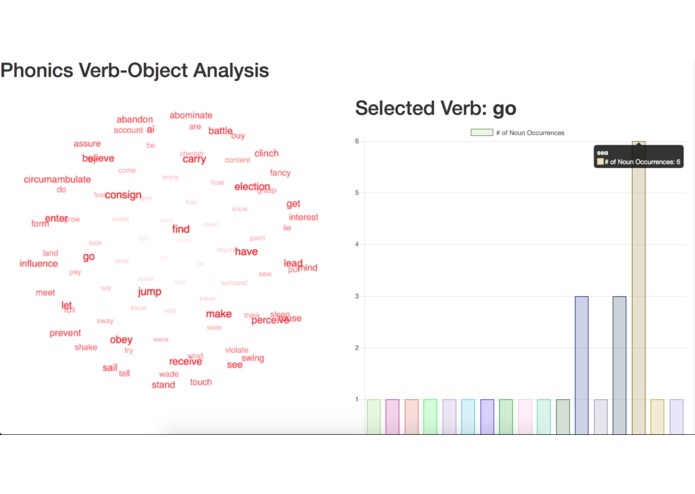
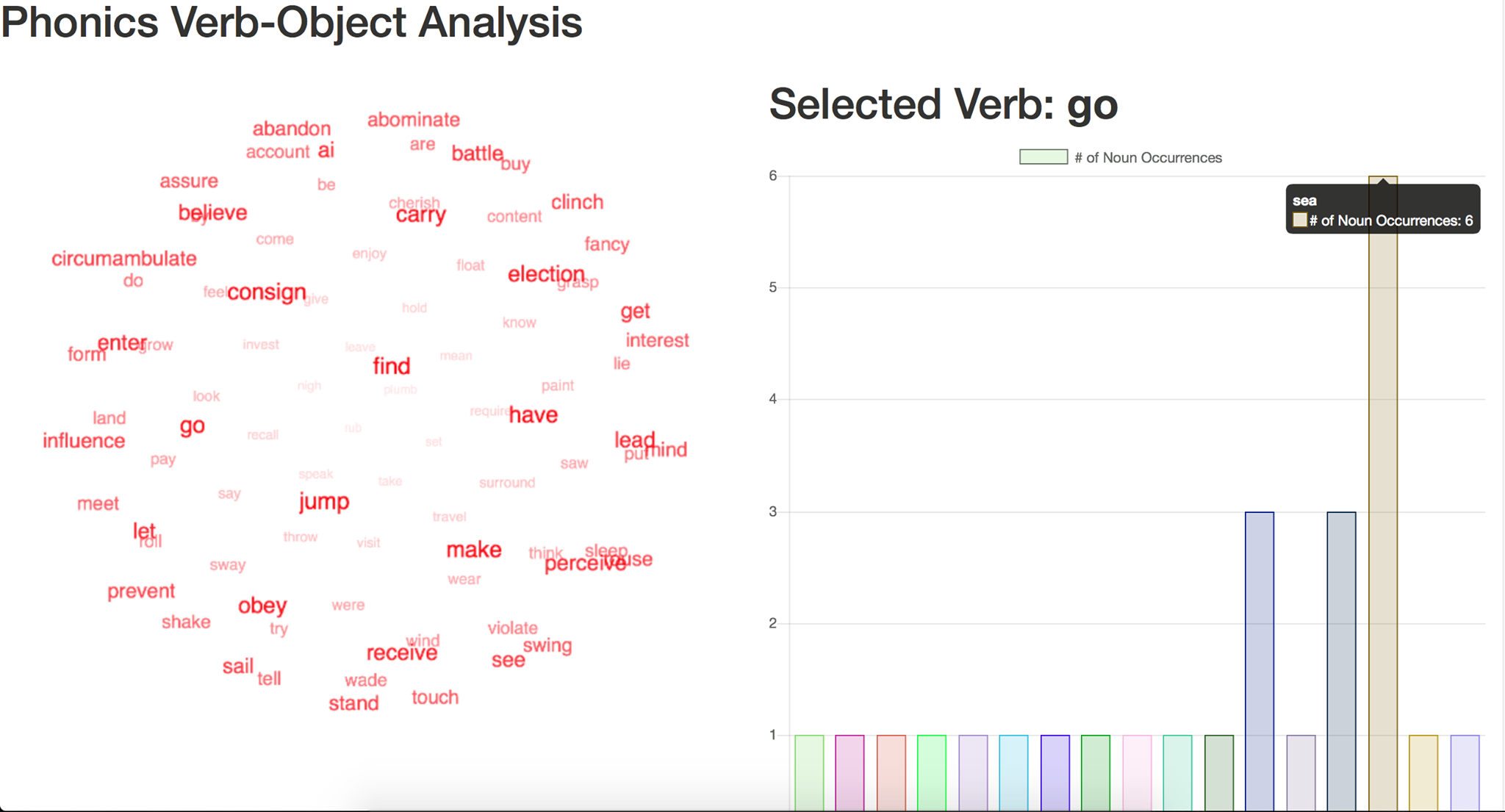
Challenge Part 2: Verb-to-Object Combination Frequency Table (zoomed out)
-

Challenge Part 2: Verb-to-Object Combination Frequency Table (zoomed in)
-
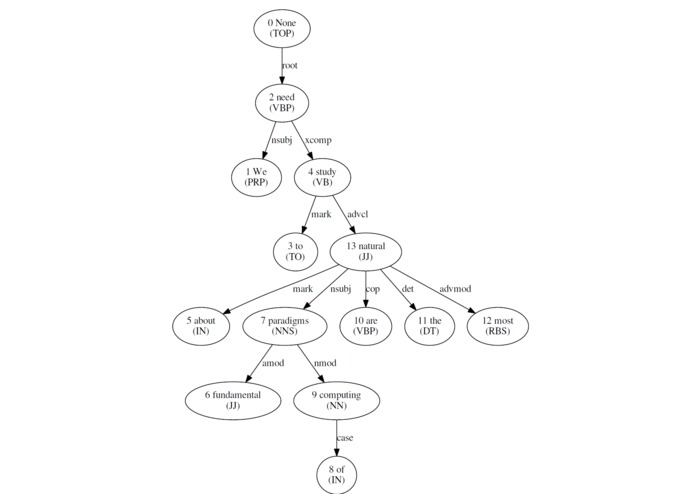
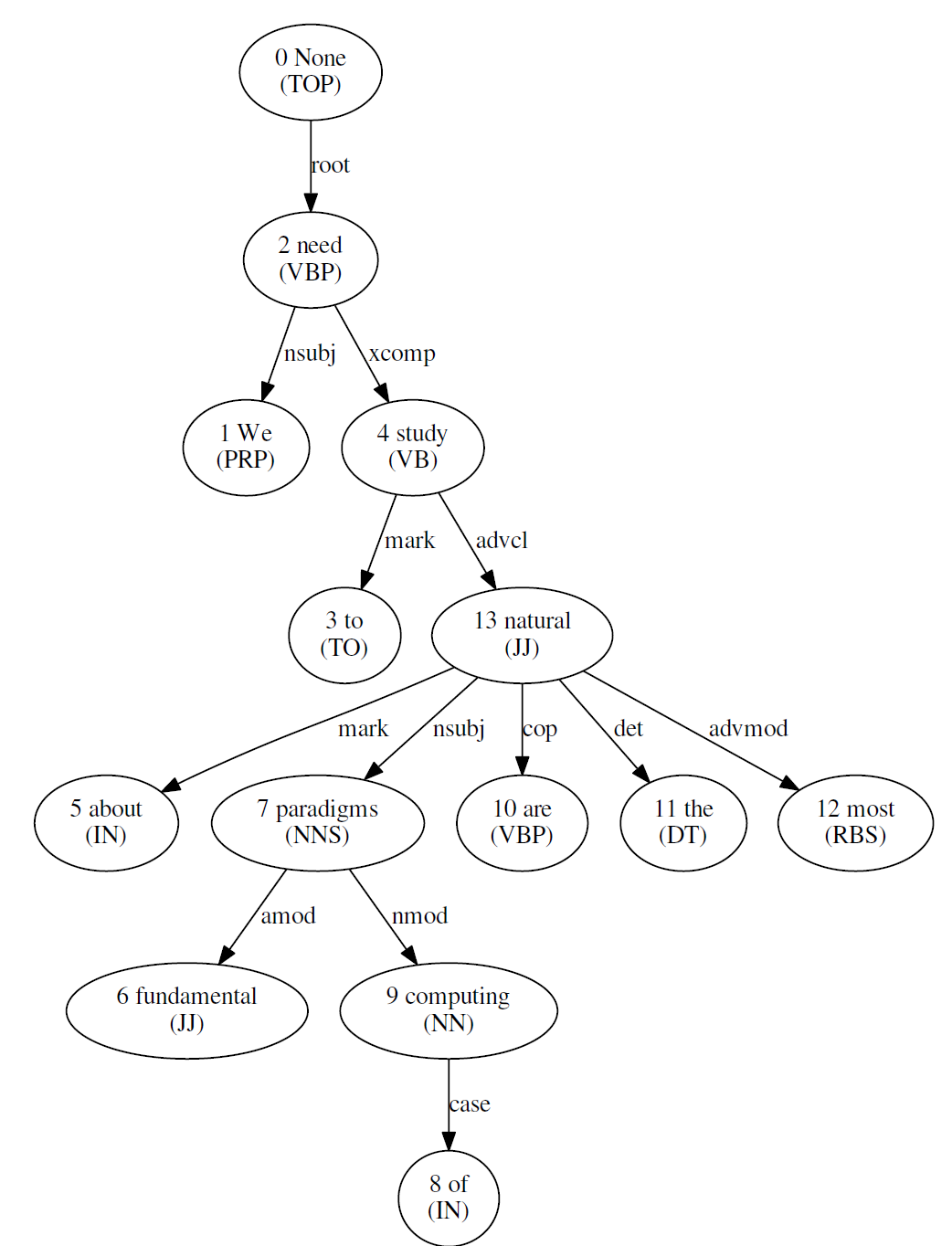
Example Dependency Graph (generated from Challenge Input: "We need to study about fundamental paradigms of computing are the most natural.")
-
Challenge Part 3: Entity Visual/Diagram (Output of First chapter of Moby Dick by Herman Melville)
-

Example computer vision output from Android Phone. It boxes and identifies the objects within the frame.



Question~
What can you do with an apple, a car, or a college degree in computer science?
Background
Humans can easily predict what one can do with these objects-- we have memories of the world around us and conditioned intuition. Computers, lacking our memory and intuition, have a harder time with these predictions. Inspired to learn more about natural language processing (NLP) through the LogApps Challenge, we wanted to bridge this gap by giving our machines a way to predict real-time, real-world interactions based on camera and natural language input.
What is Phonics?
The Phonics flow begins with an Android application that the user uses to take a photo of any real-world scene. The app sends that photo to our Node.js server, which uses the YOLO machine learning framework for object detection to identify objects within the user’s photo. To identify what actions can be done to those objects, the server can parse large text inputs and take in Google Home dictation to predict what action verbs typically act on the objects identified in the input photo. The identification of action verbs and the nouns they act on are identified via Stanford’s CoreNLP natural language processing tools, coded in Python with the Natural Language Toolkit (NLTK).
What can Phonics do?
As a result, we can train our program to predict actions that can be performed on objects with natural language input as dictated through Google Home, or provide our program with a set of sentences to improve its accuracy, for example, by training our program with specific instruction manuals that are directly relevant to the object of interest as seen in the photo taken by our Android app.
TL;DR we made a program that can be trained (verbally through Google Home or text file) to identify action verbs that are linked to specific nouns. These noun objects can be identified in the real world via computer vision through an Android camera.
LogApps Challenge Fulfillment
We also have a web page that displays the three requirements put forth by the LogApps Challenge: our verb-direct object (V-DO) mappings by sentence, matrix displaying the frequency of any V-DO pairing, and visual diagram of this V-DO frequency matrix. We also addressed the extra functionality by being able to use the Google Home to edit and resubmit the example passages to generate new mappings, matrices, and diagrams.
Built With
- android
- google-home
- machine-learning
- neural-network
- nltk
- node.js
- object-detection
- python
- stanford-corenlp





Log in or sign up for Devpost to join the conversation.