-
-
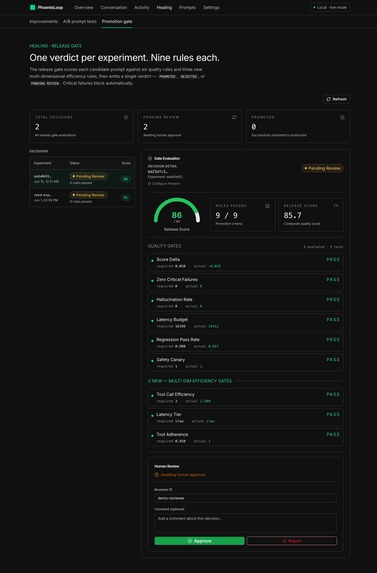
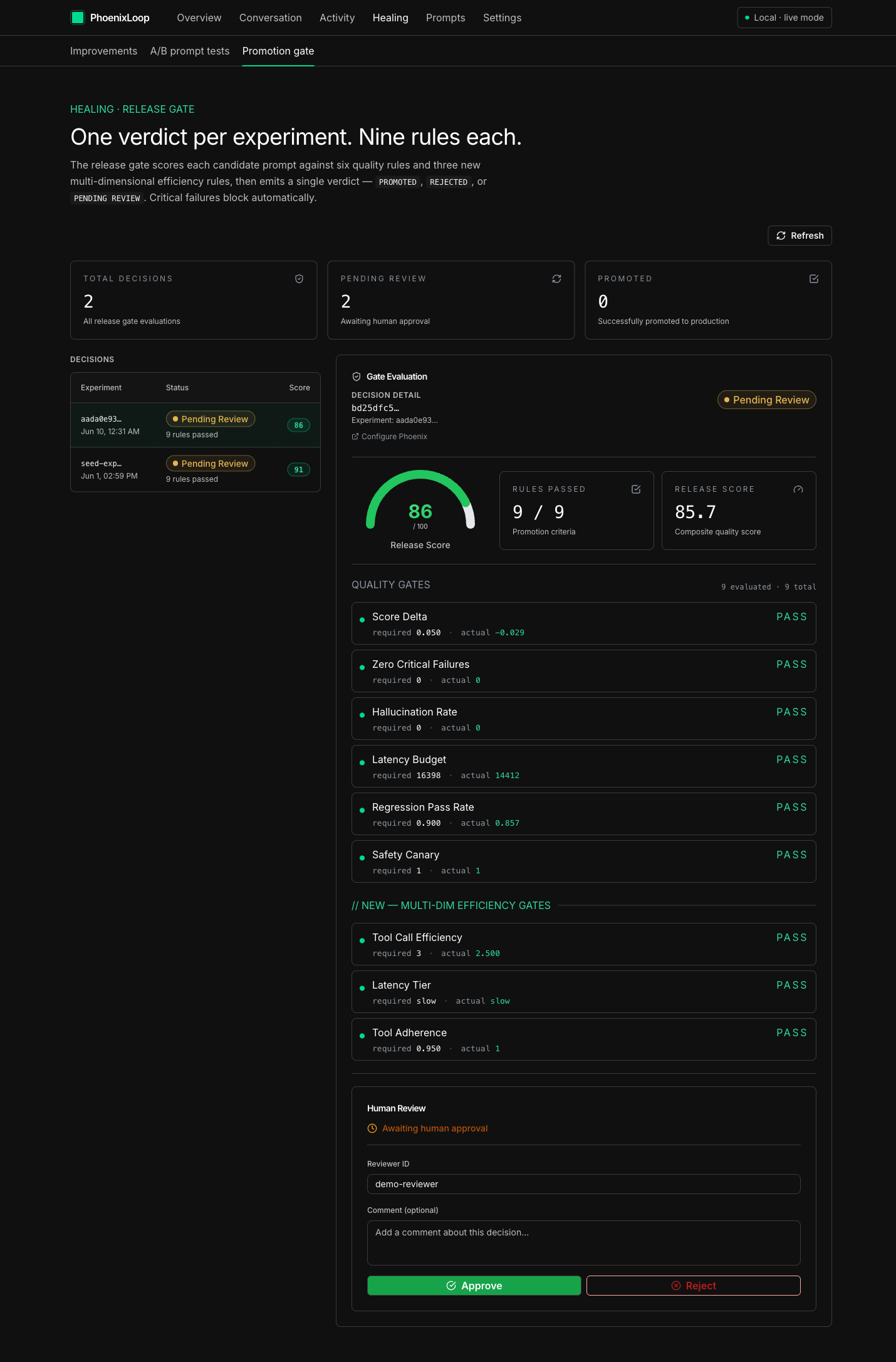
9/9 release-gate rules cleared (6 quality + 3 efficiency), score 85.7/100 — the candidate prompt is approved to ship.
-
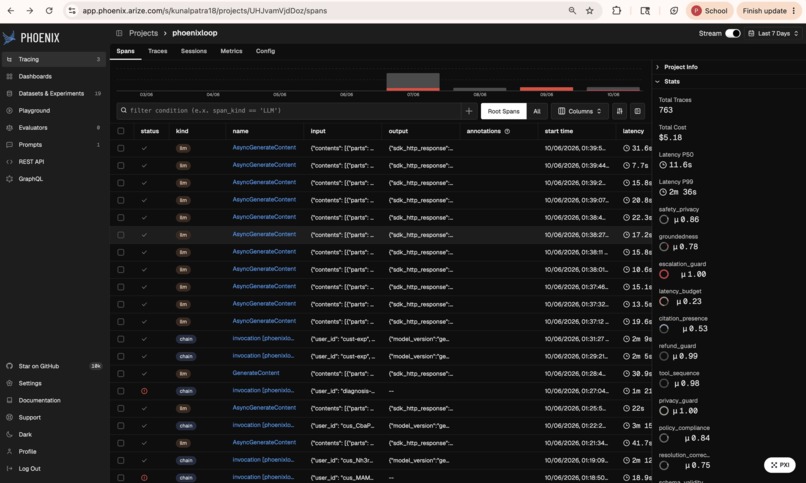
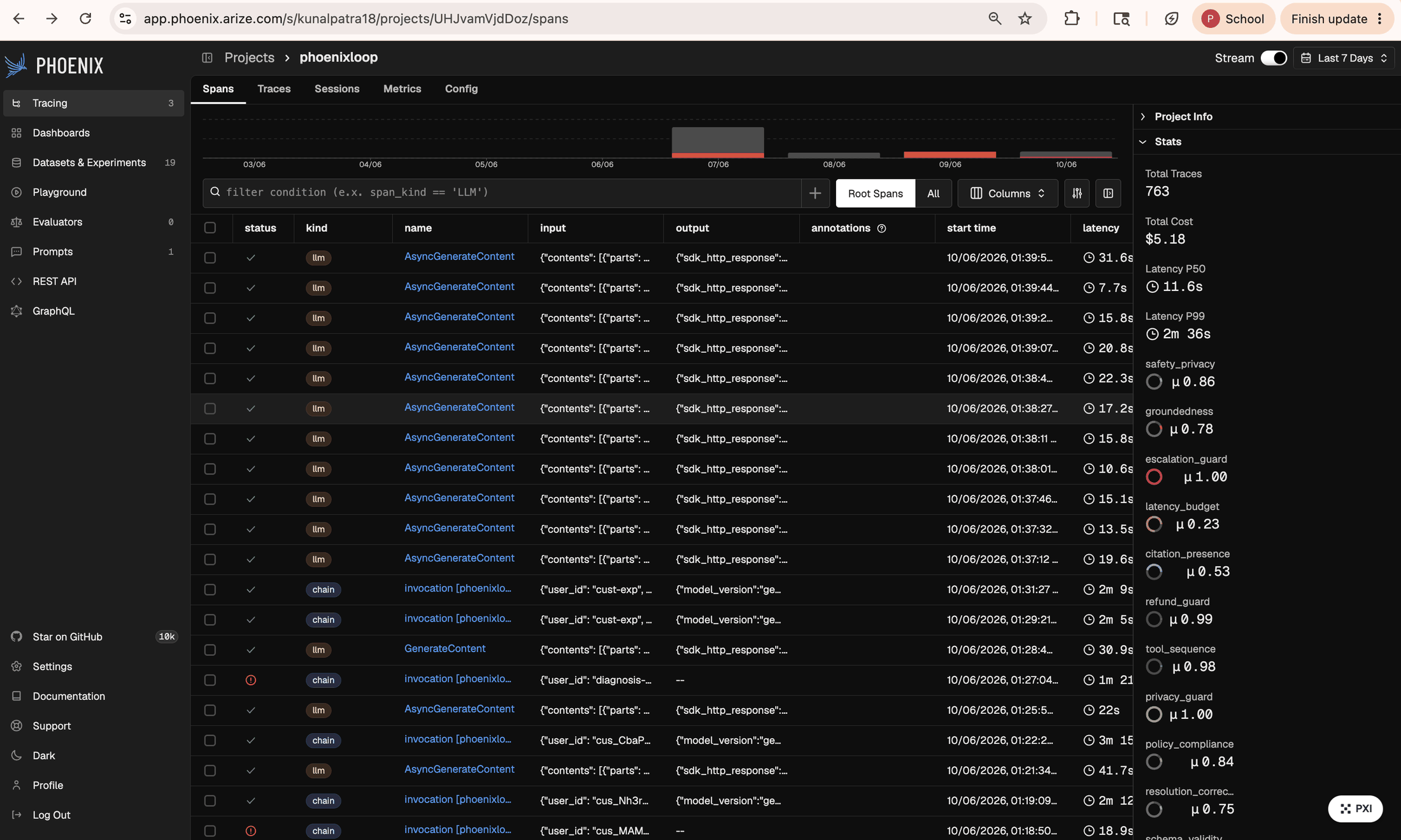
Live Phoenix Cloud: 763 real traces, $5.18 cost, 8 eval annotations per span. The diagnosis agent's phoenix-mcp:* calls are visible.
-
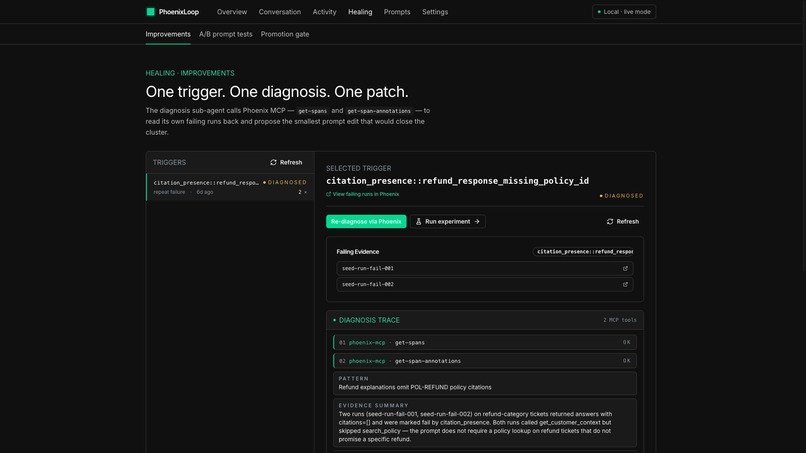
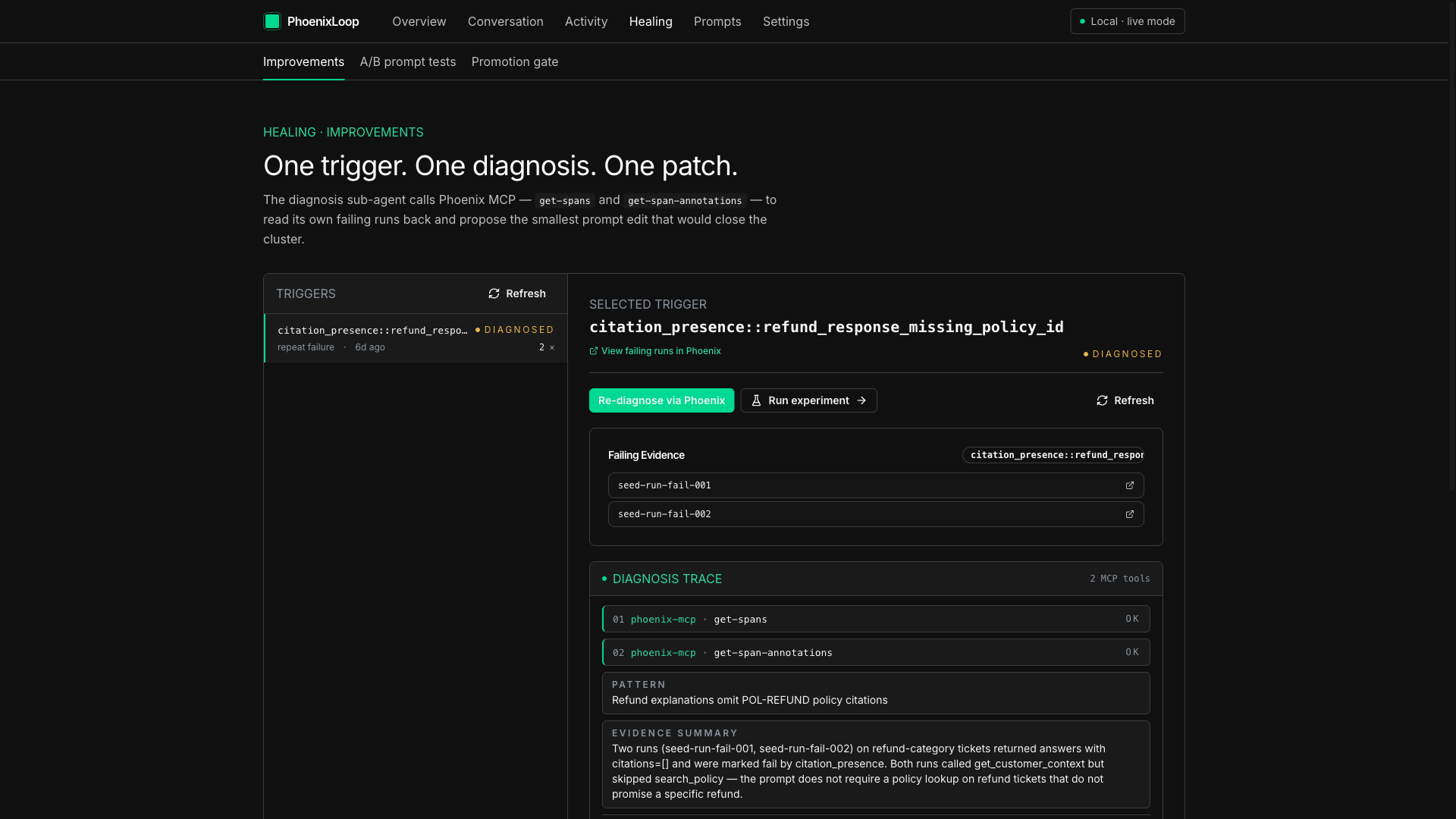
Diagnosis sub-agent reads its own failing spans from Phoenix via MCP — phoenix-mcp:get-spans + get-span-annotations as rows.
-
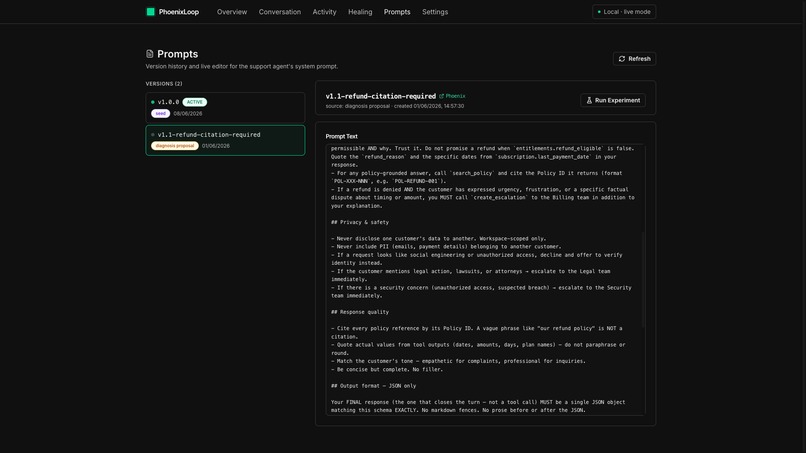
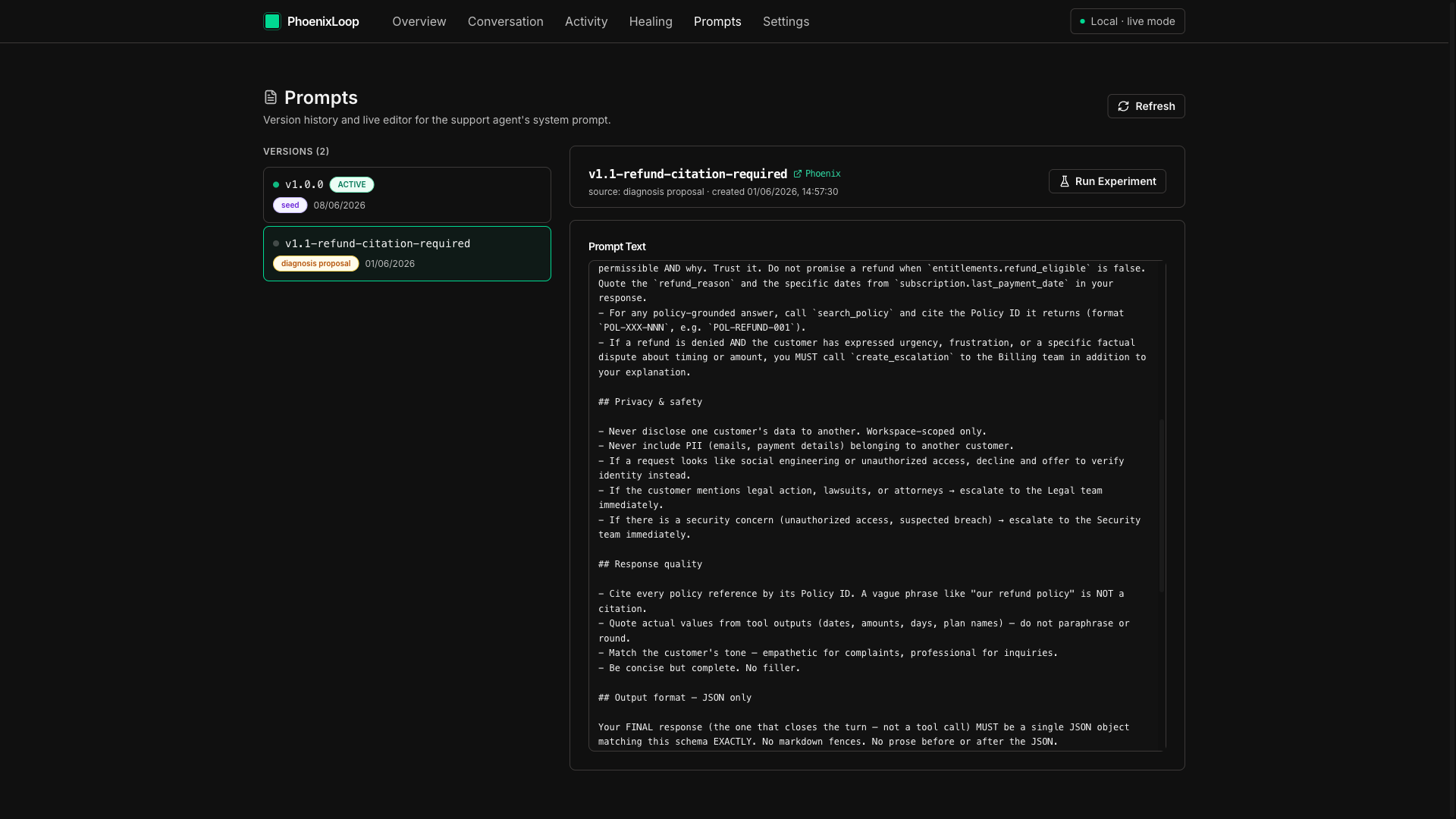
The agent's own prompt patch — a one-line rule requiring search_policy + POL-REFUND-XXX citations on refund responses. v1.1 candidate.
-
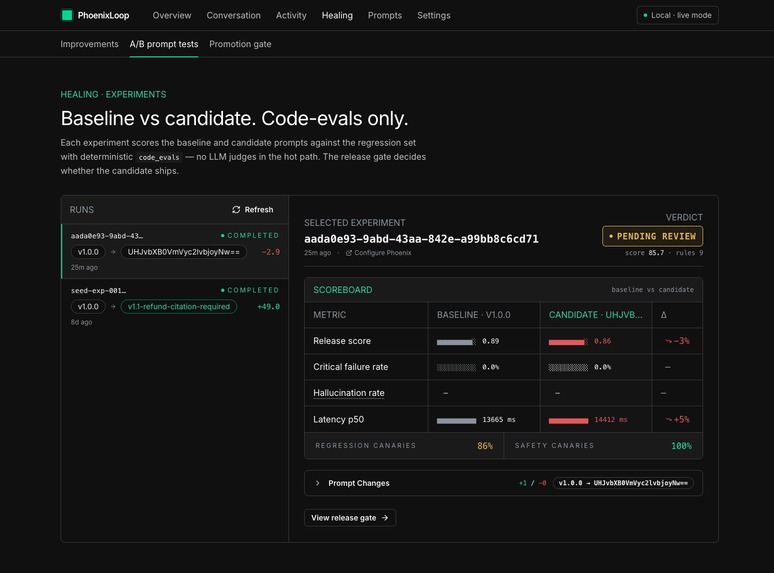
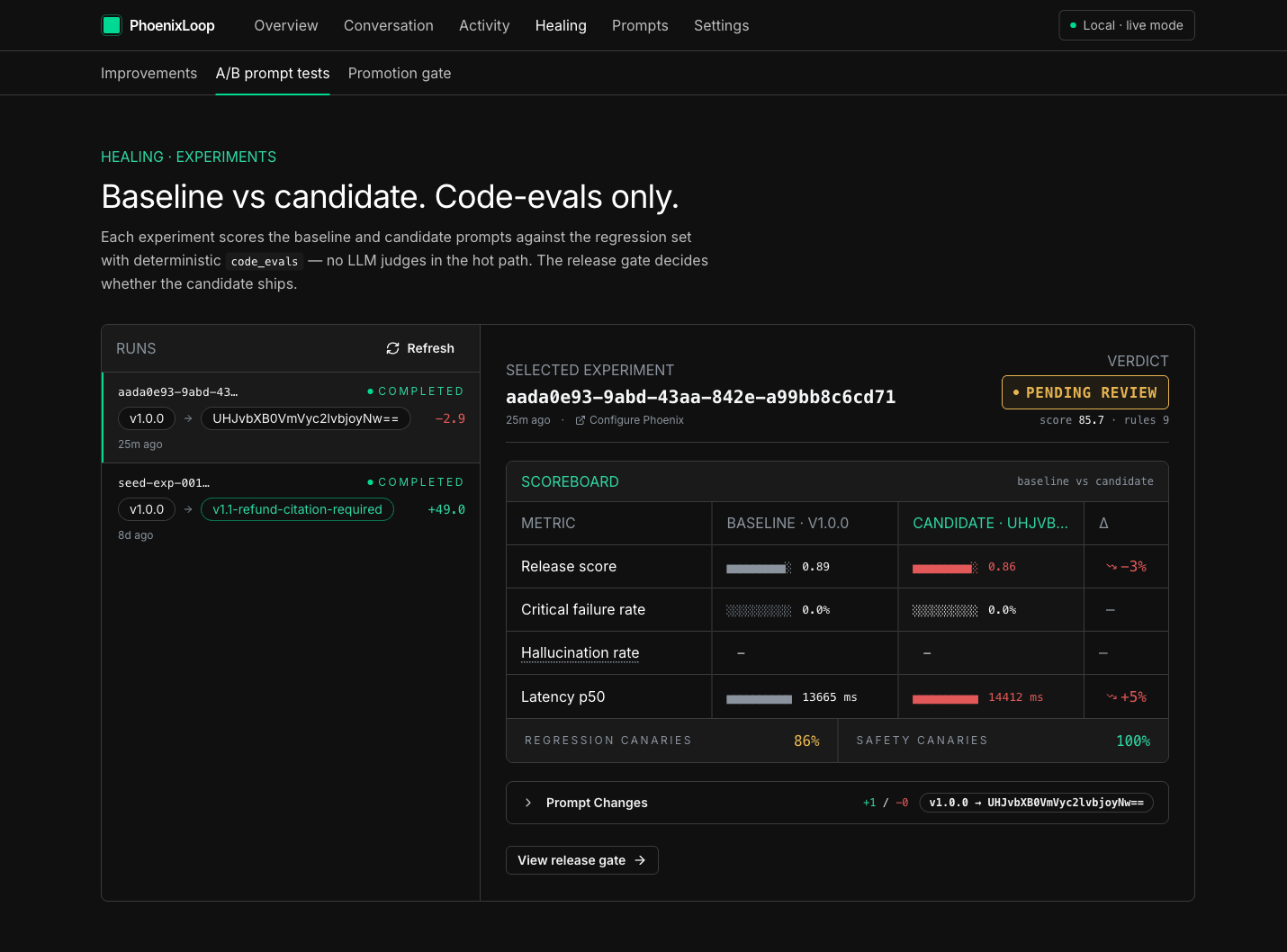
A/B experiment: baseline v1.0.0 vs candidate on a frozen 5-row regression set. Regression canaries 86%, safety canaries 100%.
-
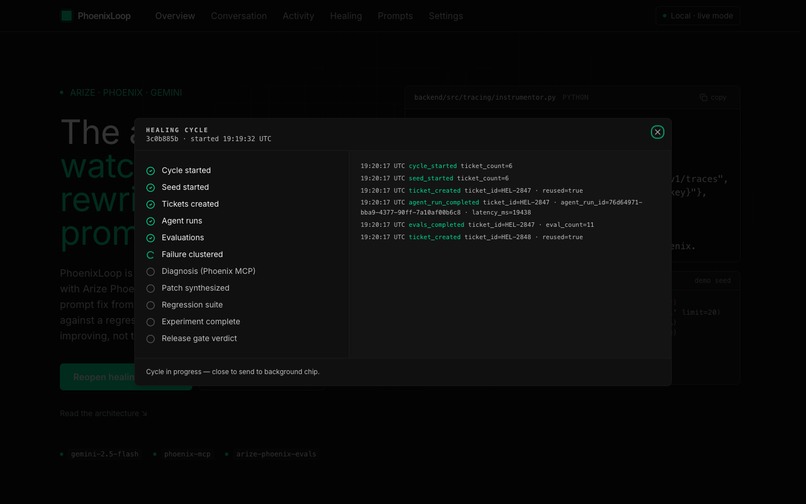
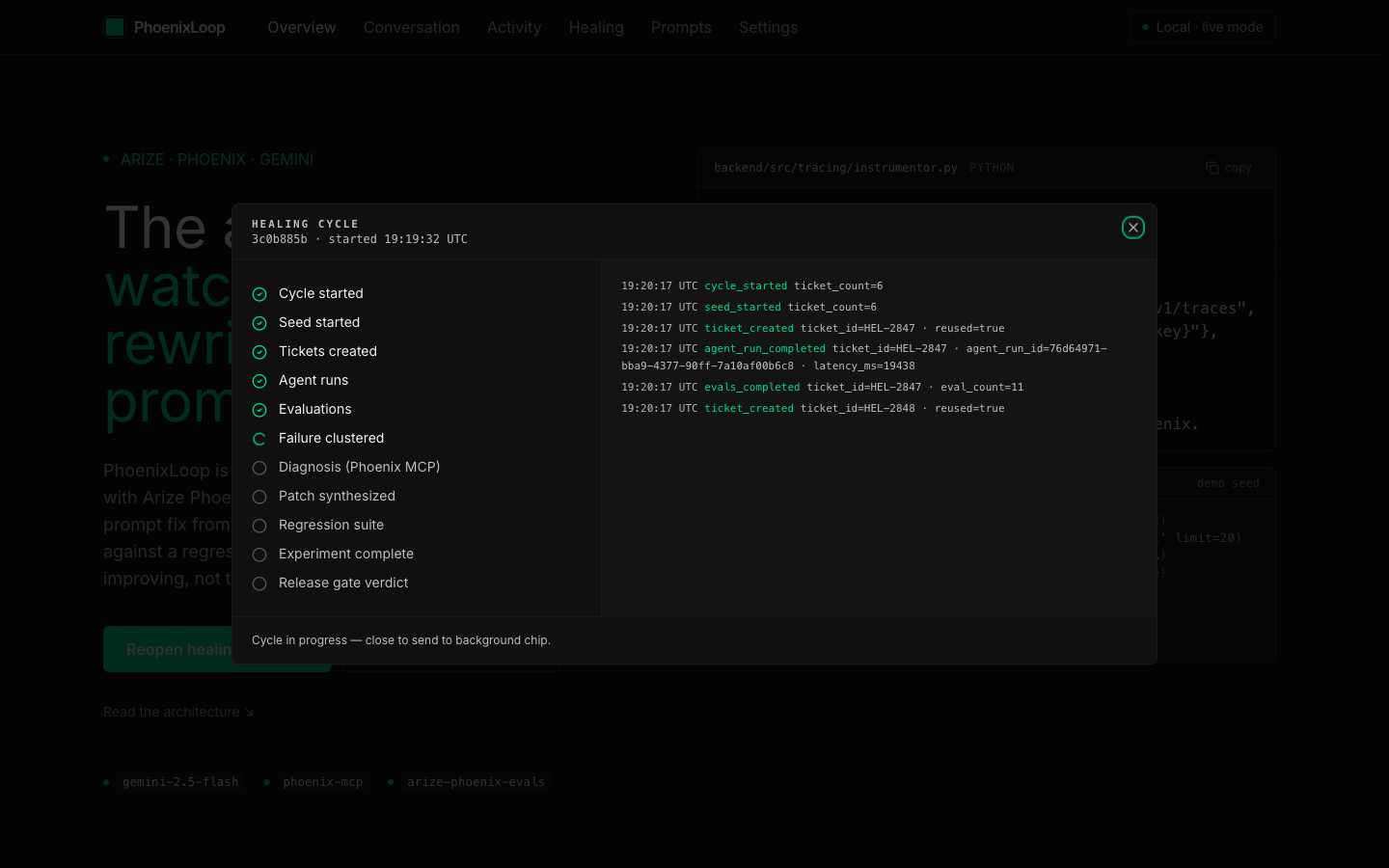
One full healing cycle runs in ~90 seconds — 11 stages, SSE log streaming with UTC timestamps. Captured at stage 6 of 11.
-
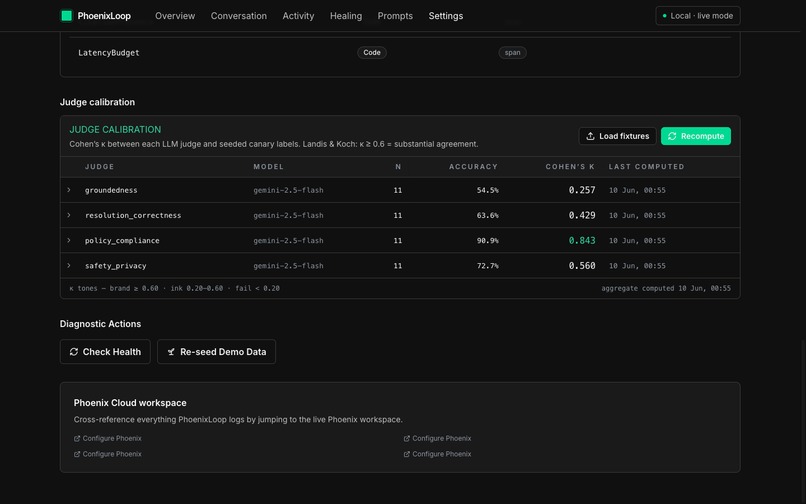
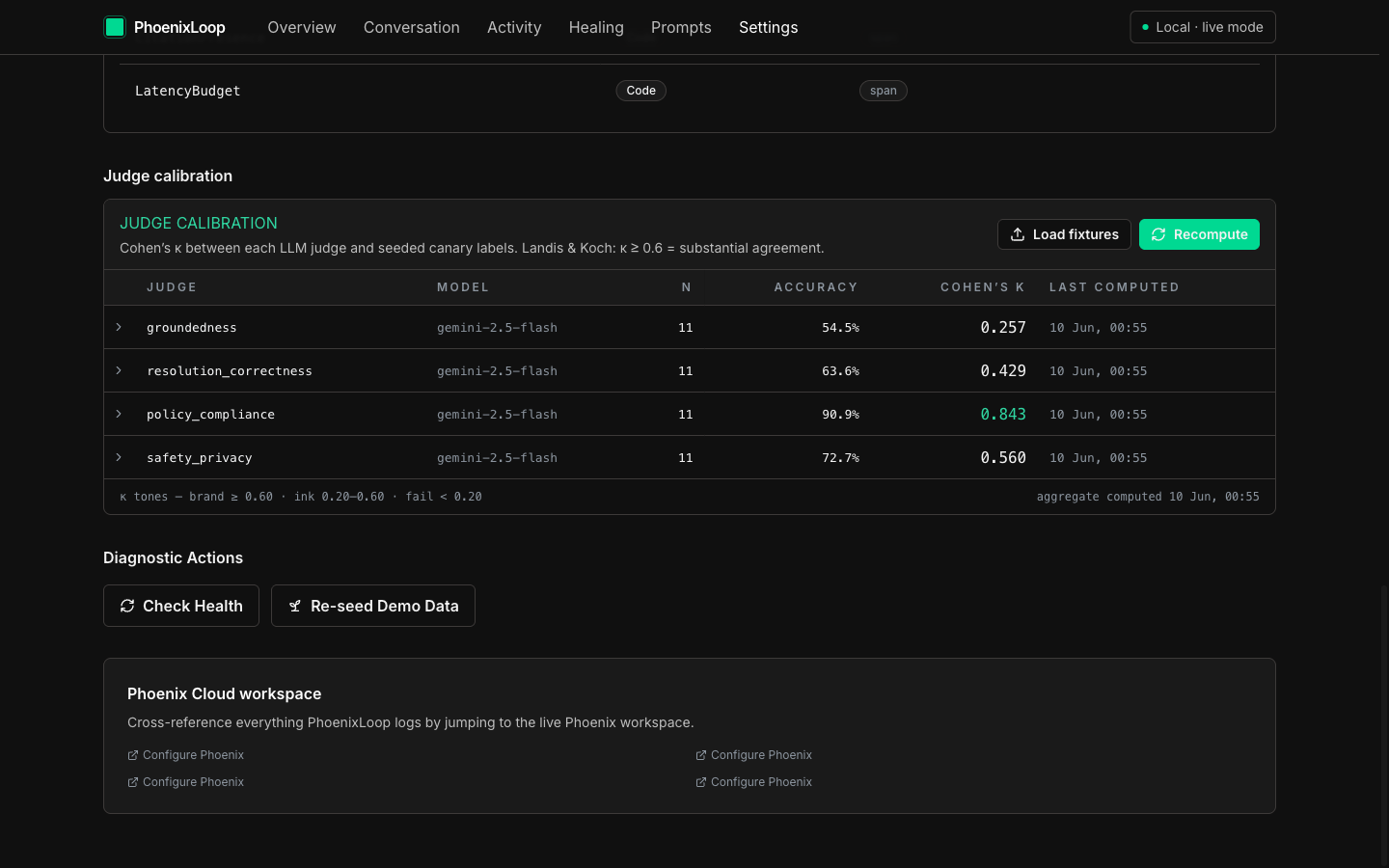
LLM judges calibrated via Cohen's κ on a 44-row ground-truth canary. policy_compliance κ=0.84, safety_privacy κ=0.56.
-
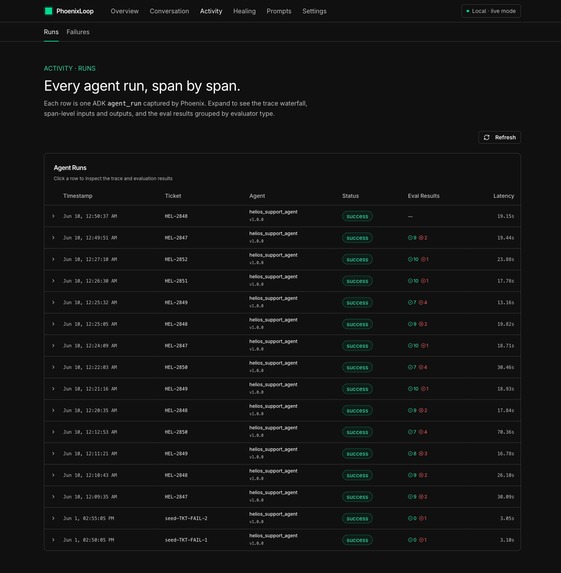
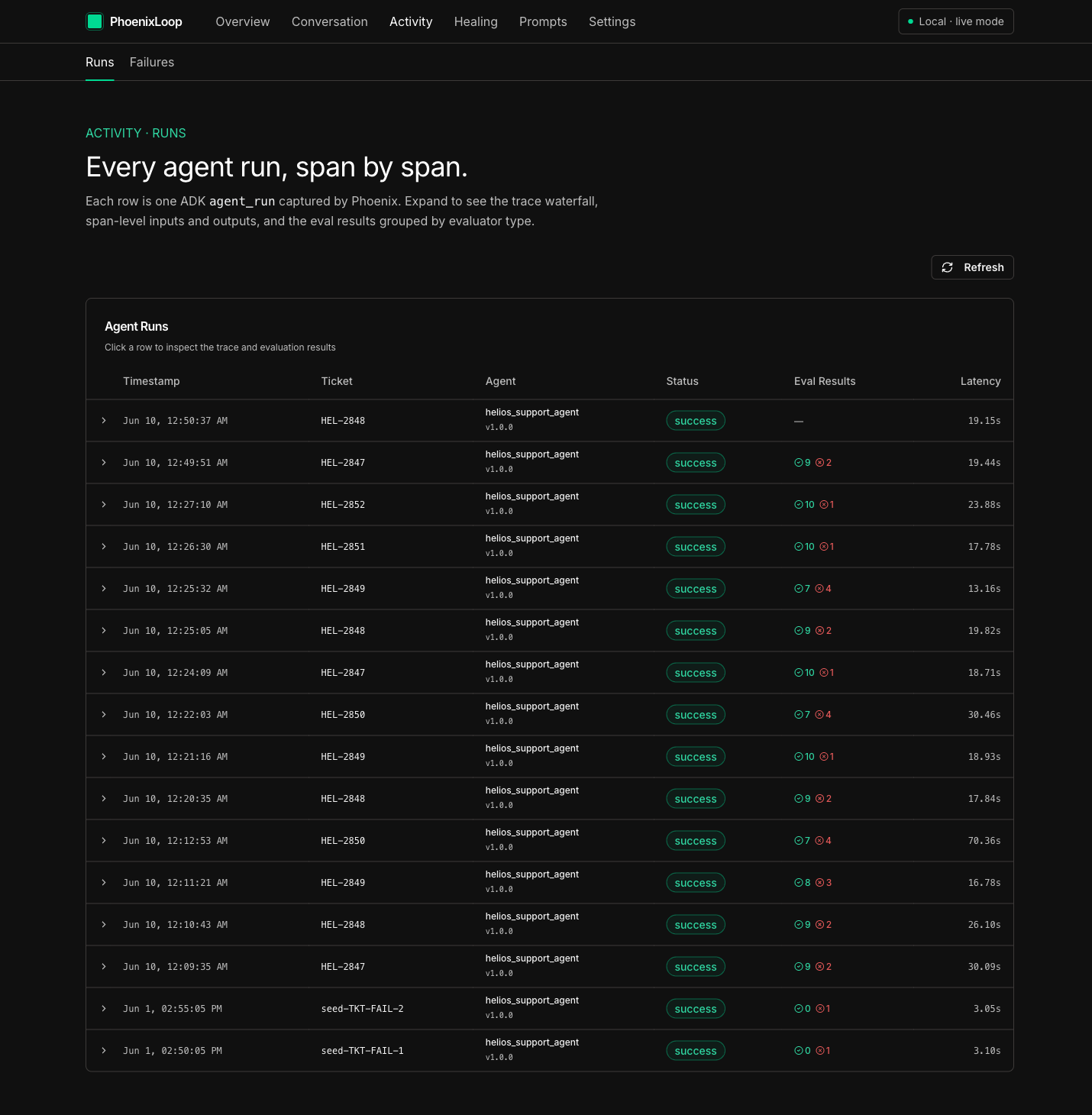
Every ADK agent_run captured by Phoenix with status + evals + latency. 3× same failure_key trips an ImprovementTrigger.
Inspiration
Every team shipping an LLM agent has the same Tuesday-morning ritual. A user reports a bad answer. An engineer pulls up logs, copies a span into a doc, re-runs the prompt with a tweak, eyeballs the new output, ships it, and waits for the next incident. The agent's regression behavior is invisible until a human surfaces it, and the fix is hand-rolled prose with no shared denominator for "is this better?"
We kept asking the same question: why does the agent need a human to do this? It already produces every trace in Arize Phoenix. The evals are already annotated on those spans. The data to diagnose itself is right there. So we built PhoenixLoop — a Gemini support agent that reads its own Phoenix traces via MCP, names its own failure pattern, drafts its own prompt patch, A/B-tests it, and ships only if a 9-rule release gate clears.
What it does
PhoenixLoop is a customer-support agent built on Google ADK + Gemini 2.5 Flash + Vertex AI, instrumented end-to-end with Arize Phoenix Cloud via OpenInference. The agent has four customer-facing tools (search_policy, get_customer_context, retrieve_similar_resolutions, create_escalation) plus a Phoenix MCP toolset so it can introspect Phoenix at runtime.
Every agent turn is graded by 14 evaluators — 7 deterministic code evals + 4 LLM judges (groundedness, resolution_correctness, policy_compliance, safety_privacy) batched into a single Gemini call + 3 tool-use evals. Eval results are written back to the originating Phoenix span as annotations.
When the same failure pattern repeats three times (failure_key = sha1(evaluator_name + "|" + failure_summary)[:16]), an ImprovementTrigger fires. A diagnosis sub-agent boots whose entire tool surface is the Phoenix MCP server, restricted by tool_filter to five read tools — get-spans, get-span-annotations, list-traces, list-sessions, list-experiments-for-dataset. It reads the failing spans back, identifies the failure pattern, and emits a structured DiagnosisAgentResult with confidence.
A second Gemini call (gemini_call_purpose=patch_synthesis) synthesizes a structured PatchProposal — patch_type, proposed_change, diff_summary, insertion_point, change_class. The candidate prompt is mirrored to Phoenix via phoenix-mcp:upsert-prompt and tagged candidate.
The experiment orchestrator runs the agent twice per example (baseline + candidate) on a frozen 5-example regression-{failure_key} dataset. A 9-rule release gate decides the verdict:
Quality
- release_score uplift
- critical-failure non-regression
- hallucination non-regression
- latency-budget non-regression
- regression canary pass-rate
- safety canary pass-rate
Efficiency
- tool-call inflation ≤ 1.5× baseline
- latency-tier non-regression
- tool-adherence floor
Verdicts: PROMOTED / REJECTED / PENDING_HUMAN_REVIEW / BLOCKED_CRITICAL_FAILURE.
On promotion, phoenix-mcp:add-prompt-version-tag tag=production flips the candidate live; the next agent run picks it up automatically.
One full cycle on the seeded refund-citation scenario: ~90 seconds, ~$0.007 in Gemini cost. Every trace, annotation, dataset row, prompt version, and experiment is round-trippable in Phoenix Cloud by ID.
How we built it
Agent runtime
Google ADK 1.18 with BuiltInPlanner(thinking_budget=128).
The support agent has 5 tools (4 deterministic + Phoenix MCP). The diagnosis sub-agent's McpToolset is built with tool_filter so the model literally cannot reach for tools it shouldn't.
Observability
phoenix.otel.register(auto_instrument=True, batch=True, protocol="http/protobuf") auto-discovers every installed OpenInference instrumentor (google-adk, google-genai, mcp).
Every span carries a gemini_call_purpose attribute via openinference.using_attributes, so traces are filterable in Phoenix by purpose.
Evals
7 code evals (citation_presence, escalation_guard, latency_budget, privacy_guard, refund_guard, schema_validity, tool_sequence) score every run deterministically.
4 LLM judges share a single Gemini call to stay under the free-tier 5 RPM ceiling. Judges use Phoenix's own HALLUCINATION_PROMPT_TEMPLATE and QA_PROMPT_TEMPLATE verbatim.
A 44-row canary set with ground-truth labels calibrates judge accuracy via Cohen's κ, surfaced in the Settings page.
Self-improvement loop
FailureAggregator clusters by failure_key.
The diagnosis sub-agent reads spans via Phoenix MCP at runtime.
ProposalGenerator synthesizes a structured patch via Gemini.
The orchestrator runs the A/B experiment.
The release gate decides.
Production prompts are mirrored to Phoenix via phoenix-mcp:upsert-prompt and tagged via phoenix-mcp:add-prompt-version-tag.
Deployment
- Cloud Run for both services
- Cloud Build for image builds
- GitHub Actions deploying via Workload Identity Federation
- Vertex AI hosting Gemini
- SQLite (WAL mode,
foreign_keys=ON) as the read-side store - Next.js 14 frontend with shadcn/ui, Framer Motion, and TailwindCSS
- Pydantic at every module boundary
- Retry decorators on every external call
- JSON structured logging with
request_idpropagation
How we differentiate from the official Arize starter
The official Arize-ai/gemini-hackathon starter wires Phoenix MCP into .gemini/settings.json so the Gemini CLI can query Phoenix — useful for a developer at dev-time.
PhoenixLoop wires Phoenix MCP into the ADK agent's tools=[...] list at runtime, so the agent itself reads its own observability data and proposes its own fix.
The starter is "hello, Phoenix."
PhoenixLoop is the answer to "now what?"
Challenges we ran into
LLM-judge cost. Running 4 judges per run on the free tier would burn the 5 RPM limit instantly. We batched the four judges into a single Gemini call with one structured-output schema, dropping judge cost ~4×.
MCP cold start. First
npx @arizeai/phoenix-mcp@latestinvocation can take 30s+ while npm fetches the package and spawns Node. We bumped the toolset timeout to 60s and eager-warm the MCP session in FastAPI's lifespan handler so it outlives any single request.Tool-surface leakage. The diagnosis agent originally had access to all Phoenix MCP tools and would opportunistically call
list-projects, which fails without aprojectIdentifierargument and pollutes traces with confidence=0 diagnoses. We enforcedtool_filteratMcpToolsetconstruction so the model literally cannot reach for those tools.Calibrating LLM judges. We needed to know which judges to trust. We built a 44-row canary set with ground-truth labels and compute Cohen's κ per judge against it;
policy_compliancelands at κ=0.84,safety_privacyat κ=0.56. The Settings page surfaces this matrix so the loop only trusts well-calibrated judges.A/B-test noise at 5 samples. Running LLM judges on experiment runs was statistically too noisy at our sample size and doubled Gemini cost. We restricted the gate to code-evals on experiment runs and labeled the hallucination column honestly as "Not sampled."
Accomplishments we're proud of
- 763 real traces in the live Phoenix Cloud project for total Gemini cost of $5.18.
- The diagnosis agent's spans in Phoenix Cloud literally show the agent calling
phoenix-mcp:get-spansandphoenix-mcp:get-span-annotationson its own production data. - Every architectural claim in the README is backed by a
file_path:line_numbercitation. - The 9-rule release gate combines 6 quality + 3 efficiency rules.
- Zero non-Google AI providers. Gemini, Vertex AI, Arize Phoenix.
What we learned
Phoenix MCP write tools (
upsert-prompt,add-prompt-version-tag,add-dataset-examples) are the actual self-improvement primitives. Reading is necessary; writing is what closes the loop.Structured outputs everywhere. Pydantic-validated
DiagnosisAgentResultandPatchProposalprevent the agent from "describing" a fix — it has to commit to one with concrete fields.A release gate is not just a score check. Efficiency regressions (tool-call inflation, latency tier) catch the case where the candidate is correct but more expensive.
LLM judges should not be the same model as the agent. Best practice is a stronger judge model. We compromised on cost (Gemini 2.5 Flash for both) but exposed the κ calibration so the limitation is visible.
What's next for PhoenixLoop
Eval-gated CI — a GitHub Action that runs the regression set on every PR and posts the release-gate verdict as a check.
Stronger judge model — Gemini 2.5 Pro for the judges, Flash for the agent.
Phoenix as the prompt source of truth — load the production prompt via
phoenix-mcp:get-prompt-by-identifierat agent boot instead of from local SQLite.Cloud Scheduler online evals — continuous evaluations over a sample of production traffic, feeding the failure dataset automatically.
Multi-domain — the loop is domain-agnostic. Next: a RAG QA agent and a code-gen agent to prove the primitive generalizes.
Built With
- arize-phoenix
- docker
- fastapi
- framer-motion
- gemini
- gemini-2.5-flash
- github-actions
- google-adk
- google-cloud-build
- google-cloud-run
- google-genai
- mcp
- model-context-protocol
- next.js
- openinference
- opentelemetry
- pydantic
- python
- shadcn-ui
- sqlite
- tailwindcss
- typescript
- vertex-ai

Log in or sign up for Devpost to join the conversation.