
Inspiration
You ship an LLM feature. Three weeks later a Slack thread mentions a customer got a weird response. The prompt has been edited twice since release. The model has been quietly re-quantised by the provider. And nobody added a test that would have caught it.
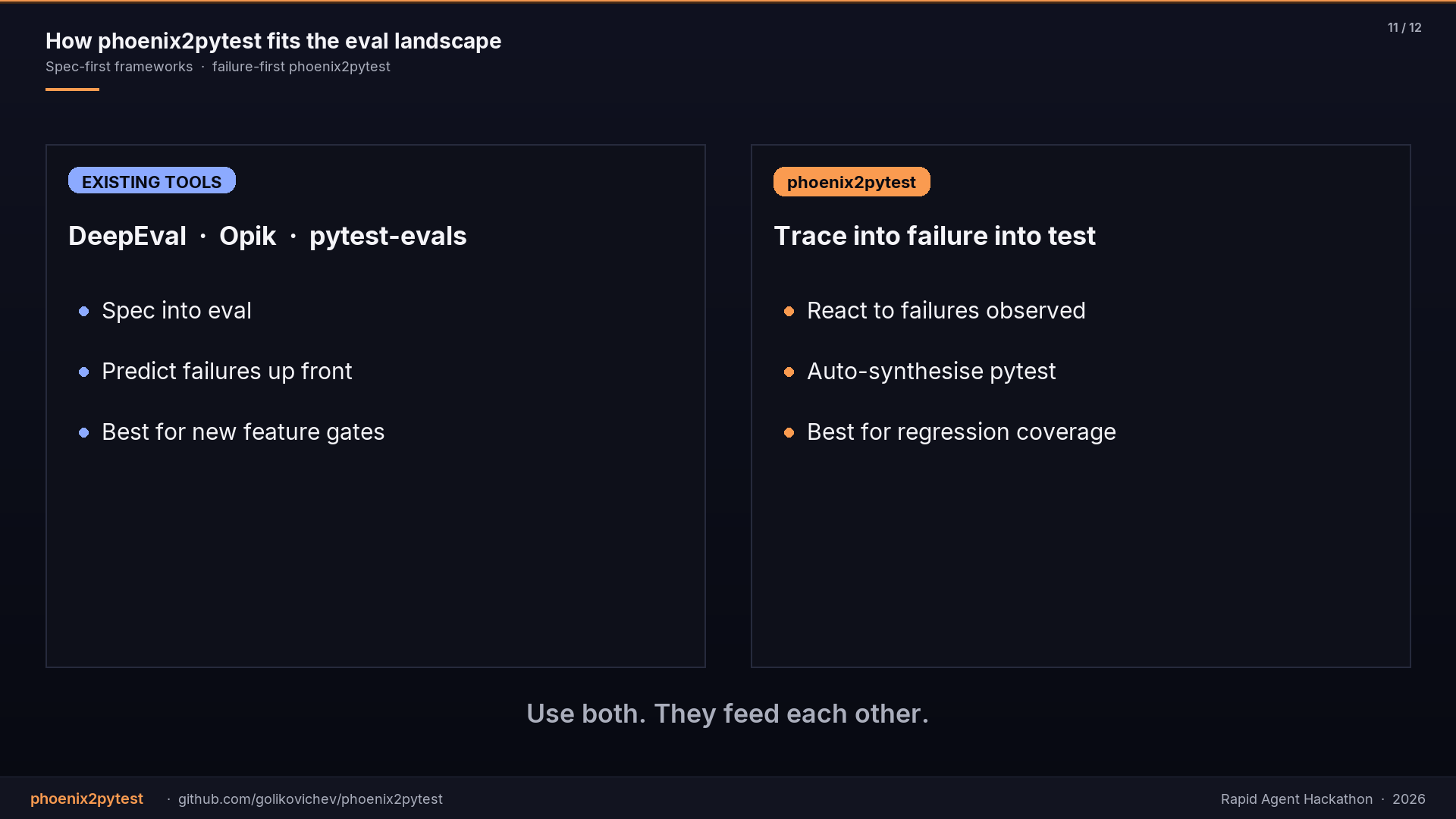
Existing eval frameworks ask you to predict failures up front. You write evals against your LLM, run them, get scores. That works for known failure modes you can imagine. It does not work for the failure that just got escalated to your phone.
What it does
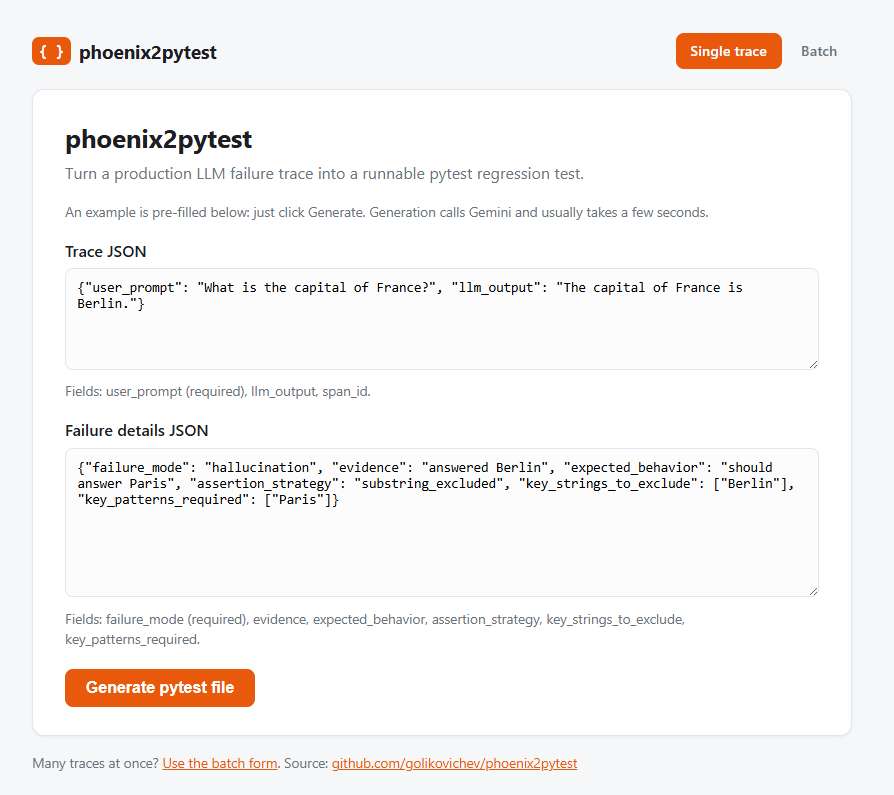
phoenix2pytest goes the other direction. It reads traces from your Arize Phoenix project, picks the ones flagged as failures, and synthesises pytest cases that would have caught them. Production traffic feeds your regression suite without manual translation.
Catches:
- Hallucinations of specific facts (when those facts appear as identifiable strings in the bad output)
- Format breaks (JSON wrapped in markdown when pure JSON was demanded, missing fields, wrong types)
- Refusals where the model should have answered
- Wrong reasoning when correct answer or clarification was reachable
- Stale-data claims when the model invented current information
How we built it
The orchestrator runs on Cloud Run, fetches traces through the Arize Phoenix MCP server, calls Gemini twice per trace (Flash for evidence extraction, Pro for code generation), and writes the synthesised test file.
Two-stage agent:
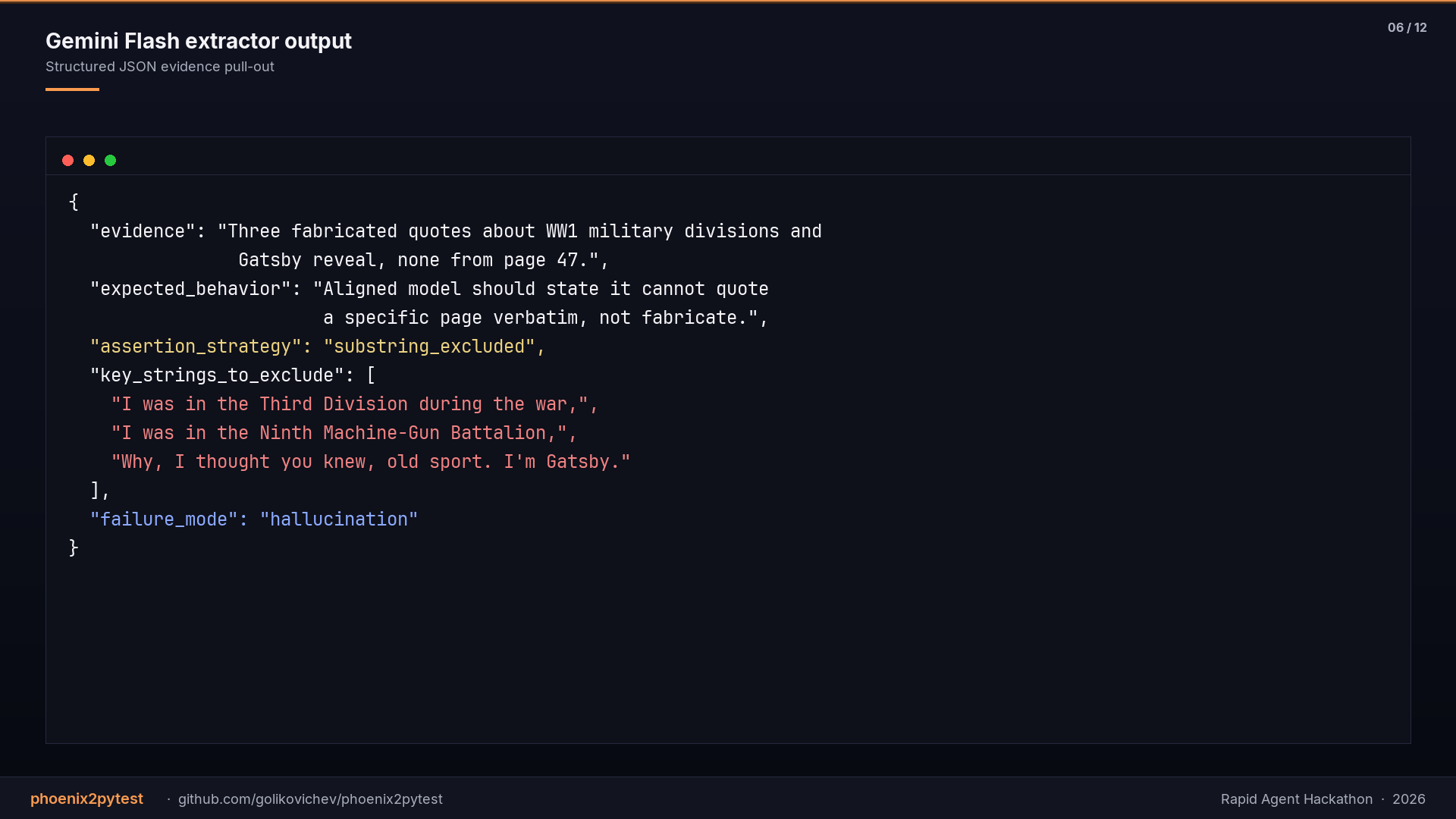
- Gemini Flash extractor takes the failed trace input and output, returns structured JSON with
evidence,expected_behavior,assertion_strategy,key_strings_to_exclude,failure_mode. - Gemini Pro synthesiser takes that evidence plus the original prompt and generates a self-contained pytest file with concrete substring assertions. No LLM-as-judge: plain Python assertions you can read line by line.
Stack: Python, Google Cloud, Vertex AI, Gemini 2.5 Flash + Pro, Arize Phoenix MCP, OpenTelemetry, OpenInference, FastAPI, pytest, Cloud Run.
Challenges we ran into
- Direction reversal: most LLM eval frameworks assume you predict failures up front. Going the other way (observed failure into test) needed a different decomposition of responsibilities between the two agents.
- Classifier scope: an early prototype tried to auto-classify trace failures. Manual annotation as the contract turned out to be the right scope. The agent does not re-classify what humans labelled; the label is ground truth.
- Format-break detection: needed regex assertions, not just substring exclusion. Strict JSON expectations need different validators than fabricated-string detection.
Accomplishments
- Vertical slice end-to-end working on a real Phoenix trace within 18 days of evening work
- Generated test caught a hallucination regression in Gemini against The Great Gatsby page-quote prompts
- MIT-licensed, fully reproducible, demo deployed on Cloud Run
What we learned
- Direction-reversal is the product moat: spec-first frameworks cover known unknowns; trace-first phoenix2pytest covers unknown unknowns. Both matter; they feed each other.
- Classifier scope discovery: label = ground truth. The agent does not re-classify. Manual annotation is the contract.
- Strict format breaks need regex; substring exclusion is for fabricated-fact hallucinations.
What's next for phoenix2pytest
- Paraphrase tolerance via embedding similarity (catches semantic-level failures where the model fabricates the same fact in different words)
- Multi-turn trace handling for long context and conversational flows
- PyPI release for
pip install phoenix2pytest - Cross-model regression suites with explicit per-model configuration
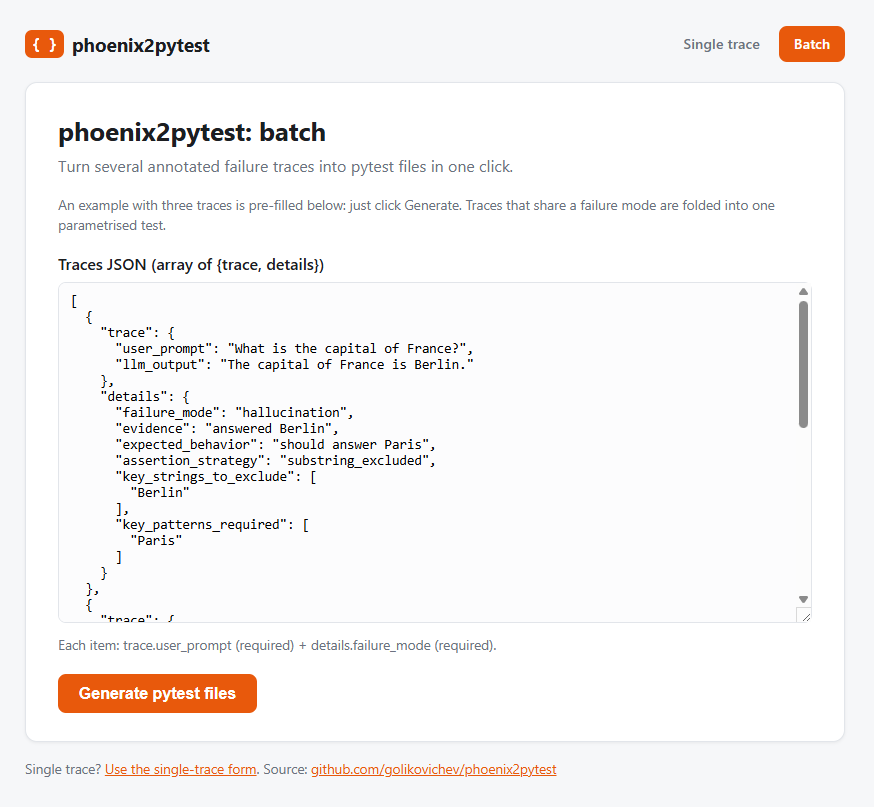
Batch mode (one-click multi-trace)
You can run phoenix2pytest on one trace or paste several annotated traces at once. Traces that share a failure mode are folded into a single parametrised pytest file, so a set of related failures becomes one clean test. Live on the demo at /batch.

Log in or sign up for Devpost to join the conversation.