-
-
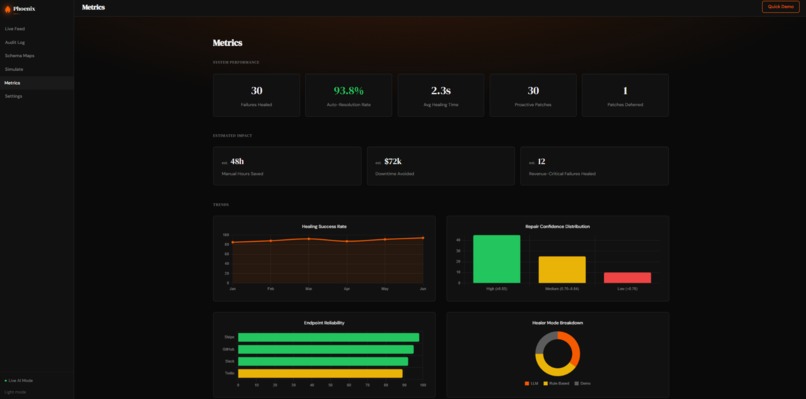
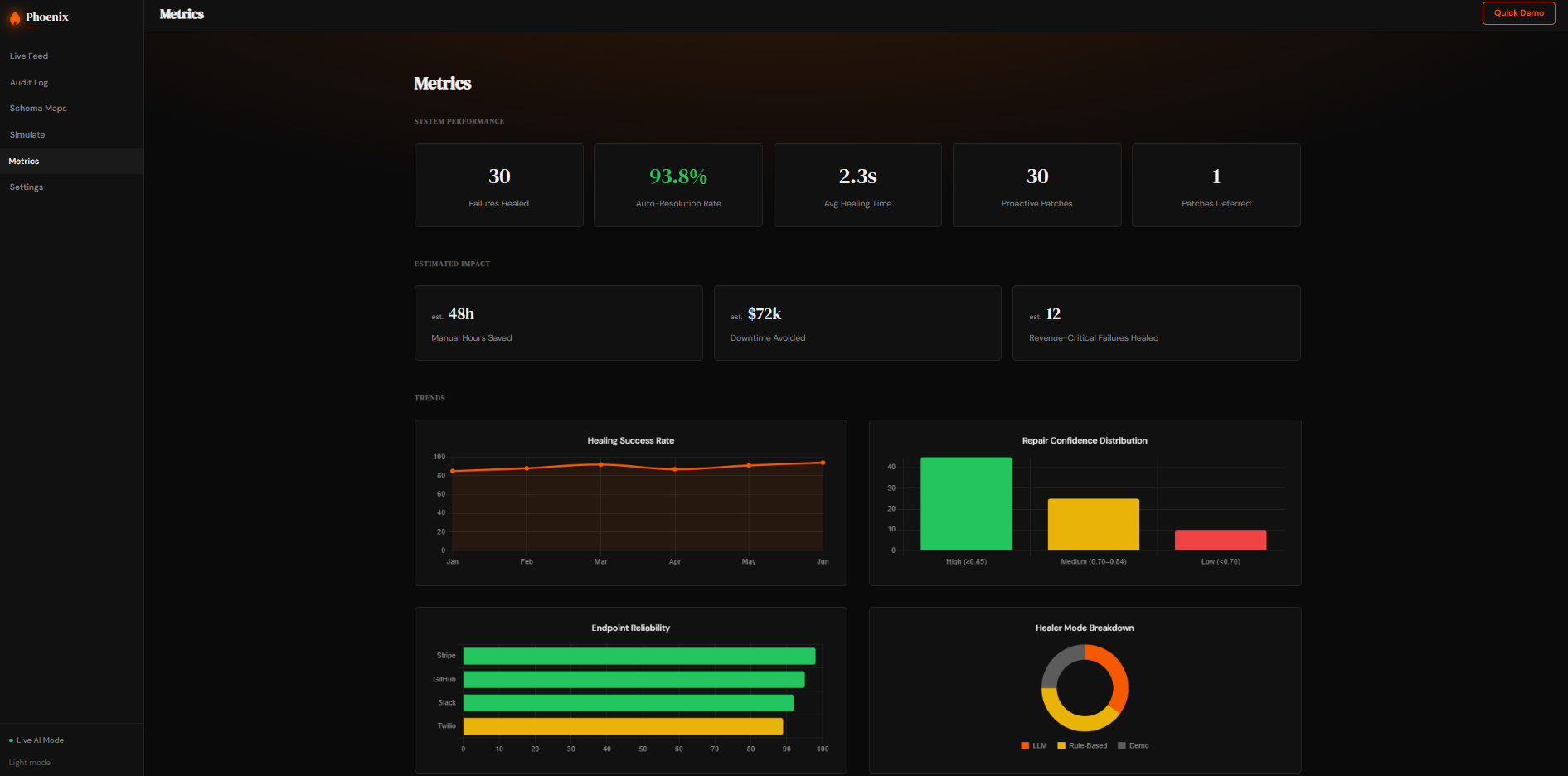
Metrics Page
-
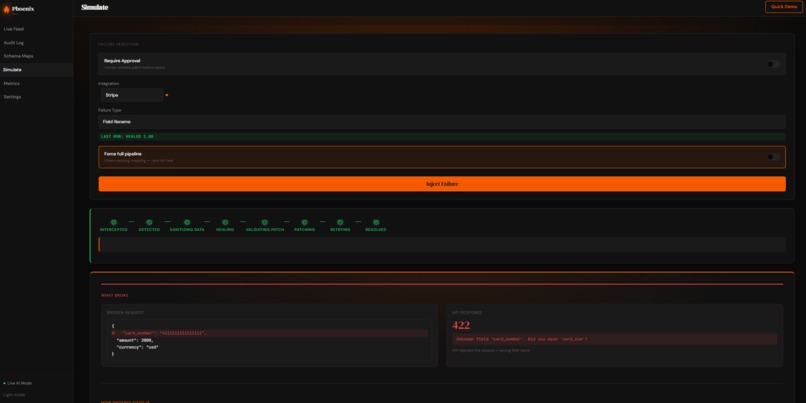
Simulate API failure and how Phoenix fixes it
-
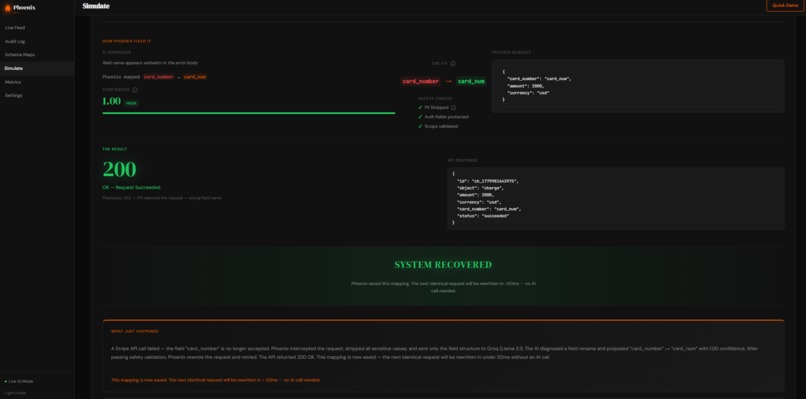
Elaboration on the Simulation Page
Inspiration
APIs fail in ways that are surprisingly expensive, up to $300 billion expensive. A renamed field, a version mismatch, or a schema change can quietly break production systems and suddenly an engineer is debugging something at 2 in the morning. Monitoring tools are good at detecting failures, but the actual repair process still depends on a human stepping in: there was no product that did both detect and fix APIs.
And so we started asking a simple question: what if software could do more than detect failure? What if it could diagnose the issue, safely repair it, and learn from the fix so the same problem never happened again?
That idea developed into Phoenix API.
What it does
Phoenix API is a self-healing API integration proxy. It sits between an application and external APIs and automatically responds when integrations break.
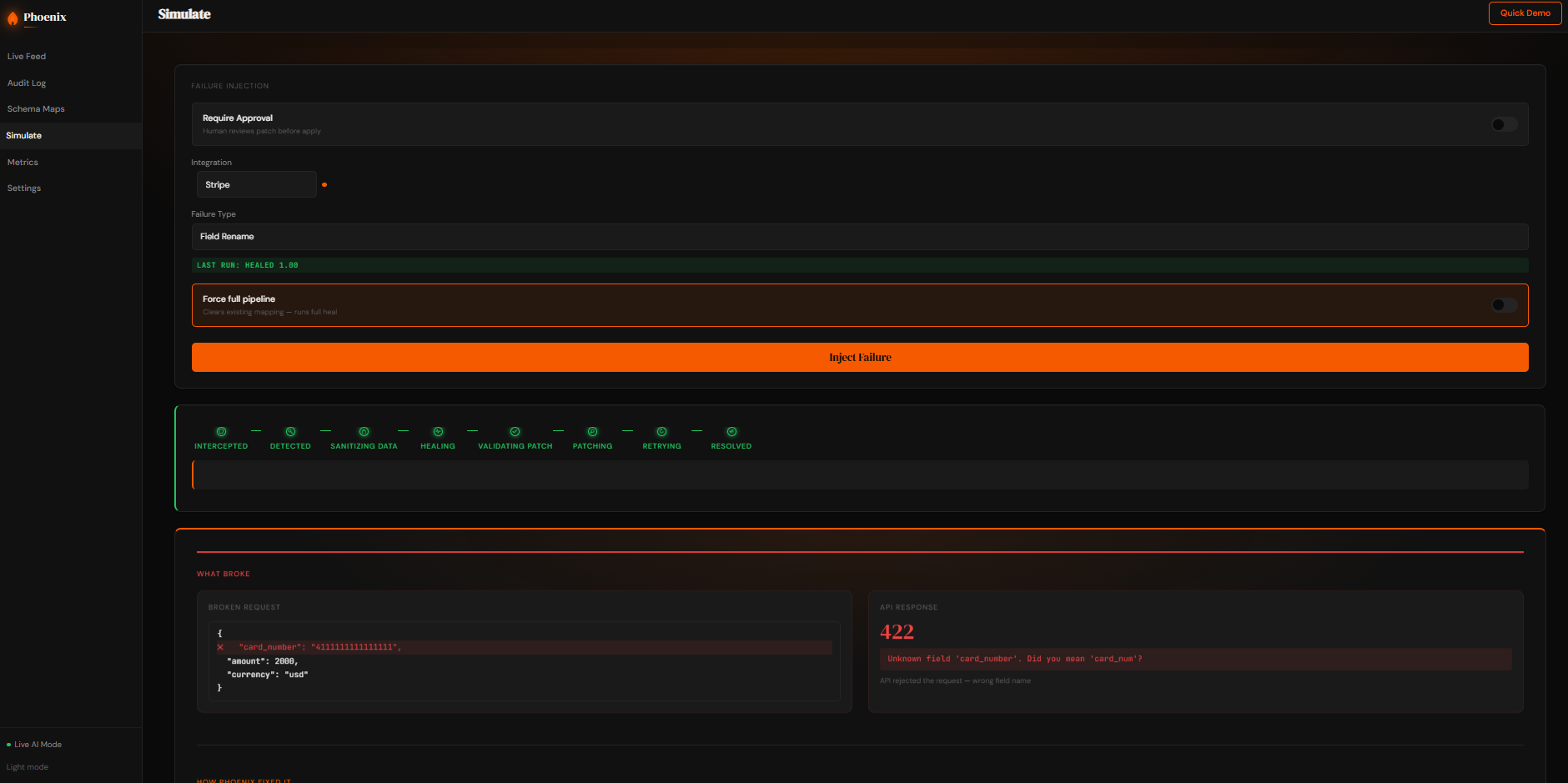
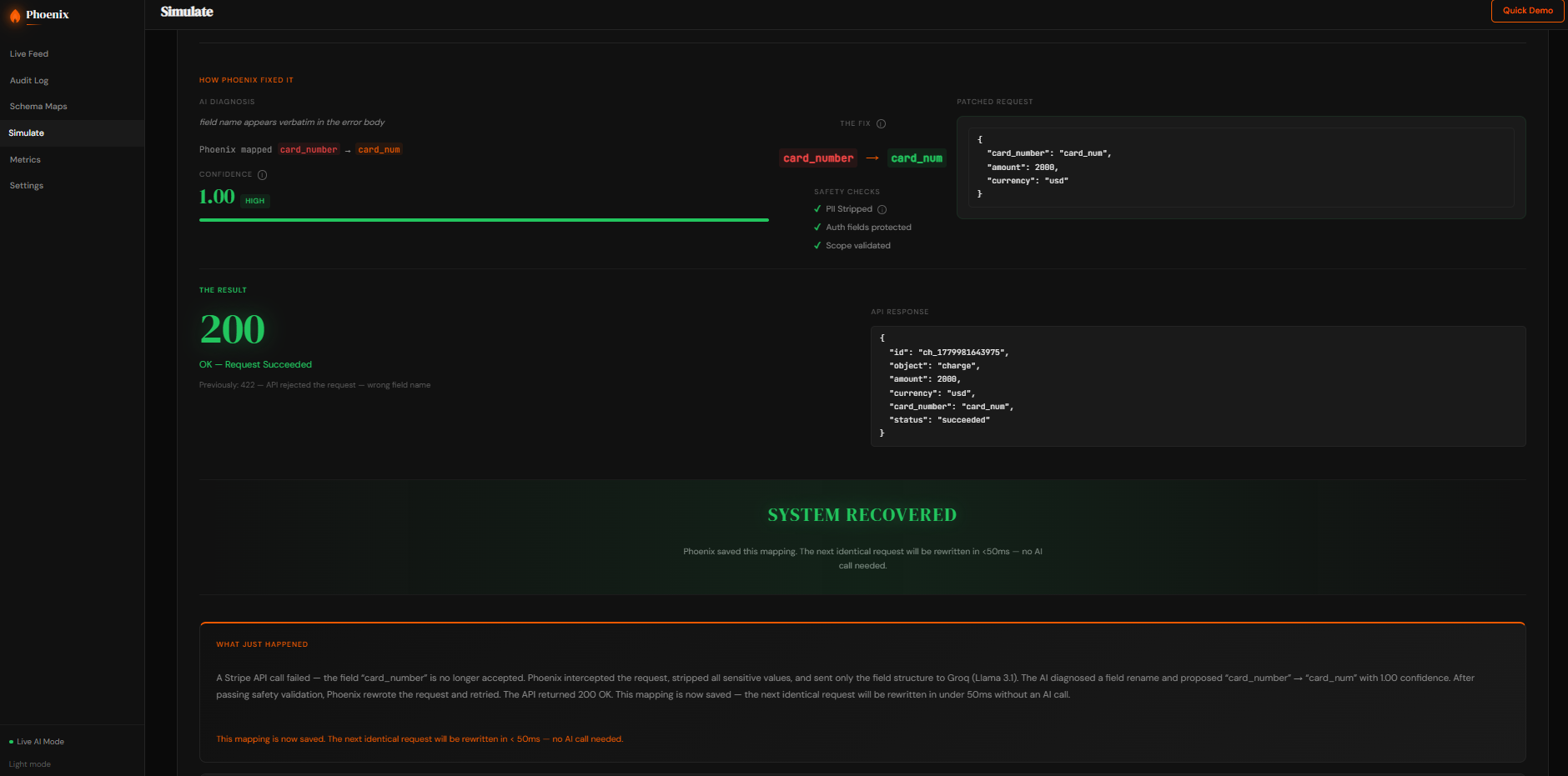
When an API call fails, Phoenix analyzes what went wrong, strips sensitive user data, generates a potential repair, validates it against safety rules, retries the request, and records what worked. If the same issue appears again, Phoenix proactively rewrites the request before failure happens.
Phoenix is designed to move teams from reacting to incidents to preventing repeat incidents altogether.
How we built it
Phoenix API was built as a system, not just an LLM wrapper.
We built a proxy architecture in Node.js and Express that intercepts outbound API requests and routes them through independent stages: failure detection, PII stripping, repair generation, patch validation, retry handling, schema learning, and audit logging.
The detection engine handles both explicit failures, such as 400 or 422 responses, and silent schema drift where an API technically returns a success response but the payload no longer matches expected structure.
Before any model is involved, Phoenix removes payload values and preserves only field names, types, and error context. This ensures no sensitive user data is exposed to inference.
For repair generation, we used Groq-hosted inference with fallback behavior and offline rule-based recovery. More importantly, we focused heavily on guardrails around the model. A PatchSanitizer blocks edits to authentication-related fields, confidence thresholds prevent risky auto-application, failed retries automatically roll back, and unresolved repairs are deferred instead of forced.
To make repair decisions safe and explainable, Phoenix assigns every suggested patch a confidence score:
$$ C = 0.35S + 0.25E + 0.20R + 0.20V $$
Where:
(S) = schema similarity score between expected and observed payload structure (E) = error-context match score based on failure type and API response patterns (R) = retry success likelihood estimated from historical repair outcomes (V) = validator confidence based on sanitizer and safety checks
Only repairs above a confidence threshold are automatically applied. Lower-confidence patches are deferred for manual review, reducing the risk of unsafe or incorrect modifications.
We also built a schema memory system so confirmed fixes are stored and reused. Once Phoenix learns a repair, repeated failures can be intercepted proactively in under 50 milliseconds without another AI call.
We measure proactive improvement as the prevention rate:
$$ P_{prevented} = \frac{R_{reused}}{R_{total}} $$
Where (R_{reused}) represents previously learned repairs reused proactively and (R_{total}) represents total repair incidents. This captures how Phoenix improves over time as it accumulates reliable repair patterns.
On the frontend, we built a real-time dashboard in React with WebSocket updates, failure simulation tooling, audit logs, schema visualization, metrics, and configurable safety settings. The goal was to make every repair decision observable and understandable, rather than hidden behind automation.
Challenges we ran into
One of the biggest challenges was making Phoenix feel trustworthy.
It's relatively easy to build something that suggests fixes. It's much harder to build something that can safely apply them without creating new problems. We spent a lot of time thinking through rollback behavior, confidence thresholds, validation logic, and what should never be modified automatically.
Another challenge was handling silent failures. APIs don't always fail loudly. Sometimes a request still returns a 200 OK even though the schema changed underneath. Building logic to catch those cases pushed us beyond standard error handling and into behavioral detection.
We also had to balance realism with hackathon speed. Phoenix is ambitious, so we had to be selective about what would create the strongest proof of concept without sacrificing credibility.
Accomplishments that we're proud of
We're proud that Phoenix feels like a real system rather than a prototype stitched together with prompts.
The proactive interception loop is probably our biggest accomplishment. Watching Phoenix heal a failure once, learn from it, and prevent the exact same issue seconds later without another AI call feels genuinely rewarding along with practically useful.
We're also proud of the safety architecture. PII stripping, confidence gating, rollback behavior, authentication-field protection, and deferred repair handling were treated as first-class features rather than afterthoughts.
Finally, we're proud that the system is explainable. Every repair is logged, auditable, and visible through the dashboard so users can understand exactly what Phoenix changed and why.
What we learned
We learned that building with AI is less about the model itself and more about the systems built around it.
The model is only one component. Reliability comes from constraints, observability, fallback behavior, and safe failure handling. Everything is a system, from the trust of the users to the actual API fixes.
We also learned how much trust matters in automation. Even if a system works technically, people won't just rely on it unless they can understand its decisions and stay in control.
But most importantly, we learned how quickly a small idea can evolve once you start building around a problem that feels genuinely painful with real consequences. All it takes is an idea and the willingness to follow through with it.
What's next for Phoenix API
The next step is making Phoenix more production-ready.
We want to move from SQLite to PostgreSQL for scalability, add idempotency support for safer retries on live APIs, and introduce notifications for deferred repairs that require human review.
We also want to expand schema isolation for multi-tenant environments, improve observability and tracing, and strengthen repair validation for more complex edge cases.
The long-term goal is simple: make broken integrations something of the past, where both engineers and business can rest assure that APIs won't be their downfall--both fiscally and mentally.
Built With
- chart.js
- css
- express.js
- git
- groq
- learning-agent
- node.js
- npm
- patchsanitizer
- pii
- pipeline
- proxy
- react
- schema
- sqlite
- typescript
- vite
- websockets

Log in or sign up for Devpost to join the conversation.