-
Demo Screenshot
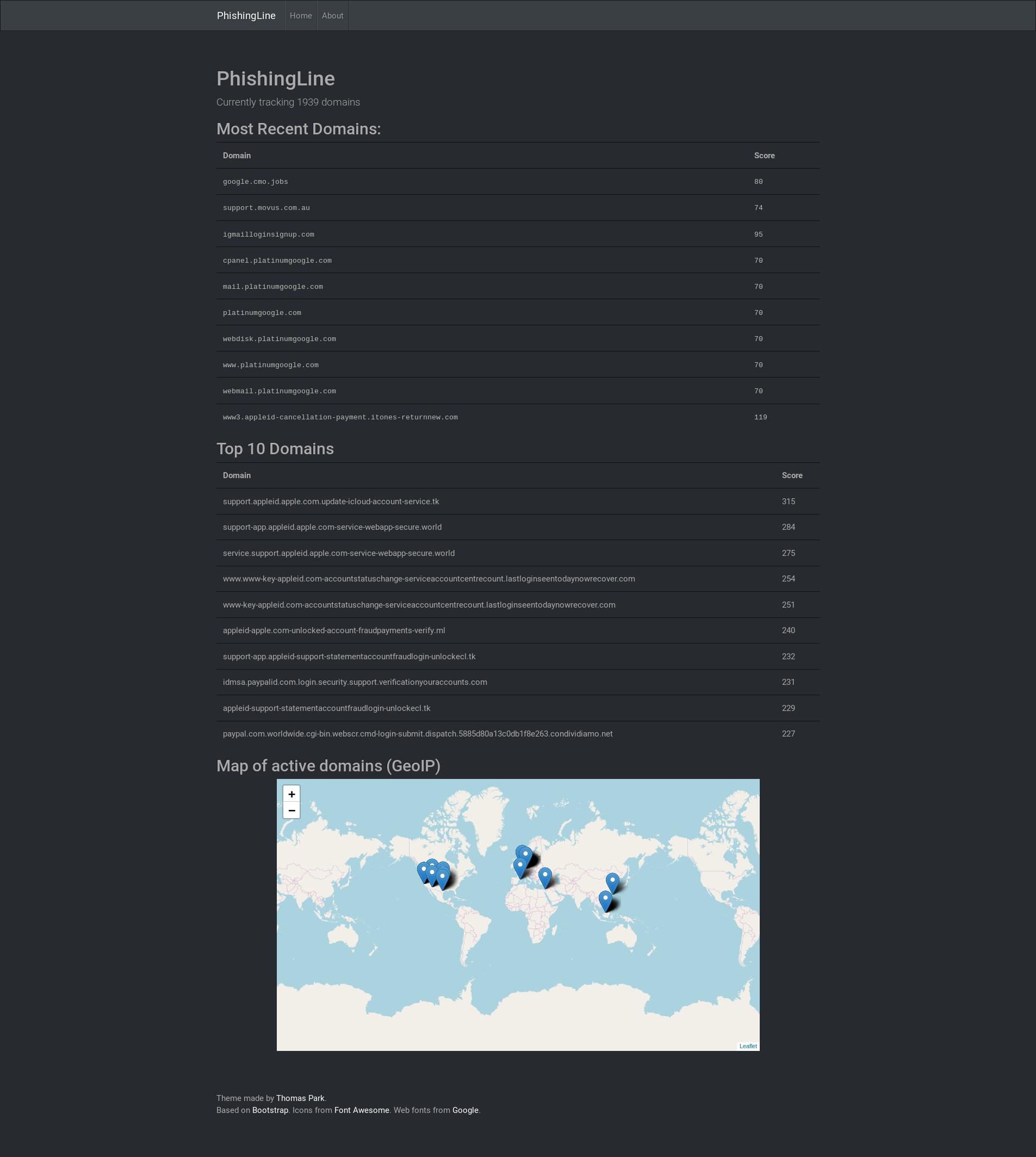
PLEASE NOTE: Due to issues with Domain.com's DNS propagation being rather slow, I'm having to run it the demo on a high port of an existing domain. If it propagates in time, phishingline.net should go up
Inspiration
The theme of this hackathon was "Open Data". While searching for ideas, I found a data source called CertStream, which parses the Certificate Transparency Logs to create a WebSocket feed of newly registered domains.
As someone who's quite into security, the idea of distilling the data provided by CertStream into something that could be applied for security purposes seemed interesting. After some consideration, I settled on looking for new phishing domains - they tend to follow some common patterns, which turned out to be amenable to automatic recognition
What it does
PhishingLine reads incoming certificate registrations from CertStream, and scans the domains the certificate is valid for. The scans comprise of a set of simple heuristics, which are used to calculate a score for the domain - the higher the score, the more likely the domain is to be a phishing domain.
I made use of the following matching techniques:
- Substring Matching - Phishing domains typically use a lot of common substrings, which can easily be matched.
- TLD Matching - Certain TLDs are commonly abused in phishing domains and other malicious activities. A domain under such a TLD can be viewed with more suspicion.
- Character Count Matching - Phishing domains often contain many "-"s and deeply nested subdomains, so if there are enough present, score proportional to the number of "-" and "." characters in the domain.
- Levenshtein Distance Matching - Some phishing domains contain near-matches to some keywords - e.g. "pavpal". Therefore, we can match on certain keywords if the Levenshtein distance to parts of the domain is small.
- Free Certificate Authority Matching - Free CAs are commonly used in phishing sites in order to help present an image of legitimacy. As such, if such a CA is in use, this will incur a small score.
PhishingLine then presents the 10 most recent domains, 10 highest scoring domains and a map of the 50 most recent domains which resolve to an IP address. There are also endpoints available to provide JSON of the domains, useful for scraping and automatic parsing (e.g. into a DNS blacklist)
How I built it
I begun by developing a simplified, command-line version of PhishingLine - this allowed me to implement the stream reading functionality and some basic scanning early on, without worrying about moving the data to the frontend.
Next came some improvements on the matching heuristics, followed by the implementation of a basic frontend, written in Python with Flask. However, this used a frankly terrible means of getting the data from the stream parser to the web page - so the obvious next step was to move to a SQLite database.
Beyond that, some gradual functional and UI improvements later, and PhishingLine reached its current state.
Challenges I ran into
There were a few key challenges which I ran into:
Firstly, I attempted to scan content, rather than domains. This caused issues, as there are quite a lot of new domains coming in on CertStream per second, and any exceptions while fetching content needs to be handled, etc, etc. - In the end, it turned out to be an unsuitable approach for a lot of reasons, while domain scanning proved sufficient.
The next major challenge was in implementing the map - I tried rendering it server-side, first trying to use BaseMap (Which failed due to the fact that - in spite of far too much effort - it simply wouldn't install) and then Cartopy (Which wouldn't produce a suitable map, again in spite of too much effort). Then it was suggested I try Leaflet. Half an hour later it worked. After several hours of build systems/graph libraries hating me.
Wonderful.
Accomplishments that I'm proud of
Went from idea to a somewhat-working result fairly quickly, before I stalled out trying to get a map to render.
Did something interesting with an open data source
Staying awake... x.x
What I learned
Practised working with Flask, Bootstrap, etc.
Learnt about processing a novel data source.
Practised using SQLite
What's next for PhishingLine
Not a lot, immediately. The first thing would be to move the background worker to some sort of slightly less shitty setup - at the moment I'm just forking it off in a thread when the mainapp.py loads, which is less than ideal...
An interesting line of experimentation might be to try applying some sort of machine learning for scoring and detection, rather than manual hard-coded heuristics.


Log in or sign up for Devpost to join the conversation.