-
-
First Image
-
Inspiration
In today's digital age, the growing threat of phishing attacks, spam messages, and malicious content has become a serious concern. As communication shifts towards online platforms, protecting users from deceptive and harmful messages is more important than ever. Inspired by the increasing need for secure digital communication and the potential of machine learning in natural language understanding, we set out to create a tool that could intelligently detect spam or phishing content, especially in email and SMS formats. The goal was to enhance safety and build trust in everyday communication.
What it does
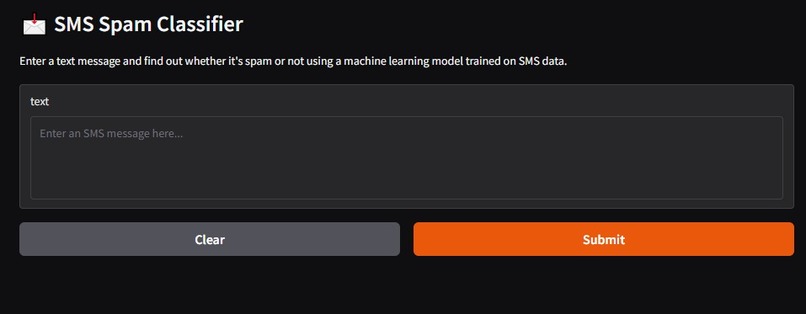
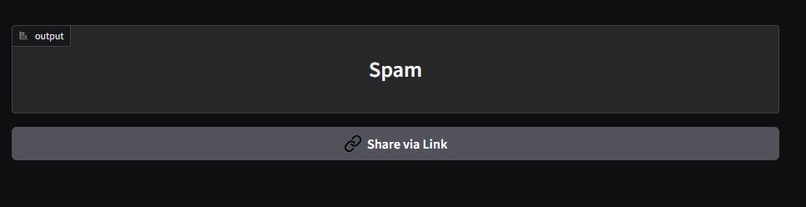
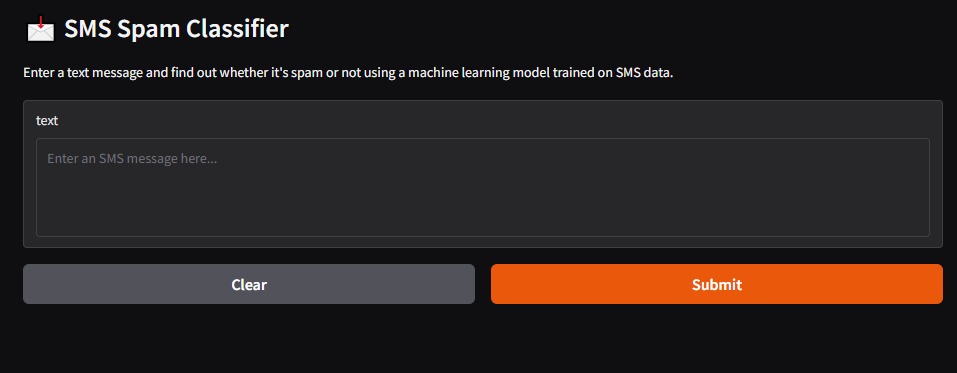
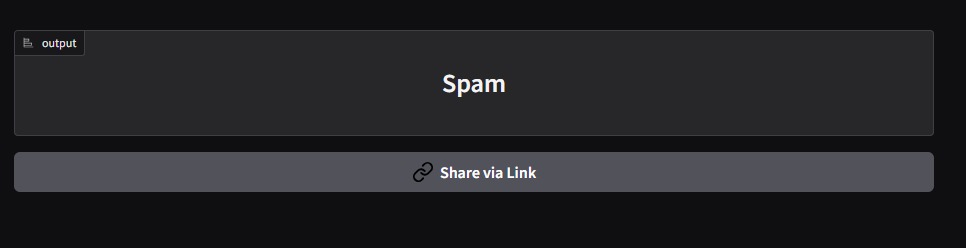
NeuroText Shield is a machine learning-powered tool that classifies messages as either safe (ham) or harmful (spam or phishing). It takes input in the form of emails or SMS texts and analyzes their content using a trained logistic regression model to predict whether the message poses a potential threat. This helps users and organizations identify suspicious content and reduce their risk of falling for scams or unwanted solicitations.
How we built it
We started by analyzing a labeled dataset of SMS messages, cleaning the text, and extracting features using a TF-IDF tokenizer. These features were then used to train a Multinomial Naive Bayes classifier, which showed strong performance for spam detection tasks. We saved the trained model and vectorizer using joblib for later use during inference. To create a user-friendly interface, we used Gradio, which enabled us to build an interactive web application without the need for traditional front-end development. The app allows users to input SMS messages and instantly receive predictions on whether the text is spam or ham. We used Python throughout the project, leveraging libraries such as pandas, scikit-learn, joblib, seaborn, and Gradio to support data handling, model development, visualization, and deployment.
Challenges we ran into
One of the primary challenges was ensuring consistency between training and inference when using the TfidfVectorizer. We had to carefully preprocess text during both phases to maintain the format expected by the model. Integrating the trained model and vectorizer into a Gradio interface also posed challenges, particularly in handling real-time inputs and maintaining performance. Additionally, we encountered environment-related issues when transitioning between development in Google Colab and local setups, including version mismatches and file path inconsistencies that required debugging.
Accomplishments that we're proud of
We successfully built an end-to-end machine learning application that accurately detects spam and phishing content. The ability to process raw text input, match it against learned patterns, and return results in a matter of seconds makes this tool both practical and impactful. We also take pride in overcoming data preprocessing and deployment hurdles that would typically block a small team on a tight timeline.
What we learned
This project helped us strengthen our understanding of the entire machine learning lifecycle, from data preparation and model training to deployment and user interaction. We learned the importance of reproducibility in ML workflows, especially how critical it is to save both the model and the exact preprocessing pipeline. Additionally, we gained hands-on experience in debugging and resolving real-world issues that arise during deployment.
What's next for NeuroText Shield
We aim to expand the system to support multilingual inputs, integrate with popular messaging apps and email services, and improve the model’s ability to detect sophisticated phishing attempts using deep learning. We also plan to collect more real-world data to fine-tune the model and reduce false positives. Eventually, we hope NeuroText Shield becomes a plug-and-play security layer for both individuals and enterprises.
Built With
- flask
- googlecolab
- huggingface
- joblib
- pandas
- python
- re
- scikit-learn
- seaborn




Log in or sign up for Devpost to join the conversation.