Inspiration
After seeing the FIHR dataset in the list of given challenges, we decided to write code to interpret it.
What it does
FIHR-viewer, as of now, parses the input JSON dataset and extracts data on user-specified features, before passing these to a library to apply a statistical method called 'factor analysis' to the given features to determine potential underlying correlations between features in a factor matrix.
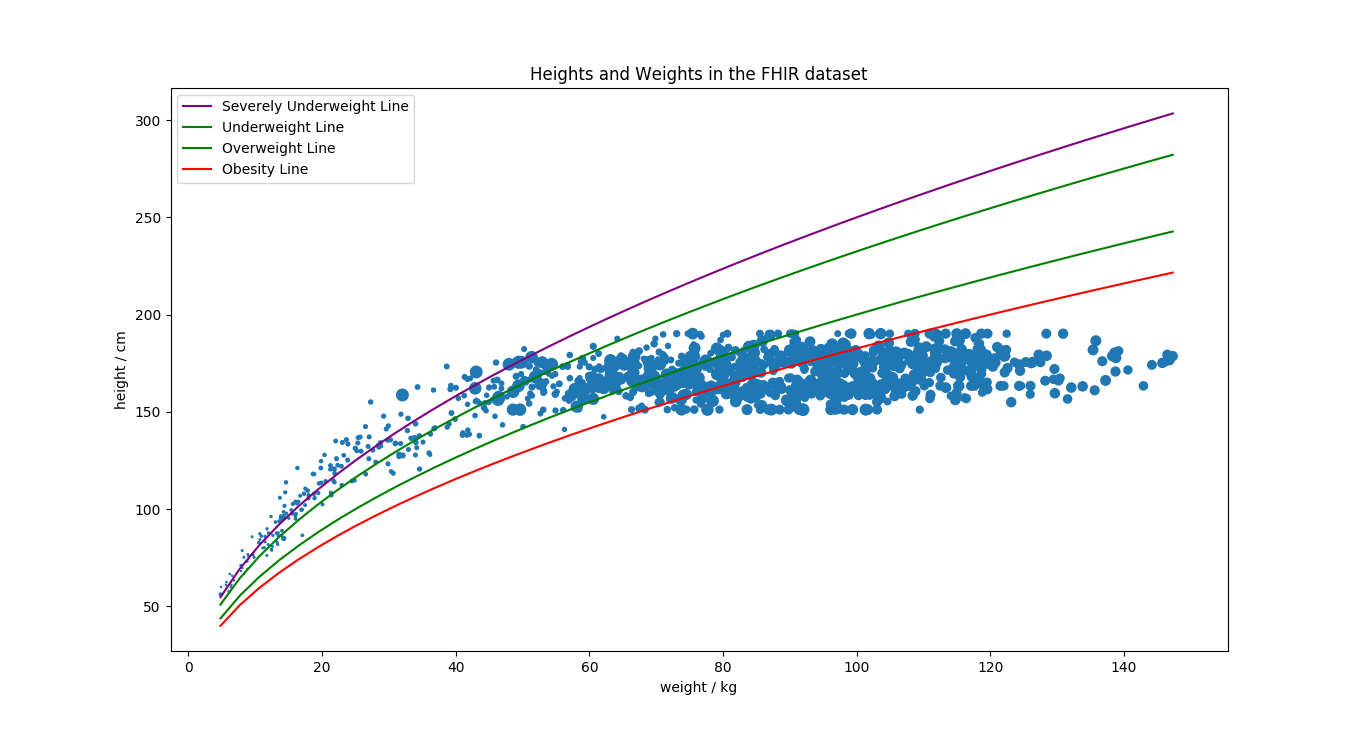
The program also has graphing facilities thanks to matplotlib, which produced the example graph found on the git repository.
How we built it
Using an unofficial python parser for the FHIR dataset, we extracted relevant data and put it into a format to pass to a general-purpose set of analysis libraries for further processing.
Challenges we ran into
We ran into plenty of challenges not limited to not having access to the easy to use code keywords of the dataset as the definitions were kept behind a paywall. Another issue was the fact that out of the data available, we had very limited amount compared to what we should have even for something like height,mass and BMI which meant using regular factor analysis was limited to discrete or normalised datasets only.
Following on from the previous point, there was a significant lack of resources available on python and in general (as one algorithm had only been described in research papers and not in actual use), on how to apply an algorithm with the same goal to categorical data or non numerical such as Country of birth. This meant out of the data available we were limited to discrete and easily normalised data.
Accomplishments that we're proud of
Using parser wrote our own script to parse and organise the data in a format readable and usable by the scientific packages. Successfully used statistic algorithm package after normalising data to get meaningful conclusions from our given factors. Plotted the results on a bubble graph along with references lines denoting boundaries between BMI categories and how our data fits in.
What we learned
FHIR data format has a lot of information not accessible without the official libraries which we did not have access to so learned a lot parsing the information ourselves using standard JSON facilities developed by reading JSON files in the dataset. How to apply statistical methods to a given dataset and come up with meaningful results. Also how create and visualise the data in a format which is easily readable and makes it come across nicely.
What's next for FHIR-Viewer
Incorporating algorithms which work on non-numerical (discrete) data which was not possible today. Long-term: refactor code into an API that reads in JSON data, applies statistical analyses based on user control input, and visualizes the output, all in one fell, readable swoop.





Log in or sign up for Devpost to join the conversation.