-
-
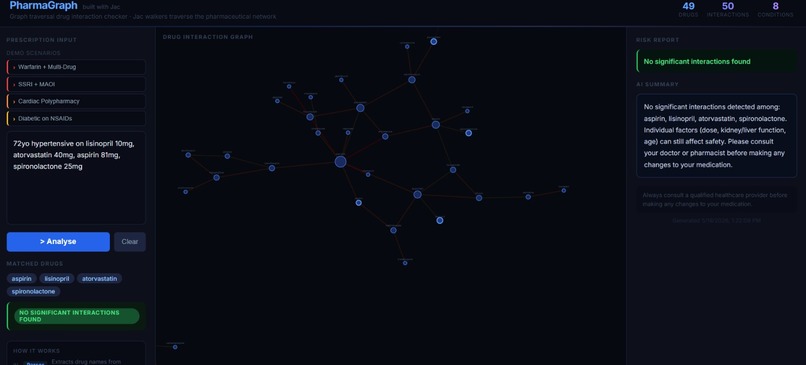
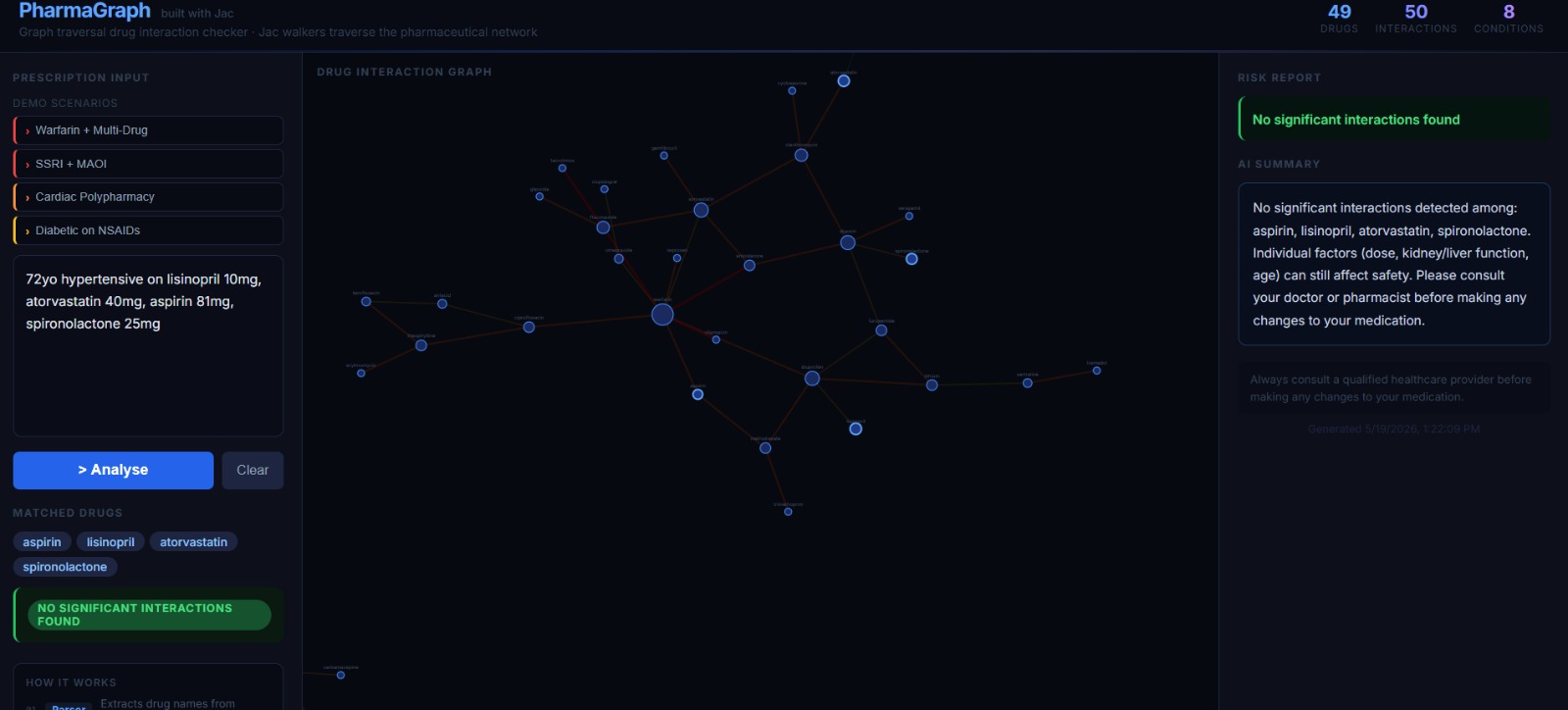
Safe prescription
-
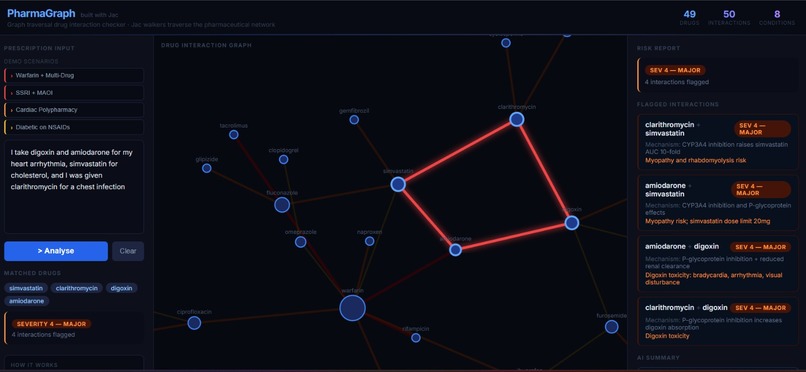
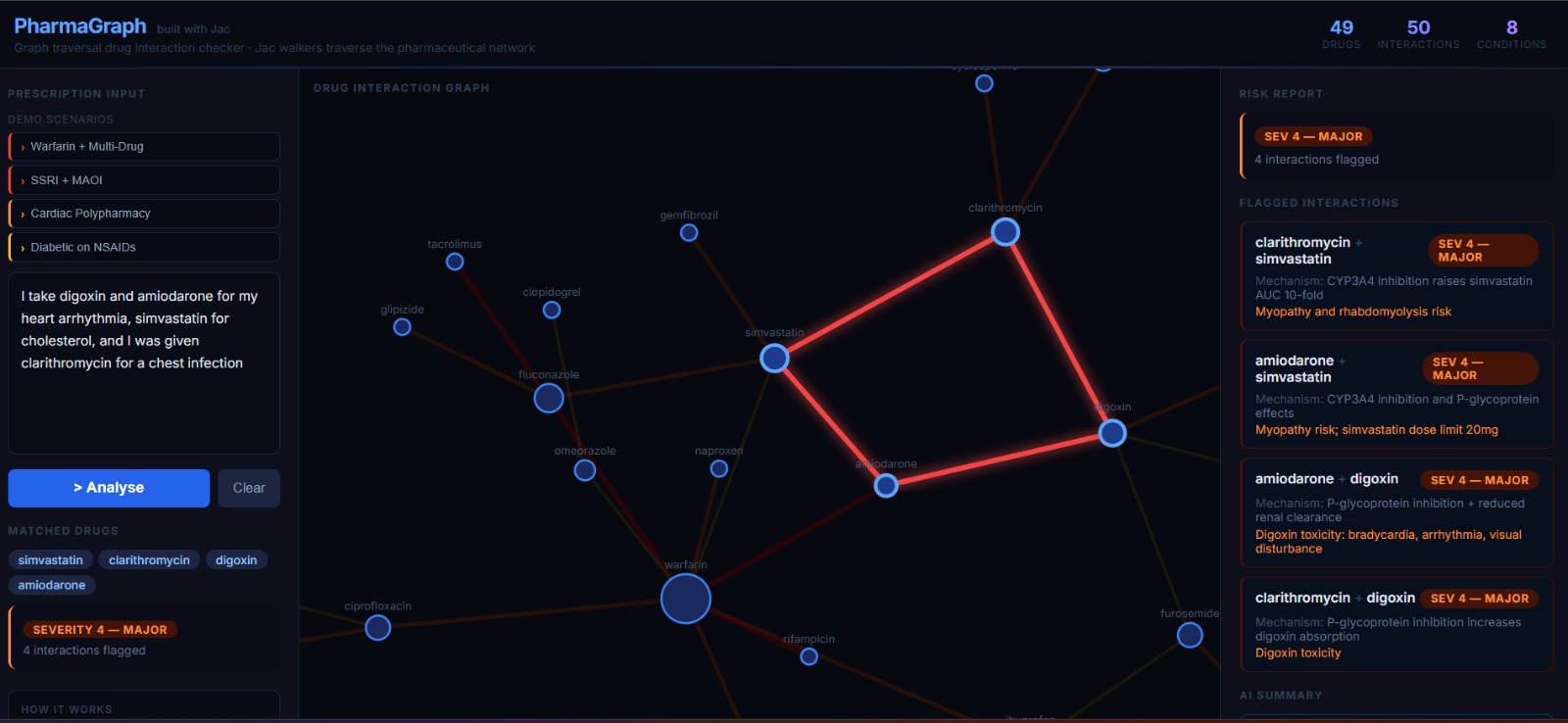
Unsafe prescription-1
-
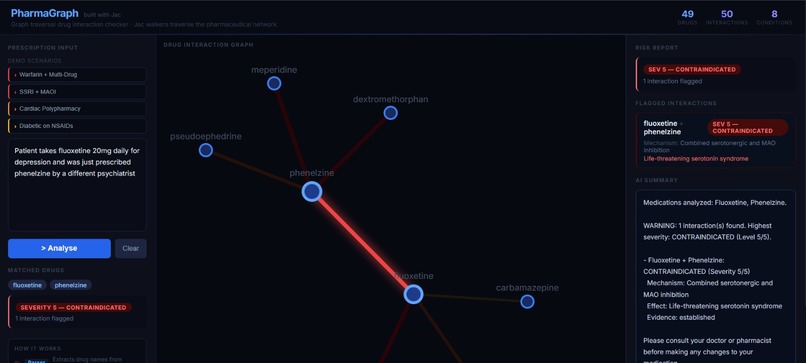
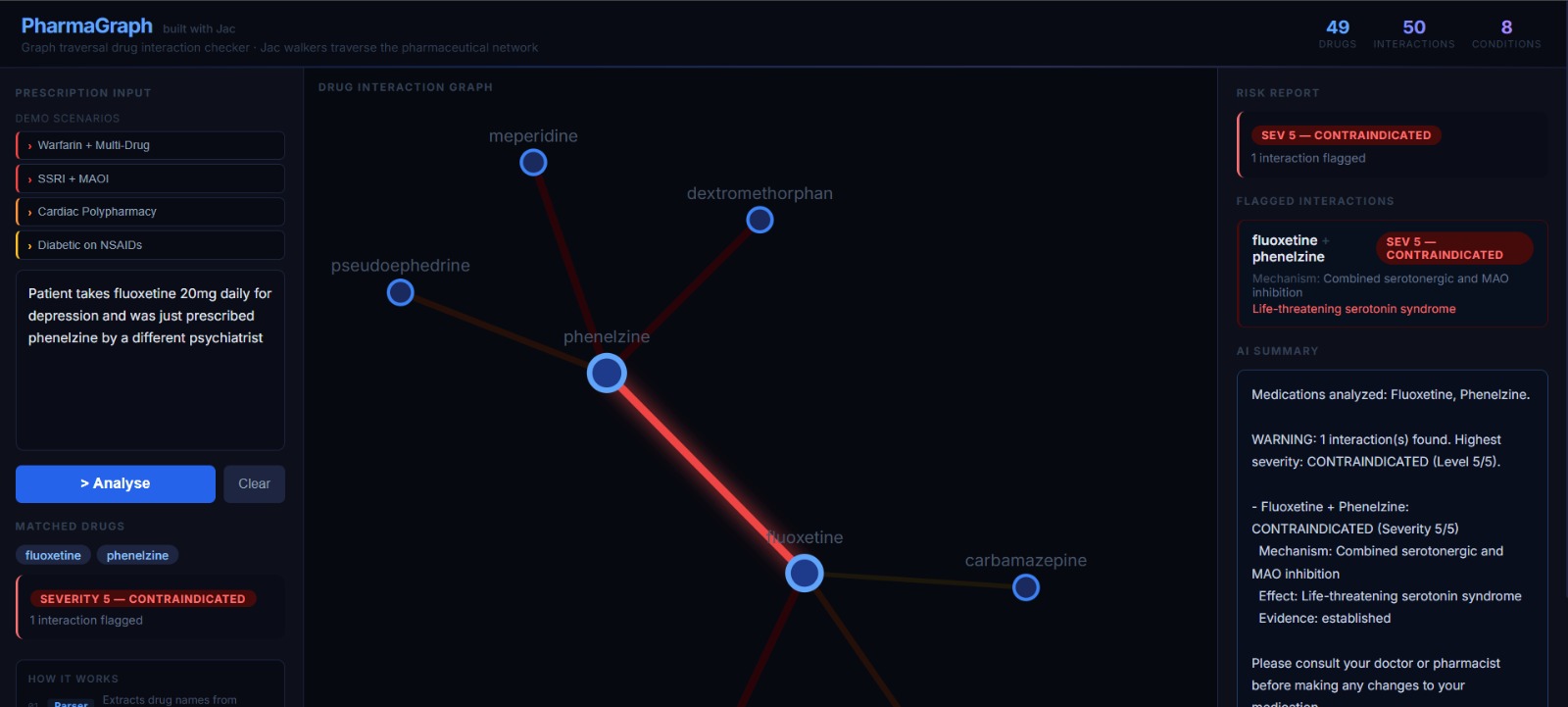
Unsafe prescription-2
-
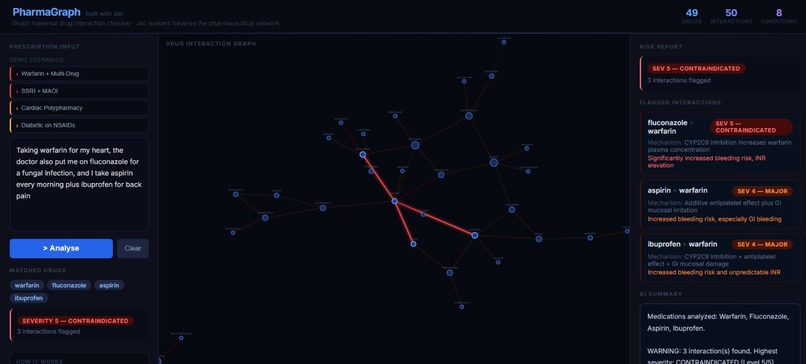
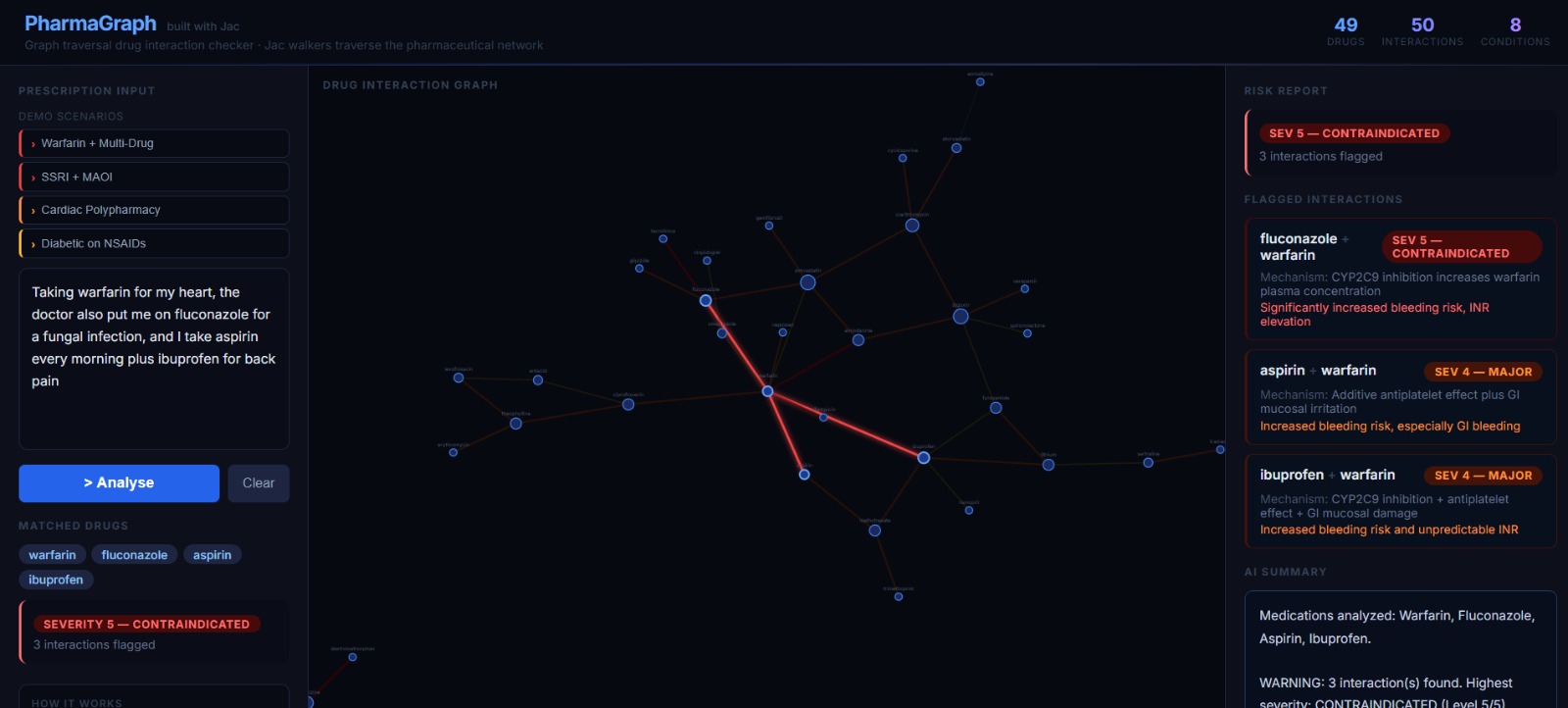
Unsafe prescription-3
Inspiration
Medication errors kill over 7,000 people annually in the US alone. Most don't happen from a single wrong drug — they happen from combinations. A pharmacist missing an interaction buried in a long prescription. A doctor unaware of what a patient was already taking. An elderly patient on six drugs seeing three different specialists, none of whom have the full picture.
The problem is fundamentally a graph problem. Drugs inhibit enzymes. Enzymes metabolise other drugs. Conditions change how drugs are cleared. These are nodes and edges — not rows and columns. Yet most interaction checkers treat it like a lookup table.
We wanted to build a tool where a clinician could paste in a messy, real-world prescription and get a structured safety report in seconds — traceable, explainable, and not dependent on a black box saying "trust me."
What It Does
PharmaGraph accepts free-text prescription input — the kind a real clinician would write, not a structured form — and returns a full drug safety report.
- Parse — NLP extracts drug names and patient conditions from the raw text
- Match — drugs are matched against a knowledge graph by brand name or generic name
- Traverse — graph walkers check every drug pair for known interactions and every drug against the patient's conditions for contraindications
- Report — results are ranked by severity, explained in plain English, and visualised as a live interactive graph
Interactions are scored on a severity scale from \(1\) (minor) to \(5\) (life-threatening). Any pair with severity \(\geq 2\) is flagged. The overall risk level is:
$$\text{RiskLevel} = \max_{(d_i,\, d_j)\, \in\, \text{FlaggedPairs}} \text{severity}(d_i, d_j)$$
The graph visualisation colours edges by severity — dark olive for mild, bright red for critical — so the most dangerous interactions are visually immediate.
How We Built It
The backend is written entirely in Jac (jaclang), a graph-native language where nodes, edges, and walkers are first-class constructs. Drug nodes, Condition nodes, MedProfile nodes, and RiskReport nodes live in a persistent SQLite-backed graph. Walkers traverse that graph to find interaction paths.
The core architectural decision: the graph does the medical reasoning, the LLM does the language. The LLM is called exactly twice per request — once to parse the prescription into structured drug and condition lists, once to write the plain-English summary. Every interaction flag comes from a graph edge, not a model prediction.
The frontend is React 18 + D3 v7, built with Vite 6. Nodes are drugs; edges are interactions weighted and coloured by severity. A force-directed layout surfaces dense interaction clusters naturally. The UI uses AWS Cloudscape components for a clinical, trustworthy aesthetic.
Seed data covers 49 drugs and 50 curated interaction pairs, each tagged with mechanism, clinical effect, and evidence level (established / probable / suspected).
Challenges We Ran Into
Separating graph logic from LLM reasoning
Early versions asked the LLM to reason about whether two drugs interact — which produced plausible-sounding but unverifiable answers. We rebuilt from scratch with the graph as the sole source of truth. The LLM never makes a clinical judgement.
Free-text drug name matching
Real prescriptions use brand names, generics, abbreviations, and misspellings. We built a dual-key lookup — first against brand names, then against generic names — so a drug like "soframicin" still maps correctly to its canonical graph node.
Unrecognised drugs are surfaced explicitly in the report rather than silently dropped, because a missed drug is a patient safety risk.
Jac as a new language
The walker/node/edge model is elegant for graph problems but the ecosystem is still maturing. Several things trivial in Python required reading source code and experimenting.
The payoff was code that reads almost like a clinical decision tree — but the learning curve was real.
Accomplishments We're Proud Of
- Every flagged interaction is fully auditable — traceable to a specific graph edge with a mechanism and evidence level, not a model weight
- Jac's walker traversal maps naturally to medical reasoning; the code structure mirrors how a pharmacist actually thinks through a prescription
- The D3 visualisation makes severity-5 interactions viscerally obvious — a bright red edge between two nodes is harder to ignore than a text warning
- The system handles genuinely messy free-text input and still extracts matched drugs correctly
What We Learned
Graph-native languages are a genuinely different way to model relational problems. Medical knowledge is a graph — drugs share CYP pathways, conditions alter clearance, interactions are edges with weights — and forcing that into a flat database loses structural information that matters.
We also learned that LLMs are best used at the periphery of a system, not the centre. Parsing input and formatting output are exactly what language models are good at. Making safety-critical decisions in the middle of a clinical workflow is not.
The CYP pathway structure is mathematically interesting. A single inhibitor drug shifts the effective concentration of every drug sharing that pathway:
$$ C_{\text{effective}}(d) = C_{\text{dose}}(d) \times \prod_{i} \left(1 + \frac{[I_i]}{K_{i,\text{CYP}}}\right) $$
where $[I_i]$ is the plasma concentration of inhibitor $i$ and $K_{i,\text{CYP}}$ is its inhibition constant for the shared pathway.
PharmaGraph's current model approximates this — a full pharmacokinetic layer is the natural next step.
What's Next for PharmaGraph
Larger dataset
Expand to the full DrugBank or FDA interaction database (currently 50 curated pairs).
Dosage-aware severity
The same interaction can be minor at $\leq 10\text{ mg}$ and critical at $\geq 40\text{ mg}$; severity should be a function of dose, not just drug pair.
Patient history
Persist prior prescriptions and flag interactions introduced by newly added medications against an existing regimen.
EHR integration
HL7 FHIR input so it plugs into clinical workflows without manual copy-paste.
CYP pathway inference
Derive probable interactions from shared enzyme pathways even when no direct pair evidence exists, clearly labelled as inferred rather than established.


Log in or sign up for Devpost to join the conversation.