-
-
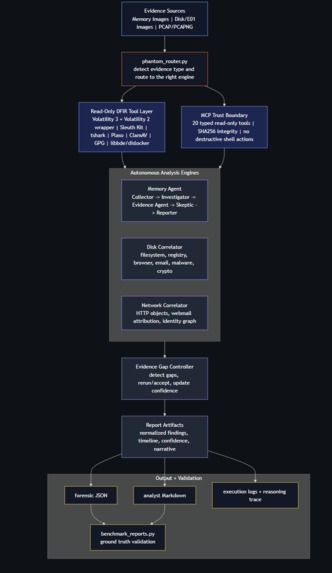
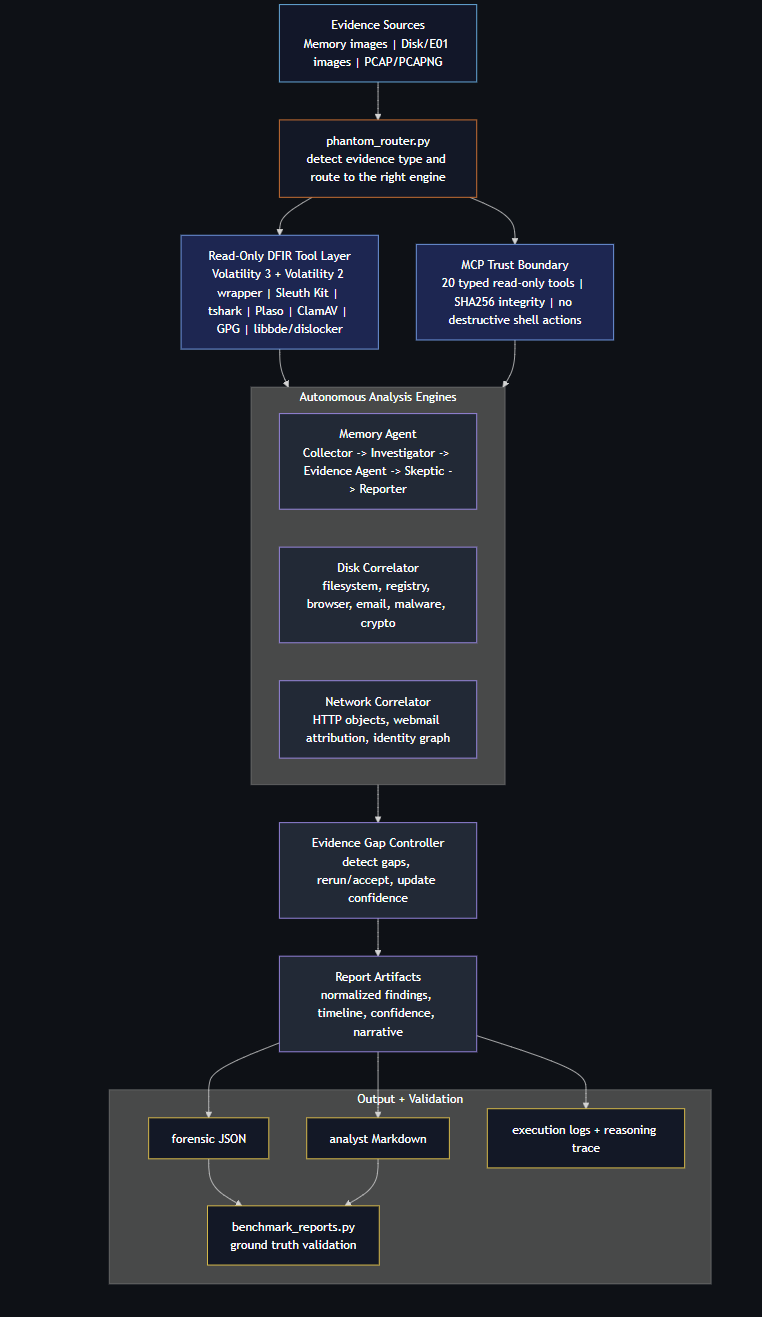
PHANTOM DFIR routes memory, disk, and PCAP evidence through read-only tools, self-correction, and traceable validated reports.
Inspiration
Modern attacks move faster than traditional incident response. Public reporting has shown attacker breakout times measured in minutes, while defenders often still need to collect evidence, choose tools, run plugins, correlate artifacts, and write a reliable narrative.
The problem is not only speed. It is trust.
Many AI-assisted DFIR workflows perform single-pass analysis. They may flag legitimate software as malicious, miss cross-source evidence, or present weak assumptions as conclusions.
A senior incident responder does not work that way. They challenge findings, demand corroboration, clear false positives, and explain why a conclusion is justified.
That gap inspired PHANTOM DFIR:
What if a forensic AI agent could argue with itself before presenting findings?
PHANTOM DFIR was built to behave less like a raw tool runner and more like an autonomous investigative workflow: collect evidence, generate hypotheses, validate them, challenge them, correct mistakes, and produce traceable reports.
What it does
PHANTOM DFIR stands for Parallel Hypothesis Analysis with Multi-agent Threat Hunting Overlay Network.
It is an autonomous digital forensics and incident response framework for memory, disk, and network evidence. PHANTOM routes evidence to the correct analysis engine, runs forensic tooling, validates findings, performs self-correction, and generates reports with traceable evidence.
PHANTOM supports:
- Memory images
- Disk and E01 images
- PCAP / PCAPNG network captures
- Offline LLM-assisted reasoning with Ollama
- Rule-based fallback when no LLM is available
- Read-only MCP forensic tooling
- Ground-truth benchmark validation
Core Workflow
PHANTOM uses an adversarial investigation model:
| Component | Responsibility |
|---|---|
| Router | Detects evidence type and routes memory, disk, or PCAP evidence to the correct engine |
| Collector | Runs forensic collection using Volatility 2/3, Sleuth Kit, tshark, strings, YARA-style rules, and other tools |
| Investigator | Generates hypotheses from deterministic rules and optional LLM reasoning |
| Evidence Agent | Re-queries specific processes, IOCs, identities, services, files, or network artifacts |
| Skeptic | Challenges weak findings, clears false positives, and requires corroboration |
| Evidence Gap Controller | Detects missing evidence and decides whether to rerun, continue, or accept |
| Reporter | Produces JSON, Markdown, execution logs, reasoning traces, and benchmark-ready output |
Key Capabilities
- Memory analysis using Volatility 2 and Volatility 3
- Disk artifact extraction from filesystem, registry, browser, email, malware, crypto, prefetch, UserAssist, and Shimcache evidence
- PCAP analysis with HTTP objects, webmail attribution, identity extraction, and communication role ranking
- Harassment attribution logic for sender, victim, alias, and internal IP correlation
- Crypto evidence recovery for AES, GPG, and BitLocker workflows
- MITRE ATT&CK-style mapping from validated indicators
- MCP-based read-only forensic tool access
- SHA256 evidence integrity verification
- Self-correction and false-positive clearing
- Benchmark validation against known ground truth
Benchmark Results
PHANTOM was tested across memory, disk, crypto, and PCAP evidence using a ground-truth benchmark framework.
| Case | Evidence Type | Result |
|---|---|---|
| Ali Hadi memory | Memory | Fully reproduced |
| SysInternals challenge | Disk | Fully reproduced |
| CFReDS data leakage | Disk | Fully reproduced |
| Ali Hadi Encrypt Them All | Disk / Crypto | Fully reproduced |
| Nitroba harassment attribution | PCAP | Fully reproduced |
Overall benchmark summary:
| Metric | Result |
|---|---|
| Cases scored | 5 |
| Fully reproduced | 5 / 5 |
| Average adjusted score | 97% |
| Verdict matches | 5 / 5 |
The benchmark framework validates findings against known ground truth instead of relying only on subjective report quality.
Self-Correction Example
In memory analysis, PHANTOM may initially identify a suspicious executable or IOC from a single source.
Instead of immediately escalating it, the workflow performs adversarial validation:
Investigator:
“This process or artifact may indicate suspicious activity.”Evidence Agent:
Re-query process path, service metadata, command line, network state, and supporting plugins.Skeptic:
“This finding is weak or benign unless corroborated by independent evidence.”
If the evidence does not support the claim, PHANTOM clears or downgrades the finding.
This prevents the system from treating every suspicious string, YARA hit, or tool name as a confirmed compromise.
Case Example: Nitroba PCAP Attribution
PHANTOM’s PCAP engine extracted and correlated webmail identity evidence from network traffic.
It identified:
- Suspect account:
jcoachj@gmail.com - Threat alias:
the_whole_world_is_watching@nitroba.org - Victim:
lilytuckrige@yahoo.com - Internal IP:
192.168.15.4 - Case classification: harassment attribution
- Verdict: high-confidence attribution
The tool also corrected earlier over-attribution by separating:
- Primary suspects
- Primary victims
- Communication participants
- Background identities
- Session/tracking/request tokens
This reduced noise from unrelated browsing artifacts and ranked identities by evidentiary proximity instead of raw frequency.
How we built it
Core Stack
- Python 3.10 for orchestration and forensic pipelines
- LangGraph for multi-agent memory investigation
- Ollama / qwen2.5:14b for optional offline reasoning
- Volatility 2 and Volatility 3 for memory forensics
- Sleuth Kit for disk image analysis
- tshark for PCAP extraction
- ClamAV, YARA-style rules, GPG, libbde/dislocker for malware and crypto workflows
- FastAPI + Uvicorn for the MCP server
- JSON / Markdown reports for traceable outputs
- Ground-truth benchmark framework for validation
Architecture Guardrails
PHANTOM uses structural safety controls rather than relying only on prompts.
1. Read-Only Evidence Handling
Evidence is treated as read-only. The tool hashes evidence and avoids modifying original images.
2. MCP Trust Boundary
The MCP server exposes typed read-only forensic tools. It does not provide destructive shell actions.
3. SHA256 Integrity Verification
Evidence is hashed during analysis so reports can reference evidence identity and integrity.
4. Bounded Self-Correction
Self-correction loops have maximum iteration limits to avoid runaway analysis.
5. Rule-Based Fallback
If the LLM is unavailable, PHANTOM still runs deterministic collection, validation, skepticism, and reporting.
Challenges we ran into
1. False Positives from Weak Indicators
Early versions treated isolated suspicious strings or tool names as stronger evidence than they deserved.
We fixed this by requiring corroboration from multiple sources and by adding a skeptic stage that downgrades under-supported findings.
2. Identity Over-Attribution in PCAPs
The first PCAP attribution engine extracted many webmail identities but ranked unrelated browsing artifacts too highly.
We improved this by adding identity validation, role separation, recipient/sender logic, and attribution chains.
3. Sender vs Victim Confusion
Threat recipients were initially being ranked as suspects because they appeared frequently in threatening communications.
We added role precedence:
- Sender/authenticated account evidence increases suspect confidence
- Recipient/target evidence increases victim confidence
- Recipient-only identities cannot outrank sender identities
4. Crypto Case Runtime
Deep disk and crypto analysis can be expensive, especially when scanning large extracted filesystem caches.
We added clearer progress messages, skip options for expensive modules, and benchmark workflows so long runs are explainable and reproducible.
5. LLM Output Reliability
LLMs can return vague hypotheses or malformed structured output.
PHANTOM validates LLM-generated indicators, rejects vague IOCs, and falls back to rule-based investigation when needed.
Accomplishments that we're proud of
- Built a working autonomous DFIR pipeline across memory, disk, crypto, and PCAP evidence
- Added self-correction and skeptic review instead of single-pass conclusions
- Fully reproduced 5 benchmark cases with a 97% average adjusted score
- Correctly attributed the Nitroba harassment case to
jcoachj@gmail.com - Recovered Ali Hadi Encrypt Them All crypto evidence, including AES, GPG, and BitLocker artifacts
- Added execution logs, reasoning traces, and benchmark validation
- Built a read-only MCP forensic tool server
- Added graceful no-LLM mode for offline deterministic analysis
- Preserved evidence safety with read-only workflows and SHA256 integrity checks
What we learned
Forensic AI needs skepticism
Detection is not enough. The system must challenge its own conclusions before reporting them.Evidence proximity matters
The best identity is not always the most frequent identity. It is the identity closest to the action being investigated.Ground truth matters
Benchmarking against known cases makes accuracy measurable and prevents overclaiming.Rules and LLMs work best together
Deterministic forensic logic provides stability, while LLM reasoning helps with narrative, gap analysis, and hypothesis generation.Read-only architecture is essential
Forensic systems must protect evidence integrity by design.
What's next
- Add Zeek and Suricata enrichment for deeper network analysis
- Expand multi-source correlation across memory, disk, and PCAP from the same incident
- Add more benchmark cases from public forensic datasets
- Improve timeline fusion across filesystem, registry, browser, memory, and network artifacts
- Add richer report provenance so every finding links directly to the tool output that produced it
- Improve runtime controls for very large disk and crypto evidence

Log in or sign up for Devpost to join the conversation.