
Inspiration
As a bioinformatician, I've spent years working with genomic data and watching clinicians struggle with one of medicine's most preventable problems: prescribing medications that are genetically wrong for the patient in front of them. A patient who can't metabolize codeine receives no pain relief — or worse, a patient who carries HLA-B*57:01 is prescribed abacavir and suffers a potentially fatal hypersensitivity reaction.
These aren't rare edge cases. An estimated 90% of people carry at least one actionable pharmacogenomic variant. Yet at the point of care, clinicians rarely have time to cross-reference CPIC guidelines, check DDInter interaction databases, and interpret diplotype-to-phenotype mappings — all while a patient is waiting.
I built PGx-Guardian to solve this in real time, using voice.
What it does
PGx-Guardian is a clinical decision support voice agent. A clinician speaks naturally:
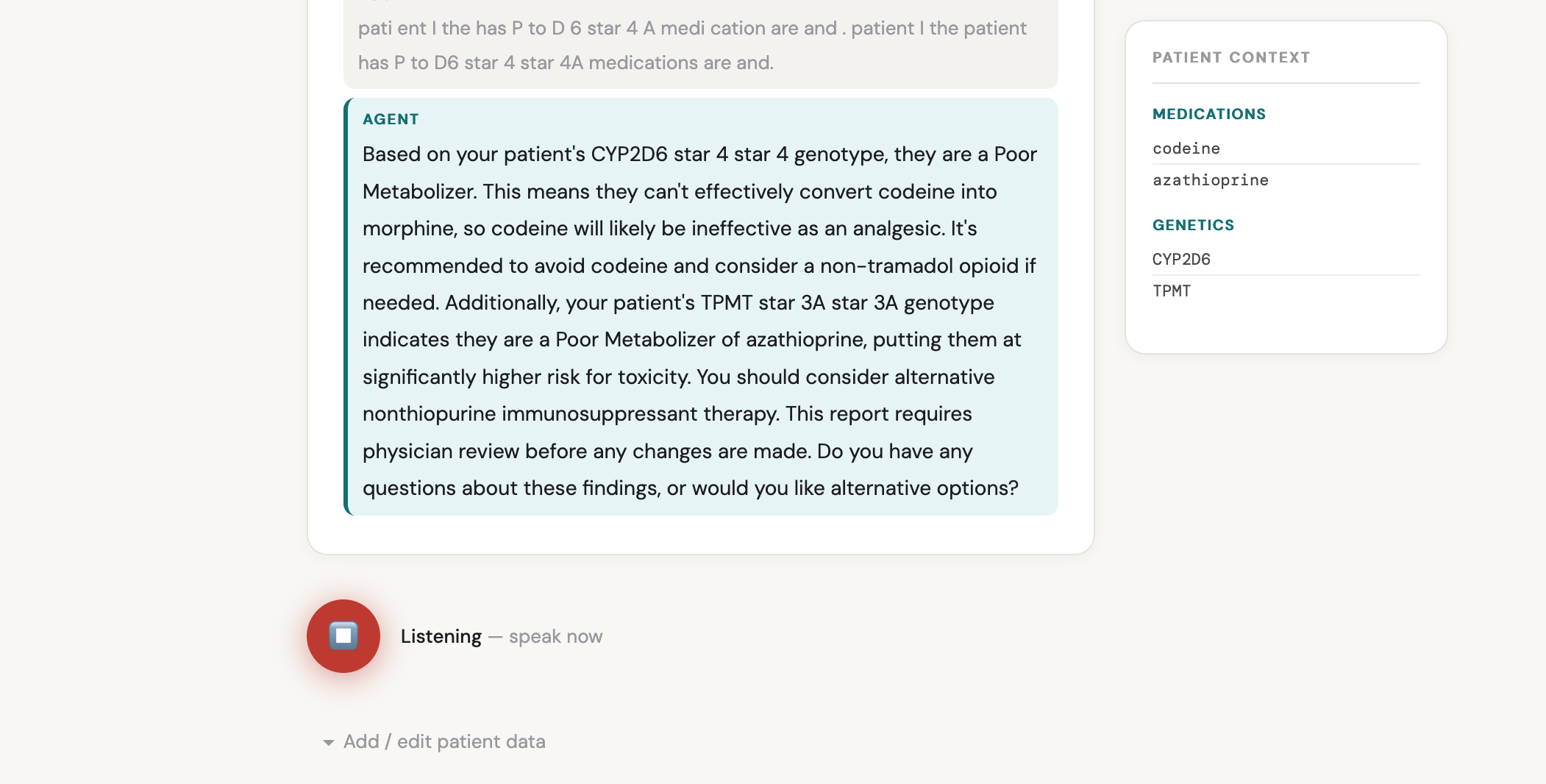
"CYP2D6 star 4 star 4, CYP2C19 star 2 star 2. Patient is on clopidogrel, codeine, omeprazole, and fluoxetine."
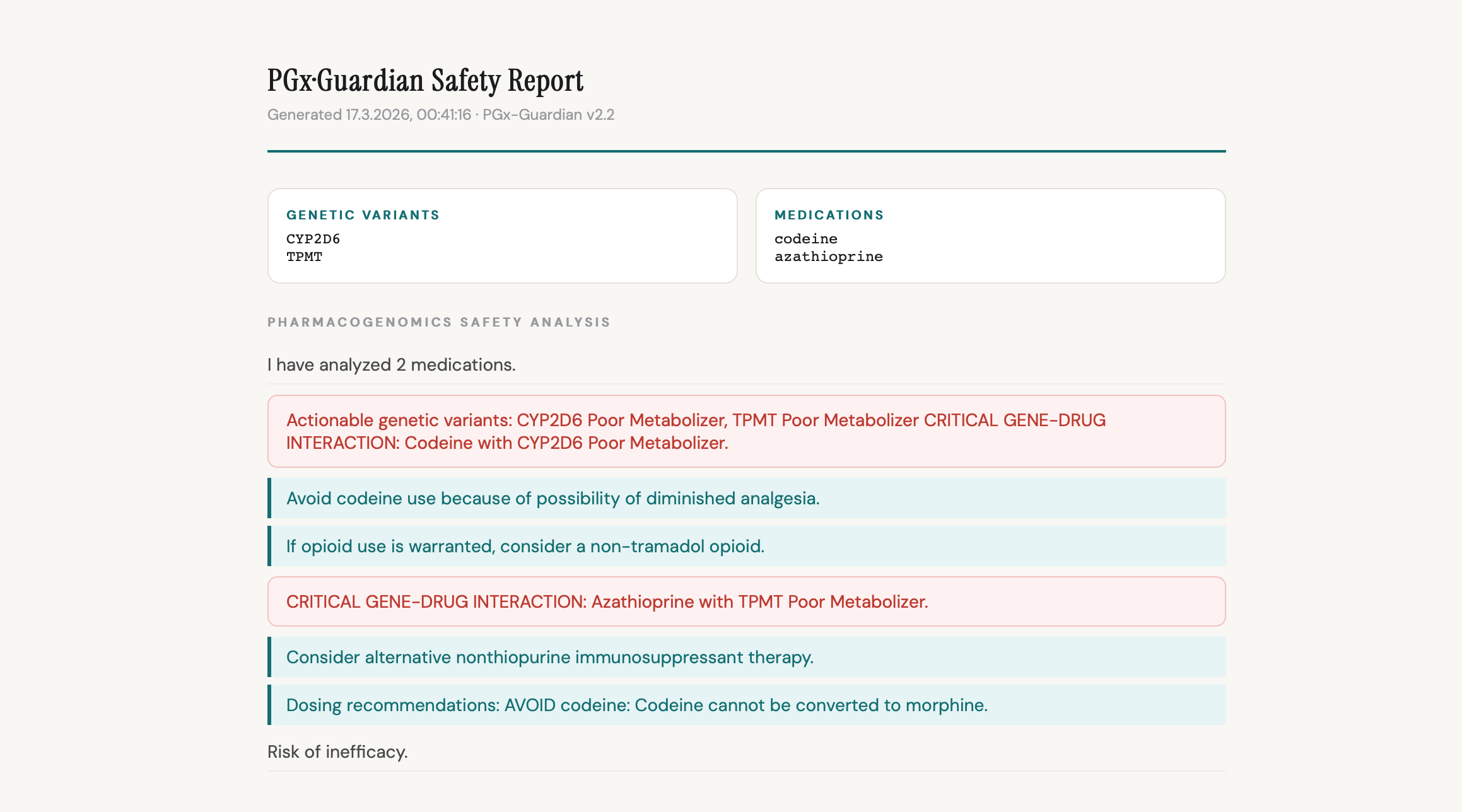
Within seconds, PGx-Guardian delivers a complete pharmacogenomics safety report — spoken aloud and displayed visually — covering:
- Critical gene-drug interactions (e.g. CYP2C19 Poor Metabolizer + clopidogrel = markedly reduced platelet inhibition, high cardiovascular risk)
- Genetically-escalated drug-drug interactions (baseline DDI scores elevated when pharmacogenomics confirms the risk pathway)
- CPIC-grounded dosing recommendations (AVOID / REDUCE / MONITOR with full rationale)
- Conversational follow-up — the clinician can ask "why is this dangerous?" or "what's the alternative?" without re-running the analysis
How I built it
The system runs on Google ADK 1.26.0 with Gemini 2.5 Flash Native Audio for real-time bidirectional voice interaction. A FastAPI WebSocket server streams PCM audio from the browser to Gemini and audio chunks back. The analysis pipeline is multi-layered:
- Genotype normalization engine — handles ASR-mangled allele notation (e.g. "star four star four" →
*4/*4, "H B 57" →HLA-B: *57:01/*57:01) with a 6-step flexible matching strategy - PHENOTYPE_MAP — 42,000+ diplotype-to-phenotype mappings generated from the CPIC API
- dgi_analyzer.py — queries Supabase (
cpic_cache+mechanism_knowledge_base) for gene-drug recommendations using a 3-tier priority lookup - ddi_checker.py — checks 222,383 DDInter drug-drug pairs in memory, with genetic escalation logic
- Hardcoded clinical recommendations for HLA-B/A (3 alleles), G6PD (5 oxidative drugs), and RYR1/CACNA1S (malignant hyperthermia) where CPIC uses allele-presence rather than diplotype-to-phenotype mapping
The frontend is a single voice_ui.html file with real-time transcript display, colour-coded safety report rendering, patient context sidebar, and auto-reconnect with session replay.
Deployed on Google Cloud Run (europe-west1, min-instances=1).
Challenges I faced
ASR mangling of clinical notation was the hardest problem. Gemini ASR transcribes "HLA-B star 57 colon 01" as "H B 57" or "HB 5701". I built a multi-stage normalization pipeline that handles 15+ ASR variant patterns — ordinal conversion, star notation, HLA allele padding, gene name disambiguation (CYP 2 C 19 → CYP2C19), and DIRECT_PHENOTYPES shortcuts so clinicians can say "HLA-B abacavir risk" instead of spelling out the allele.
CPIC API pagination — the API returns at most 500 rows per gene by default. I discovered this when common diplotypes like *4/*4 were missing from the database. Fixed by implementing PostgREST Range header pagination, ultimately loading 42,288 diplotypes across 16 genes.
Concurrent tool call suppression — early versions had Gemini speak a confirmation before calling the tool, but the audio stream would win over the tool call. The fix was explicit instruction: "Call analyze_medications immediately — do not speak first, do not wait."
DPYD activity scoring — CPIC uses activity scores for DPYD rather than standard diplotypes. I wrote dpyd_patch.py to inject hardcoded clinically-relevant DPYD diplotypes after the main sync.
HLA and immune genes — CPIC's HLA recommendations are allele-presence based, not diplotype-based, so cpic_cache returns empty for HLA-B + abacavir. I implemented a HLA_HARDCODED dict in dgi_analyzer.py with full CPIC-grounded recommendations for all 3 HLA-B alleles, HLA-A, G6PD, RYR1, and CACNA1S.
What I learned
Building this taught me that the gap between genomic data and clinical action is fundamentally a UX problem, not a data problem. The CPIC guidelines exist. The interaction databases exist. What was missing was a zero-friction interface that works at the speed of a clinical conversation.
Voice — with all its ASR noise and imprecision — turned out to be the right modality. A clinician can speak a patient's genotype in 10 seconds. No form to fill, no dropdown to navigate, no copy-paste from an EHR. The system meets them where they are.
Gemini's native audio capabilities made this possible. The real-time bidirectional streaming, the built-in VAD for natural barge-in, and the reasoning quality that correctly handles ambiguous spoken allele notation — none of this would have worked with a traditional ASR + LLM pipeline.
Gene coverage
19 pharmacogenomics genes: CYP2D6, CYP2C19, CYP2C9, CYP2B6, CYP3A4, CYP3A5, CYP1A2, TPMT, NUDT15, DPYD, SLCO1B1, UGT1A1, NAT2, HLA-B, HLA-A, G6PD, RYR1, CACNA1S, VKORC1, IFNL3
Built for the Gemini Live Agent Challenge · #GeminiLiveAgentChallenge
Accomplishments that I'm proud of
The genotype normalization engine is the technical achievement I'm most proud of. It correctly resolves spoken allele notation under real ASR noise conditions — something I didn't think was tractable when I started. "H B 57" reliably becomes HLA-B: *57:01/*57:01. "See why fee 2D6 star 4 star 4" becomes CYP2D6: *4/*4. The 6-step flexible matching strategy with prefix matching, sub-allele precision stripping, and HLA single-allele expansion handles the long tail of ASR variation without a single hardcoded regex per gene.
I'm also proud that all four demo scenarios produce clinically correct reports — not approximately correct, but matching CPIC guideline recommendations exactly. The compound warfarin recommendation that combines CYP2C9 Poor Metabolizer AND VKORC1 High warfarin sensitivity into a single dose-reduction advisory is particularly satisfying. That's the kind of multi-factor reasoning that genuinely helps a clinician.
Finally, the conversational follow-up capability — asking "why is abacavir dangerous for this patient?" after the report and getting a coherent mechanistic explanation without re-running the analysis — makes this feel like a real clinical colleague rather than a lookup tool.
What's next for PGx·Guardian
Live camera integration — streaming webcam frames to Gemini at 1 FPS so the agent can read a printed lab report or VCF file held up to the camera, extracting genotypes visually without any manual input.
EHR integration — connecting to HL7 FHIR endpoints so the agent can pull genotype and medication data directly from the patient record, eliminating even the voice input step for routine checks.
Expanded gene panel — adding pharmacogenomics genes beyond the current CPIC panel, including emerging variants in oncology pharmacogenomics (DPYD in chemotherapy dosing is already covered; TPMT/NUDT15 for thiopurines is covered; UGT1A1 for irinotecan is next).
Population-specific guidance — CPIC guidelines increasingly include population-stratified recommendations (e.g. HLA-B*15:02 screening is recommended specifically in patients of Southeast Asian ancestry). Adding ethnicity-aware recommendations would significantly increase clinical utility.
Prospective prescribing mode — instead of analyzing an existing medication list, the clinician describes a patient they are about to prescribe for, and PGx-Guardian proactively flags which drug classes to avoid before the prescription is written.
Built With
- cpic-api
- ddinter
- dgidb
- fastapi
- gemini-2.5-flash
- gemini-live-api
- google-adk
- google-cloud-build
- google-cloud-run
- html
- postgresql
- python
- rxnorm
- supabase
- websockets

Log in or sign up for Devpost to join the conversation.