-
-
Landing
-
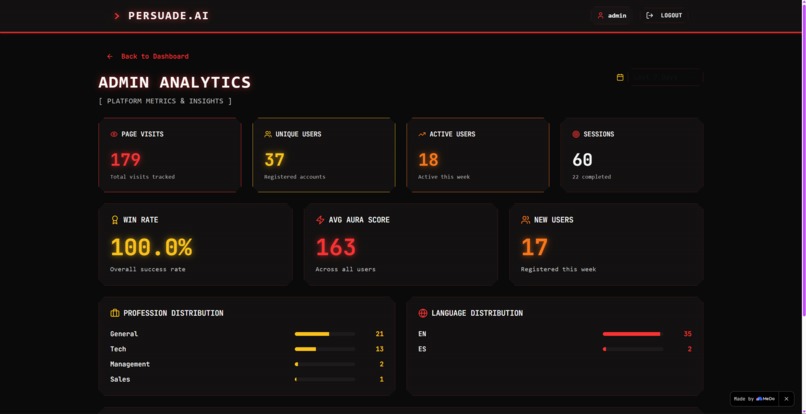
Analytics
-
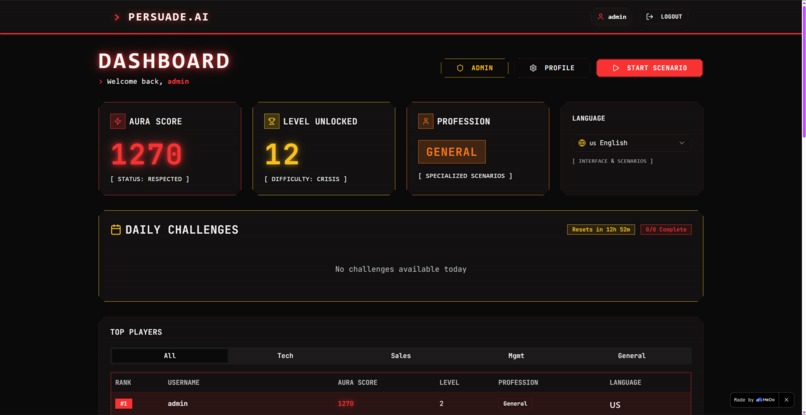
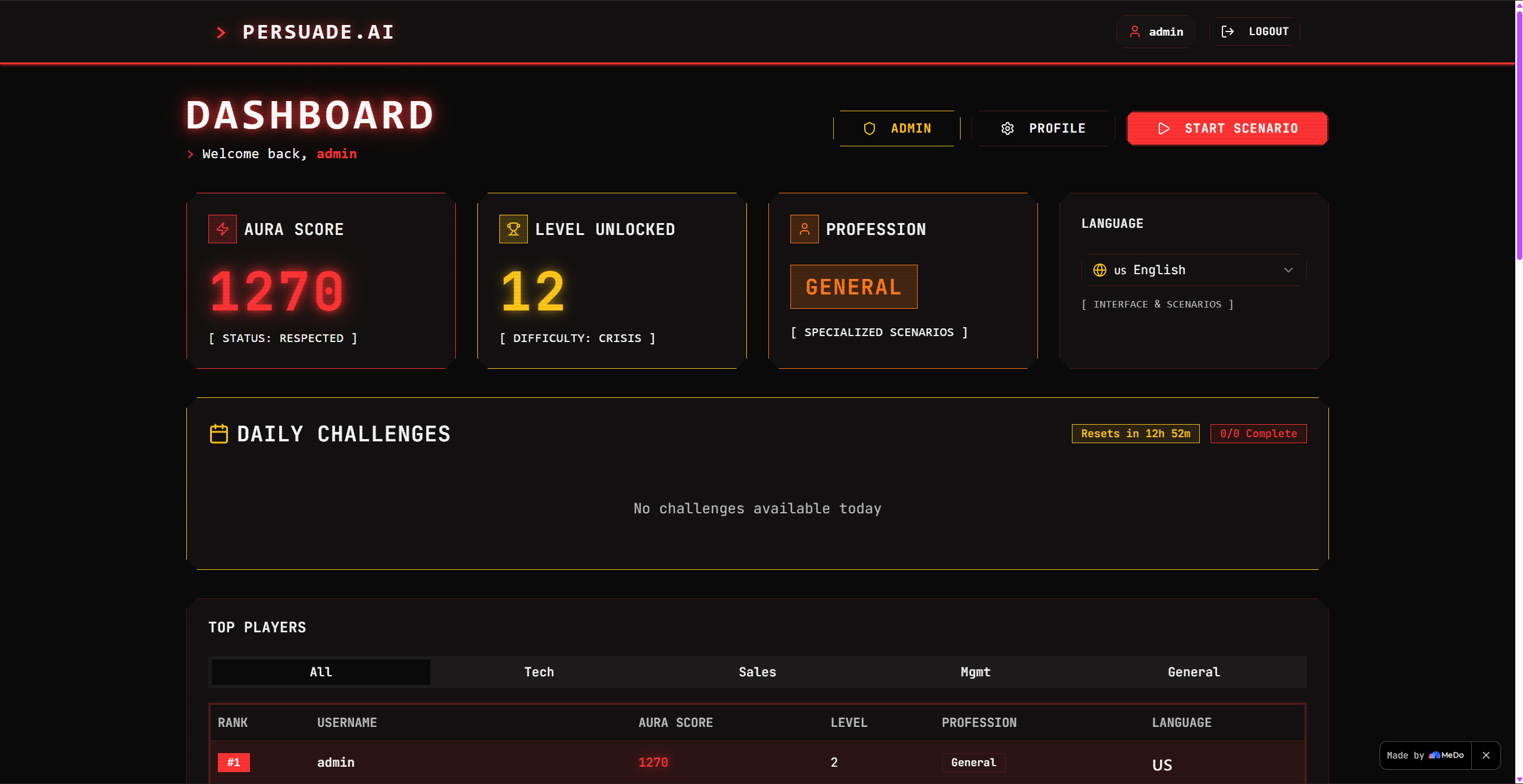
Dashboard
-
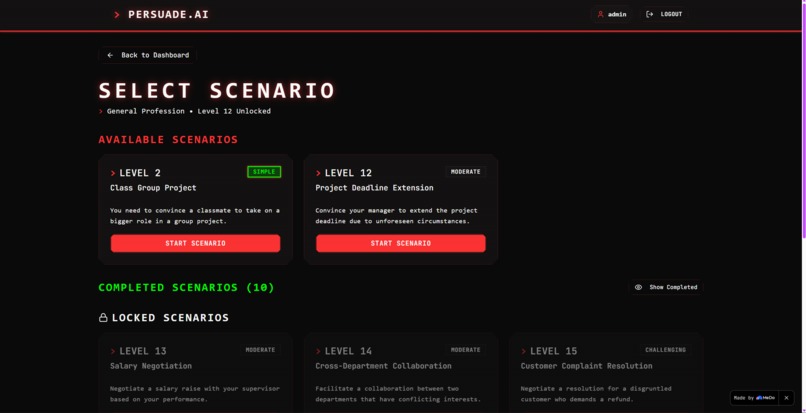
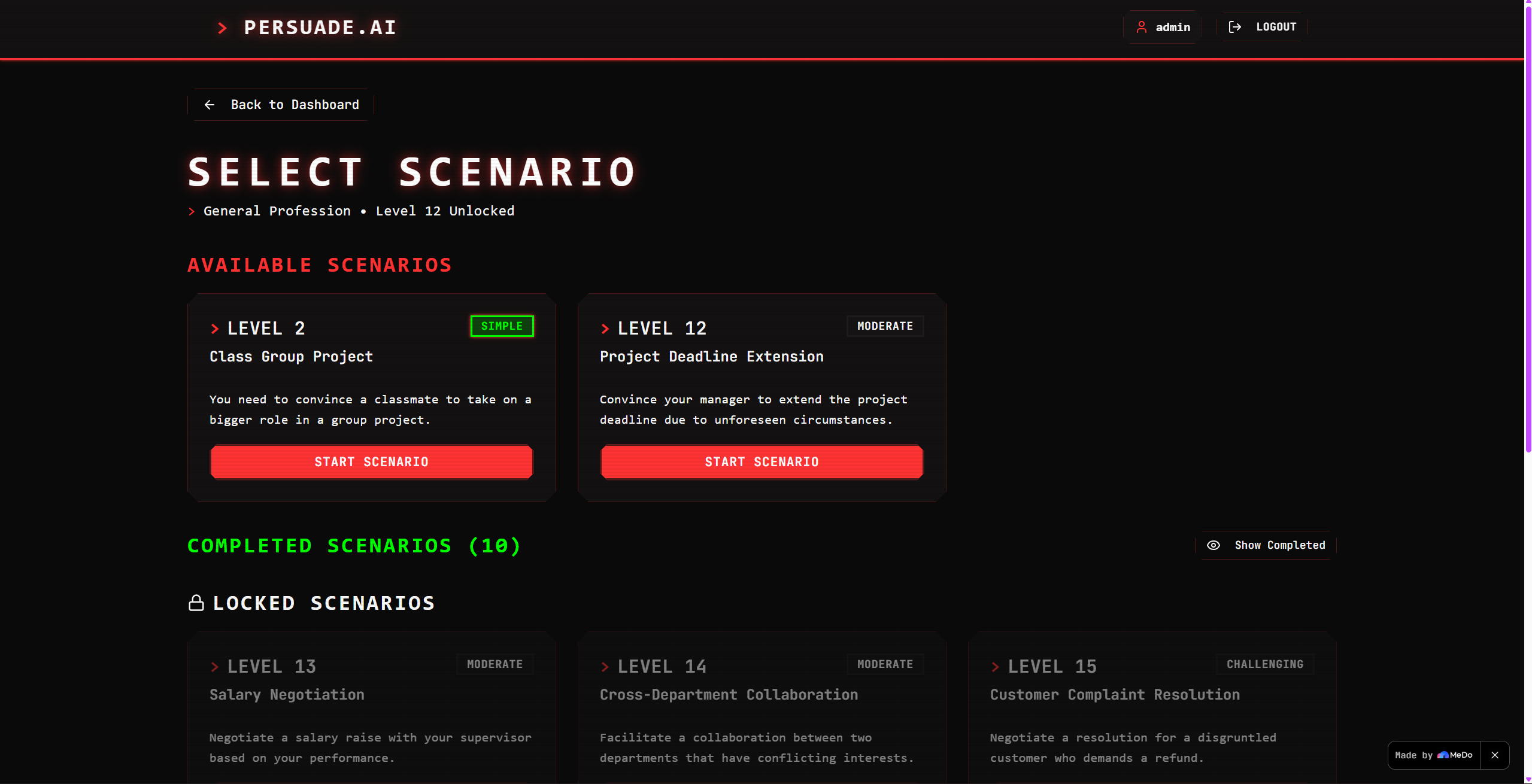
Game Senerios
-
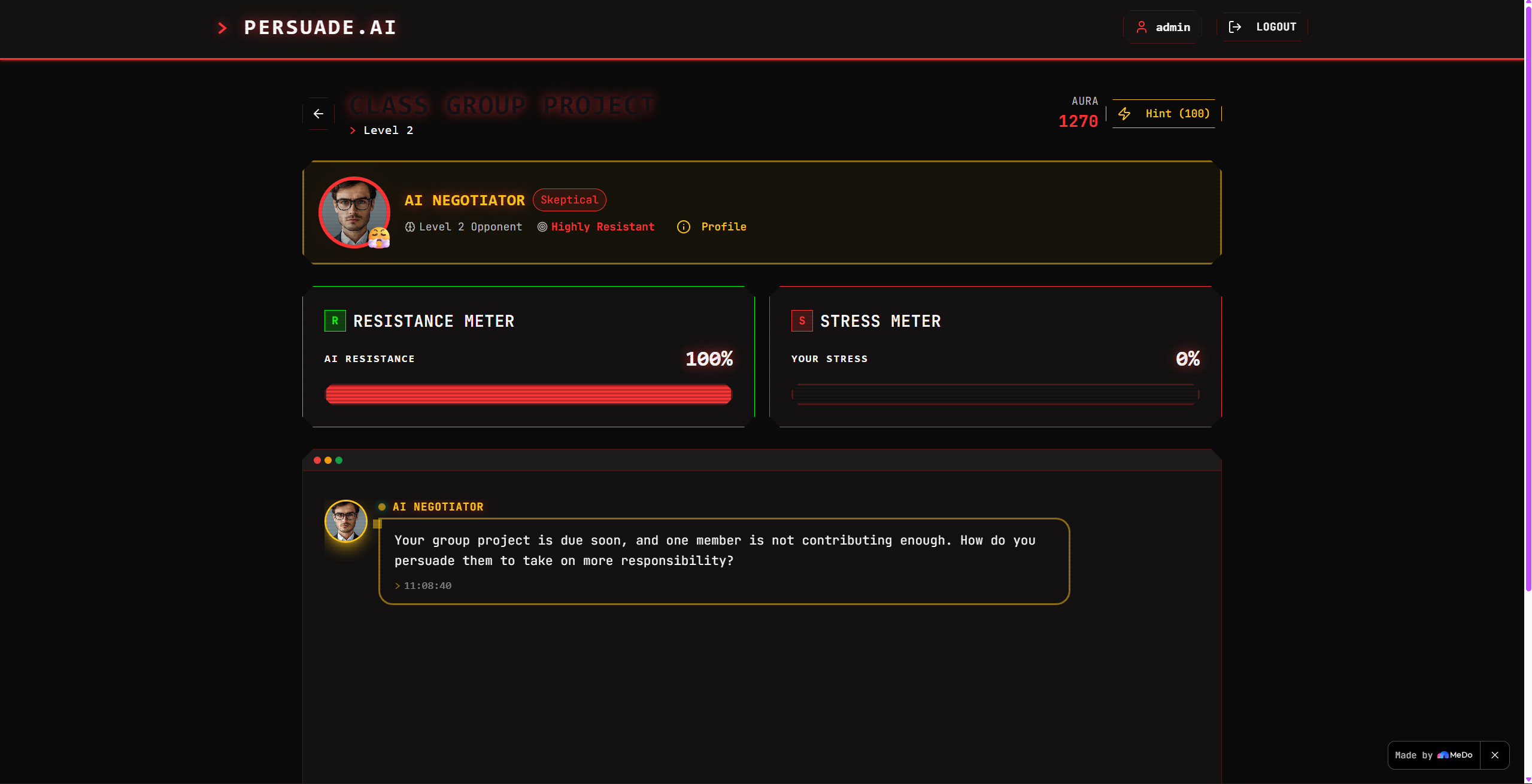
Sample Senerio
-
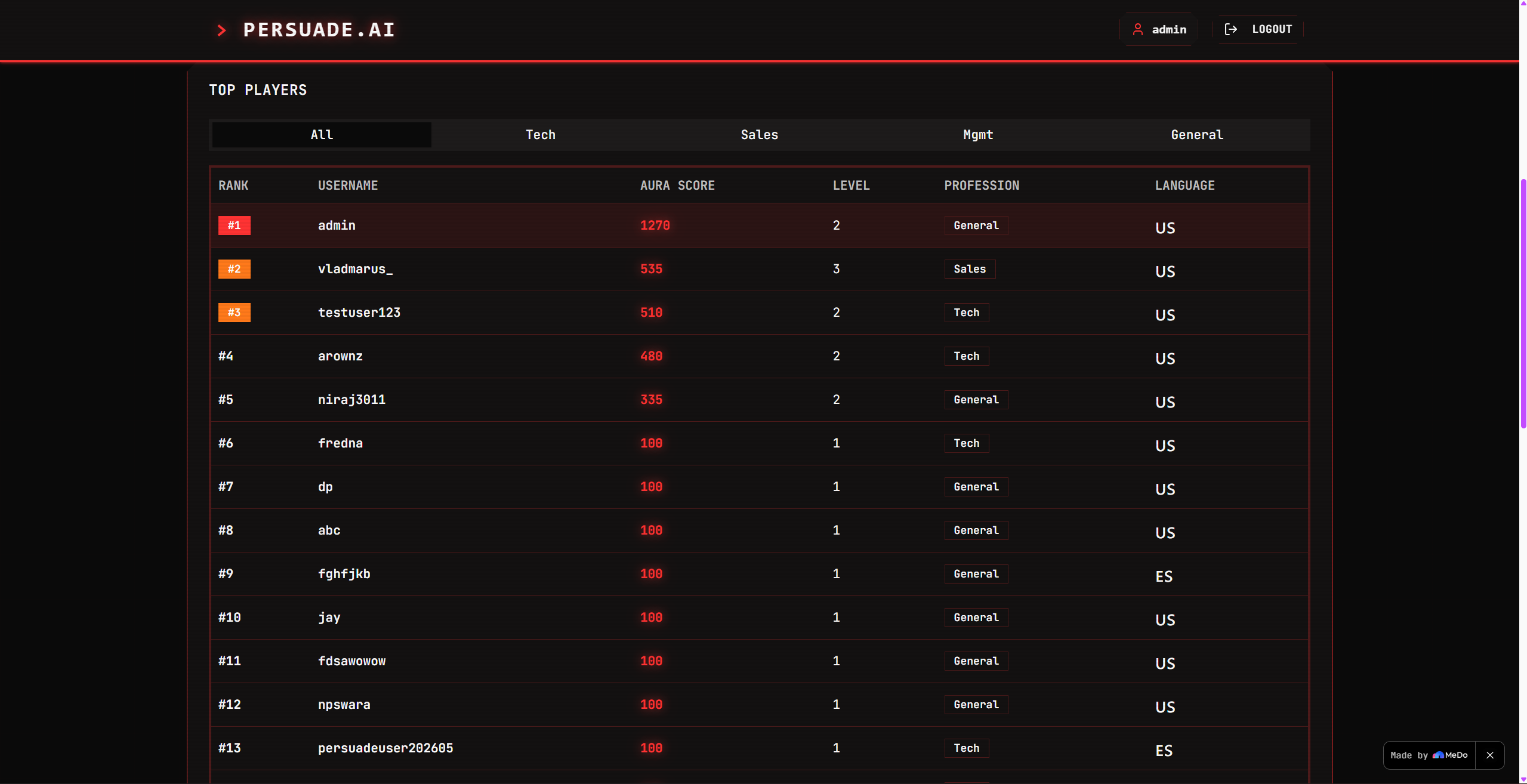
Leaderboard
-
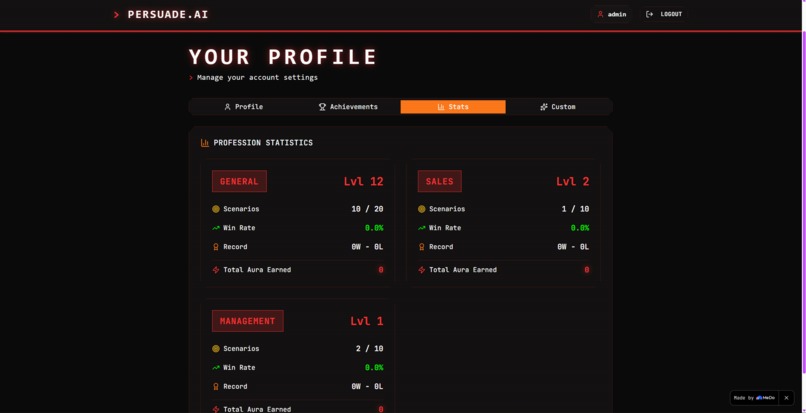
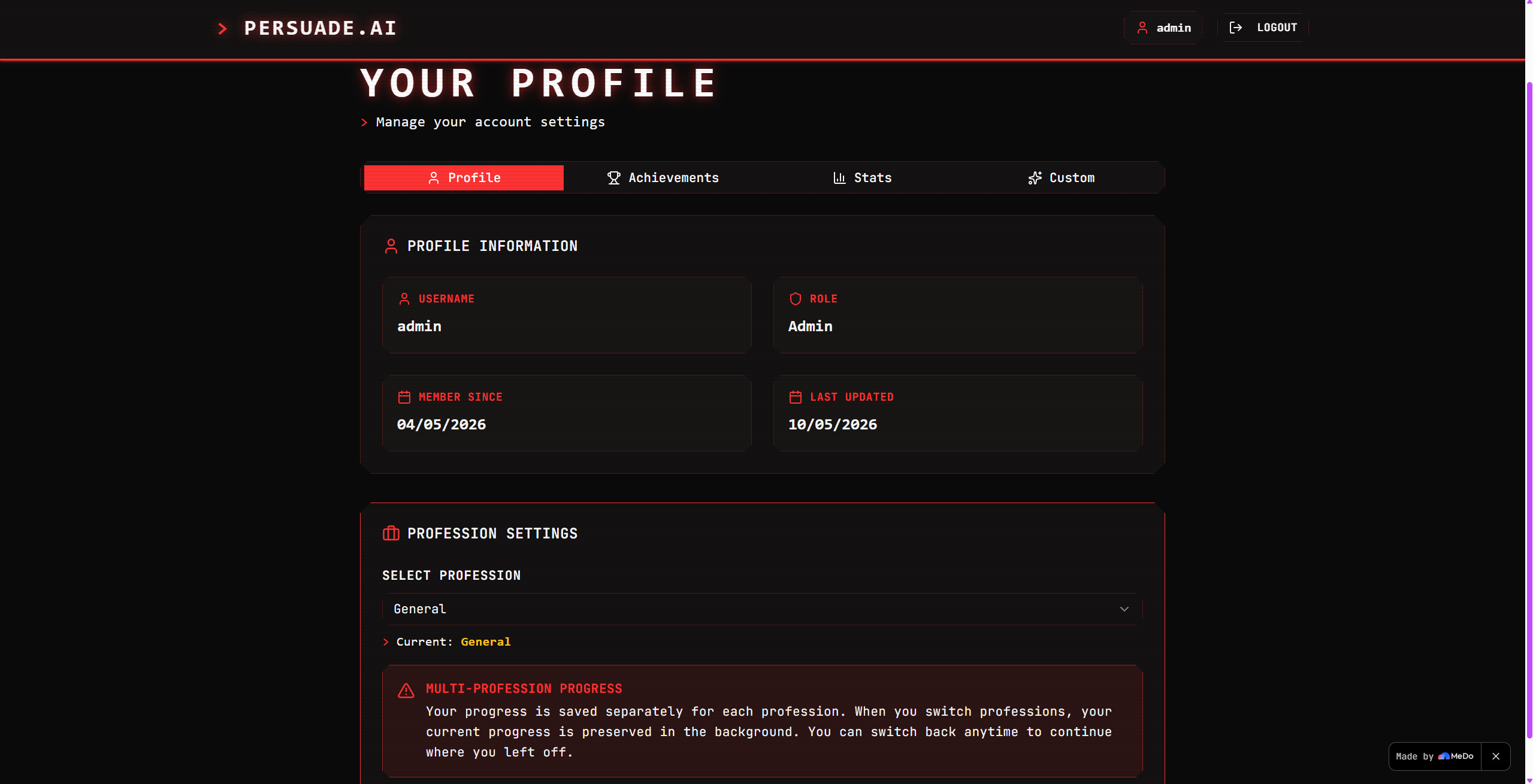
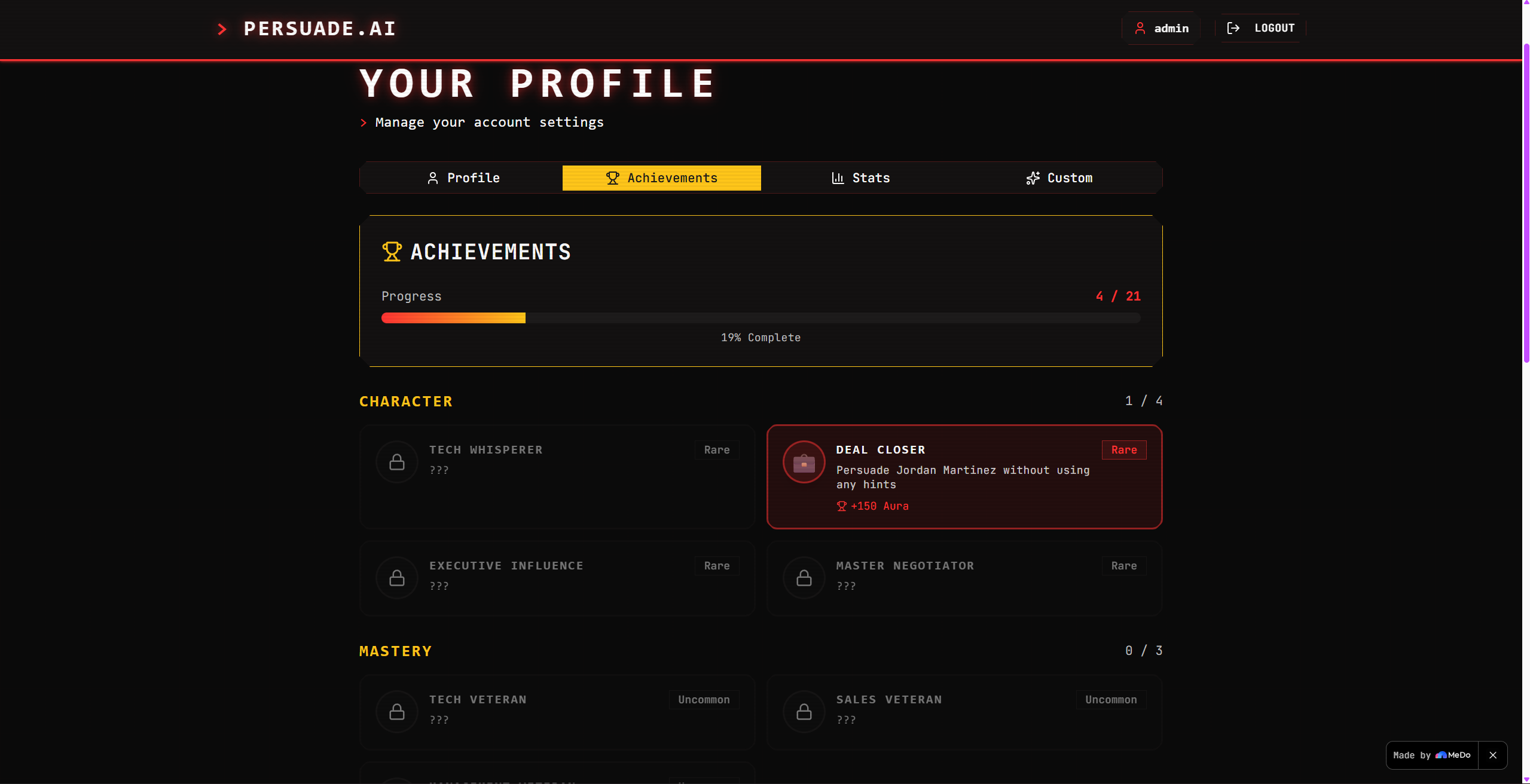
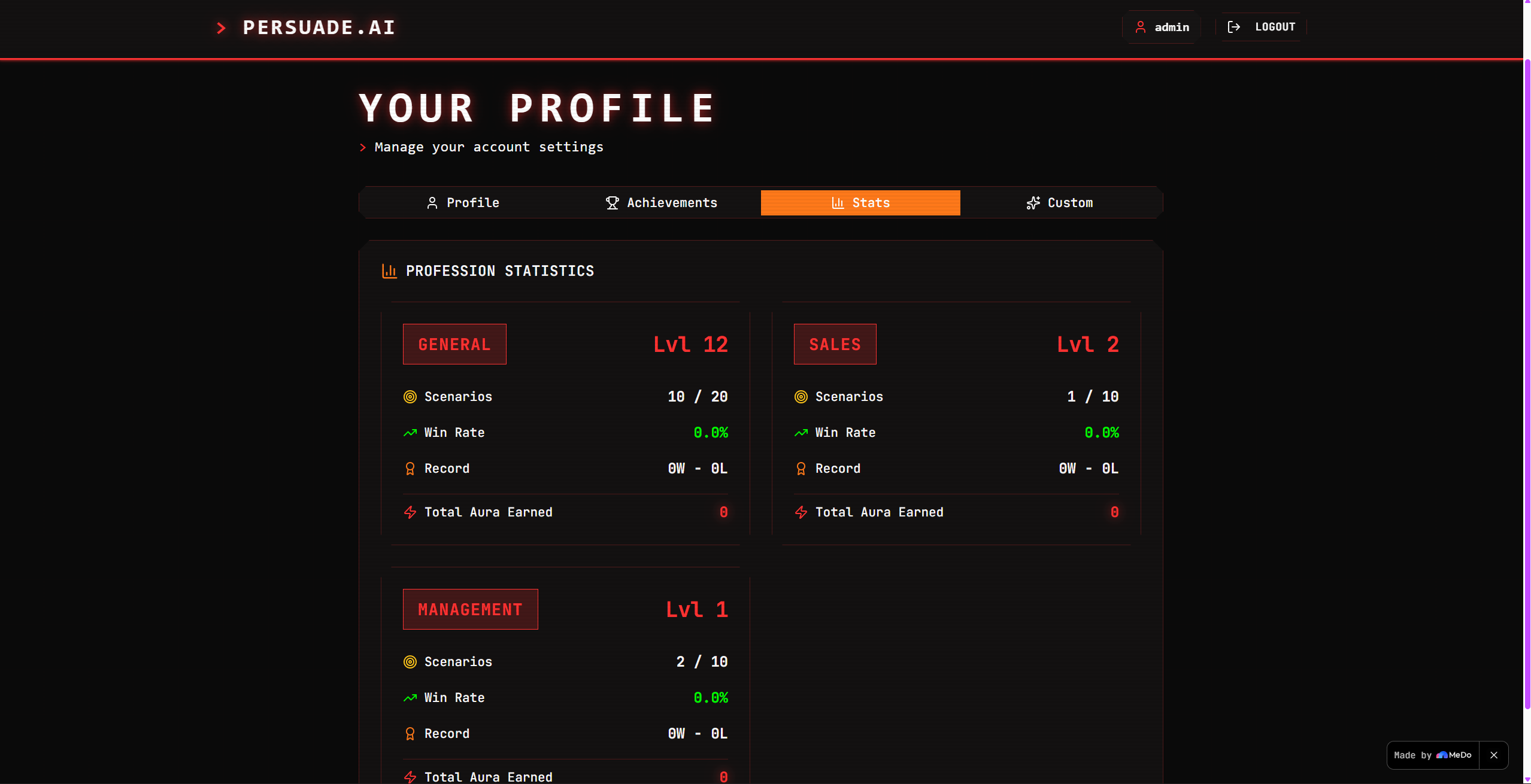
User profile
-
-
🔥 PERSUADE.AI — The Persuasion Simulator
Your words are your weapon. Your psychology is your power. Your Aura is your legacy.

💡 Inspiration
It started with a failed negotiation.
A teammate of ours — a brilliant engineer — had been passed over for a promotion twice. Not because of skill. Not because of output. But because when the moment came to advocate for himself in a room full of stakeholders, he froze. He couldn't persuade. He didn't know how. And worse — he had nowhere to practice.
That conversation stuck with us. We started asking around. Sales reps who knew the product cold but couldn't close. Managers who understood the problem but couldn't get buy-in. Tech leads who had the right answer but couldn't win the room.
The pattern was everywhere: persuasion is arguably the highest-leverage skill in a professional's life, and it is almost never formally trained.

The existing solutions felt broken:
- Corporate workshops are expensive, generic, and awkward
- YouTube videos teach theory with zero feedback
- Role-playing with a colleague is embarrassing and hard to schedule
We kept coming back to one question: What if practicing persuasion felt like playing a video game?
What if you could step into an arena, face a resistant AI opponent, get pushed back on, adapt in real time — and then receive a detailed psychological breakdown of exactly what you did and why it worked or didn't?
That question became PERSUADE.AI.

🛠️ How We Built It
Architecture Overview
PERSUADE.AI is built around a dual-agent AI system that separates the opponent from the evaluator — two distinct Claude API calls with completely different roles.
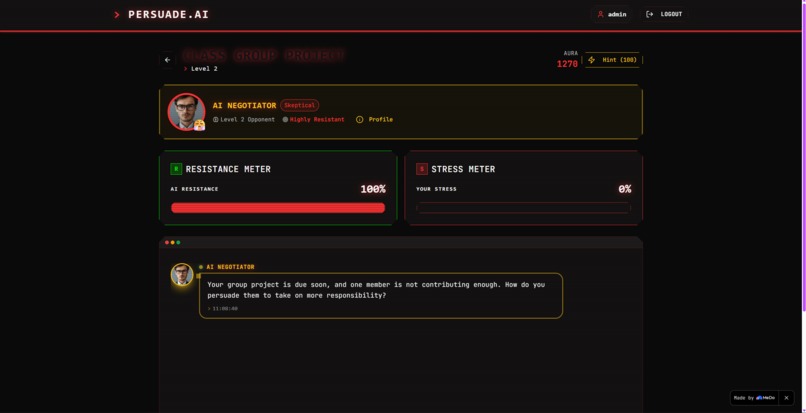
Agent A — The Interrogator is the NPC the user faces. Its system prompt is calibrated by profession (Tech, Sales, Management, General) and shaped by the user's current Aura Score $\Omega$:
$$ \text{Agent A tone} = \begin{cases} \text{skeptical, dismissive} & \text{if } \Omega < 150 \ \text{neutral, guarded} & \text{if } 150 \leq \Omega \leq 500 \ \text{friendly, respectful} & \text{if } \Omega > 500 \end{cases} $$
This creates a dynamic difficulty curve that responds to real performance — the better you get, the more the AI respects you before you even start.
Agent B — The Judge never speaks to the user. It monitors the transcript silently after each session, produces the psychological breakdown, determines win/loss, and calculates the Aura delta:
$$ \Delta\Omega = \begin{cases} \lfloor 20 + 30 \cdot r \rfloor & \text{win, where } r \in [0, 1] \text{ is performance rating} \ -10 & \text{loss} \end{cases} $$
The psychological report decomposes the user's communication into four dimensions — Logic, Empathy, Authority, and Scarcity — each expressed as a usage percentage with concrete examples pulled from their own words.
The Aura Engine
Aura is more than a score. It's a reputation system that creates real psychological stakes. Starting at 100, it compounds across sessions:
$$ \Omega_{n+1} = \max(0,\ \Omega_n + \Delta\Omega_n) $$
The max(0, ...) floor prevents Aura from going negative — instead triggering a warning state with a glitch effect animation, which signals to the player they're in dangerous territory without punishing them permanently.
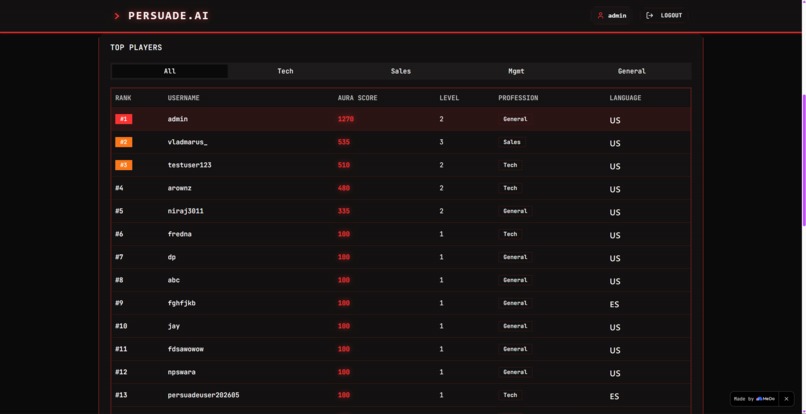
The leaderboard ranks players globally by $\Omega$, with language flags indicating which region they practice from — making it genuinely competitive across language barriers.
Multi-Language & Voice Input
Voice input uses the Web Speech API with SpeechRecognition, initialized with the user's selected language code. The transcript streams into the input field in real time — the user sees their words form as they speak, exactly like a live caption.
All AI responses from Claude are prompted in the selected language, meaning the entire experience — UI labels, scenario descriptions, NPC dialogue, and psychological report — is localized end-to-end without a translation service layer.
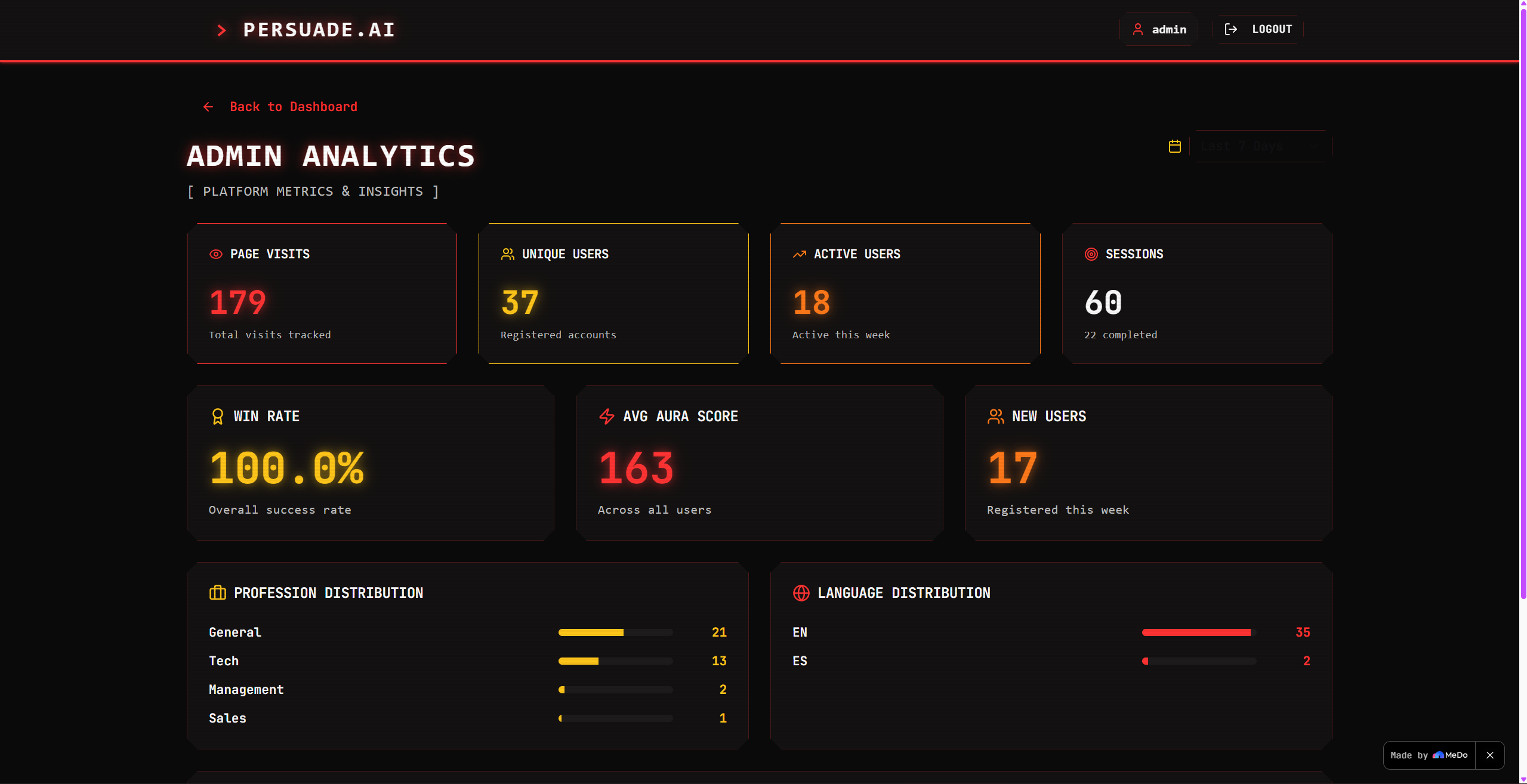
Admin Analytics
Every user action generates a timestamped event stored server-side:
- Page visits (with page type and session ID)
- Scenario start and completion events
- Voice input toggle activations
- Login and logout events for session duration
The admin dashboard aggregates these across three time windows (Today / 7 days / 30 days / custom) and presents profession distribution, language distribution, average Aura, and completion rate — all with the same retro pixel aesthetic as the main app.
📚 What We Learned
1. Dual-agent prompting is underrated
Most people think of Claude API as one conversation. Splitting it into two independent agents — one that plays a character and one that evaluates — unlocked a level of depth that a single prompt could never achieve. The Judge can be brutally honest precisely because it's never in the conversation.
2. Gamification changes the emotional stakes of learning
When we tested early prototypes without the Aura system, users treated losses casually. The moment we added the score, the leaderboard, and the tone shift based on Aura — something changed. Users cared. They replayed scenarios. They read the psychological report. The game layer made the learning layer matter.
3. The psychology framework was the hardest thing to design
Deciding what the Judge evaluates — and how to express it usefully — took more iteration than any technical feature. We landed on Logic, Empathy, Authority, and Scarcity because they map to the real influence frameworks used in negotiation literature (Cialdini, Fisher & Ury, Voss), but are concrete enough to give actionable feedback in a short post-game report.
⚔️ Challenges We Faced
Getting the AI to stay in character under pressure
The Interrogator agent would occasionally break character when the user's argument was strong enough. A user would make a genuinely compelling case and the NPC would essentially concede mid-conversation rather than maintaining structured resistance. We solved this with explicit persona-lock instructions in the system prompt, separating the character's emotional state (which can soften) from the character's willingness to break (which is governed by the Resistance Meter, not free-form Claude judgment).
Designing the psychological report to be useful, not just impressive
Early versions of the Judge's output were verbose and vague — lots of words, little signal. We redesigned the prompt to force the Judge to output percentages with examples — specific sentences the user actually said, labeled by technique. This made the report feel less like an AI-generated summary and more like coaching notes from a real observer.
Making the Aura system feel fair
If users feel a score system is arbitrary, they stop caring about it. We had to make $\Delta\Omega$ feel proportional to effort — not just a flat reward for winning. Tying the performance rating $r$ to specific behaviors evaluated by the Judge (how many technique types were used, how early resistance dropped, how many pushbacks were overcome) made wins feel earned and losses feel instructive rather than punishing.
🔥 Built With
MeDo .Openai API · Web Speech API · Web Audio API · Canvas API · JavaScript · HTML5 · CSS3 · Node.js
PERSUADE.AI was built during the hackathon by a team that believes the most important skill most people never practice is the one that determines almost everything else. We hope you feel the heat.
🔥 Step into the arena.
Built With
- ai
- medo
- openai
- react
- supabase
- vite


Log in or sign up for Devpost to join the conversation.