-
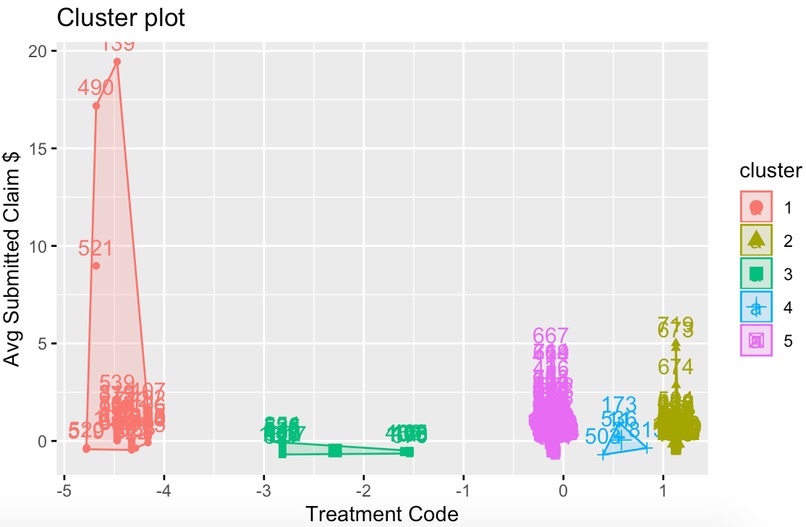
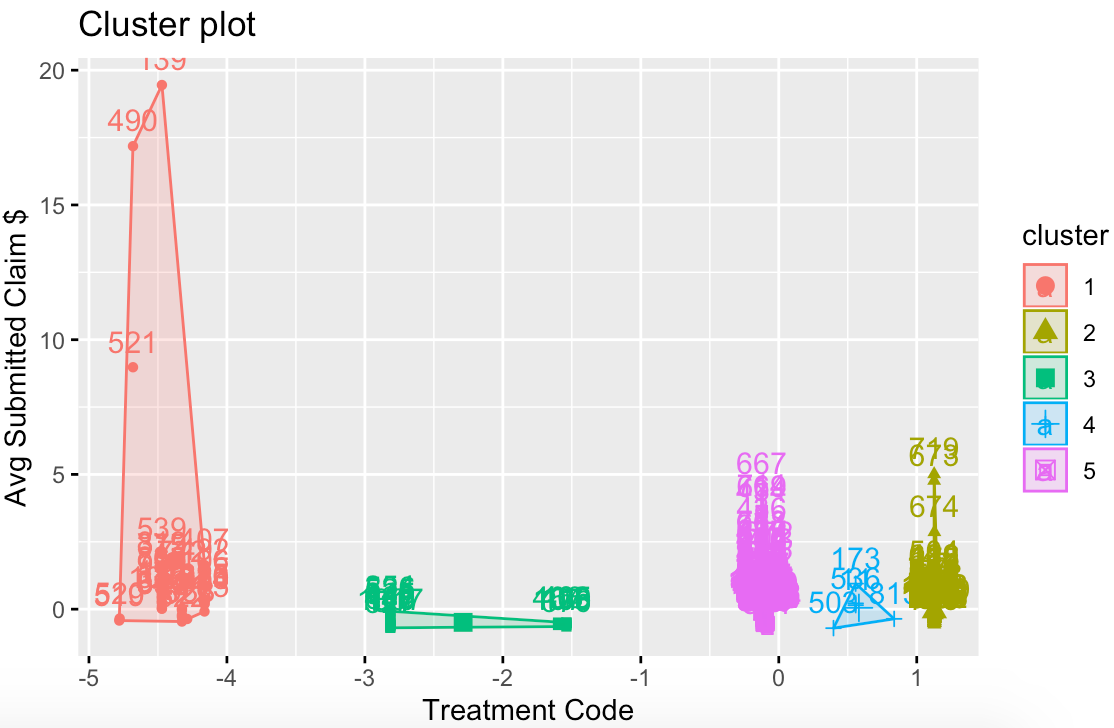
Cluster plot showing the correlation between a doctor and his/her insurance claim charges, indicating likelihood of committing fraud.
Inspiration
Healthcare insurance providers and the federal government suffer from enormous amounts of insurance fraud every year. In the year 2017, the US Government spent more than $600 billion on Medicare payments. Out of these, more than $60 billion in payments were later proven to be fraudulent , constituting almost 10% of the entire sum. This leakage of healthcare funds is a severe misallocation of resources that negatively impacts insurance providers, physicians and taypayers. We believe that this issue needs to be addressed urgently.
What it does
Perspicio is a tool that uses Machine Learning to improve the detection of healthcare fraud. Specifically, the algorithm analyzes publically available healthcare payment data to group physicians and healthcare service providers into individual risk groups. This facilitates the detection of fraudulent claims and augments the often opaque claim review process.
How we built it
For the datasets, we downloaded the "General Payment Data" for a certain resporting year using the "Data Explorer Tool" on the Center for Medicare & Medicaid Services (CMS) website. This publically-available dataset tracks all payments made by a certain physician in the given timeframe, including the credentials of the physician, the HCPCS code of the medical procedure provided and the $ amount of the claim. For proof-of-concept, we decided to focus on a dataset of ophthalmology payments in California, given the recent healthcare fraud case involving several prominent ophthalmologists in Southern California. Further, we incorporated the physician's Google Review Score and Yelp Rating into the dataset as additional predictors for a physician's fraud risk.
The ML algorithms were built via R. We tested both Supervised and Unsupervised Learning for our dataset. For Supervised Learning, we referred to the data on known healthcare fraud offenders provided by California State Board of Optometry Citations and Disciplinary Action website. For Unsupervised Learning, we plotted several predictors against another (e.g. HCPCS code vs. $ amount of claim) to identify possible clusters and indicators for high-risk individuals.
Challenges we ran into
Even though all Medicare payment data is accessible online, finding reliable information on disciplinary misconducts of individual physicians is very complicated. Unlike the data on the CMS website, there is no all-in-one data set and list in detail all disciplinary misconducts by physicians in a given timeframe. So, one would need to find individual datasets for each discipline, which complicates the processes and decreases the operational efficiency. Having a comprehensive dataset on this topic would allow for a better training environment for the ML algorithm, as more suitable and universal predictors can be identified.
Accomplishments that we're proud of
Although we based the ML algorithm on relatively basic and straightforward predictors, the Supervised Learning achieved an accuracy of >90% in grouping known fraud offenders into the "high-risk individual" cluster. This methodology is also immensely scalable, as all Medicare payment data up until 2019 to-date is available on the CMS website. Once established, this tool can be adjusted and transferred to other healthcare providers as well.
What's next for Perspicio
Following the proof-on-concept, we hope to fine-tune the algorithm and achieve an even higher accuracy by incorporating additional training data. Further, we would like to look into suitable predictors for other insurance providers such as Medicaid or private insurance companies. We would appreciate insights from individuals and organizations already involved in the field of healthcare fraud detection & prediction in order to increase the feasibility of Perspicio and expand its accessibility to relevant industry sectors.


Log in or sign up for Devpost to join the conversation.