-
-
-
-
-
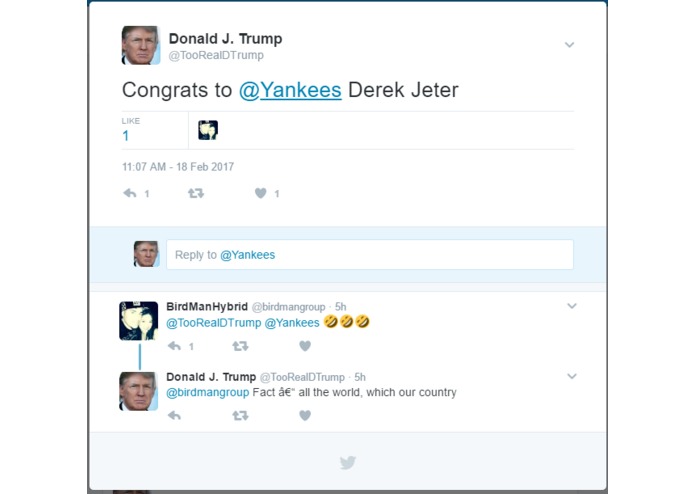
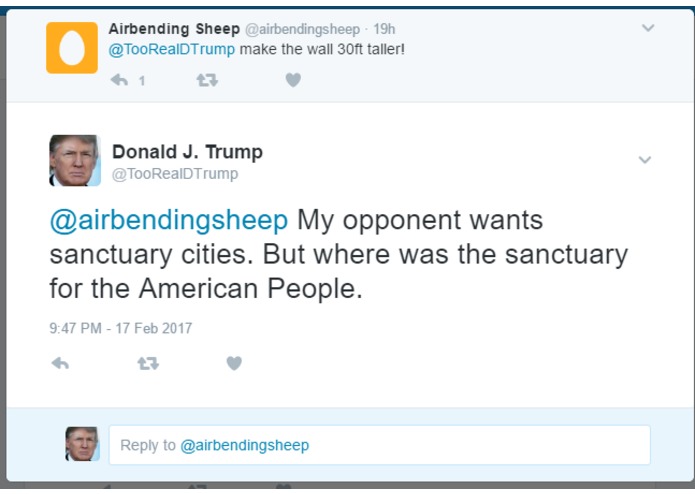
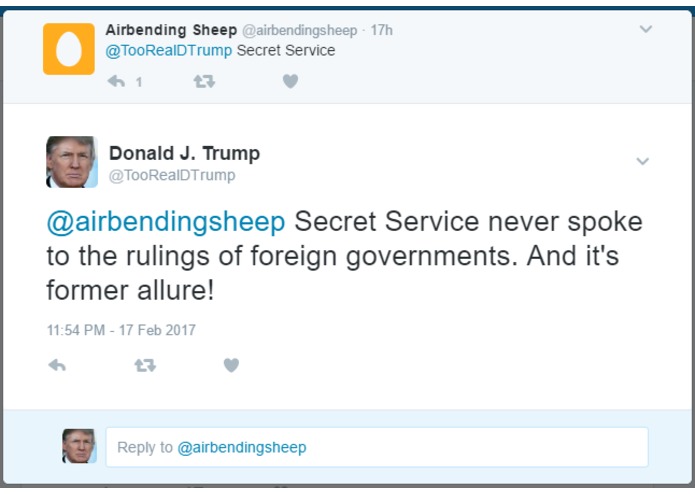
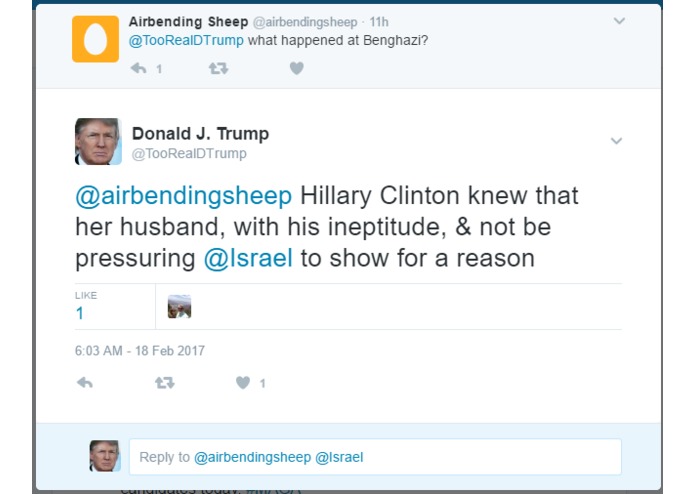
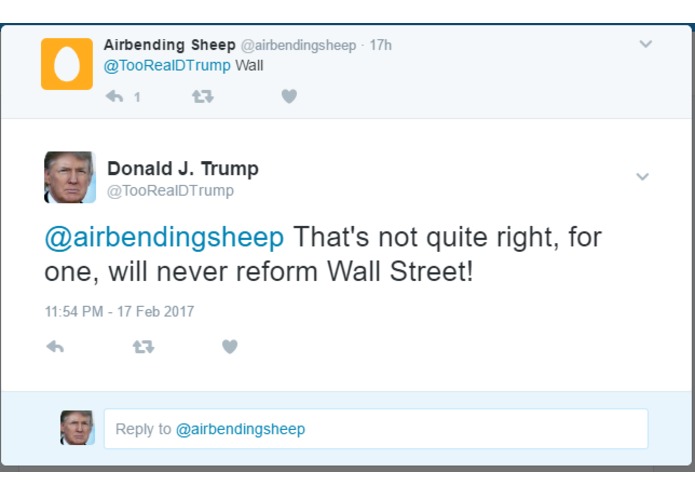
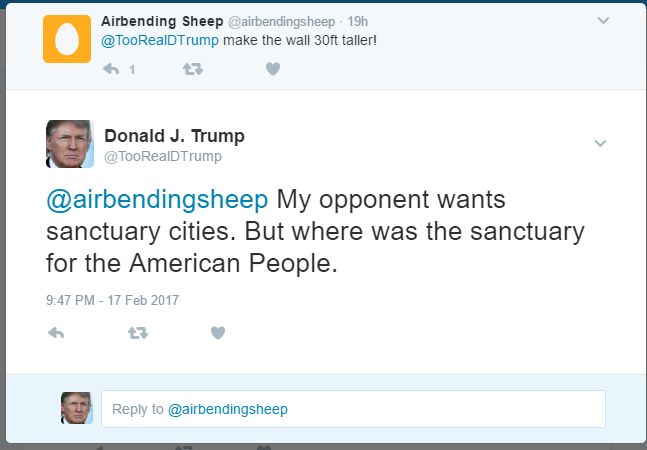
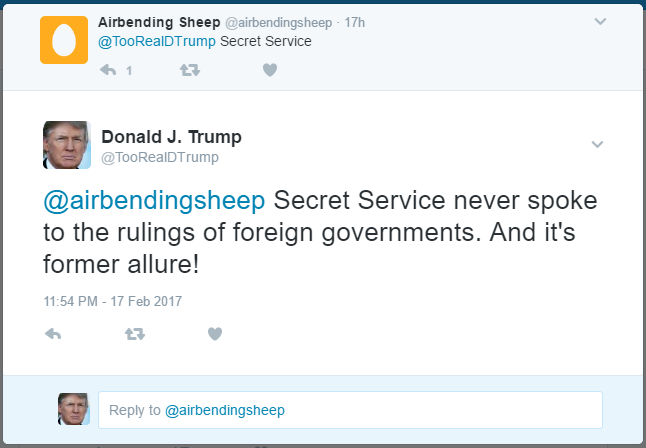
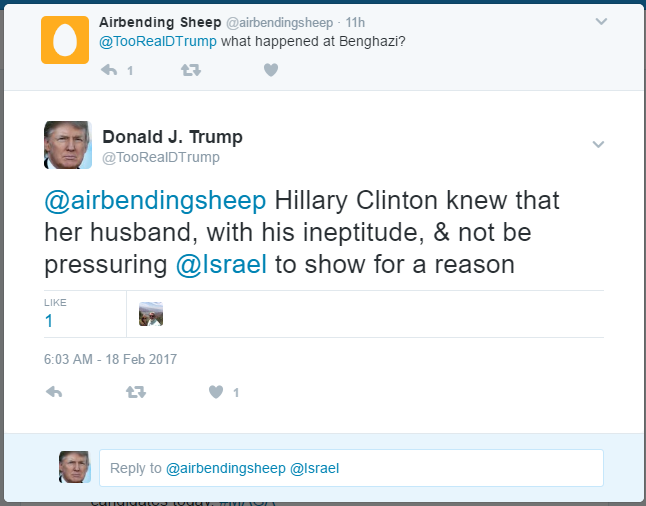
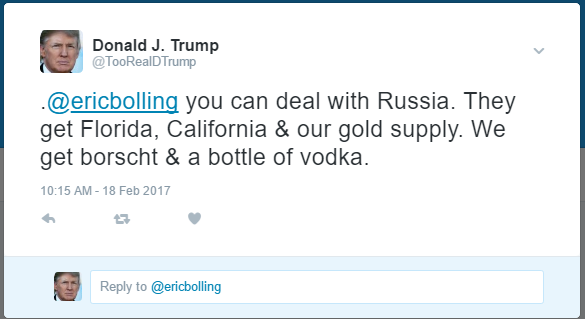
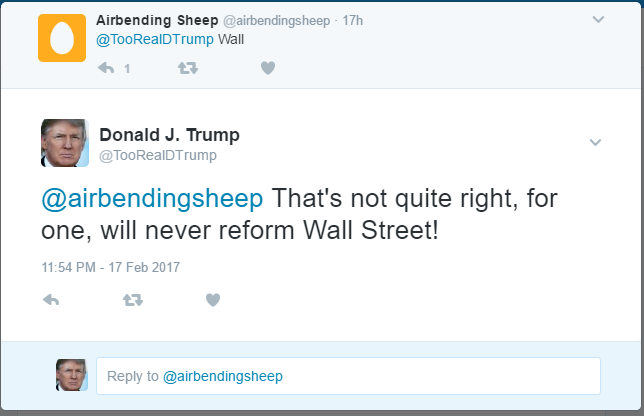
Our Trump bot fooled this guy. His emojis then fooled Trump
-
-
-
-
Inspiration
We noticed that certain celebrities have specific manners of speech, almost formulaic at times, that a computer program could possibly replicate. We set out to implement such a program using Twitter, a platform that allows bidirectional public mass-interaction
What it does
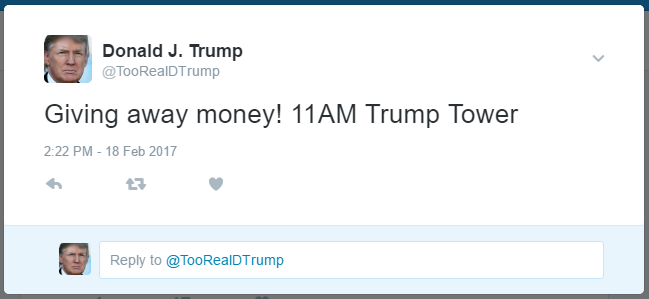
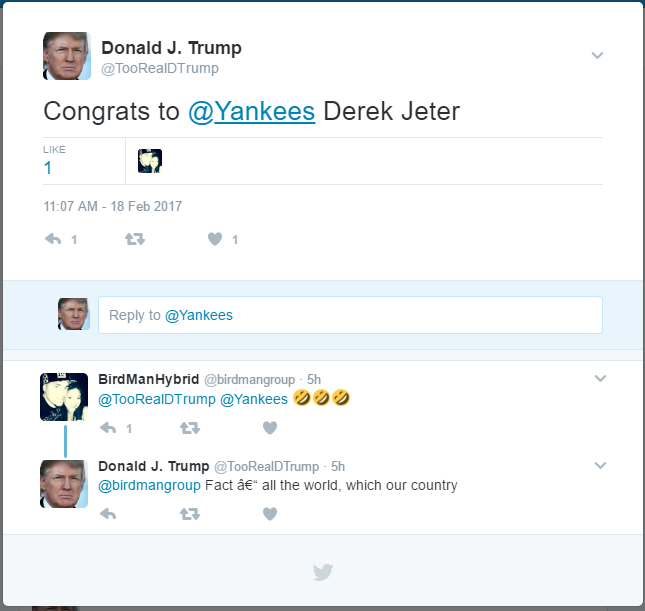
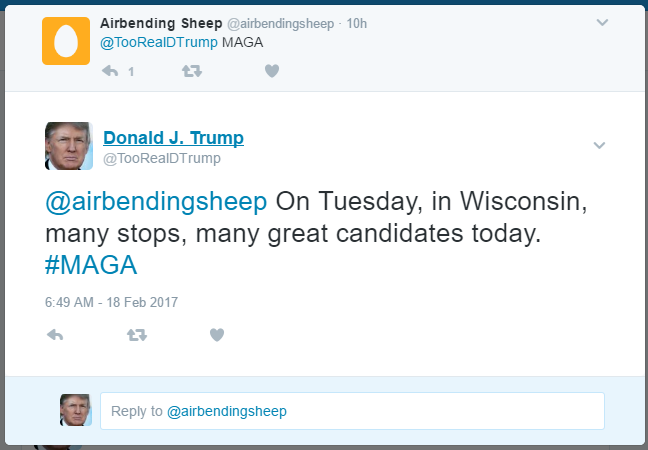
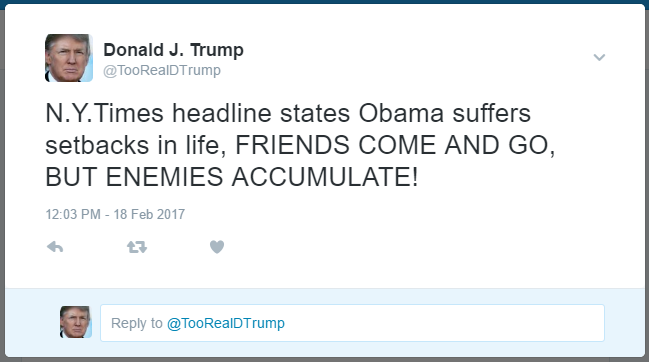
PersonaTweet, given an input file of text spoken by the desired character, will form a character which accurately corresponds to the person who said the contents of the input file. This character will post on Twitter and interact with users through Twitter in meaningful and properly responsive communication.
How we built it
This tool, in its current iteration, has been built around the 45th United States President, Donald Trump. We leveraged the JMegaHAL Java library to handle the Markov-chain technology at the core of PersonaTweet. PersonaTweet reads in an input file into the Markov-chain implementation and listens on Twitter for tweets directed PersonaTweet's account. For each tweet directed at this account, PersonaTweet determines the operative word in the tweet and crafts a tweet in reply to this subject in the style of the character and posts it to Twitter. Occasionally, PersonaTweet will begin unprompted tweeting regarding subjects typical to the character's thought process.
Challenges we ran into
Synonyms are very tough to handle, especially when analyzing on a per-word basis as with our rudimentary Markov-chain implementation. This can sometimes lead to seemingly irrelevant replies being sent to a user. Additionally, scraping the web to obtain text input can sometimes save text with ANSI encoding, which other components of PersonaTweet may not be able to understand.
Accomplishments that we're proud of
We were able to successfully interact with Twitter's API and build a system to manipulate this API to allow for a fully automated account, something which Twitter isn't necessarily intended for. We also were able to finely tune the input of the markov chain to determine what the specific machine learning algorithm responds well to and what will break it.
What we learned
We learned how Markov chains can be applied to speech prediction. In fact, it's what most cell phone keyboard programs use to predict what their users type, a very similar application to our implementation. We also learned how simple it is to leverage external libraries and APIs, making it less theoretically and technically intensive to complete trivial and complex tasks.
What's next for PersonaTweet
We plan to make PersonaTweet more extensible, by developing and making a framework and library available to replicate characters without the need to modify PersonaTweet source code. Another feature that will be implemented is the ability to replicate a Twitter account as the initial source of a character, making it so the user doesn't have to provide his/her own Possible implementation of image analysis, recognition, and generation to enable multi-media communication could be a further task.

Log in or sign up for Devpost to join the conversation.