-
StartPage
-
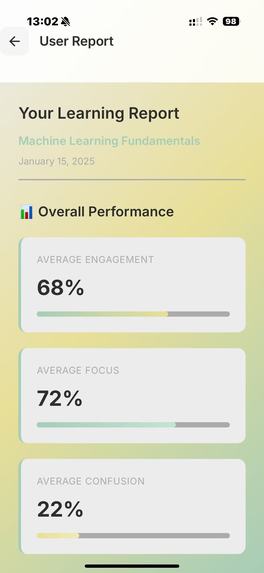
/UserReport
-
/QuestionBox
-
/PersonalizedQuizStart
-

/EngagementMonitor
-
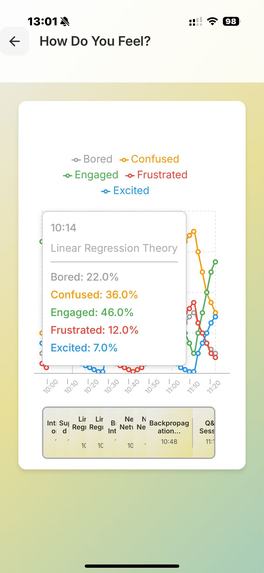
/SentimentAnalysis
-
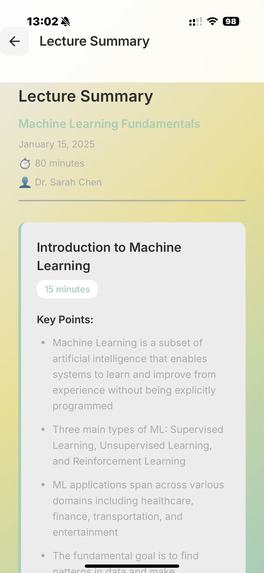
/LectureSummary
-
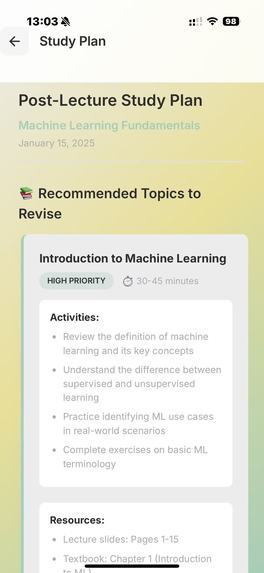
/StudyPlan
-

/PersonalizedQuiz

Inspiration
Our project was inspired by our personal experiences in lectures: namely, the inefficiency with which teaching via lectures brings. We offer a personalised study plan for every student, given that the times of boredom and misunderstanding vary at the level of the individual; we propose further that an aggregation of the data from several students could also be used to provide concrete, quantitative feedback to the lecturer.
What it does
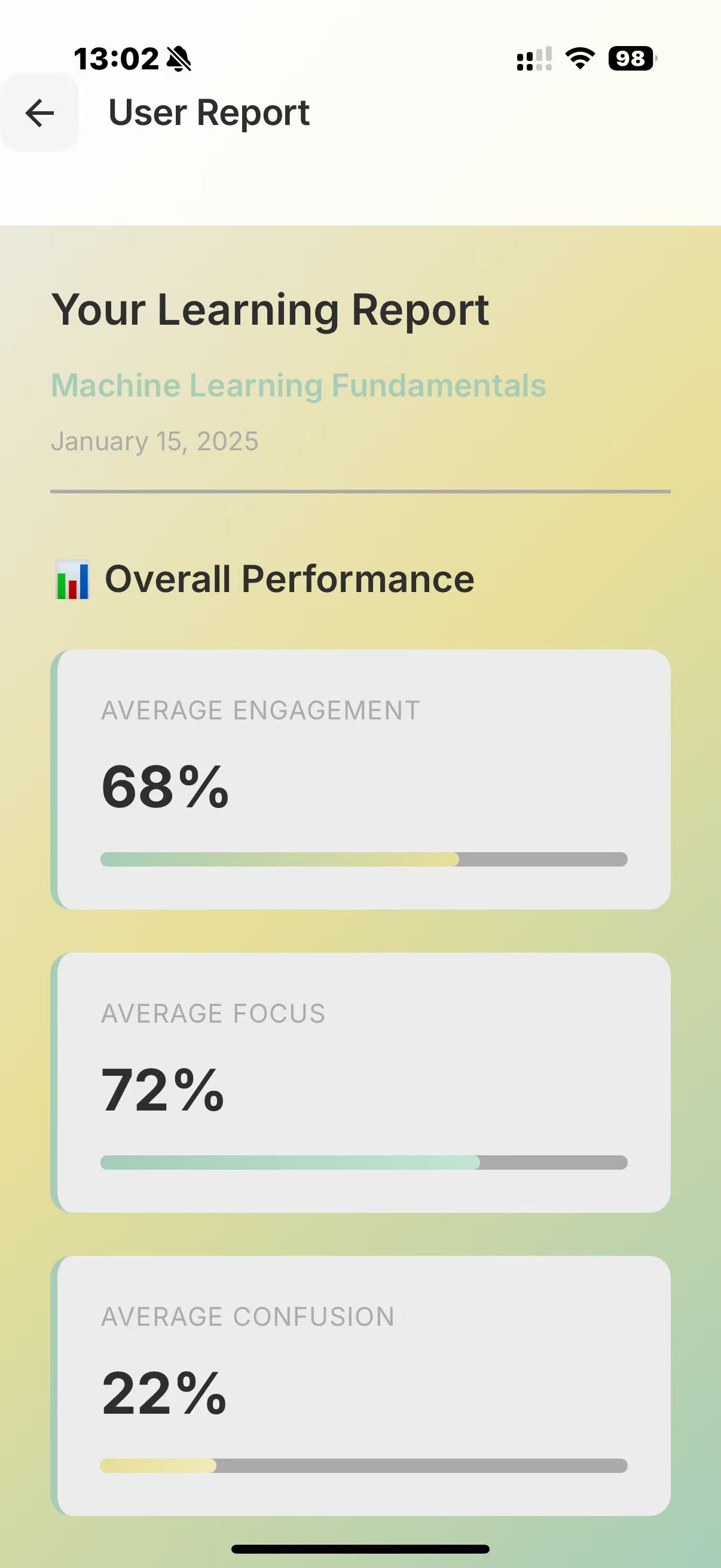
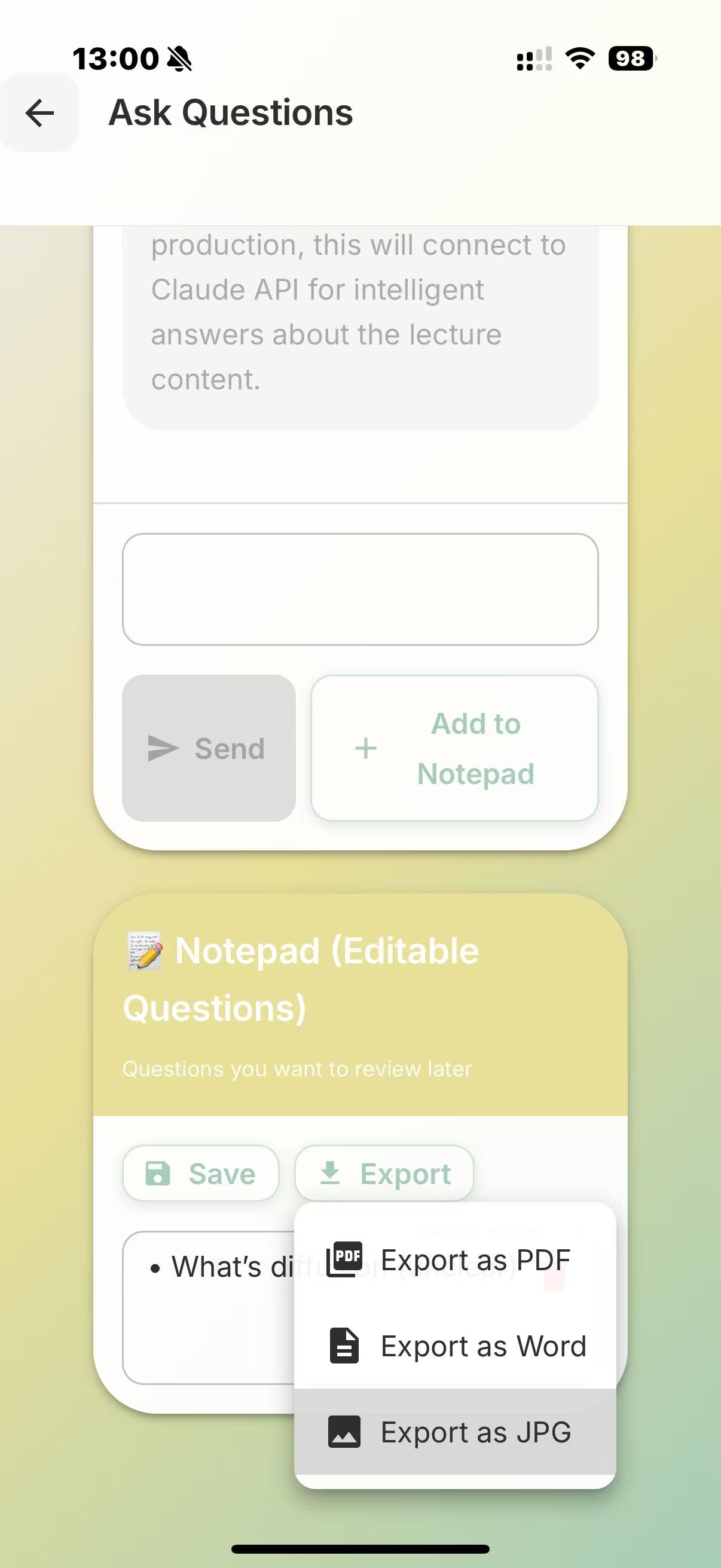
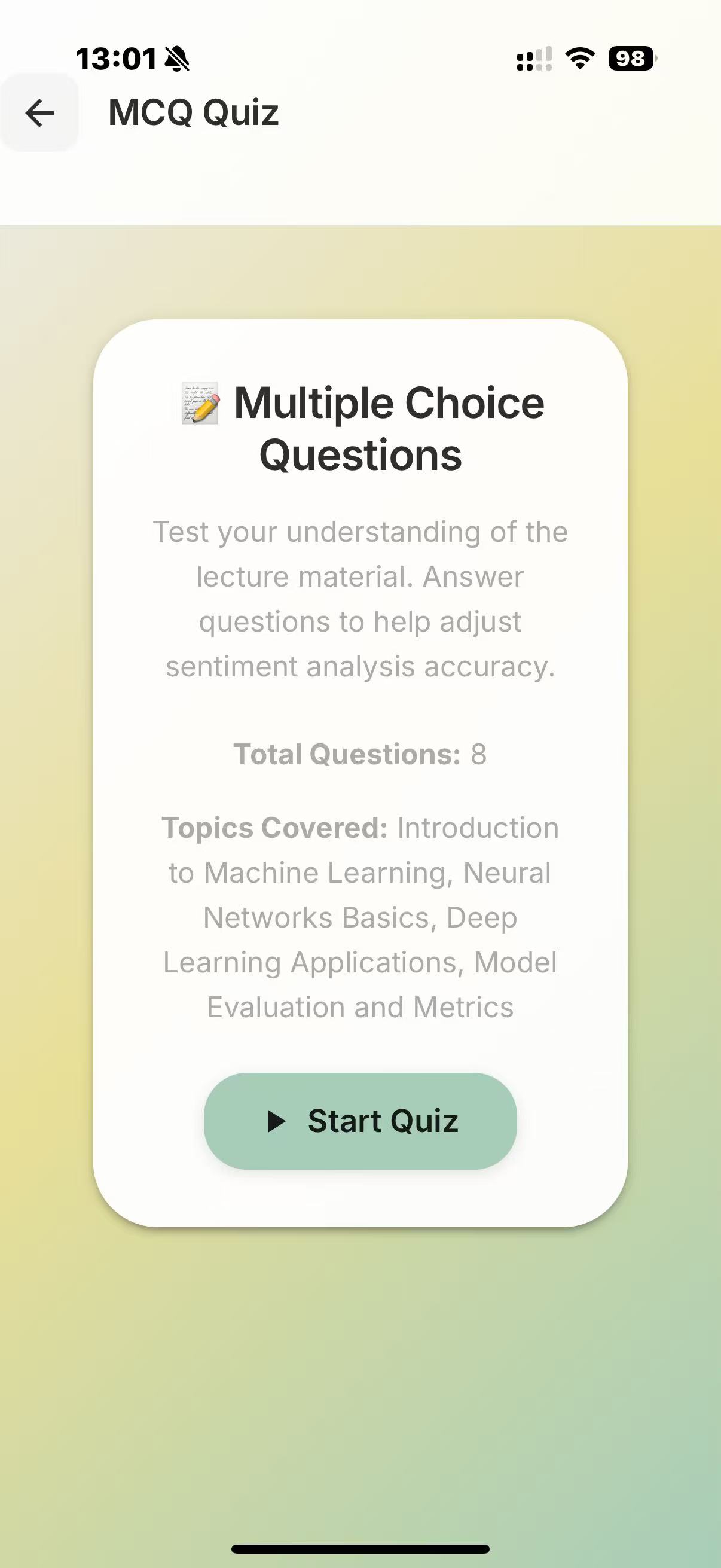
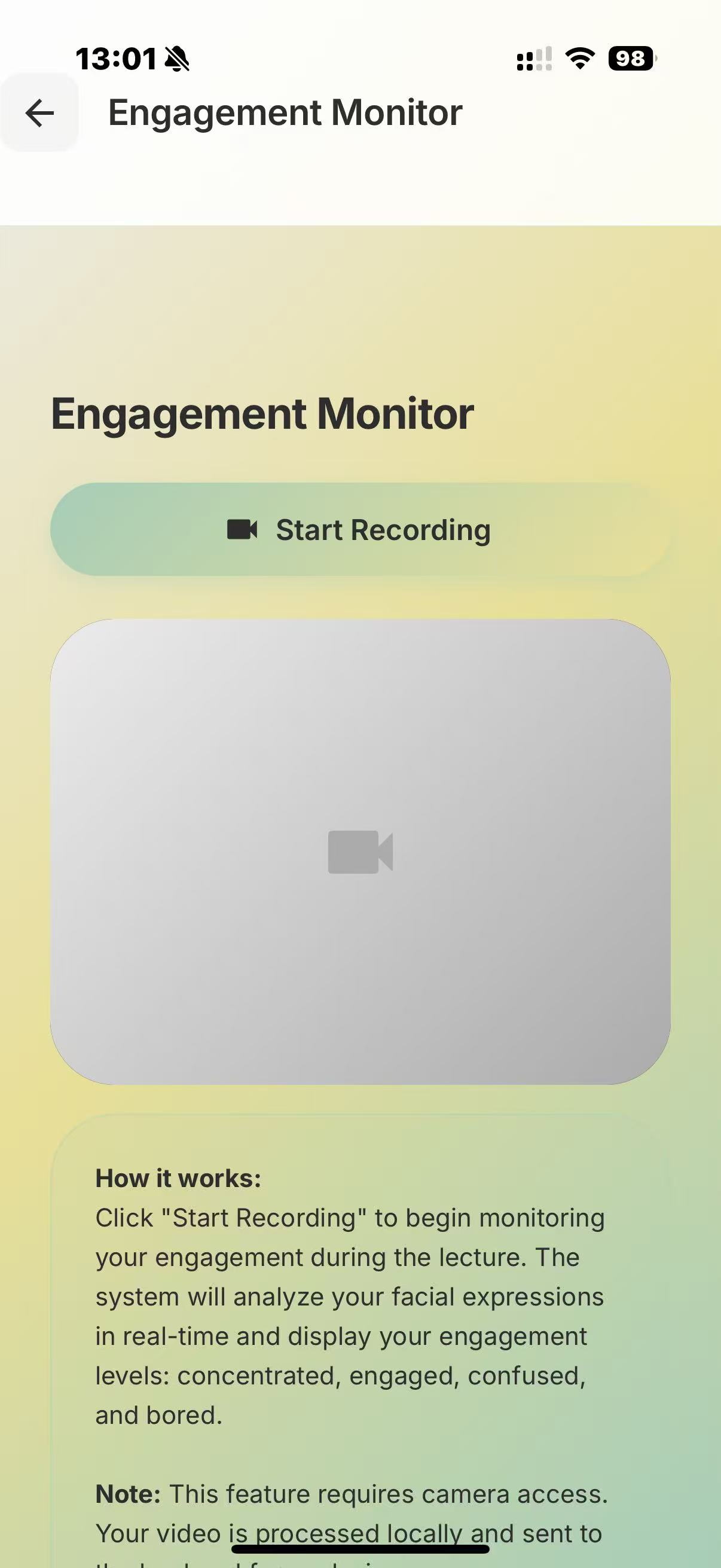
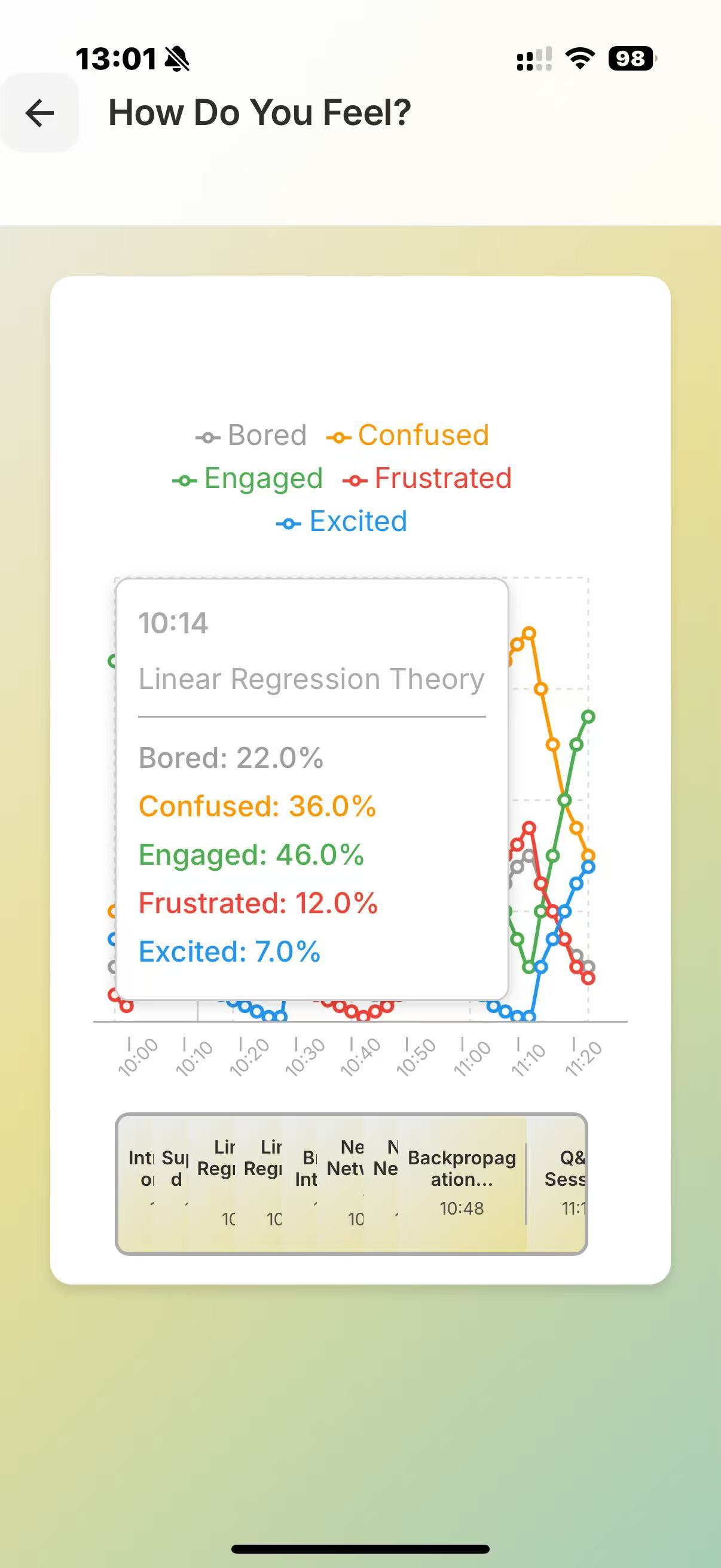
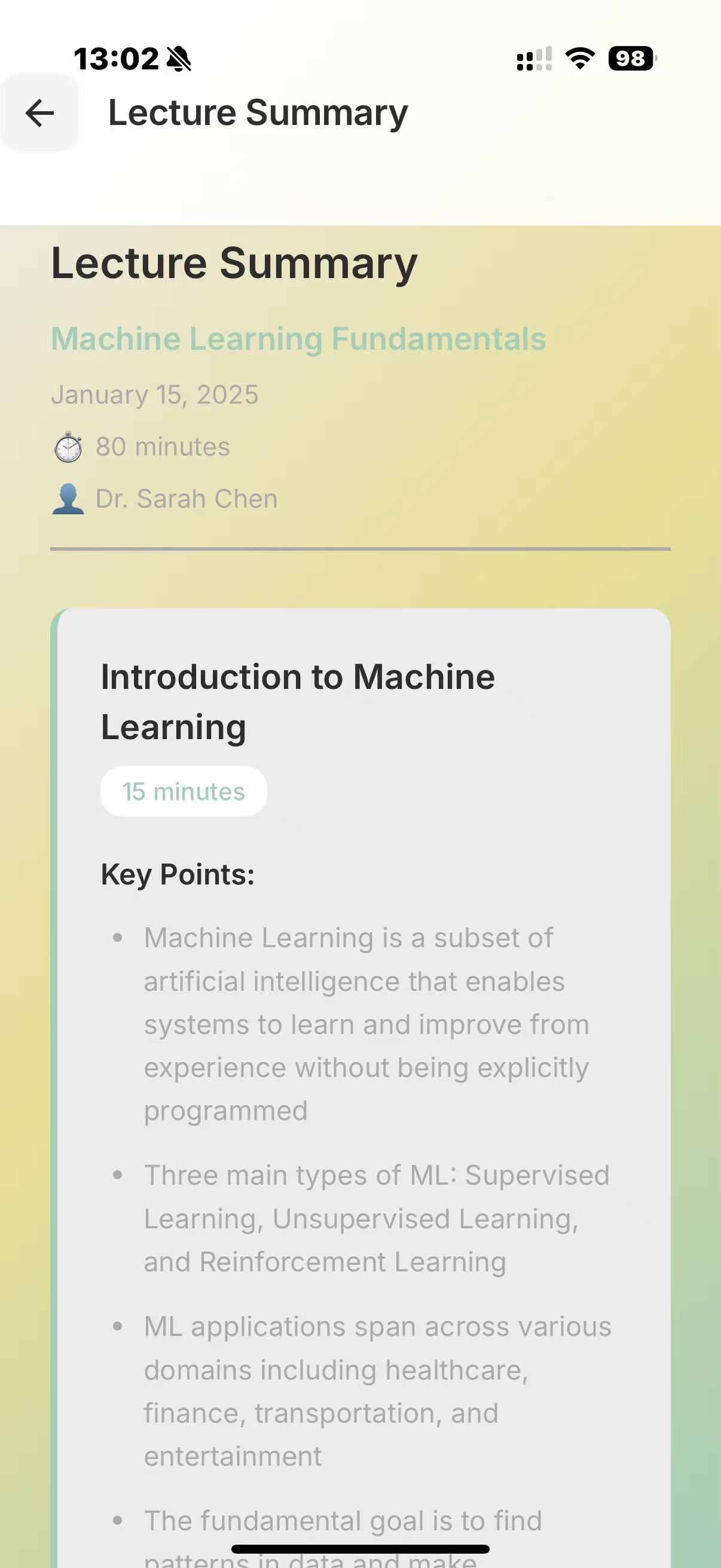
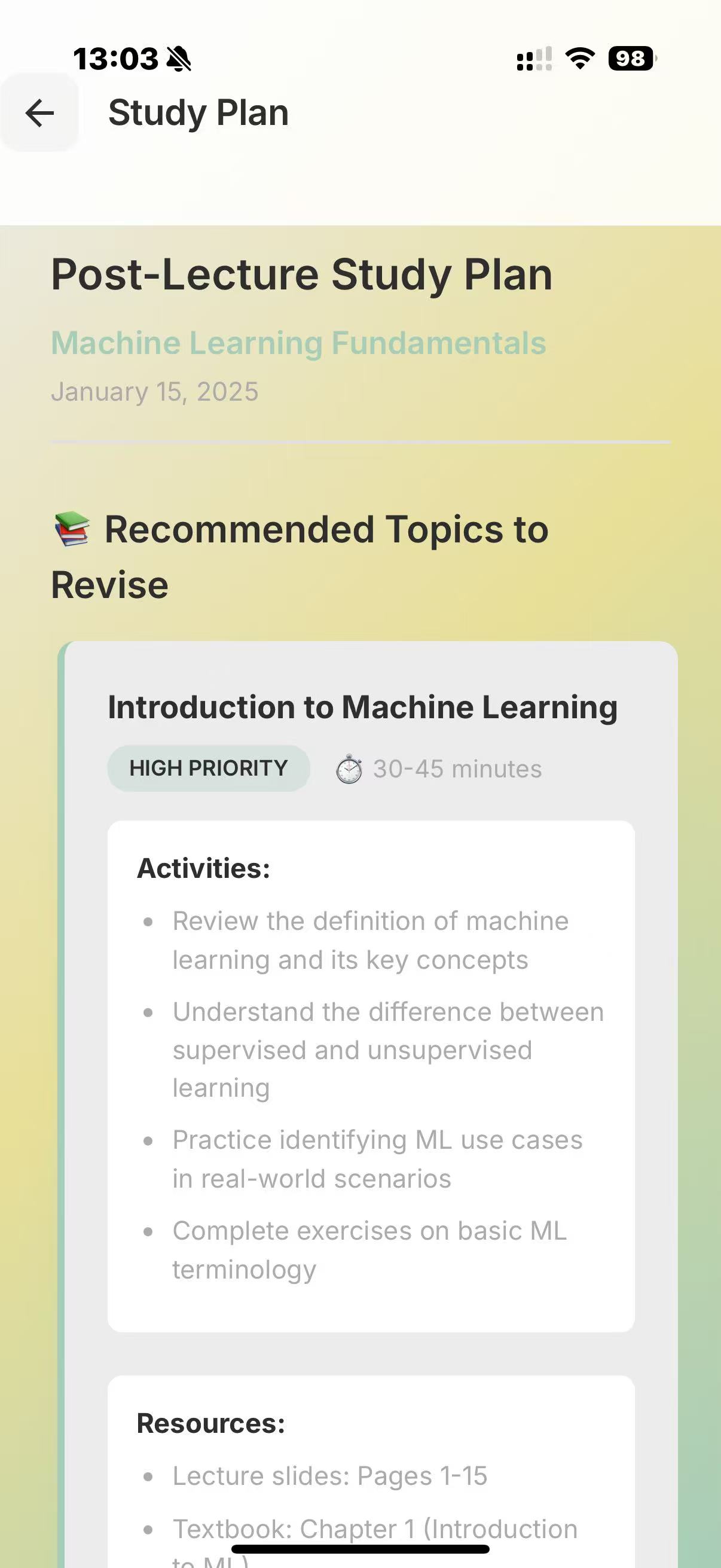
At the start of the lecture, you open the application and our program begins to record your face, the lecture audio, and, via MCP, it also has access to your lecture notes. The face recording is not saved nor necessarily displayed, but is passed through a Computer Vision script for sentiment analysis, to detect periods of boredom or confusion. This is then serialised with the lecture transcription, to identify when a student may have not understood/misunderstood the lecture content. This is further verified by the app at the end of the lecture, where we ask claude to question the student's understanding, and depending on how they perform on topics, produce a summary/personalised set of notes tailored to the student's understanding.
How we built it
We used deepface and opencv to perform the sentiment analysis, and combined the preset emotions using a heuristic to arrive at a score for the following categories: "Concentrated, Engaged, Confused, Bored". We use pyaudio to record audio. We use sound_recording to transcript the audio, and then prompt the Claude API to summarise each one minute segment (this can be used at the end to help the user verify where they have misconceptions at a glance). This combined feed is fed again into Claude's API to generate questions/explanations of the times where the user has appeared confused/bored (also concentrated for control). Depending on the question answers and all prior data, we use Claude to produce a personal set of notes, tailored to the student.
Challenges we ran into
Individually the components of our team worked very well: the front-end and IOS app progress was wonderful, and progressed in parallel with dummy data while the computer vision data was being worked on. Similarly, the audio transcription and summarisation was handled independently. The challenges arose in combining the disparate components into one, and integrating the product into a working whole. Hardware issues were also present, notably my laptop.
Accomplishments that we're proud of
We think that the idea is innovative and fits the task description very well, and we are also impressed with the speed with which we developed a working prototype and front-end that could be put into production with minor tweaks.
What we learned
We learnt how to integrate Claude's API into our programs, and also each member of the team made discoveries into their given fields/roles (speech_recognition, computer vision for sentiment analysis, ux/ui design, and data processing).
What's next for Personal Tripos Trainer
We have built the set-up for a single lecture, or a series of lectures. However, we wish to expand the current system with MCP for file managment so that we can pass in lecture notes, and also non-structured data such as supervision work/examples papers. We would like even to have Claude offer 'Just In Time' support where if the user is stuck on a particular question, Claude can step in and offer assistance in some manner.
The computer vision section could be fine-tuned for personal emotion recognition overtime, and we can include metadata to factor in sophisticated emotion detection (such as weather data, calendar data, etc. to take in to consideration these bigger factors and how they influence mood). For many students' data, we can talk about providing feedback to the lecturer as well.

Log in or sign up for Devpost to join the conversation.