
Inspiration
Every student has had this moment: you sit down with your laptop, open Canvas, and stare at it. You know the midterm is coming. You know there are things you haven't started. But the information is scattered across a dozen tabs and you don't actually know where to start.
Canvas is the source of truth for a student's academic life. Deadlines, syllabi, grades, announcements. But it doesn't tell you what to do with any of it. We wanted to build something that takes all that and turns it into a plan that actually works with you. One that knows your courses, your grades, what you've submitted, what you're behind on, and what's due tonight. One that remembers you.
What it does
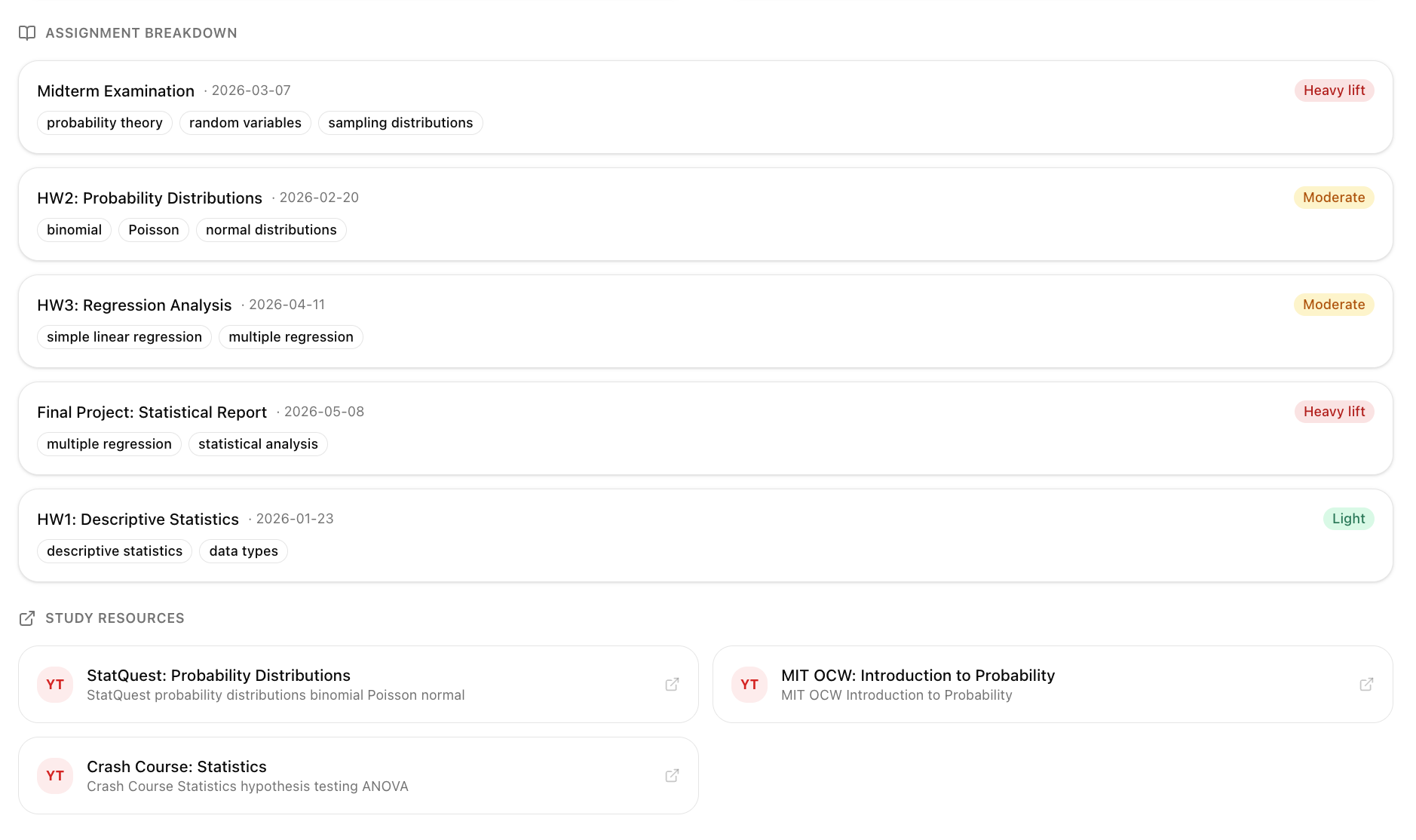
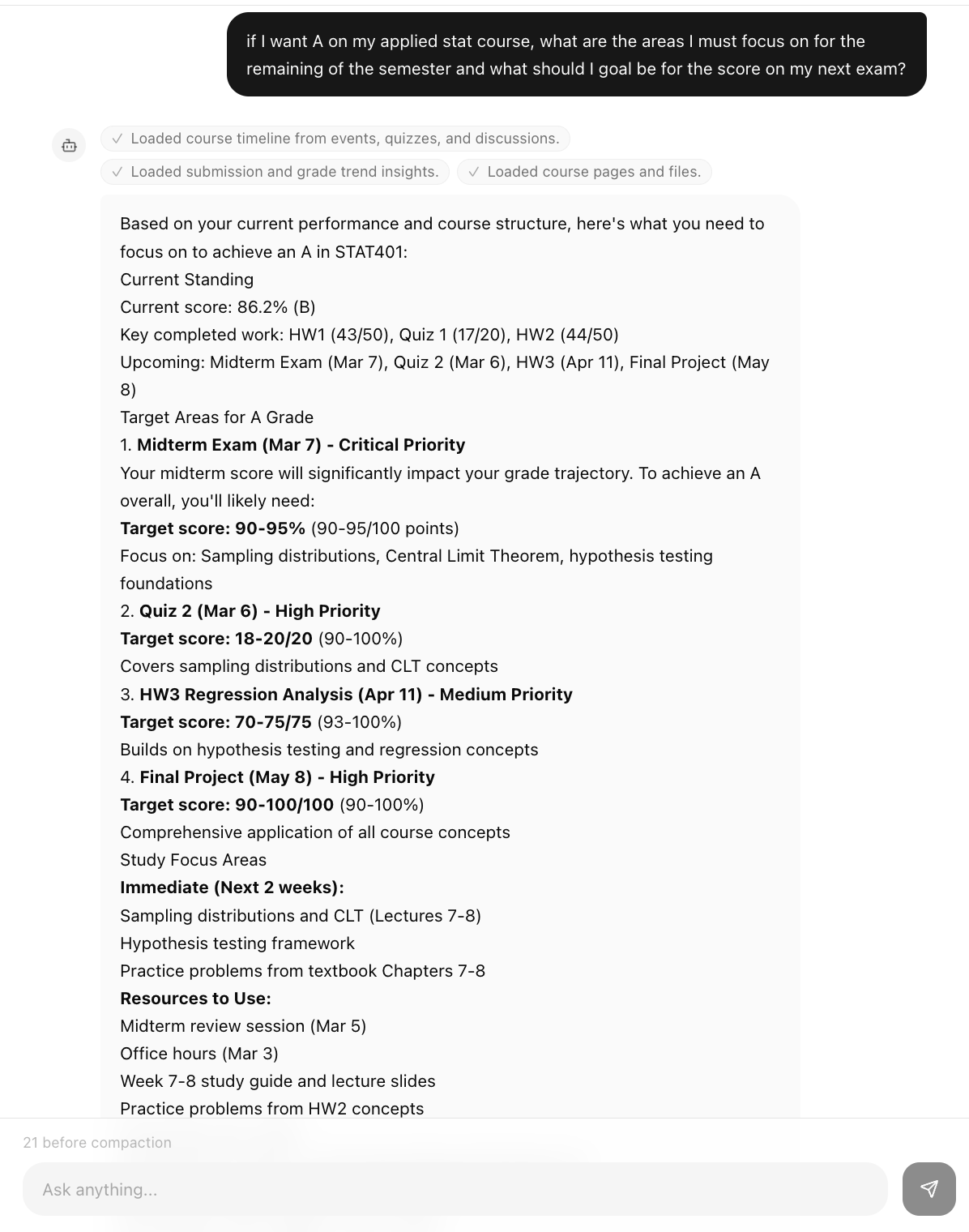
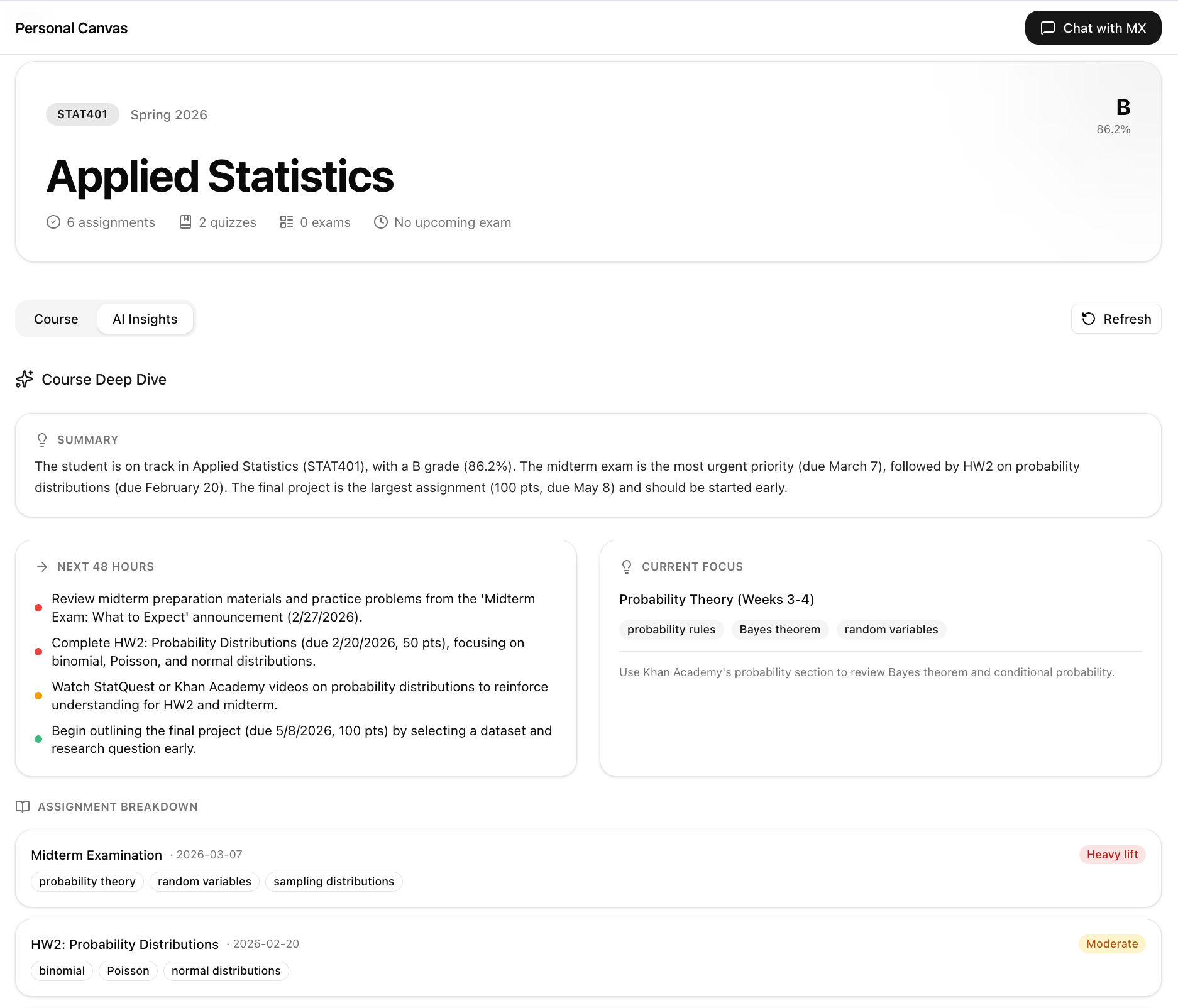
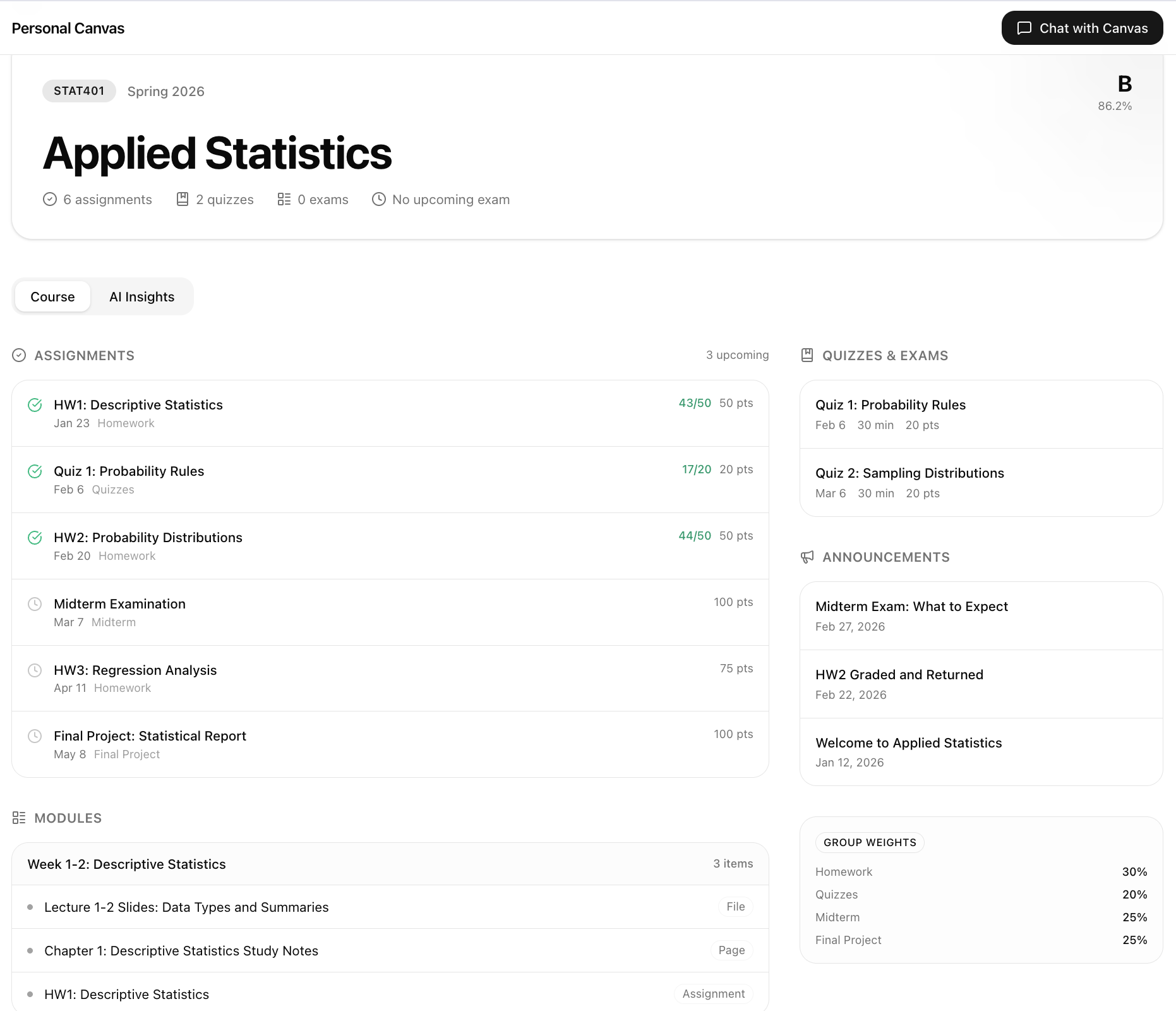
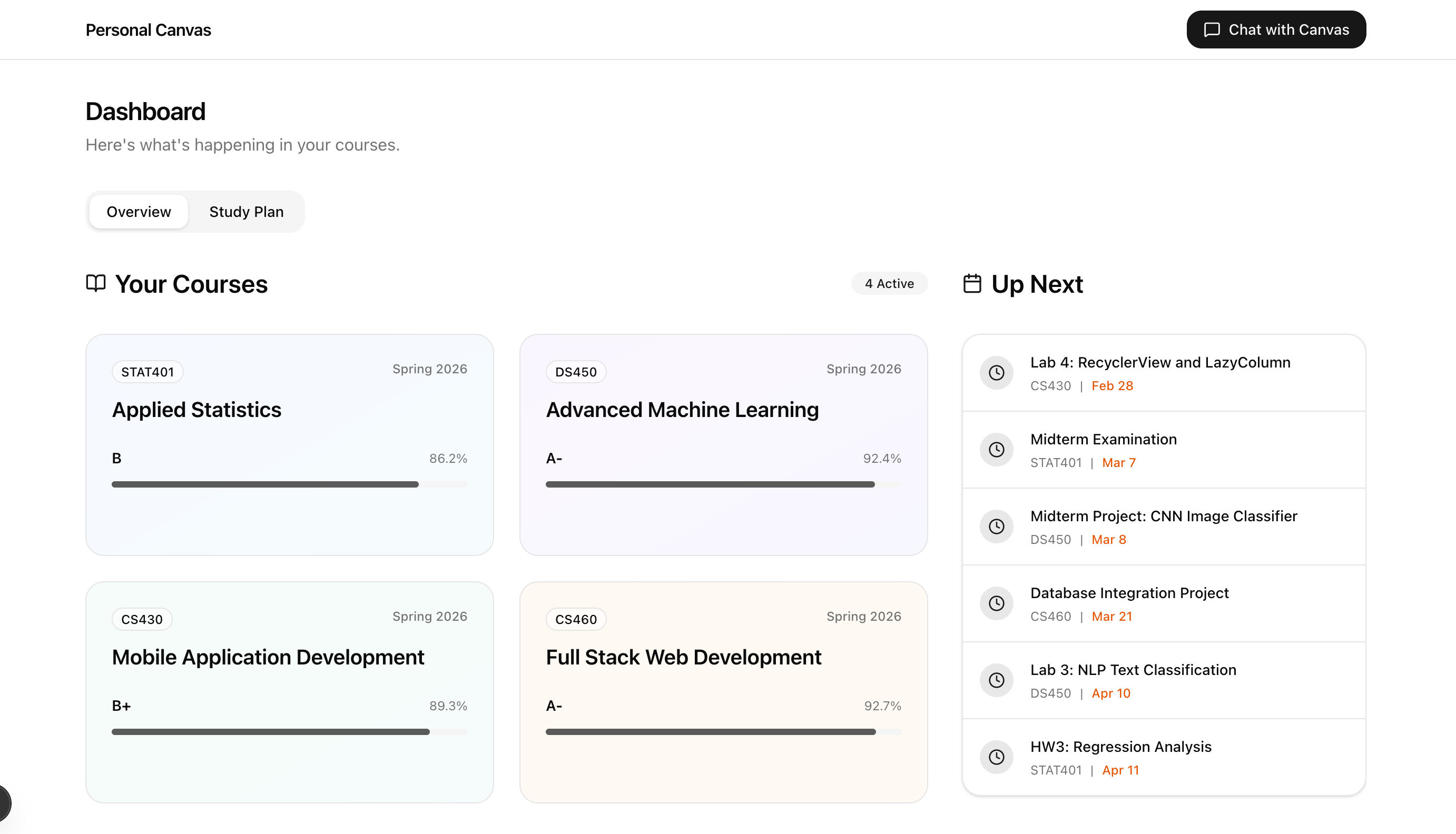
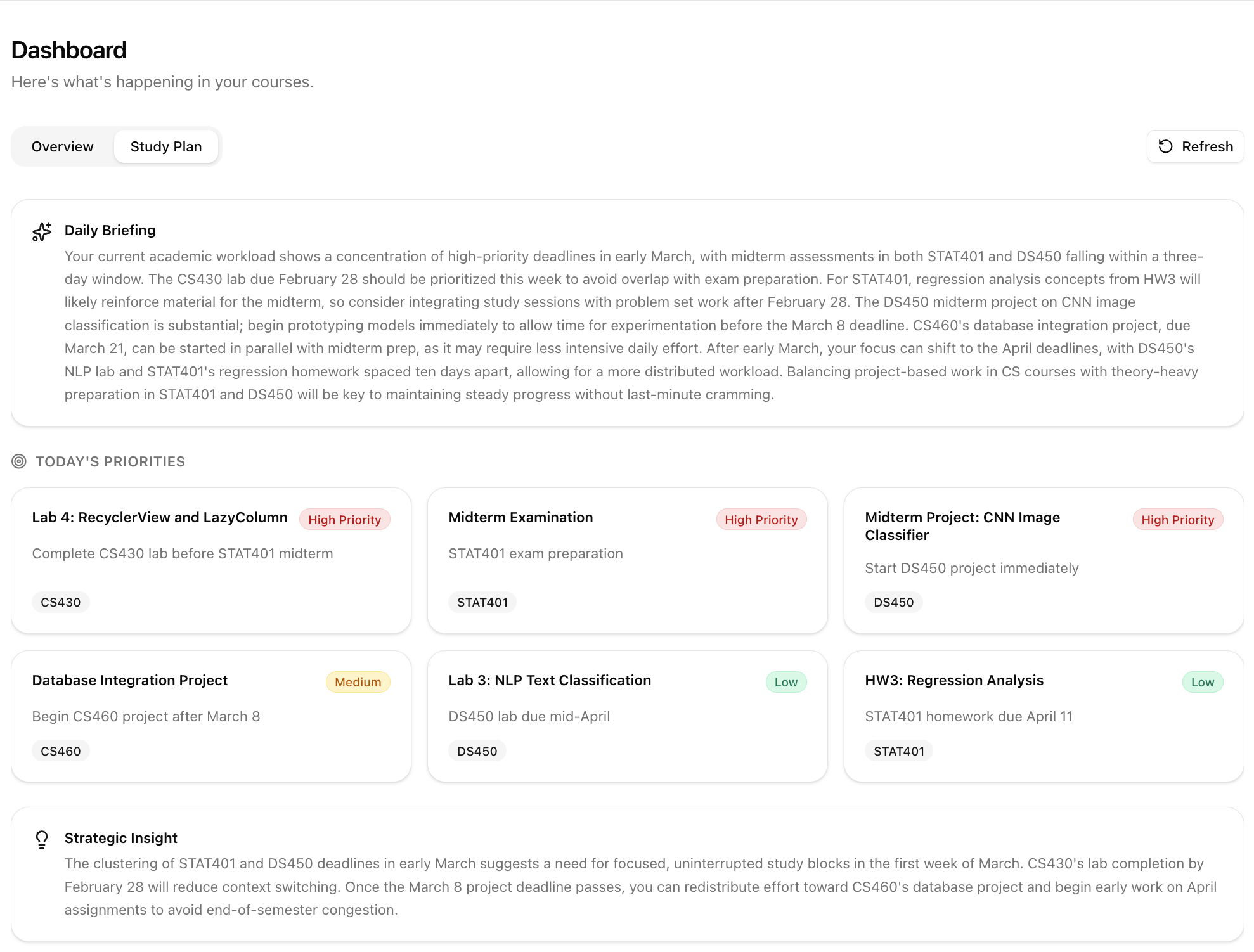
Personal Canvas is an AI study partner built on top of your Canvas data. On load, it generates a personalized briefing from what it finds. Two midterms converging this week? It tells you. A lab due tonight? Flagged. For each course, it reads the syllabus, your current grade, submission history, and active module, then gives you next steps and effort estimates.
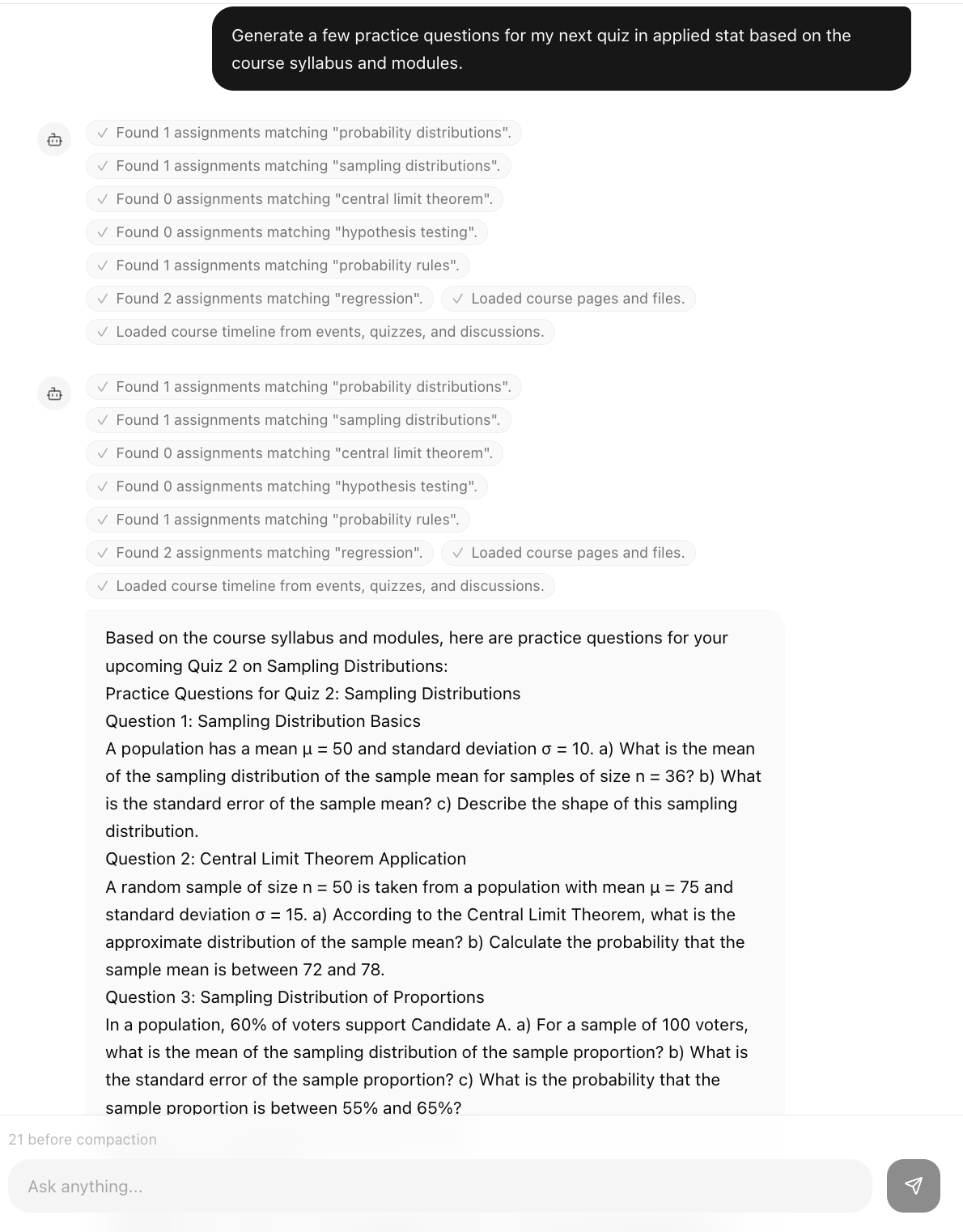
The chat agent has 9 typed tools that query your live Canvas data and render structured UI cards: grade tables, course timelines, submission breakdowns. Not paragraphs. The memory layer persists across sessions, auto-extracting context from your messages and storing it as vector-indexed memories. The more you use it, the more it knows you.
How we built it
Stack: Next.js 15, React 19, PostgreSQL 16 with pgvector, Vercel AI SDK, OpenRouter, Framer Motion, Tailwind CSS, Docker.
We mirrored the Canvas LMS schema and extended it with AI-runtime tables: chat_sessions, chat_memories, chat_planner_state, and chat_planner_events. Nine typed tools backed by parameterized SQL query this knowledgebase and return structured payloads. Each payload carries a uiTarget field so the frontend renders the right component automatically, no conditional logic needed in the UI.
Sessions persist in Postgres as UIMessage[] JSON with a per-session lock queue. When a session grows past 30 messages, older turns compact into a rolling summary via a secondary LLM call. Memories are embedded with 2048-dimensional vectors and recalled with hybrid search: cosine similarity first, ILIKE fallback. The planner recomputes a live snapshot on every request and fires a change event if anything shifted since your last session.
We couldn't use real Canvas data, so we built a Seed.sql designed to be internally consistent enough for the AI to produce real insights: grades that match the submission math, a lab due tonight, two midterms converging in 10 days, a submitted assignment still awaiting a grade.
Challenges we ran into
Getting semantic search right was harder than expected. The embedding model outputs 2048 dimensions, which meant migrating 1536-dimension columns mid-build. We also had to handle partial embedding coverage with hybrid SQL that prioritizes vector distance, not ILIKE, as the primary path.
Free-tier models on OpenRouter are slow. Multi-step tool loops can run 10-15 seconds end-to-end. Streaming masks the worst of it, but we still tuned the system prompt heavily to minimize wasted steps and capped the loop at 8.
The demo data problem was subtle. Generic placeholder data makes the AI's analysis meaningless. If the grades and assignments don't reflect a real student's situation, the "insights" are just hallucinations dressed up as advice. We had to build seed data that told a coherent story the AI could actually reason about.
Accomplishments that we're proud of
The memory system works across sessions without the user repeating themselves. Tool calls render real UI components, not paragraphs. The schema is Canvas-compatible enough that connecting to the actual API is a parser swap, not a redesign. The agent can reason about your workload holistically: midterm in 7 days, lab due tonight, pending grade, here's what to prioritize. Getting that last part right took a while.
What we learned
Tool calling is the hard part. Getting a model to pick the right tool, in the right order, with the right parameters, and synthesize the results into something useful is an architecture problem, not a prompt engineering one. The tools have to be precise or the model wanders.
Persistence changes the product more than anything else. Once the agent started recalling context from previous sessions, it stopped feeling like something you query and started feeling like something you actually work with. That shift happened faster than we expected.
We also learned we genuinely wanted this tool. We built it under time pressure and still kept finding ourselves wishing it existed for our own coursework. That felt like a good sign.
What's next for Personal Canvas
Direct Canvas API integration. We mirrored the schema precisely so a real-time ETL layer, polling the Canvas REST API and upserting into our tables, would need no changes to the AI layer or UI. With live data, the planner reacts to grade updates, newly released assignments, and due date shifts as they happen. That's the version that matters.
Built With
- docker
- framer-motion
- next.js
- node.js
- openrouter
- pgvector
- postgresql
- radix-ui
- react
- tailwind-css
- typescript
- vercel-ai-sdk

Log in or sign up for Devpost to join the conversation.