Prototype link (Please submit a link to a playable prototype, not a link to your design file) link
Describe your project (max 150 words) What makes us human is our diversity. Our cultures, experiences, and perspectives shape how we see the world. But AI doesn’t see it that way — yet. As AI, especially Large Language Models (LLMs), becomes more embedded in daily life, it struggles to reflect the necessary diversity and inclusive language. LLMs produce biased or culturally inaccurate responses due to a lack of genuine human experiences. While AI companies want more inclusive models, the crux of their struggle remains in gathering cross-cultural perspectives.
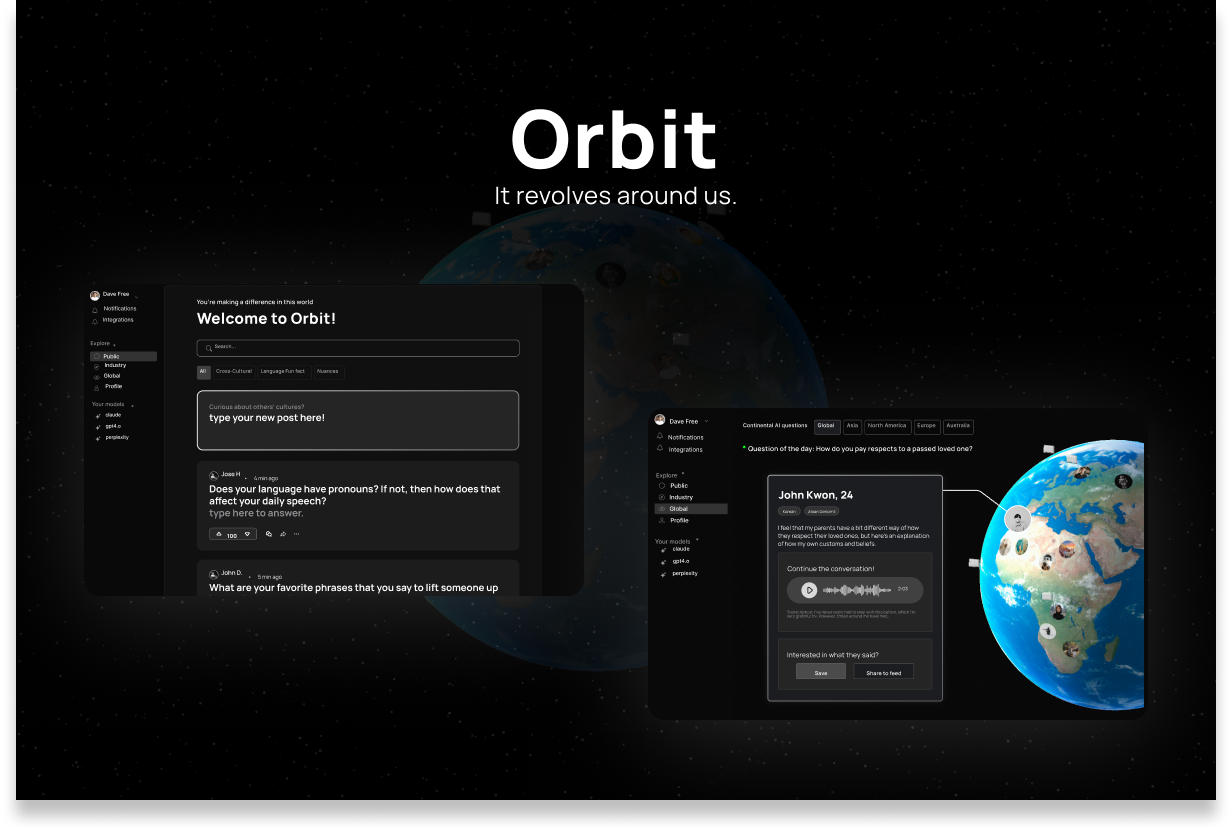
Our solution keeps the human experience at the center by fostering global conversations. Through our platform, people from diverse backgrounds connect, share insights, and discuss cultural perspectives—helping AI companies build models that truly reflect societal values. Our product ensures that AI learn from real human voices, not just data points, to build a future where technology can bolster humanity, and not diminish it.
- **Describe your research process and findings. If you conducted any surveys or interviews, please There were a variety of research methods that we have conducted. To begin, we conducted 1:1 interviews with three software engineers, including an AI/ML researcher actively working in the field. These interviews provided valuable perspectives on the technical limitations and the human impact of biased AI outputs.
Key Questions:
- Have you observed any biases or cultural insensitivities in AI-generated content during your work?
- What are the current limitations in training LLMs to better reflect diverse human perspectives?
- How do AI companies currently gather training data, and what ethical challenges arise from these methods?
- In your opinion, how can community-driven data contribute to improving LLMs’ cultural sensitivity?
- Would transparency in how LLMs are trained influence user trust? How?
Key Findings: All interviewees noted that, though improving, LLMs still frequently produce biased or culturally insensitive outputs due to training on web-scraped, unvetted data. This affirmed the need for more curated, diverse, and consent-based data sources. The AI/ML researcher emphasized the inability to trace data origins. Many companies struggle to be get clean data, leading to ethical concerns and reinforcing bias. Support for Community-Driven Solutions: Interviewees saw great potential in platforms that allow real users to contribute cultural insights, noting that this approach could significantly improve AI’s inclusivity and reduce harmful biases.
To complement our primary research, we conducted a review of existing literature on biases in LLMs and the limitations of current AI training practices. Our secondary research focused on identifying gaps in AI inclusivity and understanding how existing platforms address (or fail to address) these issues.
Sources:
- Biases in Large Language Models: Origins, Inventory, and Discussion : This paper highlighted the systemic biases present in LLMs due to training on unfiltered, web-scraped data. How LLMs often reflect Western-centric viewpoints and perpetuate harmful stereotypes, reinforcing our platform’s goal of diversifying AI training data. link
- The Partnership on AI’s Report on Ethical AI Training link This report revealed that most AI models lack transparency in data sourcing, leading to distrust among users. It highlighted the growing demand for ethical, consent-based AI development.
- Fairness and Bias in Artificial Intelligence: A Brief Survey of Sources, Impacts, and Mitigation Strategies This survey provides a comprehensive overview of fairness and bias in AI, addressing their sources, impacts, and mitigation strategies. It emphasized the need for diverse datasets to prevent biased outcomes. link
We also analyzed platforms like Reddit (r/LLMdevs) and Quora. Reddit offers a wide variety of topics but lacks a structured, moderated framework for AI-relevant data extraction, often leading to biased or unfiltered content. Quora provides educational, formal insights, but misses conversational nuances essential for training culturally aware LLMs. Both lack the ethical, consent-based data collection and transparency that our platform offers, making ours uniquely human-centered and AI-enhancing.
While time constraints limited the breadth of primary research, the depth of insights from AI professionals and secondary literature provided a strong foundation for our solution.
- Describe your most important design decisions. What research findings and/or user testing results led you to make these decisions? (Max 500 words) One of the most important design decisions we made was to prioritize accessibility and usability in the design of the product to maintain user discussions, while aiming for productive features that will retrieve as much ethical data as possible. Our project, Orbit, aims to create an inclusive platform where users from diverse backgrounds could share insights and engage in thoughtful conversations, to uproot potential biases in AI systems.
Research Findings: Through initial user interviews, we discovered that LLM users often felt that AI favored heavily towards one side, when the topic was more controversial in nature, such as politics or race. We found that the majority of biases occur for cases regarding personal identity. Even if the LLM display no specific signs of bias towards one group, the LLM still played into harmful stereotypes of combinations of identities (such as African American women). Additionally, many of these stereotypes were direct results of lacking data--which affirms the view of our previous user interviews with AI researchers. Third, there’s a disproportionate amount of data for verbal intonation data in comparison to written data; with new AI models directly conversing through speech, this was a crucial point to address as well. Lastly, we found that AI companies continued facing difficulty obtaining user data, as web scraping may be illegal without consent and other methods are often deemed unethical.
Design Decision: Based on these insights, we decided to build the platform on the basis of cultural exchange--especially with the forums. Due to societal norms and cultures’ affect on identity, we decided it was imperative to provide the LLM with cross-cultural dynamics and nuances. In addition, we decided to allow users to be able to talk and record on our daily prompts with the intention of analyzing speech patterns and intonation. For the last portion, our team decided to take a step forward and offer a partnership between our product and AI LLM companies. All of our major features were meticulously designed to pin point a specific issue we’ve uncovered.
Our color decision of monochrome was to reflect a sleek, modern, and professional look.
Built With
- figma




Log in or sign up for Devpost to join the conversation.