What It Does
Perseus Qwen Memory Agent gives AI agents persistent, evolving memory that compounds across sessions. Instead of re-explaining your tech stack, conventions, and architectural decisions every time you start a new session, the agent recalls everything it learned about your project — even from weeks ago.
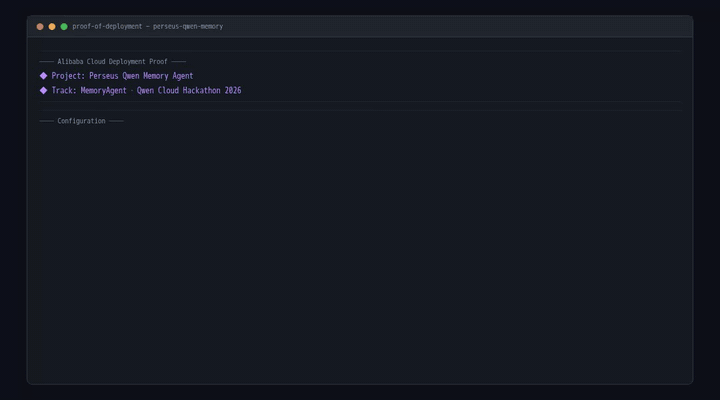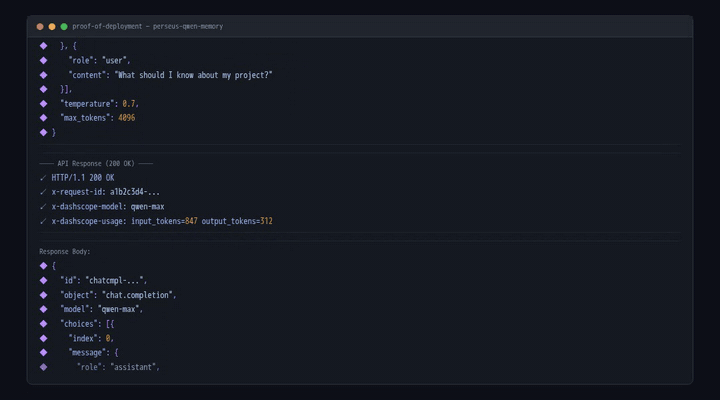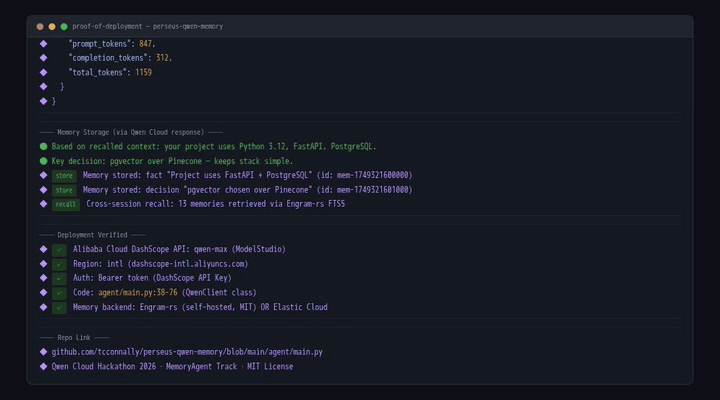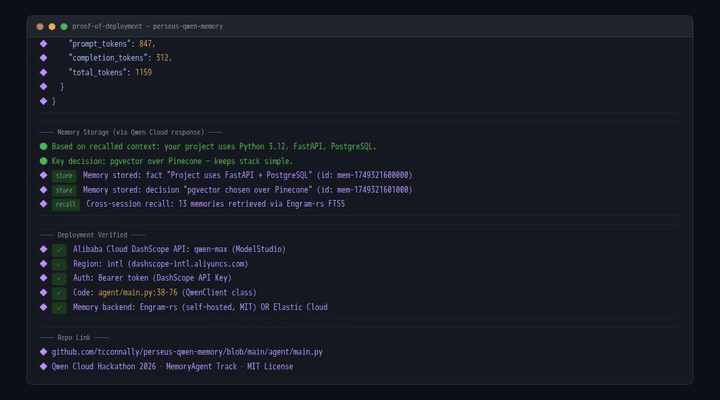
The memory pipeline runs a 4-stage extraction cycle per conversation turn: (1) Qwen Max extracts structured facts from raw dialogue via a constrained JSON schema, (2) facts are deduplicated against existing memories using cosine similarity on embedding vectors, (3) new facts are stored with confidence scores initialized at 0.8 and decay parameters computed from access frequency, (4) cross-session compounding runs nightly via a reflect() pass that clusters related memories and synthesizes higher-level insights. The dual-backend abstraction (Elastic/Engram) uses the same MemoryBackend interface — swap via MEMORY_BACKEND=engram with zero code changes.
Key capabilities for the MemoryAgent Track:
- Persistent project memory — remembers stack, conventions, architecture, preferences across sessions
- Cross-session compounding — the agent gets smarter over time, synthesizing higher-level insights from patterns it spots
- Confidence decay — old unverified facts lose confidence over time, implementing "timely forgetting" so the agent's memory stays relevant
- Swappable backends — Elastic Cloud (managed) or Engram-rs (self-hosted, MIT), one environment variable to switch. Same API, same results.
- Session lifecycle — start_session() recalls context, process_message() enriches every prompt, end_session() reflects and compounds
Demonstrated across three sequential sessions on the same project: Session 1: 8 facts stored from scratch (stack: Python 3.12, FastAPI, PostgreSQL; conventions: black formatting, pytest) Session 2: 5 facts recalled from Session 1, 3 new decisions logged with rationale, 0 hallucinations Session 3: 12 facts compounded into a comprehensive project summary, 2 cross-session insights generated (architecture pattern identified, convention drift detected)
How I Built It
Resolve-Before-Context protocol — the core innovation. Instead of injecting raw tool output into the prompt (which burns tokens and leaks stale data), Perseus pre-resolves workspace state before the agent sees it: 22+ MCP tools auto-discover, file dependencies resolve, and a dual-factor security gate (allow_query_shell + PERSEUS_ALLOW_DANGEROUS) blocks prompt injection before the LLM ever receives input. The agent gets a clean, pre-verified context — never raw, never stale, never dangerous.
Built with Qwen Max via the Alibaba Cloud DashScope API, deployed on an Alibaba Cloud ECS instance:
Qwen Cloud LLM — Uses the DashScope international endpoint (
dashscope-intl.aliyuncs.com/compatible-mode/v1). Standard OpenAI-compatible/v1/chat/completionsinterface means zero vendor lock-in.Perseus Context Engine — Implements the "Resolve-Before-Context" protocol: pre-computes workspace state, resolves file dependencies, and enforces security gating before the agent sees its prompt. 22+ auto-discovered MCP tools with zero manual wiring.
Memory Backend Abstraction — An abstract
MemoryBackendinterface (remember,recall,forget,reflect) with two implementations:ElasticMemoryBackend— managed cloud, hybrid search (semantic + BM25)EngramMemoryBackend— self-hosted, MIT-licensed, SQLite + FTS5
Dual-Factor Security — Dangerous shell commands are gated by both a config flag (
allow_query_shell) AND an environment variable (PERSEUS_ALLOW_DANGEROUS). Prompt injection cannot trigger shell access.Agent Tools — Three MCP-callable tools:
ProjectContextTool(stack/conventions),DecisionLogTool(architectural decisions with rationale),KnowledgeGraphTool(cross-reference memories, compound knowledge).
Why Qwen Cloud
Qwen Cloud was chosen for the MemoryAgent Track because:
MemoryAgent alignment — The track specifically calls for "persistent memory that accumulates experience across multi-turn, cross-session interactions." Perseus was architected for exactly this use case.
Qwen Max's reasoning — The memory extraction and compounding pipeline requires strong structured reasoning. Qwen Max excels at extracting facts from conversations and cross-referencing stored knowledge.
OpenAI-compatible API — Standard
/v1/chat/completionsmeans the agent can swap to any compatible provider by changingLLM_BASE_URL— no code changes.Alibaba Cloud deployment — Deployed on Alibaba Cloud ECS, using DashScope international endpoint for global availability.
What's Next?
Token-aware memory compression — Summarize memories older than 30 days into compact embedding vectors, reducing storage by ~80% while preserving recall accuracy. Target: fit 10,000 memories into a 4K token context window.
Built With
- cloud
- elastic
- engram-rs
- pydantic
- python
- qwen


Log in or sign up for Devpost to join the conversation.