-
-
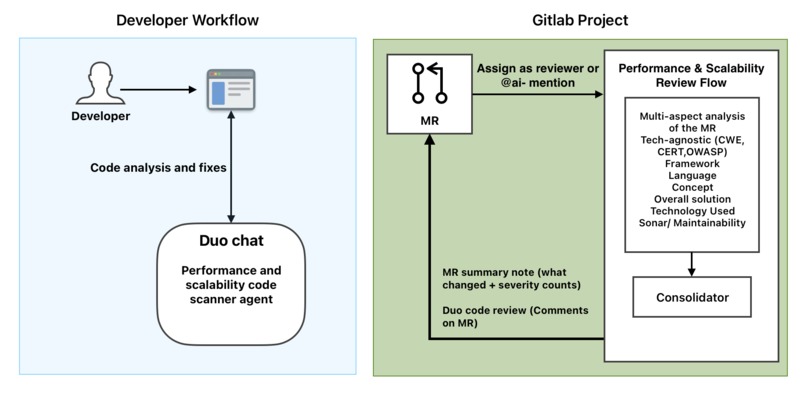
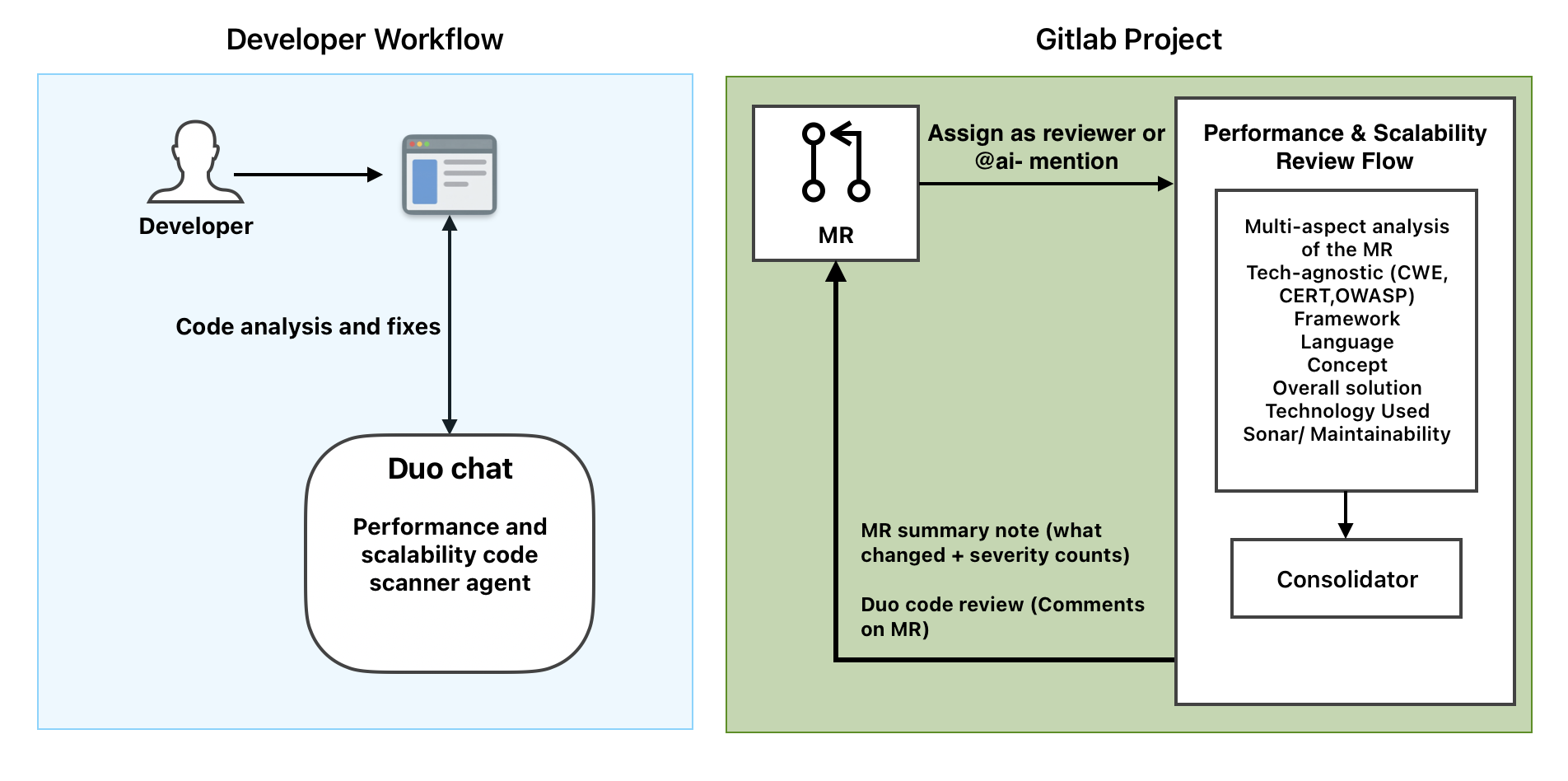
Performance & Scalability Review flow
Inspiration
Performance and scalability issues (for example, loading entire datasets into memory instead of streaming, blocking the event loop or main thread, or leaking connections and file handles) often slip through code review because they're tricky to spot across different languages and frameworks. It gets harder when a lot of code is AI-generated. Models tend to produce code that works but can introduce exactly these kinds of problems.
I wanted a single, structured reviewer that looks at merge requests from several aspects (standards, framework, language, design, alternatives, maintainability) and produces one consolidated, severity-ranked review instead of scattered comments.
What it does
In Duo Chat you can point it at a selection, a set of files, your local changes, or an MR and get a multi-aspect review with findings by category. When you ask, it can apply targeted fixes for high-confidence issues.
As a flow you assign it as an MR reviewer or @mention it. It infers the tech stack, runs seven aspect passes on the MR diff, merges findings by location, assigns severity (Critical, High, Medium, Low), and posts one Duo code review plus a short MR summary note with what changed and the severity breakdown. You get one place to see performance, scalability, security-overlap, and maintainability feedback with clear suggestions to fix issues.
How I built it
- One catalog agent. I defined the Performance & Scalability Code Scanner with a system prompt that covers all seven aspects and a toolset from the Duo catalog (read_file, grep, build_review_merge_request_context, edit_file, post_duo_code_review, create_merge_request_note). That same agent is used in Chat and as the building block in the flow.
- The flow has a tech-stack step, then seven aspect steps (same agent, different prompts per aspect), then a consolidator step that merges findings by location, assigns severity, and calls post_duo_code_review and create_merge_request_note.
- Reference material. I added CWE, CERT, OWASP and anti-pattern notes so the model has a consistent base for tech-agnostic findings.
Challenges I ran into
The main one was balancing depth and breadth in the prompts. The flow runs seven distinct aspects to get wide coverage. The hard part was how much detail to put in each aspect. Too little guidance and the model returns vague or off-target findings. Too much (long lists of patterns, many examples) and I hit the flow size limit, and the model could become rigid and only look for what's listed instead of reasoning about the code.
I fixed it by keeping each aspect's prompt tight. I used clear criteria and a short, illustrative list of patterns rather than an exhaustive checklist, plus an explicit "report only issues that matter" rule so the model uses its own judgment within each aspect.
Accomplishments I'm proud of
- One agent that works in both Chat and the MR review flow, so one definition serves ad-hoc review and automated MR review.
- A single, consolidated Duo review per MR with findings merged by location and severity-ranked, plus an MR summary note so reviewers can see what matters quickly.
- Seven aspects in one pipeline (tech-agnostic, framework, language, concept, better solution, better tech, maintainability) so teams get broad coverage without running separate tools.
- Tech-agnostic findings anchored to CWE, CERT, and OWASP where applicable, so the output is clear and useful.
- Optional, high-confidence fixes in Chat when the user asks, without doing risky big changes.
What I learned
I learned about GitLab Duo agents. You define what the agent does and which tools it can use, and the same agent can run in Chat or inside a flow.
I learned about flows. You chain steps and pass output from one step to the next, so you can run the same agent multiple times with different instructions.
I learned how the catalog tools make agents and flows powerful. They give the agent access to the repo and the MR, and let it post reviews and notes. Once I saw how agents, flows, and tools fit together, I could build something that actually reviews code and posts back to the MR.
What's next for Performance & Scalability Reviewer
The flow could run faster by running aspect steps in parallel if the platform allows. More targeted aspects or tighter scope rules could be added for better analysis.
Built With
- anthropic
- gitlab
- gitlabduo


Log in or sign up for Devpost to join the conversation.