-
Perforated Dendritic Inference Routing
-
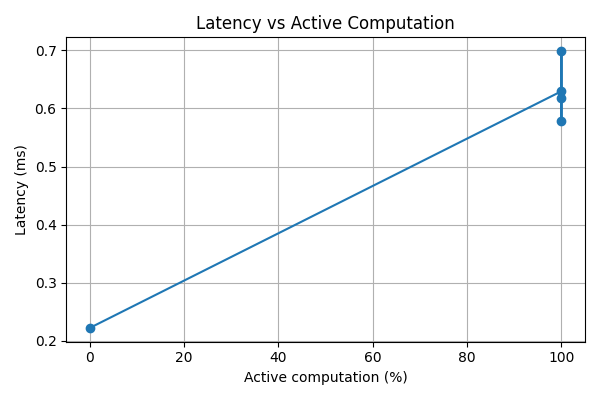
latency_tradeoff
-
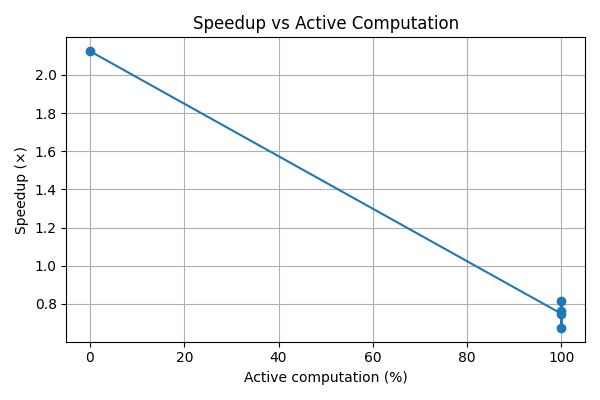
speedup_tradeoff
Inspiration
Modern neural networks typically execute all parameters for every input, even when large portions of computation contribute little to the final result. This leads to unnecessary inference cost and limits scalability, especially in deployment settings where latency and efficiency matter.
Recent work on dendritic optimization suggests that conditional computation can be introduced without redesigning models from scratch. We wanted to explore this idea from a systems perspective: can dendritic routing act as a drop-in inference optimization, and can its effects be measured cleanly and honestly?
What it does
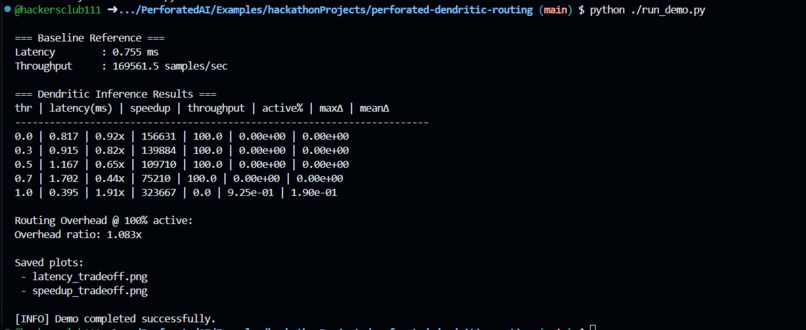
Perforated Dendritic Routing demonstrates how dendritic routing can be applied at inference time to selectively execute computation based on input characteristics.
The project:
- Wraps an existing PyTorch model without changing its architecture
- Applies per-sample routing to conditionally execute computation
- Measures wall-clock latency, throughput, and effective compute usage
- Reports output deviation to verify correctness trade-offs
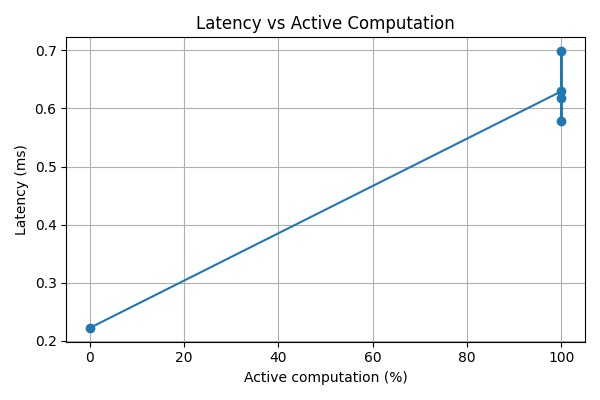
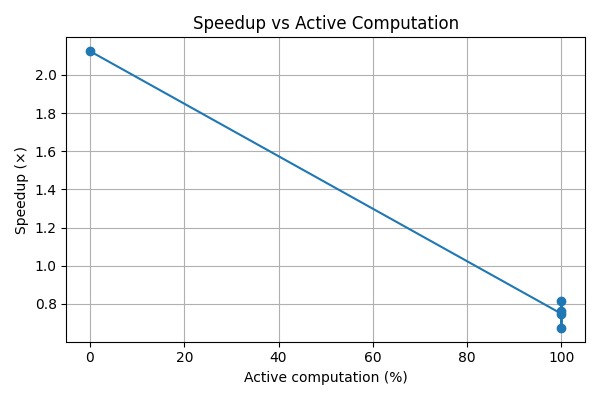
- Visualizes the relationship between active computation and performance
The result is a reproducible demo that isolates the impact of dendritic routing on inference efficiency.
How we built it
We implemented a small, deterministic baseline model and introduced a dendritic routing wrapper that decides, per input sample, whether to execute full computation or a lightweight approximation.
The system was designed to:
- Run entirely on CPU
- Avoid datasets and training pipelines
- Be deterministic and offline-safe
- Produce interpretable metrics and plots
A single script runs the full experiment, sweeps routing thresholds, records metrics, and generates trade-off visualizations.
Challenges we ran into
The main challenge was balancing realism with reliability. For small CPU-bound models, routing overhead can dominate computation, making speedups modest or even negative at high activity levels.
Rather than hiding this behavior, we chose to measure and report it explicitly. Designing routing logic that was both interpretable and produced meaningful active-computation variation without introducing instability required careful iteration.
Accomplishments that we're proud of
- Demonstrated dendritic routing as a true drop-in inference mechanism
- Measured and reported routing overhead transparently
- Produced clean performance–compute trade-off curves
- Built a fully reproducible, low-risk demo suitable for judge evaluation
- Maintained clarity without relying on large models or datasets
What we learned
Inference optimization requires honest measurement. Conditional computation introduces overhead, and its benefits depend on workload scale and characteristics.
By isolating routing effects and explicitly reporting both gains and costs, we gained a clearer understanding of where dendritic optimization is most effective and how it should be evaluated in practice.
What's next for Perforated Dendritic Routing: Efficient Computation
Future work includes applying the same routing mechanism to larger architectures, exploring learned routing policies, and integrating dendritic routing into real-world inference pipelines where computation dominates overhead.
This project serves as a foundation for evaluating dendritic optimization as a practical systems-level inference technique.
Built With
- inference
- learning
- machine
- optimization
- pytorch
- systems

Log in or sign up for Devpost to join the conversation.