-
-

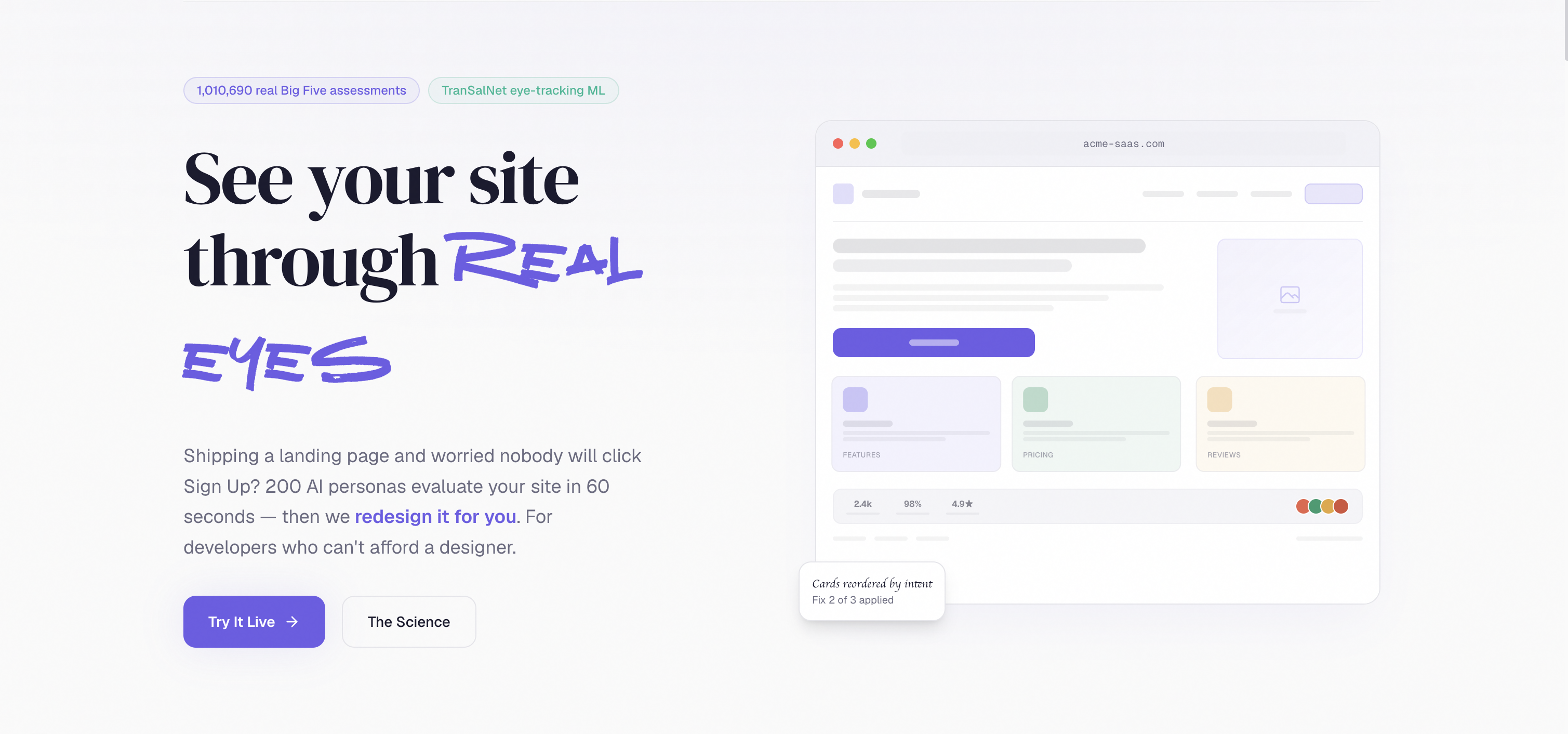
Perception Lab — see your site through real eyes
-
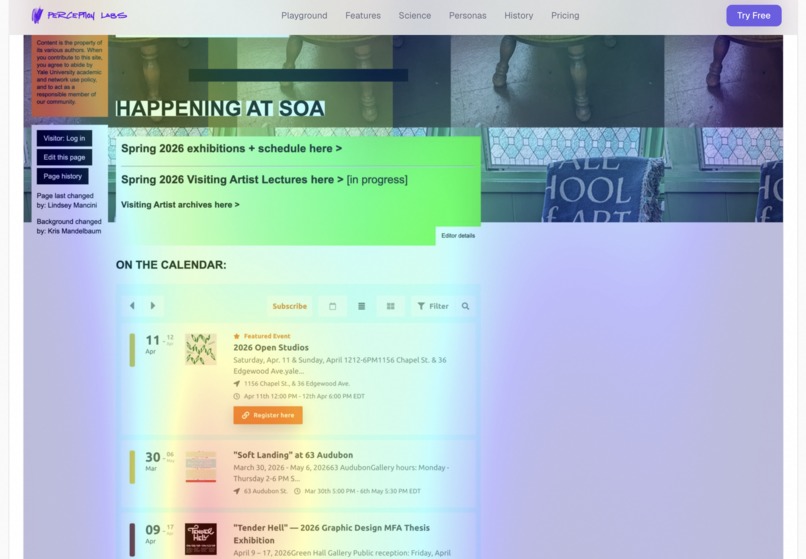
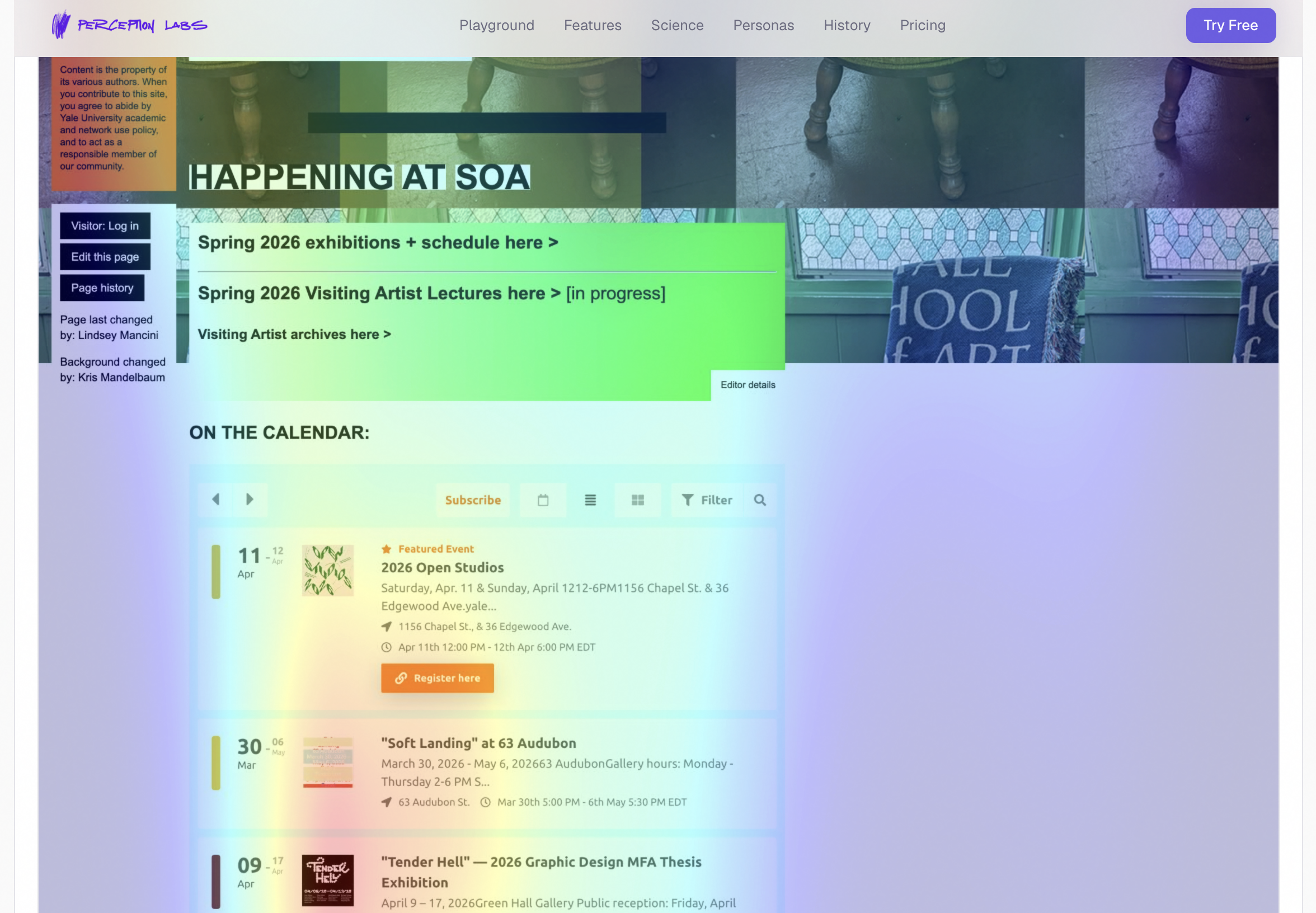
Real eye-tracking heatmap, predicting attention down to the pixel
-
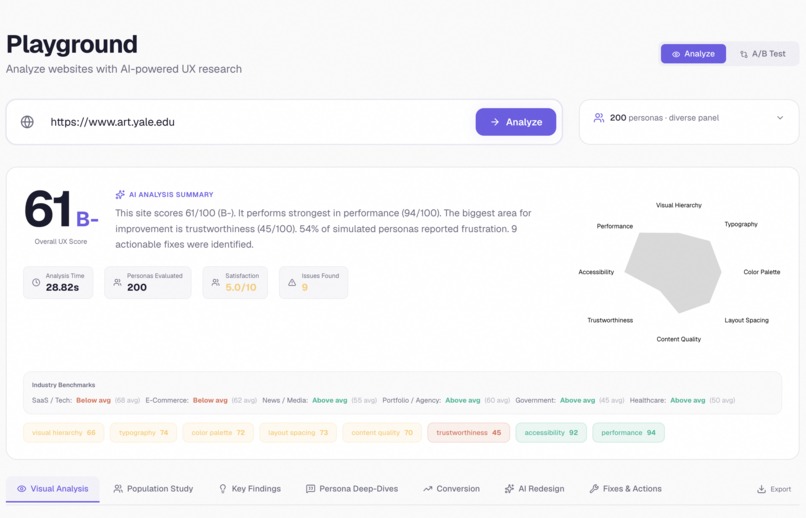
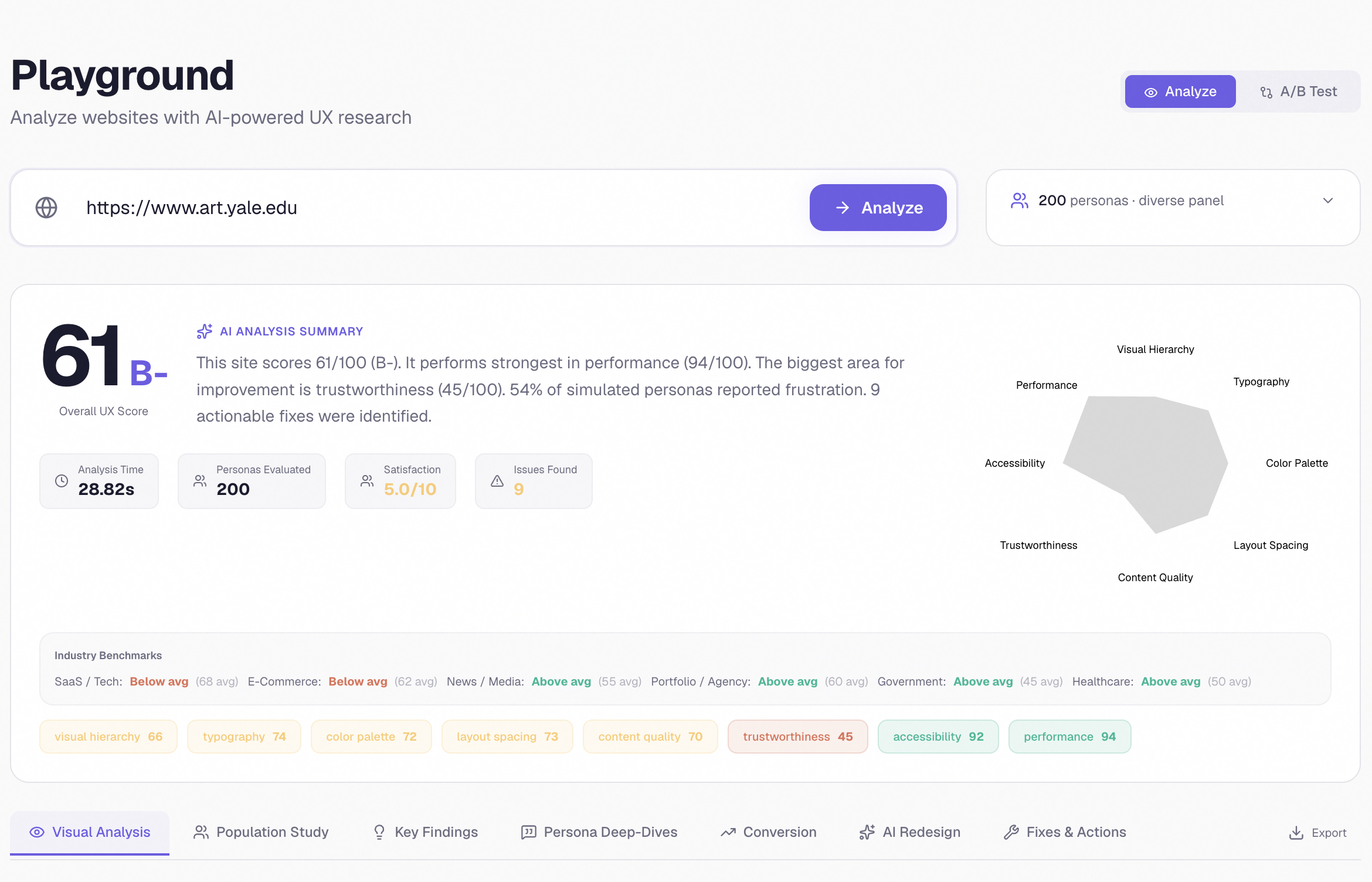
Paste any URL, get a full 8-dimension audit in sixty seconds
-
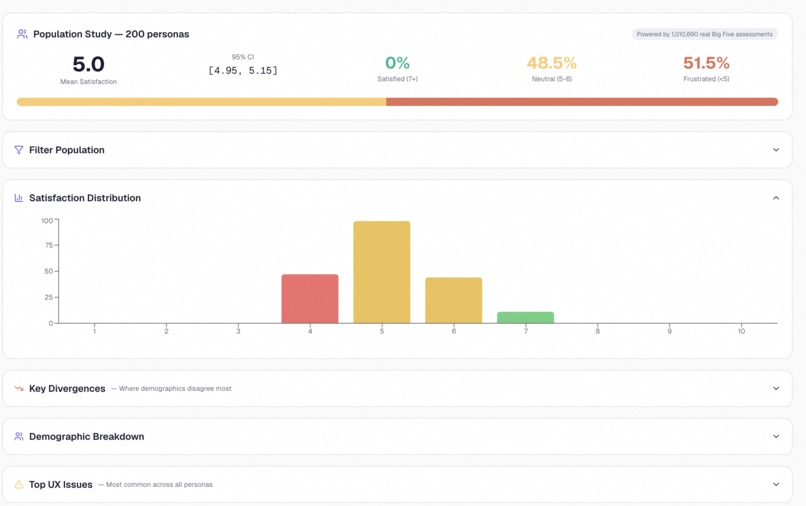
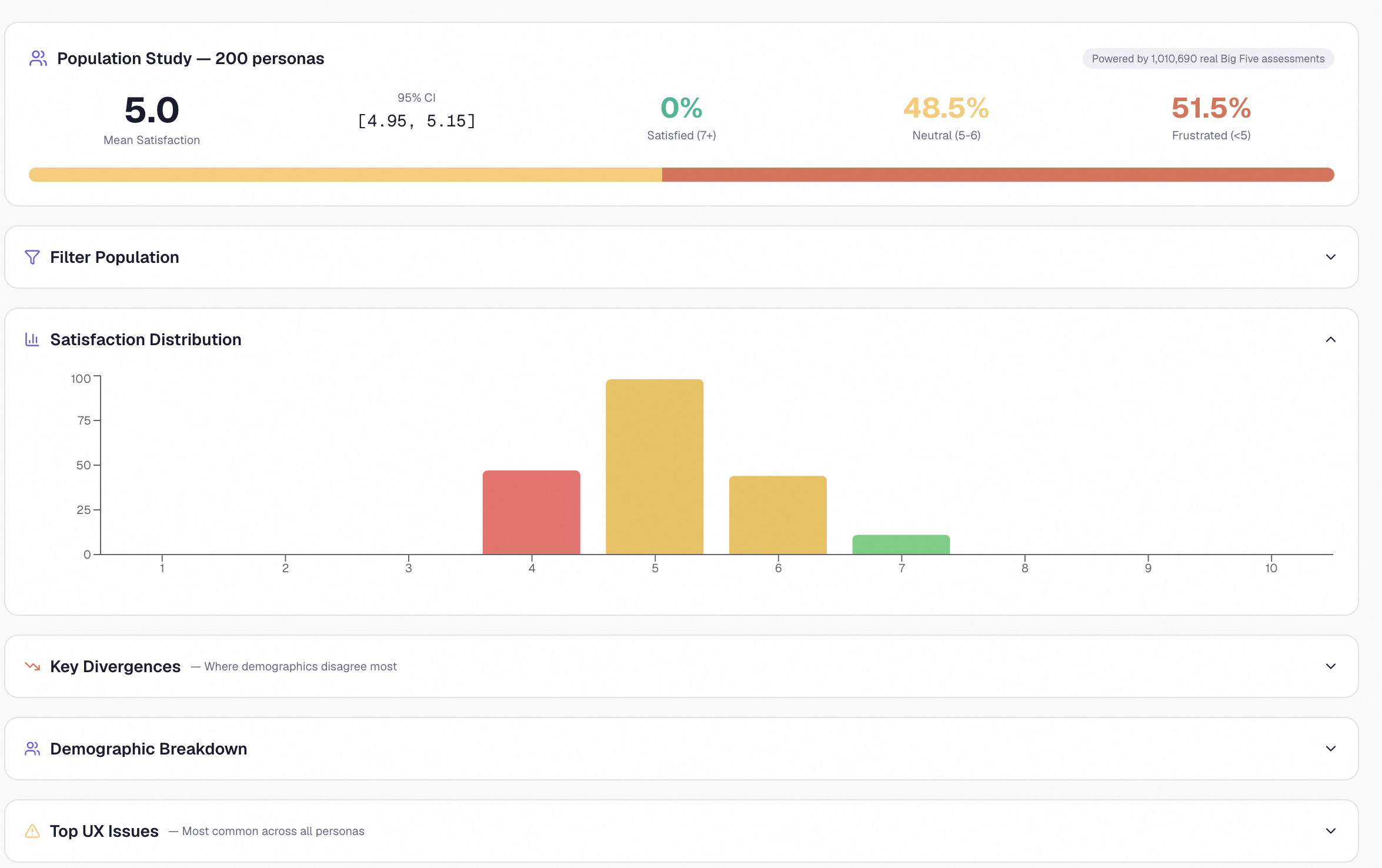
Population study — how 200 personas scored your site, broken down by demographic
-
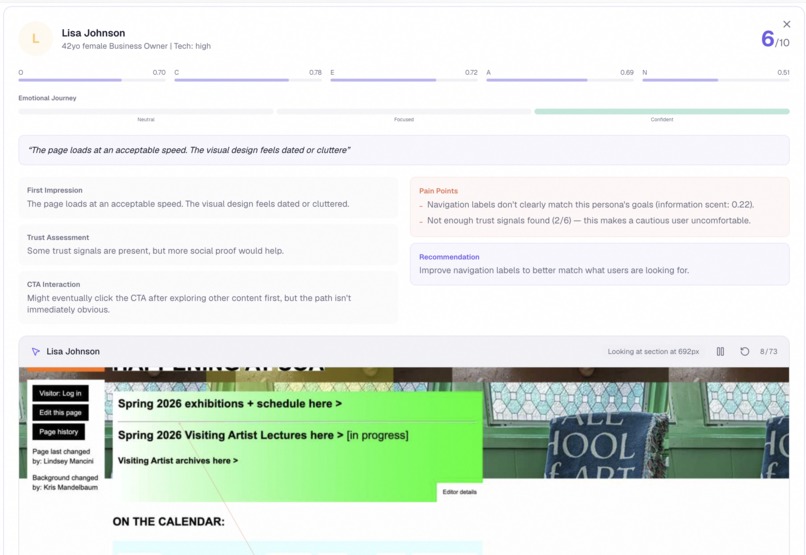
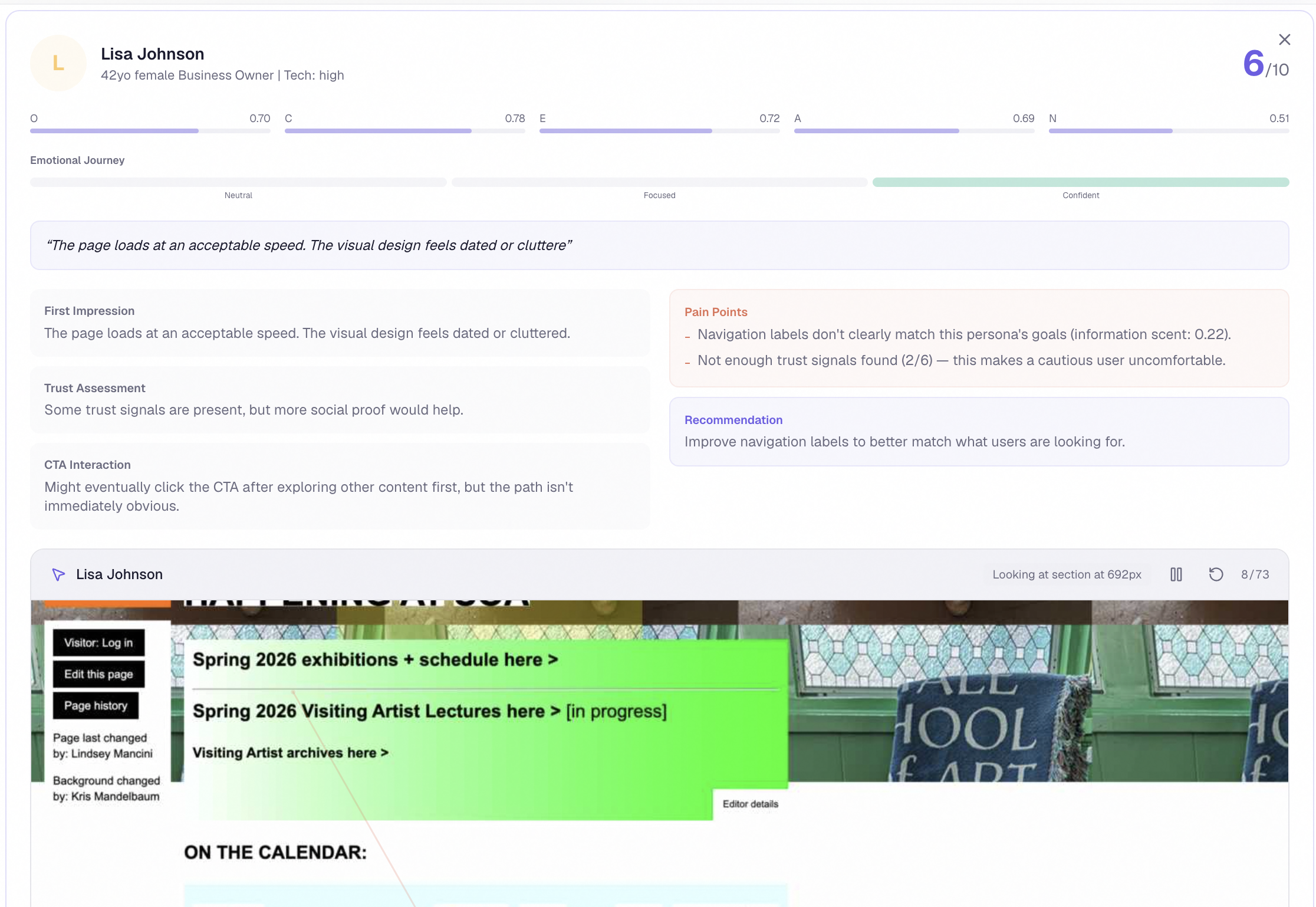
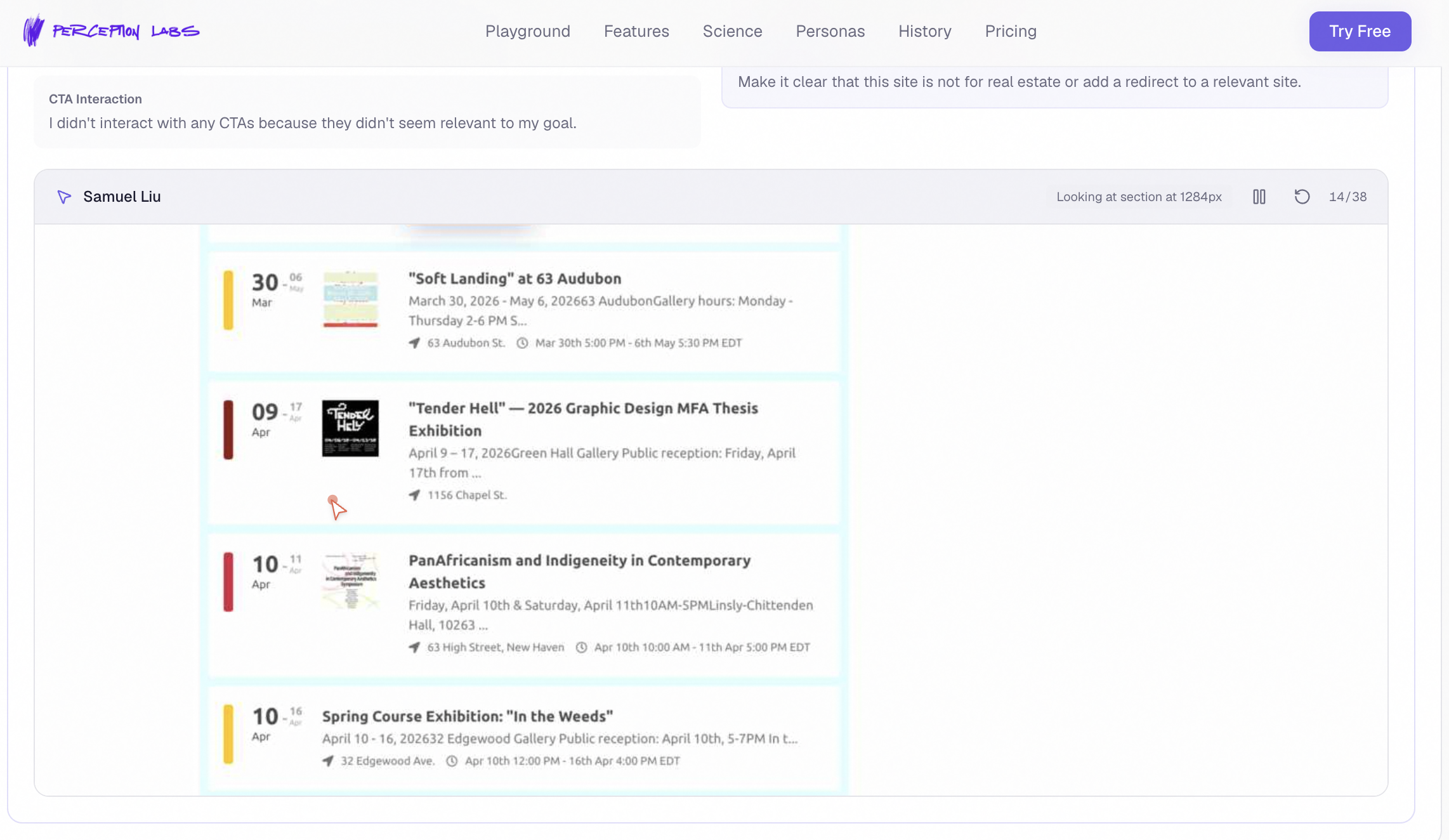
Drill into any persona — emotional journey, pain points, verbatim quotes
-
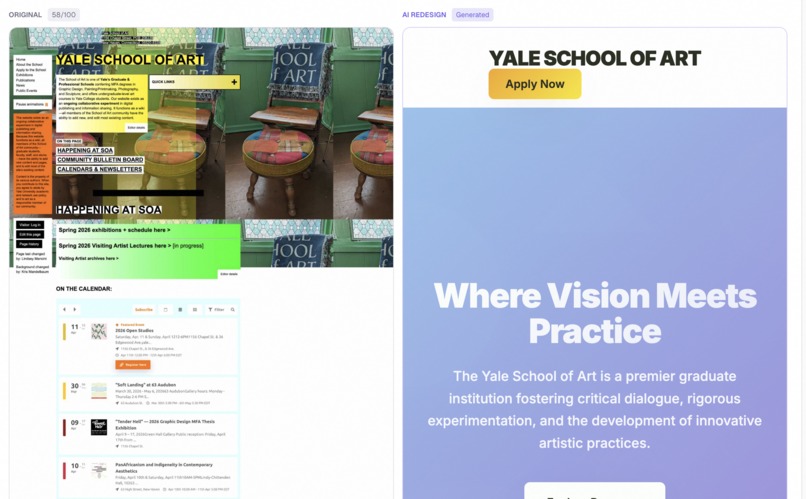
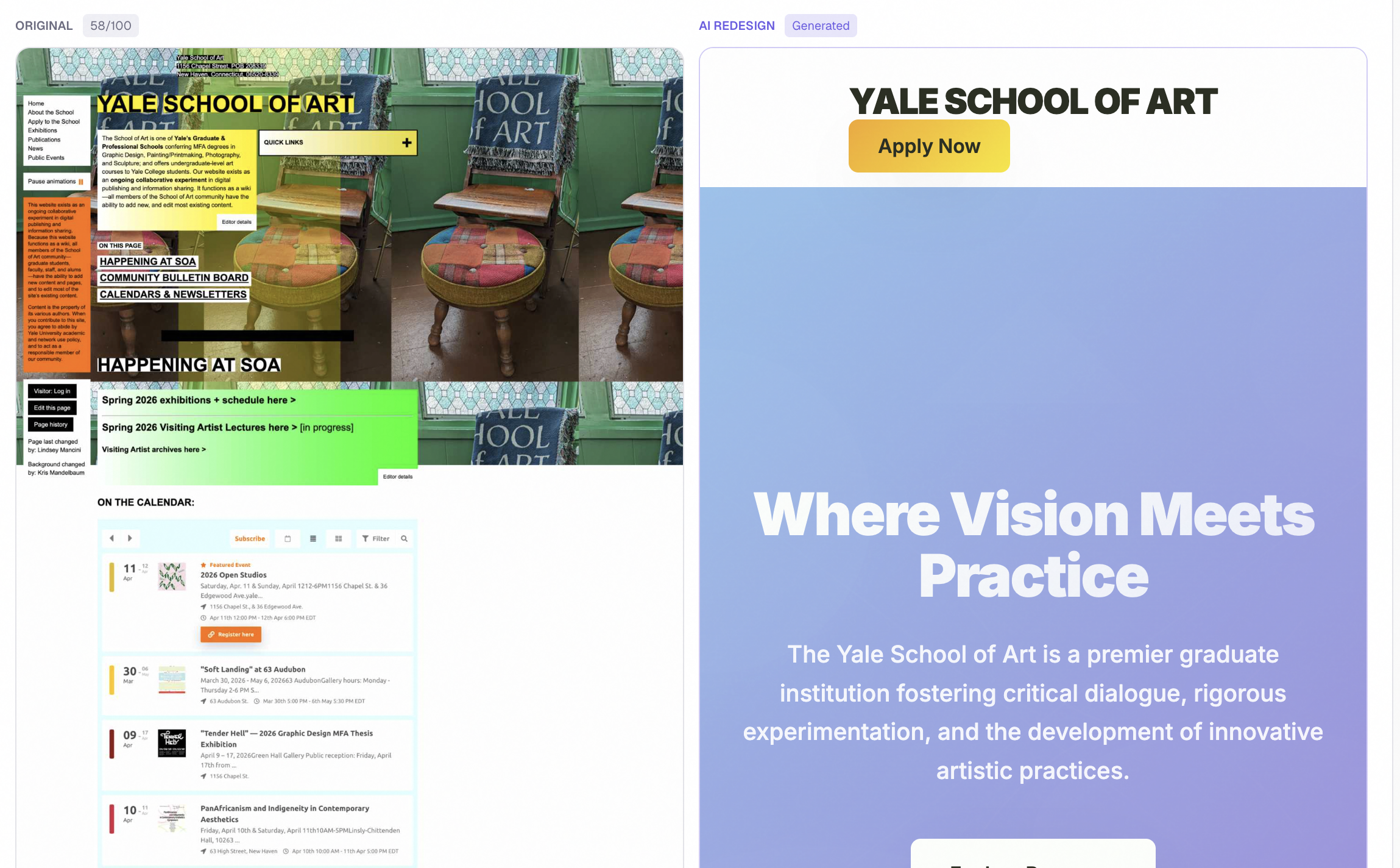
AI-generated redesign, rendered side-by-side with the original
-
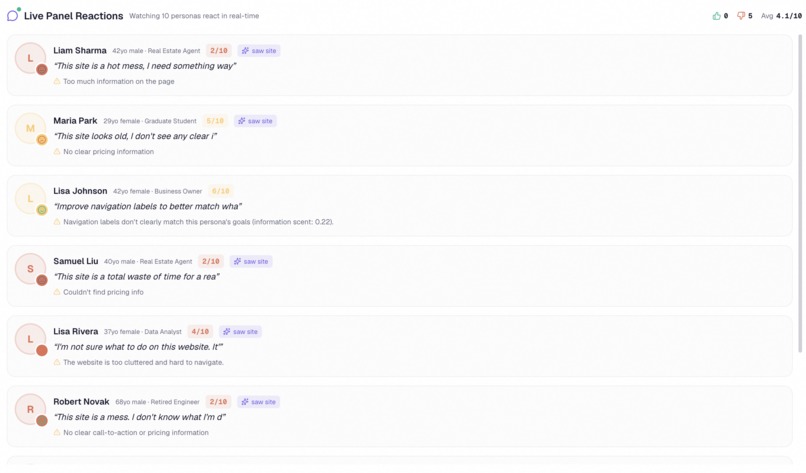
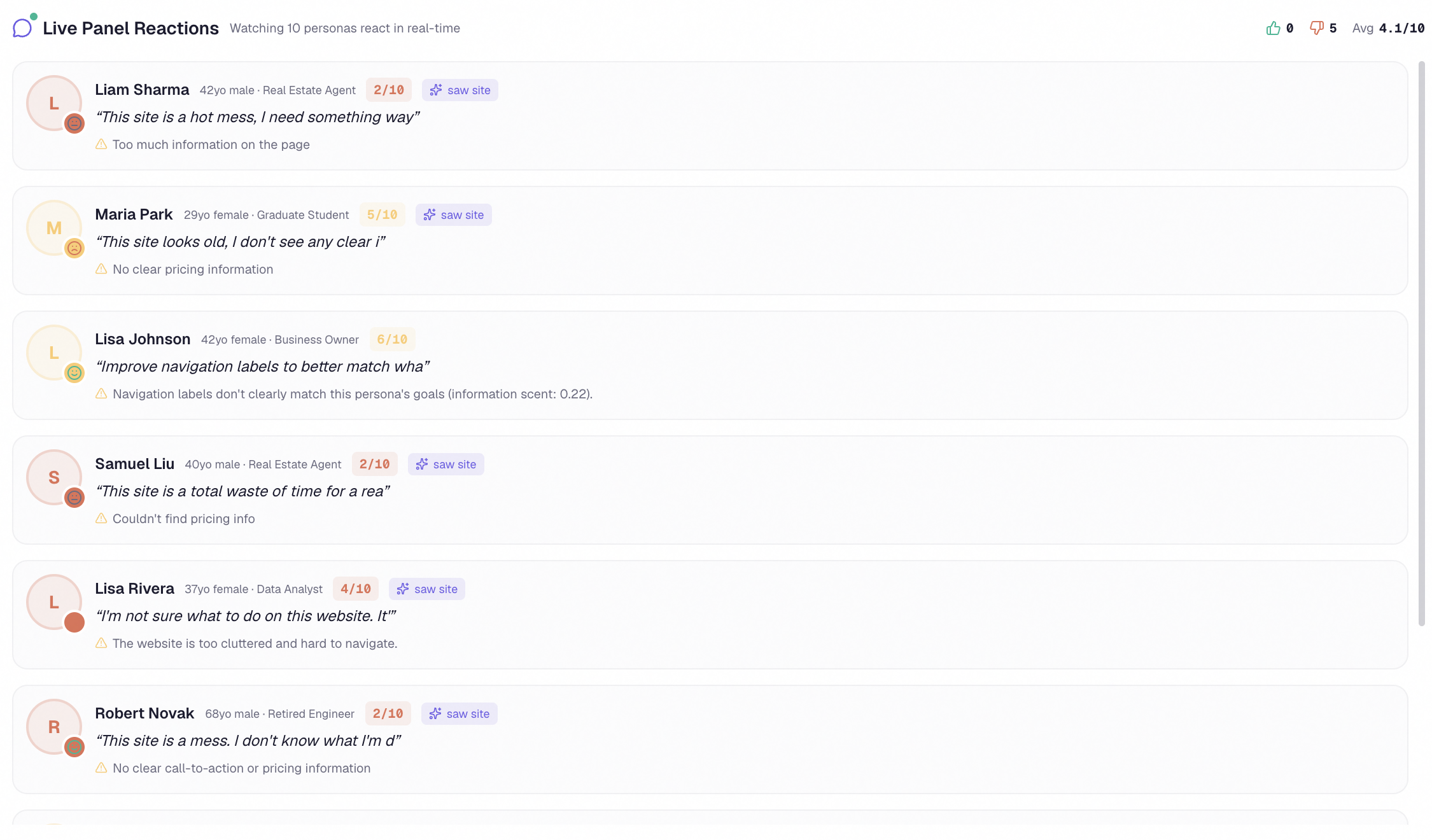
Watch all 200 personas react in real time like a live focus group
-
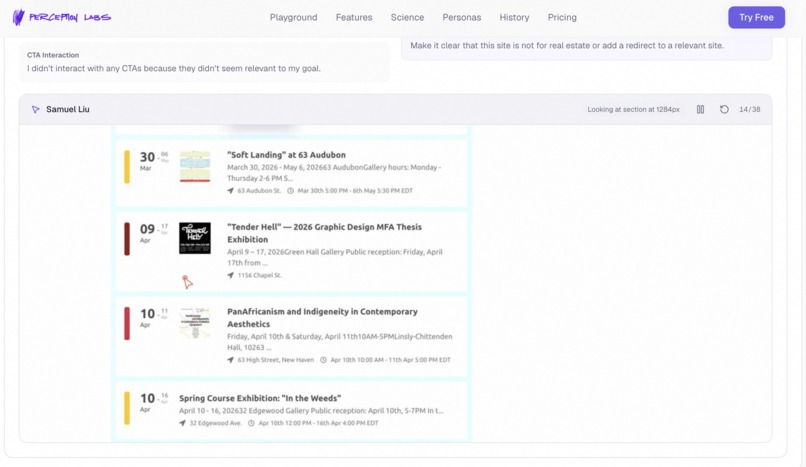
Browse recent analyses from across the community
-
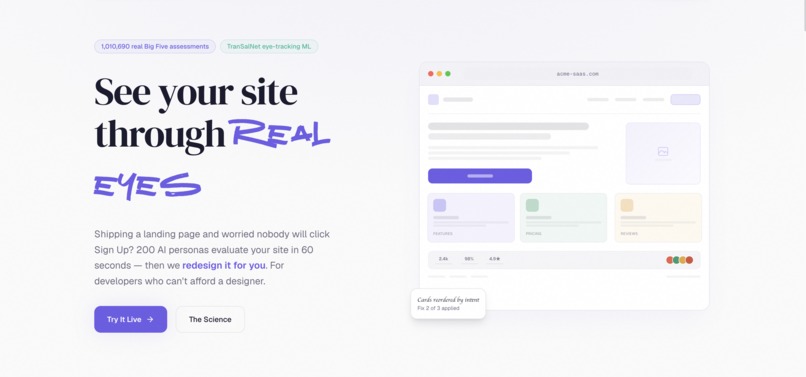
The landing page — a panel of real users, on demand
-
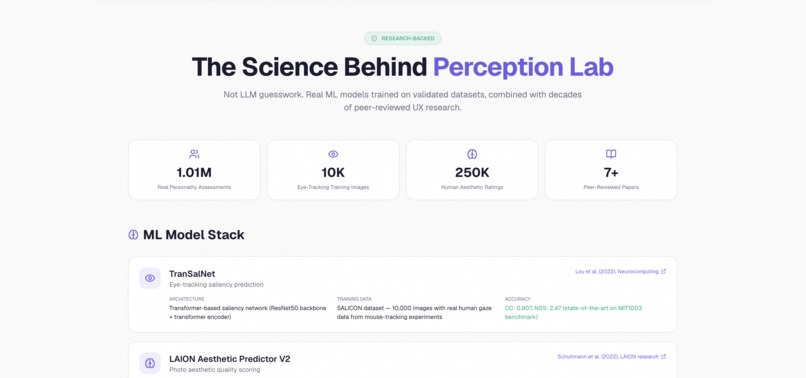
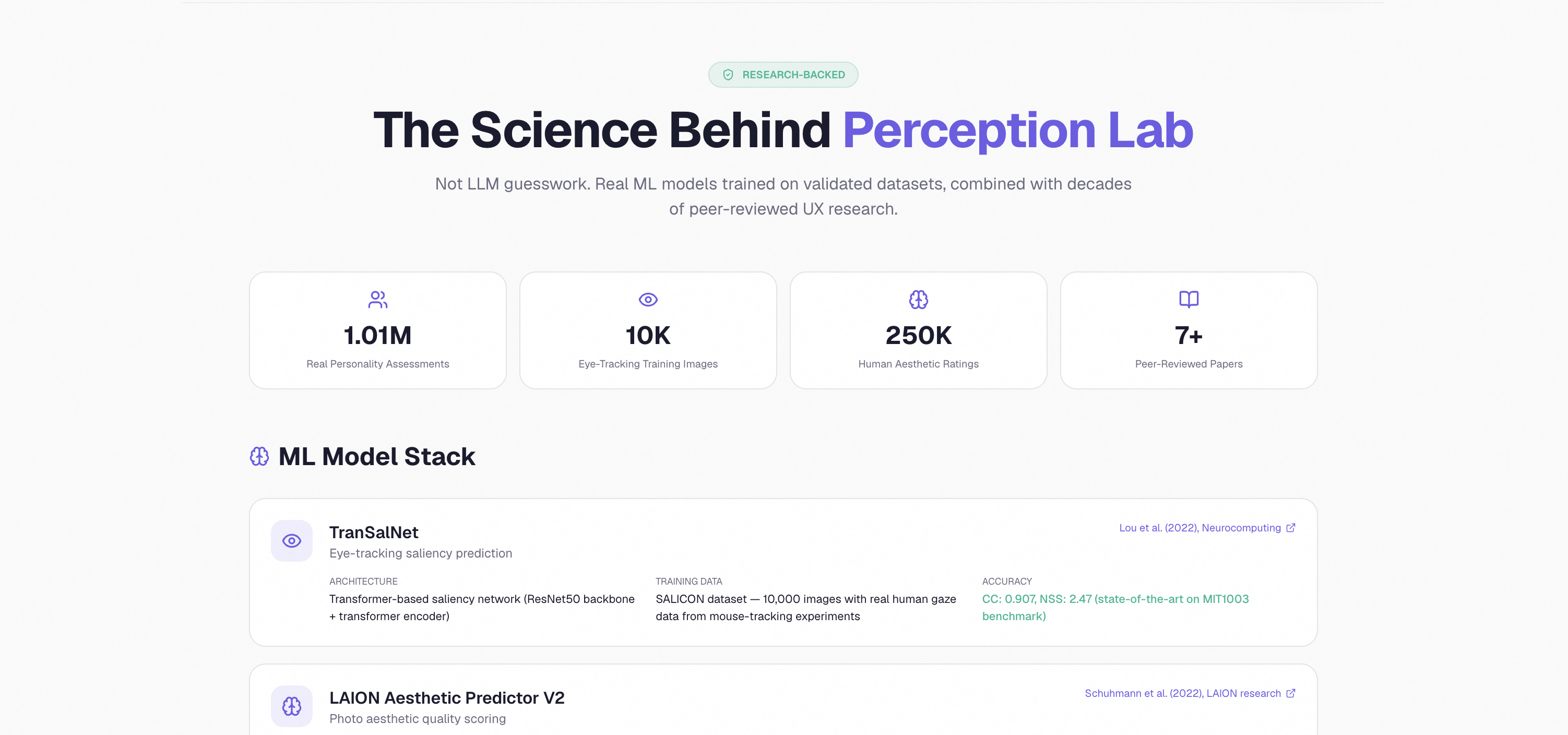
The science behind it — built on a million real Big Five responses, not LLM roleplay
-
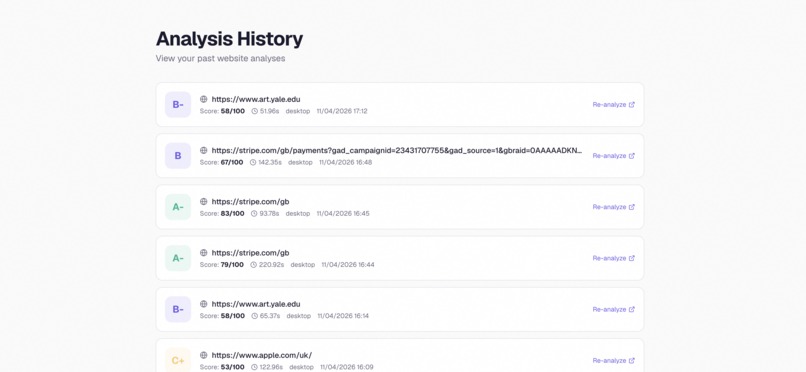
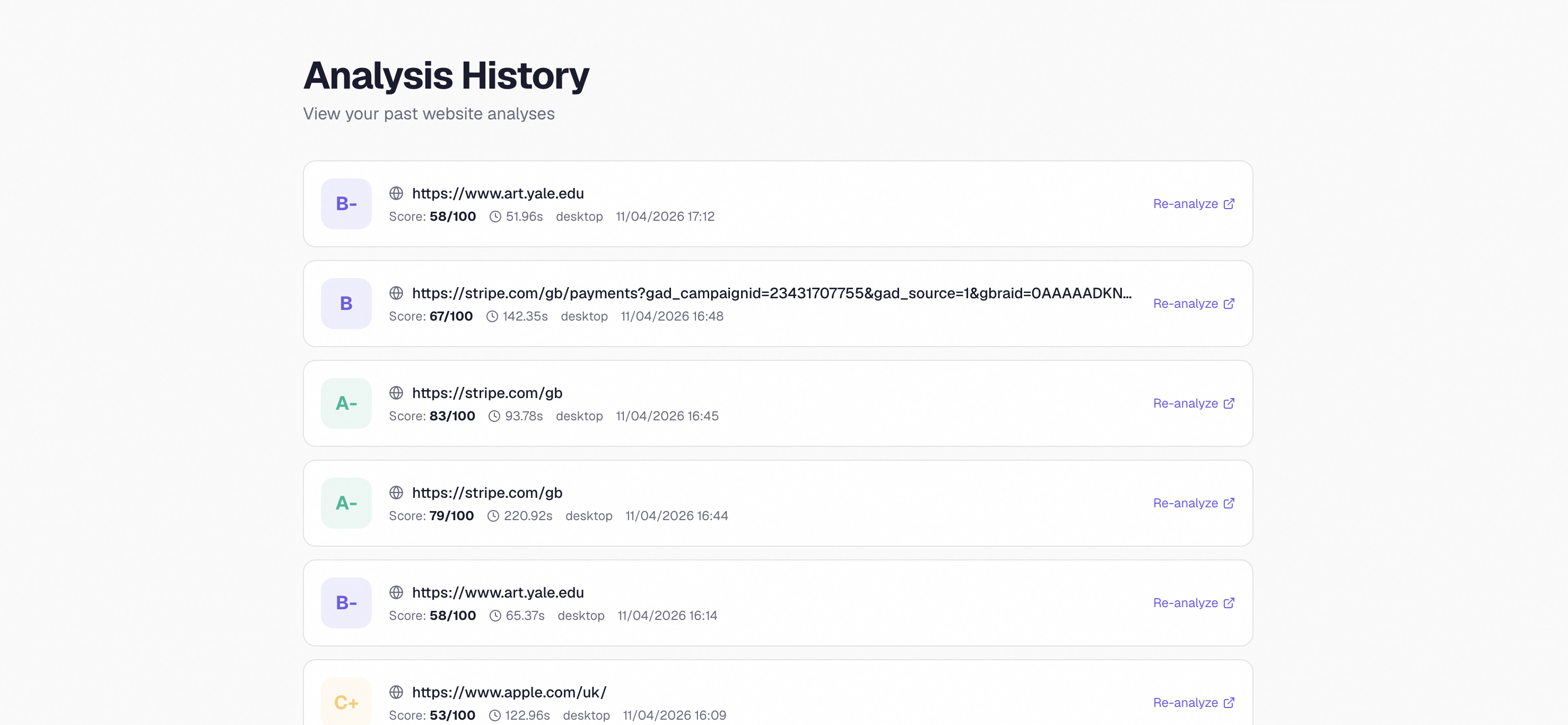
Analysis history — every past run, saved and replayable

Inspiration
I'm a data science student — I'm comfortable writing code, working with datasets, and reasoning about distributions and sampling, but design has always been the part of the stack I was the least sure about. So when I sat down recently to actually build a real website end-to-end, the front-end part was the bit that gave me the most trouble. Not because the code was hard, but because I genuinely had no way of telling whether my design decisions were good.
So I did what felt like the obvious thing — I sent the site out to a handful of people I trusted and asked for honest feedback. And the part I wasn't expecting was how much the feedback contradicted itself. One person told me the hero section was striking and the colors really worked, and the very next person said the exact same hero was the most overwhelming thing on the page. Someone praised the typography, someone else said the same font choice felt cold and corporate. The button placements I'd been agonizing over got called "clean" by one reviewer and "confusing" by another. Same elements, same screenshots, completely opposite reactions.
And the worst part was that I didn't know who to trust. Every person giving me feedback was smart, well-intentioned, and totally confident in their opinion — but they couldn't all be right at the same time. I had no way of knowing which of them represented a real slice of my actual users, and which of them just had personal taste preferences I shouldn't be optimizing around. So I was left sitting there with a pile of contradictory advice and no framework for sorting through it.
That was the moment it clicked. Coming from a data science background, I knew the answer to "whose opinion do I trust" is never "the loudest one in the room" — it's "the largest, most representative sample you can get." The problem with feedback from five friends isn't that they're wrong, it's that n equals five. What I actually needed was n=200, sampled from a distribution that looks like the real world, not from my immediate social circle. But running a real UX study at that scale costs around ten thousand dollars and takes six weeks, and most developers — including me — don't have either.
So I built the tool that gives you n=200 in sixty seconds, for free.
What it does
Perception Lab is a panel of over 200 simulated users that does UI/UX research on your website for you, on demand.
You paste a URL, and within sixty seconds you get:
- An 8-dimension UX score with a letter grade and a radar chart, plus benchmarks against real industry averages for SaaS, e-commerce, healthcare, and other categories
- A real eye-tracking heatmap generated by a neural network trained on actual human gaze data, predicting where attention lands down to the pixel
- 200 grounded personas reacting in real time, each one sampled from a dataset of over a million Big Five personality assessments, each one actually seeing your screenshot through a multimodal vision model and producing genuinely individual reactions, emotional journeys, and verbatim quotes
- A prioritized fix list with severity ranking and concrete CSS changes
- An AI-generated redesigned version of your page, fully coded in HTML and CSS, rendered side-by-side with the original
- A real GitHub pull request opened on your repo with the CSS fixes already staged
The whole thing runs on free-tier infrastructure and costs zero dollars per analysis.
How we built it
The system is built as four cooperating microservices.
The frontend is a Next.js 16 app with Tailwind, shadcn/ui, and Framer Motion, designed to feel like a polished SaaS product rather than a hackathon prototype. Every result page has a streaming feed of personas reacting in real time with a typewriter effect, an interactive heatmap with multiple overlay modes, a side-by-side AI redesign comparison, and a fully animated population breakdown.
The API gateway is a FastAPI service in Python that orchestrates the whole pipeline. When a request comes in, it kicks off the screenshot service, the ML service, and the persona engine in parallel, then aggregates the results into a single response.
The screenshot service uses Playwright to capture the full page, the DOM tree, performance metrics, and an axe-core accessibility audit, all in one shot.
The ML service is the heart of the system. It runs seven specialized models in parallel:
- TranSalNet, a saliency model trained on the SALICON dataset of real human eye-tracking data, generates the actual heatmap
- LAION Aesthetic Predictor V2 (a CLIP+MLP model trained on over 250,000 human-rated images) gives a calibrated visual quality score
- OpenCV computes design metrics like colorfulness, complexity, whitespace ratio, color harmony, and visual symmetry
- PaddleOCR verifies font sizes against accessibility minimums
- axe-core runs the WCAG accessibility audit
- SentenceTransformers computes information scent for navigation predictions
- A multimodal LLM layer running across Gemini, Groq Llama-4, and OpenRouter — with full failover between six different providers — handles persona simulation, fix suggestions, and the AI redesign generation
The persona engine is where the project's heart lives. We took the public-domain IPIP-FFM Big Five dataset, which contains 1,010,690 real personality responses from real human beings, ran a Gaussian Mixture Model clustering pass over it to extract eight statistically grounded archetypes, and then sampled 200 personas with calibrated demographics — age, gender, occupation, internet literacy, accessibility needs, cultural background. Every single persona is then handed the actual screenshot of the site through a multimodal vision model, so they're not hallucinating reactions from a URL — they're literally looking at the page.
The AI redesign generator uses a six-provider fallback chain (Gemini 2.5 Flash, Gemini 2.5 Flash Lite, Groq Llama-4 Scout, Groq Llama-3.3, OpenRouter Llama-4 Maverick, DeepSeek) to generate a complete multi-section landing page with inline SVG icons, gradient backgrounds, and proper typography. Whatever provider is up, the redesign ships.
The GitHub PR feature uses the GitHub API to clone the user's repo, generate a CSS patch from the identified issues, commit it on a new branch, and open a real pull request — turning "here's what's wrong" into "here's a PR you can merge."
Challenges we ran into
Personas weren't actually seeing the website. The first version of the persona engine just passed the URL and DOM to an LLM and asked it to roleplay a reaction. The reactions were generic, hallucinated, and worse, every persona sounded basically the same. The fix was to wire vision support through every single LLM provider in the chain — Gemini, Groq, OpenRouter — and pass the actual screenshot bytes all the way down. Once personas could see the page, the reactions became dramatically more grounded and varied.
The eye-tracking heatmap was only showing the top of the page. The first time it ran, the heatmap covered the visible viewport and then everything below was empty. The screenshot was being truncated because the base64 payload was hitting size limits. The fix was to compress the full-page screenshot into JPEG quality 45 at 1280px width using Pillow — small enough to send, large enough for the saliency model to still produce meaningful predictions.
Every LLM provider got rate-limited at the worst possible time. Gemini 2.5 Flash's free tier is twenty requests per day, and we burned through it in an afternoon of testing. We built a six-provider fallback chain with circuit breakers that mark a provider as unavailable for two minutes after a 429, so the system gracefully degrades through Gemini Flash → Flash Lite → Groq → OpenRouter → DeepSeek without ever failing the user.
Scores were uniform and uncalibrated. Every site we tested was scoring around 70/100, which wasn't useful or believable. We had to fundamentally rethink the scoring formula — adding clutter caps, monochrome penalties, ML aesthetic bonuses, and proper calibration against real sites. Apple now scores 77 (B+), Stripe scores 81 (A-), Linear 67 (B), and Craigslist scores 45 (C). The diversity makes the scores actually mean something.
The AI redesign was producing minimal HTML. The first version generated bare-bones pages with just a hero section and a button. The fix was a much more demanding prompt that required ten specific sections, gradient backgrounds, inline SVG icons, and a minimum character count, plus much higher token limits on every provider.
The live persona feed was showing only the first letter of every quote. A subtle React bug — the validPersonas array was being recomputed on every render, and the typewriter effect's useEffect had it in the dependency array, so the interval was being cleared and reset on every state update before the index could even reach two. The fix was wrapping validPersonas in useMemo. Took an hour to find, three characters to fix.
Server-Side Request Forgery vulnerabilities. The screenshot service originally accepted any URL, which meant a malicious user could point it at internal services like http://169.254.169.254/ (AWS metadata) or http://localhost:5432. We added a URL validator that blocks private IP ranges, cloud metadata endpoints, link-local addresses, and non-HTTP schemes.
Accomplishments that we're proud of
- The persona grounding is real. Over a million actual Big Five responses, GMM-clustered into archetypes, sampled with real demographic calibration. These aren't LLM roleplays.
- Seven ML models running in parallel in production, with end-to-end analysis in under sixty seconds.
- Real eye-tracking predictions, not heuristics. TranSalNet was trained on actual human gaze data and we're using it as it was meant to be used.
- The AI redesign actually works. It generates a complete, multi-section, fully-styled HTML page that you can render side-by-side with the original.
- Zero-cost infrastructure. The entire stack runs on free tiers — Gemini, Groq, OpenRouter, Supabase, free Cloud Run credits — which means anyone, including the solo developers and indie founders we built it for, can use it for free.
- It's a real product, not a demo. Every result is real. There are no hardcoded values, no fake screenshots, no pre-computed personas. Every analysis runs the full pipeline live.
What we learned
Multimodal vision is the unlock for persona simulation. Text-only LLM personas always end up sounding like the same character with different name tags. The moment you let them see the screenshot, their reactions diverge in genuinely human ways.
Psychometric grounding matters more than prompt engineering. Nobody's going to be impressed by "please pretend you're a 60-year-old retired teacher" — but sample that same persona from a real GMM cluster of a million responses and it suddenly produces reactions that feel like they came from an actual human focus group.
Rate limits are the silent killer of any LLM-based product. If you ship without a fallback chain, your demo will fail in front of a judge at the worst possible moment. We learned this the hard way.
LLMs minimize unless you force them not to. The first version of every prompt produced output half the length we wanted. The fix is not subtlety — it's hard requirements with character minimums and explicit section lists.
Subtle React bugs hide in useEffect dependency arrays. If you put a recomputed array in there, you've built an infinite loop generator. Memoize aggressively.
The real gap in design feedback isn't quantity, it's representativeness. Every existing tool either gives you n=1 (one designer's opinion), n=5 (a few friends), or n=10K (a real study you can't afford). There's nothing in between. And the n=5 case is the worst of all worlds, because it gives you contradictory opinions you have no framework for resolving — you can't tell whether the disagreement is meaningful signal or just noise from a tiny, biased sample. Coming from a data science background, the answer was obvious: you fix that by sampling properly, at scale, from a distribution that actually looks like your users. That's the gap Perception Lab fills.
What's next for Perception Lab
- Browser agent personas that actually click through the site, fill out the forms, and report what broke — not just react to the screenshot
- Real eye-tracking validation via WebGazer.js, so we can compare our TranSalNet predictions against actual user gaze data and calibrate the model further
- Industry-specific persona libraries — pre-built panels for fintech, healthcare, e-commerce, gaming, so you can test against the audience you're actually trying to reach
- A/B testing mode where you upload two designs and the personas vote on which one they prefer, with a statistical significance test
- Self-hosted vision model so the whole pipeline can run offline without any external LLM dependency
- Multi-page analysis that crawls your entire site (home, pricing, about, contact) and tells you which page is the weakest link in your conversion funnel
- Public persona library where users can browse all 200 personas, see their full personality profiles, and request specific subsets for their analysis
The vision is simple: every developer, every designer, every founder should have a focus group in their pocket. Perception Lab is the start of that.
Built With
- axe-core
- clip
- deepseek
- docker
- fastapi
- framer-motion
- gcp
- gemini
- github-api
- groq
- laion-aesthetics
- llama-4
- multimodal-llm
- nextjs
- numpy
- opencv
- openrouter
- paddleocr
- pandas
- pillow
- playwright
- postgresql
- python
- pytorch
- react
- scikit-learn
- sentence-transformers
- shadcn-ui
- supabase
- tailwindcss
- transalnet
- typescript
- vercel
Log in or sign up for Devpost to join the conversation.