



Inspiration
A wave of AI-built apps ship to production with no backend, no auth model, and secrets sitting in the client bundle. The people building them aren't security engineers and can't afford a pentest. We saw this hit home directly: at two of our members' school, a previous-year student-council tech exec built an app called FraserPay, a digital wallet and ledger for school events. It was largely AI slop, and it shipped with real vulnerabilities that had real consequences, exactly the kind of "no real backend, trust the client" app we kept running into. This year someone actually exploited it, credited themselves a huge amount of funds, and the whole thing now has to be rebuilt from scratch without the holes, a perfect example of why a cheap, local pentest should have run before it ever went live.
We wanted a tool that does what a pentester does, reading the code, attacking the running app, and explaining the risk in plain language, but one that runs locally, costs pennies, and meets developers where they already are: a terminal. The pattern behind FraserPay kept showing up everywhere: a Supabase or Firebase app spun up in a weekend, a service-role key shipped to the browser, and database rules left wide open because there was never a real backend to enforce them. Existing scanners either drown you in false positives or never prove anything is actually exploitable, so we set out to build one that confirms the bug, and ideally fixes it, before someone like the FraserPay attacker finds it first.
How we built it / What it does
A Python CLI/REPL with a modular scan pipeline: source resolver → repo walker → static detectors → dynamic/active probes → AI review → redaction → findings store → report/fix. Claude powers the AI review, the assistant, and the fix engine; OSV.dev backs dependency scanning; MongoDB Atlas + Voyage AI store a cross-scan knowledge base; and a Vultr GPU tier runs an uncensored local model for deep, autonomous breach testing. Everything else is standard-library Python so the core works with zero extra dependencies. Each stage is a self-contained module that hands typed findings to the next, which let us add whole new probe classes (brute-force, netscan, browser crawl, load test) without touching the orchestrator. Redaction sits as its own pass right before anything is persisted, so no secret reaches disk, a report, or an API regardless of which detector produced it. You drive it either through an interactive REPL (python -m penny → /target, /audit, /findings, /report, /fix, plus natural language) or scriptable subcommands for CI (scan, run, report, ask, fix, patch, github-fix, sandbox-test, etc.), and a scan runs a pipeline of source resolver → repo walker → orchestrator that fans out to static detectors (20+ checks for secrets, RLS, SSRF, XSS, injection, weak crypto), opt-in active probes (--active: SQLi, reflected XSS, Firebase open rules, NoSQL/SSTI/traversal/command injection, SSRF, JWT/GraphQL, headers/cookies/CORS/exposed-file checks, plus --brute/--browser/--netscan/--load-test), an AI review pass (--ai), and OSV dependency CVE lookups (--osv), before deduping, redacting secrets, storing findings, and feeding report/ask/fix—all funneled through a single TargetGate that enforces read-only methods, rate limits, same-origin, and DNS-proof ownership for public targets, with a Vultr GPU sandbox tier for autonomous breach testing. How 'fix' works is through a MCP handoff for CC or Codex, this way we aren't using the lesser models of sonnet/haiku and allows users to have more control over what is changed in their code base.
Challenges we ran into
Keeping the offensive features genuinely safe was the hardest part. Every probe had to be funneled through one guardrail (read-only methods, rate limits, DNS-proof ownership checks) so Penny can never hit a target it isn't allowed to. The vLLM server was the biggest time sink: each GPU box took 30 to 45 minutes to bake, so every bug fix turned into a waiting game, and we had to get CUDA/driver pinning, abliterated-model tokenizers, and crash diagnostics right to stop burning whole bake cycles on a single mistake. We solved the iteration tax by baking the GPU image once into a reusable snapshot, so test runs provision from the snapshot in minutes instead of rebuilding from scratch. On top of that, making sure no raw secret ever reaches disk or an API meant redaction had to be airtight end-to-end, which forced us to rebuild every AI-returned snippet from the real source line so the model could never smuggle an unredacted value into persisted output. Also the MLH vultr code redemption didn't work so we had to use our own money causing us to need a cheaper GPU (causing longer times + using a lower param model).
Accomplishments that we're proud of
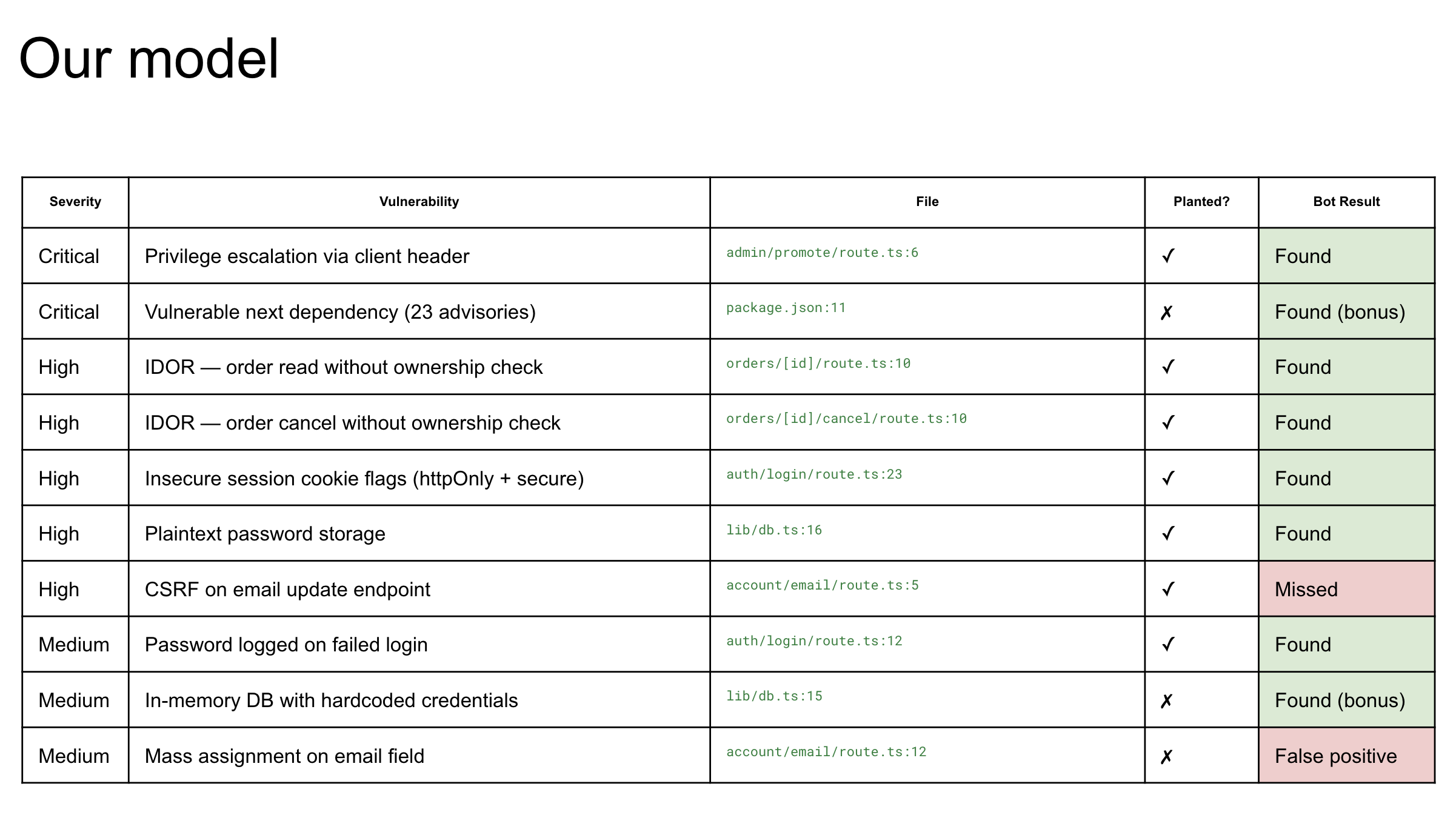
Penny proves vulnerabilities instead of just listing them, and it does so without ever sending a destructive request. The safety model is real, not a disclaimer. The whole core loop (scan, triage, report, fix) works completely offline, and the optional cloud tier can spin up a GPU, run an autonomous r agent, and self-destruct, all behind a hard cost cap. We're proud that every external service is genuinely opt-in and opt-out, so the tool degrades to local-only behaviour the moment a key is missing rather than failing. And the public-target authorization (ownership flag plus a matching DNS TXT proof record) means Penny physically cannot attack a host you haven't proven you own.
What we learned
A lot of practical offensive security: SQLi confirmation, BOLA/IDOR, the OWASP API and LLM Top 10, TLS/MitM exposure, CORS preflight abuse, the client/server trust boundary that breaks "no-backend" apps. On the infra side we learned to provision and tear down GPU VPS boxes safely (Vultr), serve a model with vLLM, and use an abliterated (decensored) model so a red-team agent doesn't refuse its own task, while keeping that firepower fenced behind ownership proof and auto-destroy timers. We also learned how much careful engineering "safe by default" actually takes: it's not a policy, it's a single gate that every request, from a static probe to the GPU sandbox, has to pass through before it leaves the machine. And working with MongoDB Atlas vector search plus Voyage embeddings taught us how to build a cross-scan knowledge base that shares generic patterns without ever storing a customer's code or secrets.
What's next for Penny
Penny is still very much a work in progress: the core scan, confirm, report, and fix loop is solid, but plenty of the more ambitious pieces are early and actively being built out. Next up is running a far larger abliterated model on the GPU tier for deeper, more capable autonomous breach reasoning, and expanding the cloud functions: more attack types, multi-box parallel runs, and longer agentic exploitation chains. Alongside that, we want broader language coverage, deeper Atlas-vector knowledge sharing across scans, and a CI-native mode that comments findings inline on pull requests. The knowledge base in particular is just getting started, and the goal is for it to get smarter with every scan, surfacing the fixes that worked for similar findings across projects. Longer term, we want to make a real, confirming pentest a default step in every developer's workflow rather than a budget line item they skip, but there's a lot of polish, testing, and hardening still ahead before it gets there.


Log in or sign up for Devpost to join the conversation.