-
-
Drag and drop your text file
-
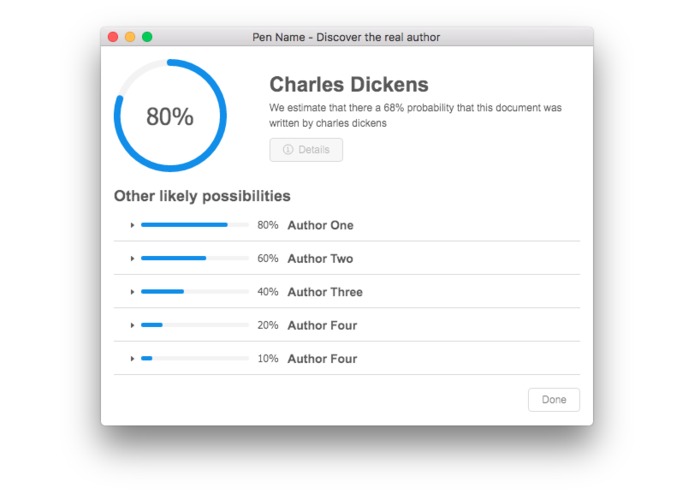
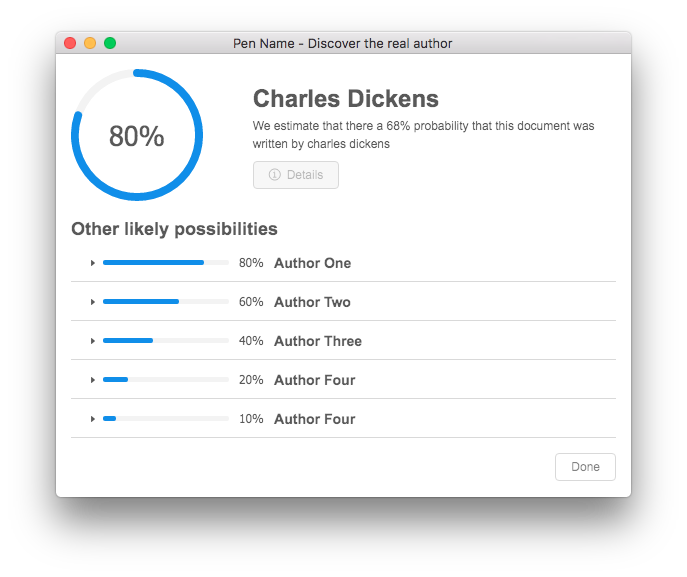
Results view will show you which author it's most likely to be (depending on which authors have been trained on)
Inspiration
Plagiarism is a rampant problem with difficult and ineffective solutions. Machine learning can be used to synthesize what makes an author's work unique, reducing overhead for plagiarism searching, and improving enforceability for things like trademarks.
What it does
Pen Name trains on a corpus of text known to belong to certain authors. Inputting a new text, Pen Name will predict how likely it is that it belongs to a particular author.
How we built it
Will worked with, trained, and built the machine learning algorithm in python and tensorflow, having a background in these areas. I built a front-end that executed his python script and displayed the results in an app packaged with electron (a node.js package).
Challenges we ran into
Scope is the most difficult problem. We sacrificed some things we wanted to do to get it working within the timeframe.
Accomplishments that we're proud of
We built a proof of concept! From here, we can improve the accuracy and functionality.
What we learned
How to build desktop apps, how to do natural-language machine learning.
What's next for Pen Name
There are many things we would like to improve on, such as using word vectors, and providing visibility into what makes an author's work unique, which can then be used for other functions like automated searches. For an idea of what word vectors are and how powerful they can be, look at Word2Vec, and some of it's examples/

Log in or sign up for Devpost to join the conversation.