-
-

Peers computation on different threads
-

GPUs accelerated peers rendering
-
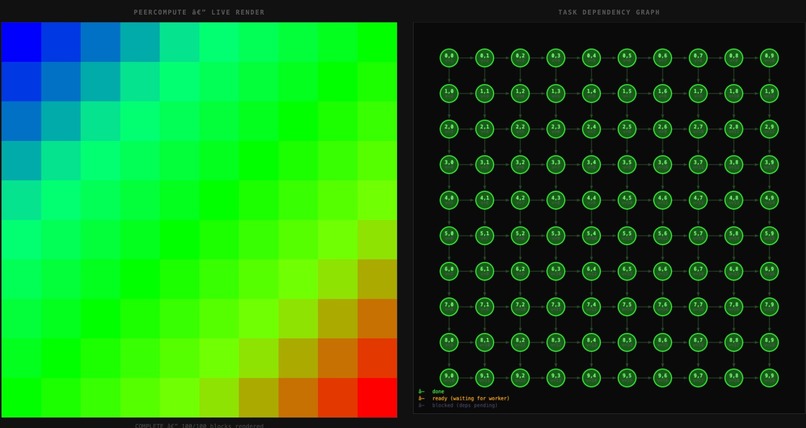
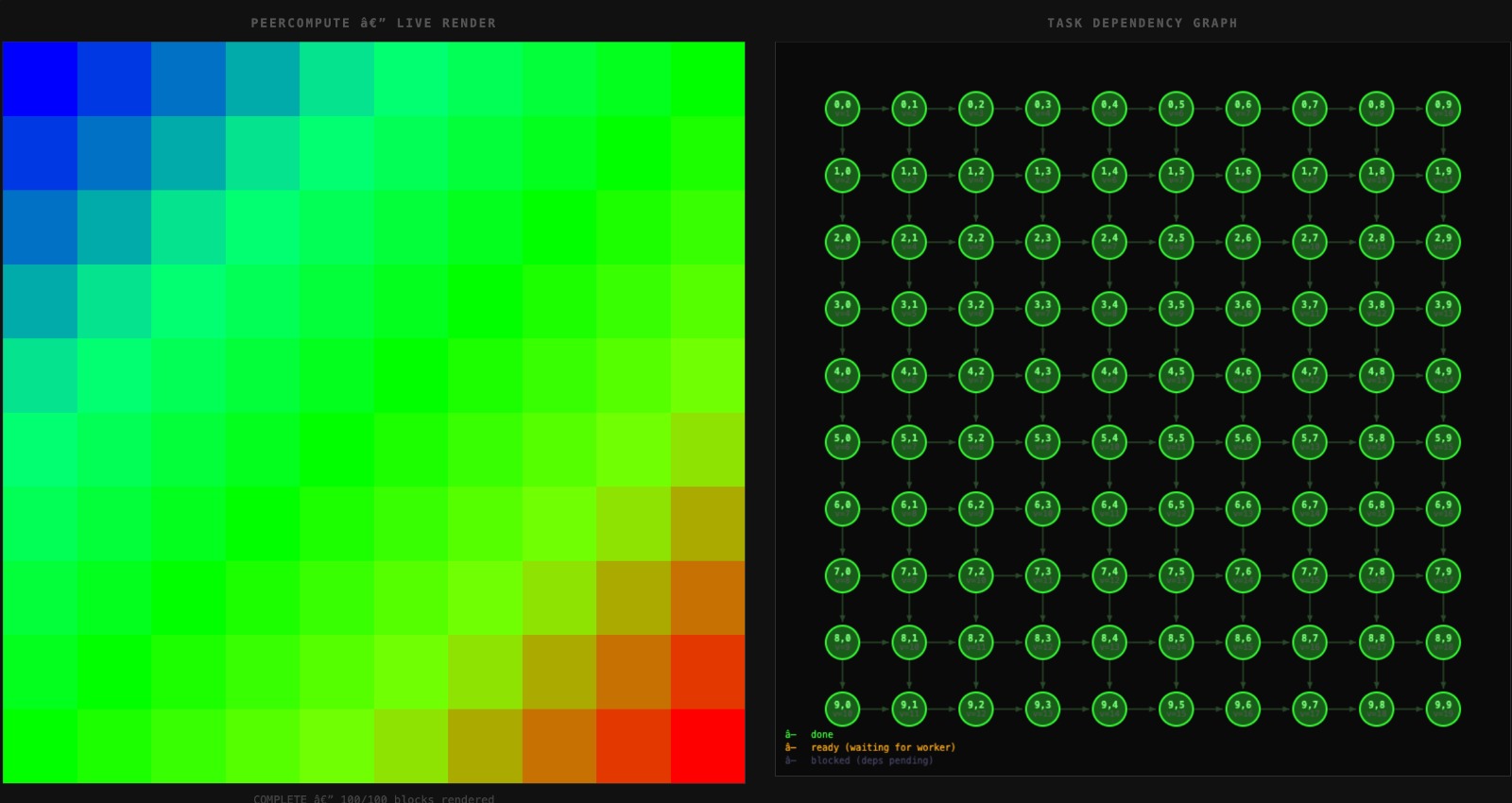
Dependency jobs scheduling


Inspiration
Our lives today are more centralized than ever, with our daily routines deeply embedded in cloud based systems controlled by a small number of powerful players. We want to shift that balance, bringing power back to the people, not monopolies. That is how PeerCompute started. By harnessing the collective power of individuals, we believe we can achieve more together and unlock a whole new level of potential. This is not just about technology, it is about ownership, fairness, and giving people control over the systems they depend on every day.
What it does
PeerCompute lets anyone request computing power or offer their own, with no middleman, no sign up, and no cloud bill. Built on the Pear and Holepunch protocol, peers discover each other directly over a distributed hash table and form a live marketplace of compute. A requester can post tasks such as JavaScript code, shell commands, or full map reduce jobs, and idle workers across the network pick them up, execute them, and return results in seconds. A reputation system tracks who contributes and who consumes, naturally rewarding active participants and helping keep the network fair and reliable. Workers automatically move to where they are needed most, making the system self organizing and resilient. There is no central server that can fail and no company that can shut it down.
How we built it
We built PeerCompute entirely on the Holepunch stack, using Hyperswarm for peer discovery, Autobase as a distributed append only task queue, and Hyperdrive for file transfer between nodes. One of our core architectural insights was repurposing a document synchronization log into a job scheduling system. Each peer runs two separate Hyperswarm instances, one for lightweight JSON signaling and one for binary replication, because mixing both on the same connection corrupts the protocol. Workers detect their own hardware capabilities such as CPU cores, GPU type, and Python or PyTorch availability, and only accept tasks they can realistically execute. A thread pool is used to route heavy compute tasks off the main thread for better performance. The user interface is a simple app that communicates with a local Node.js HTTP server, which wraps the peer to peer core and keeps the frontend fully decoupled from the protocol layer.
Challenges we ran into
Autobase was never designed to be a job queue, and adapting it into one required handling write contention, stale cores blocking the global view, and race conditions when multiple workers attempted to claim the same task at the same time. The dual swarm architecture came from a difficult lesson, when we first mixed JSON messages with binary Protomux replication on the same connection it silently corrupted all subsequent communication. Worker roaming was another complex challenge, deciding when a worker should leave a requester and move on without dropping tasks in progress required careful tuning of idle timeouts and reconnection logic through many iterations. Getting the Pear runtime worker threads to accept pear protocol URLs instead of file based paths also forced us to explore low level module internals before finding a working solution. Delivering all of this in thirty six hours added another layer of difficulty, as we had to constantly learn, adapt, and reshape the idea while building it at the same time.
Accomplishments that we are proud of
We built a fully serverless distributed compute network from scratch in a single weekend. There is no backend, no database, and no authentication service, only peers communicating directly with each other. Tasks submitted from one machine can be executed by another machine across the world in under two seconds. The reputation system creates meaningful incentive without relying on tokens or blockchain systems. Most importantly, the system works in practice, you run one command and immediately become part of the network. What started as an idea became a functioning distributed system in less than two days.
What we learned
Distributed systems challenge every assumption you make. We learned that protocol layers must remain strictly separated, that eventual consistency is something you design for rather than try to avoid, and that the hardest bugs appear only when independent peers interact in unpredictable ways. We also saw that the Holepunch ecosystem is capable of replacing entire layers of traditional cloud infrastructure. The difference between a simple demo and a reliable system comes down to handling edge cases and timing issues correctly. More importantly, we learned that ideas alone are not enough, execution and collaboration are what make things real. Working together as a team is what allowed PeerCompute to exist, reflecting the same principle behind the system itself.
What is next for PeerCompute
The network is now alive and the next step is to grow it into something larger and more robust. We are planning to add persistent worker identities so reputation can carry across sessions, and to build a proper task marketplace where requesters can post bounties and workers can specialize based on their capabilities. We also want to introduce GPU aware scheduling so machine learning workloads are automatically routed to the most suitable machines. In the longer term, we see PeerCompute as a foundation for community owned AI inference, where running models does not require paying centralized platforms but instead relies on shared compute and mutual contribution. We aim to support a wide range of GPU backends, improve system security, introduce safer execution environments, and integrate container based solutions such as Docker for better isolation and flexibility. The goal is not only to build powerful infrastructure, but to make it open, fair, and owned by the people who use it.
Check our GitHub repo Readme for more information.
Built With
- autobase
- bare
- corestore
- holepunch
- hyperdrive
- hyperswarm
- javascript
- pear
- protomux
- python

Log in or sign up for Devpost to join the conversation.