-
-
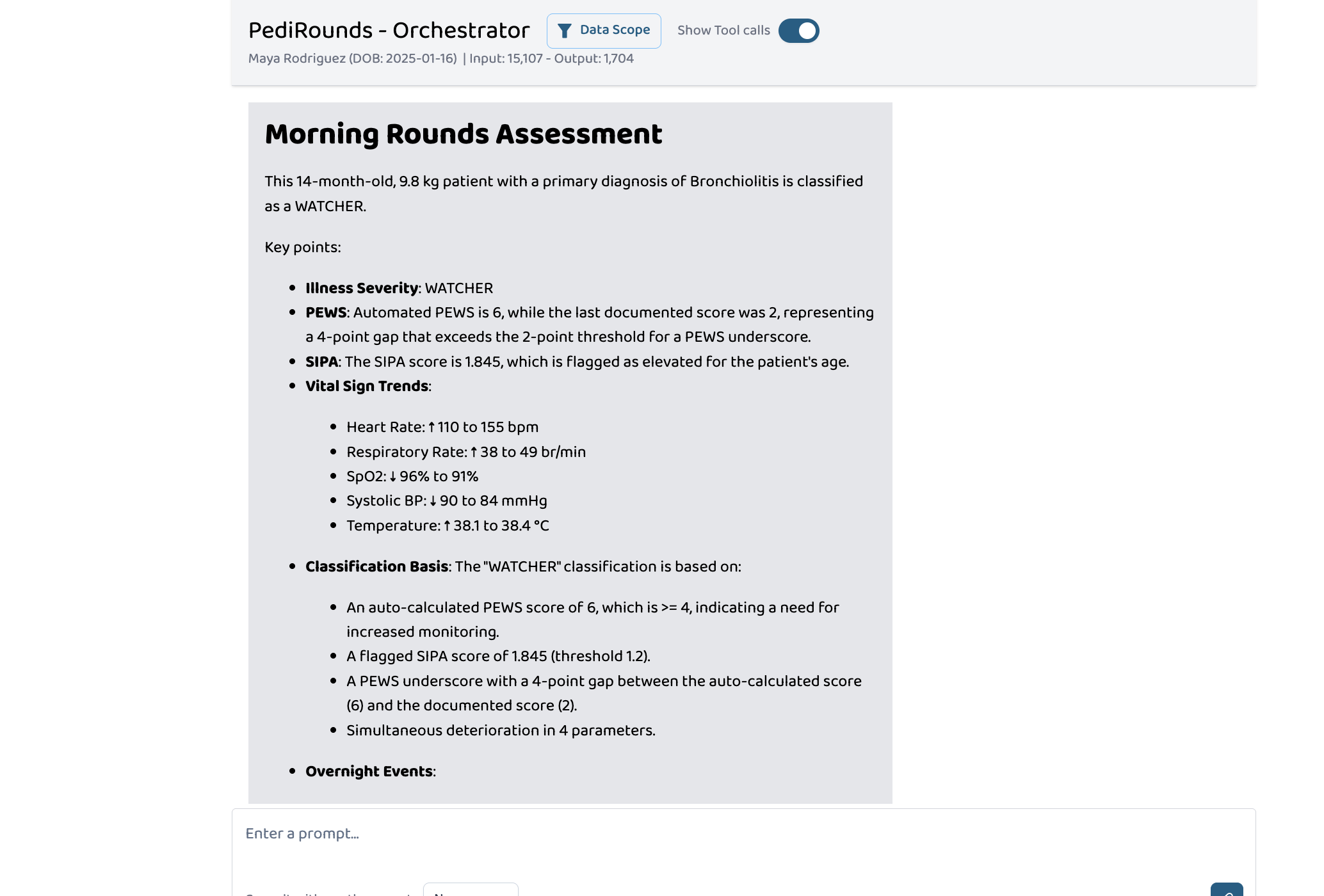
Morning Rounds Assessment
-
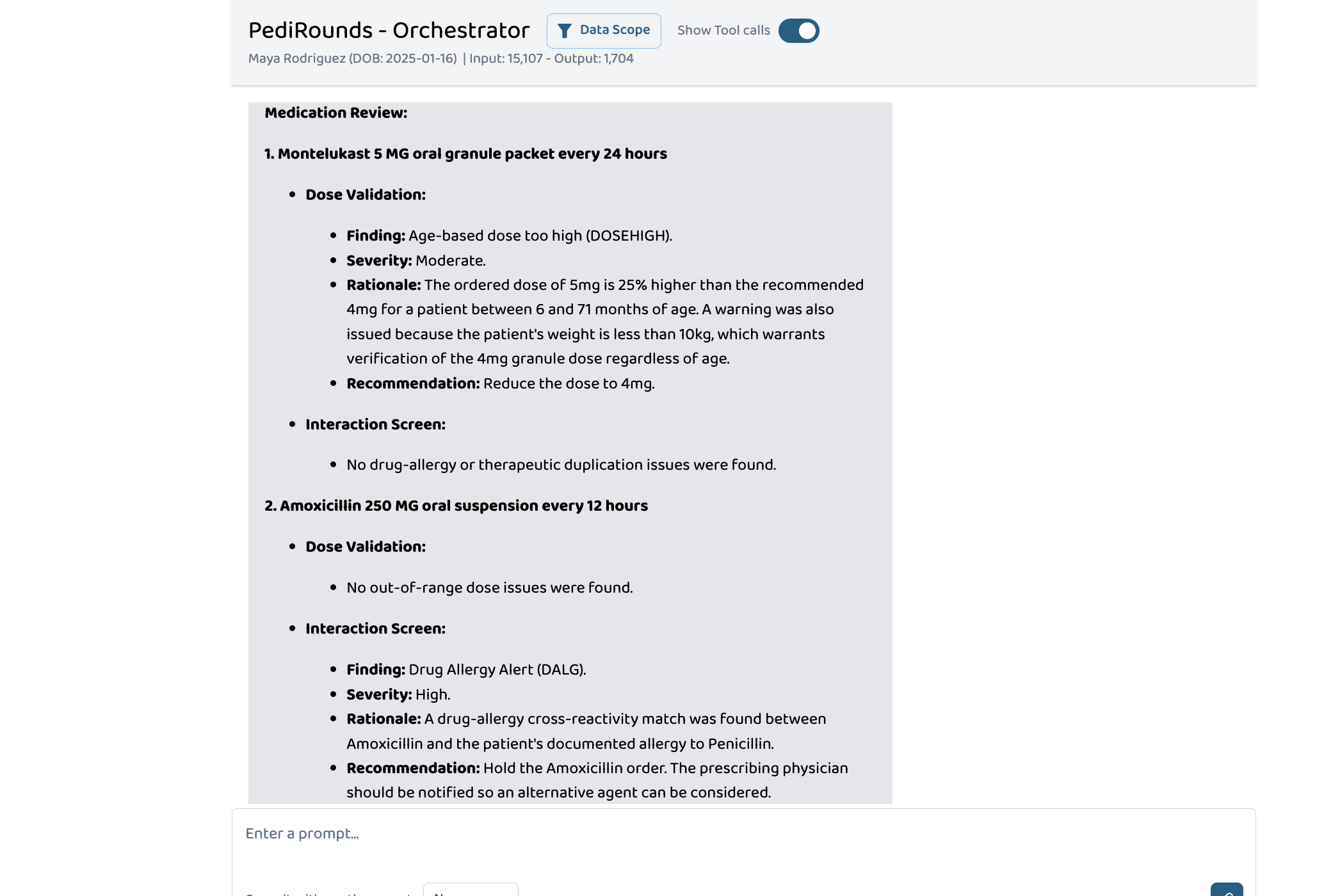
Medicine Check
-
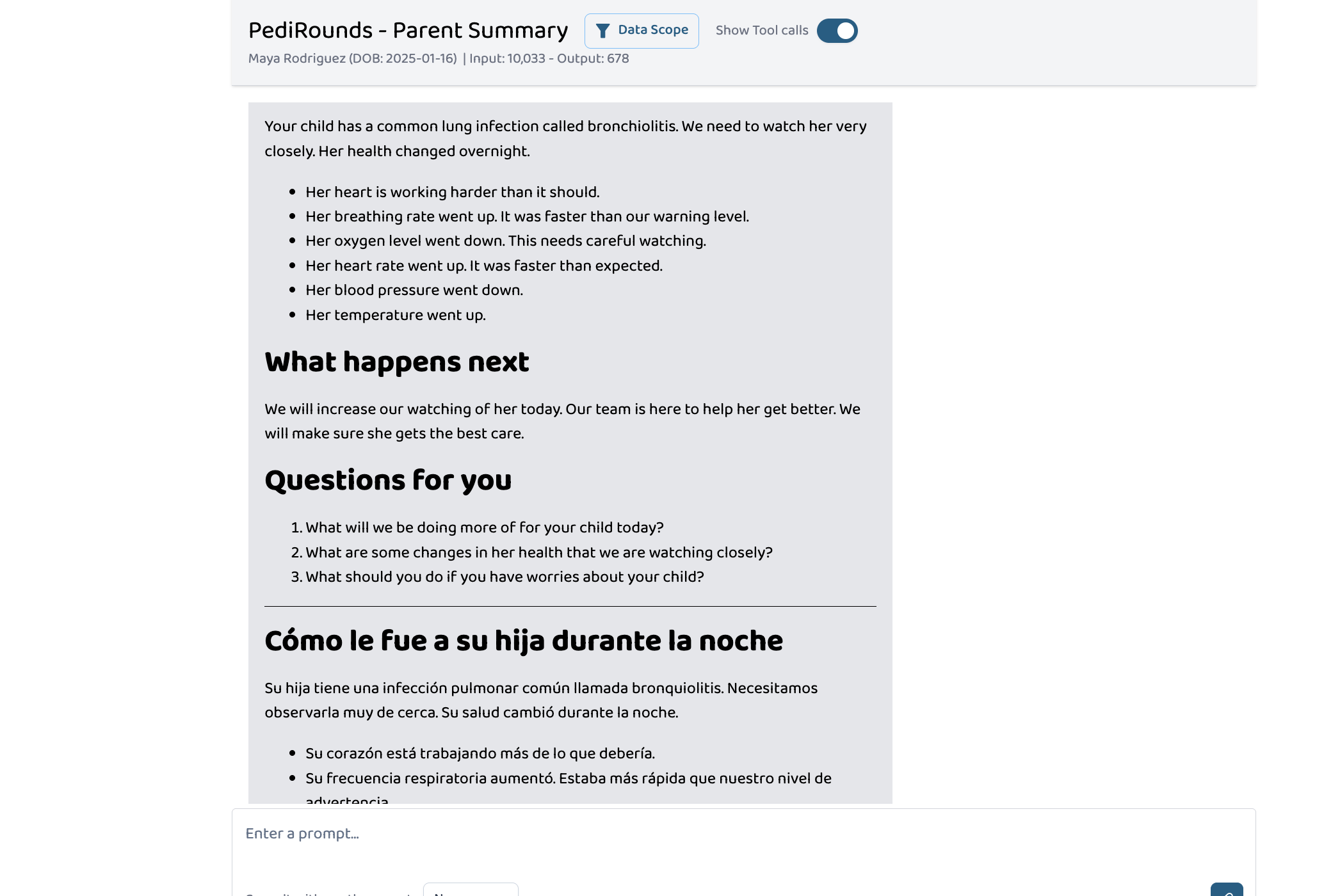
Parent Note - English and Spanish
-
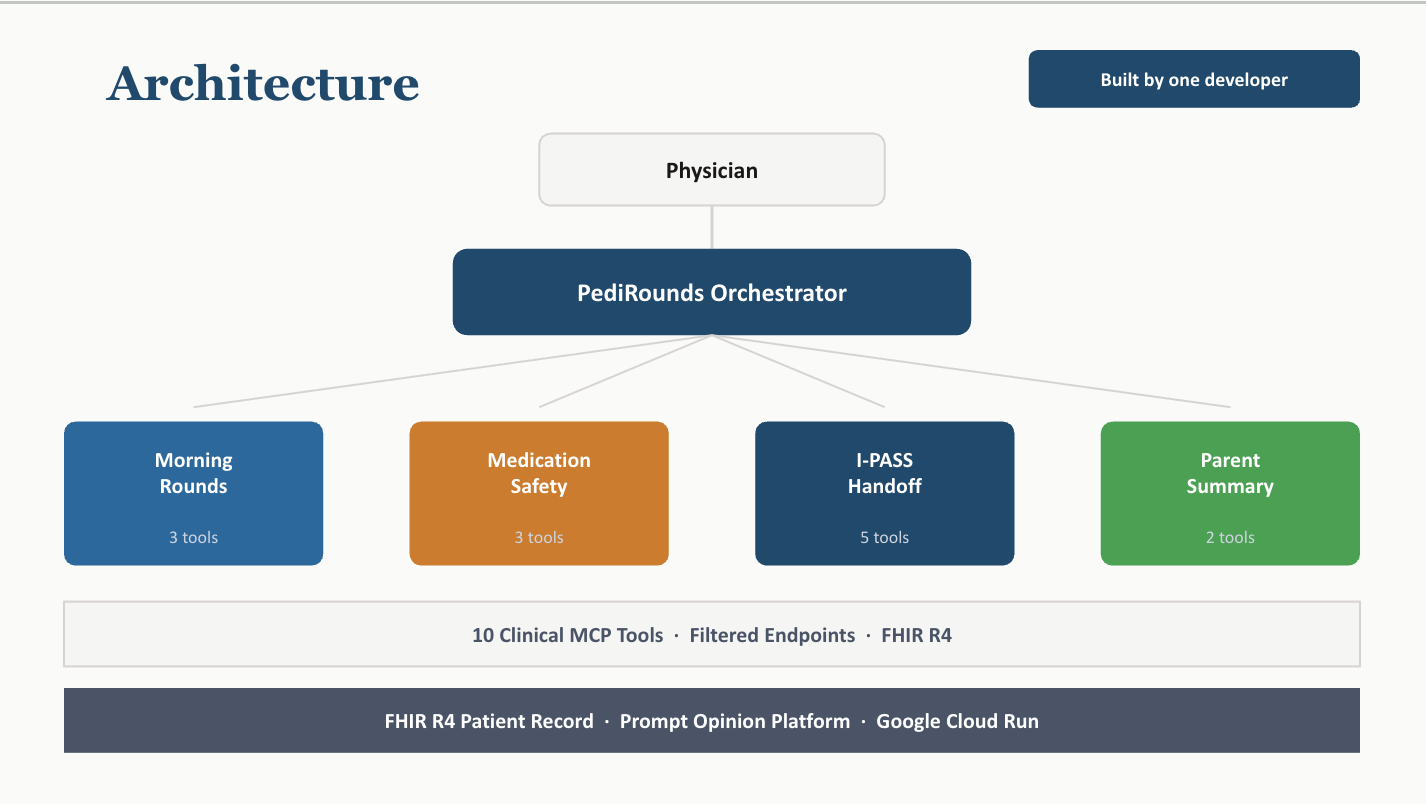
Architecture
Inspiration
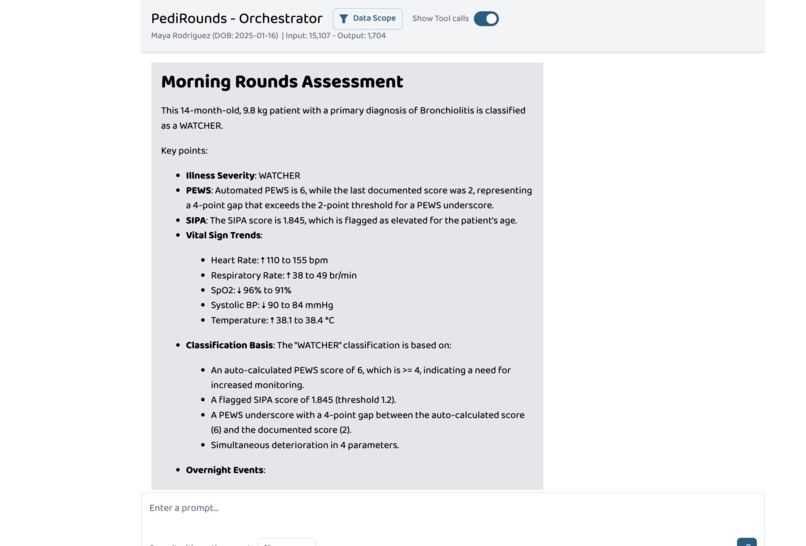
A 14-month-old is admitted overnight with bronchiolitis. The nurse documents a PEWS score of 2 — stable. But the vitals tell a different story: heart rate climbing from 110 to 155, SpO₂ dropping from 96% to 91%, respiratory rate nearly doubling. The auto-calculated PEWS should be 6 — a score that triggers senior clinician review. By morning rounds, nobody has caught it.
This isn't a hypothetical. A University of Virginia 8-year retrospective study found that 47% of patients had at least one underscored PEWS in the 24 hours before emergent PICU transfer, and over 20% had no PEWS recorded at all (Kowalski et al., JMIR Pediatrics and Parenting, 2021). Chapman et al. found that only 36% of observation sets contained complete vital signs and a concurrent PEWS score (Chapman et al., Arch Dis Child, 2019). Meanwhile, approximately 1 in 5 hospitalized children experience at least one medication dosing error (Gates et al., Drug Safety, 2019), and only 1 in 3 parents fully comprehend their child's discharge instructions (Uong et al., Pediatrics, 2021). These gaps are systematic — not failures of individual clinicians, but failures of the systems they rely on. At an average cost of $8,000 per PICU day, even one avoided emergent transfer per month represents approximately $100K annually for a mid-size children's hospital — early detection doesn't just save lives, it changes the economics of pediatric inpatient care.
The math behind deterioration detection is straightforward. The Shock Index, Pediatric Age-Adjusted (SIPA) is:
$$SIPA = \frac{HR}{SBP}$$
For a 14-month-old with HR = 155 and SBP = 84:
$$SIPA = \frac{155}{84} = 1.845$$
The age-specific threshold is 1.22 for ages 4-6 (Acker et al., J Pediatr Surg, 2015), extended to ages 1-3 by subsequent validation (Nordin et al., J Pediatr Surg, 2018). A SIPA of 1.845 indicates significant cardiovascular stress — but this calculation never happens unless someone pulls the vitals, does the division, and knows the threshold. At 6 AM after a 14-hour shift, that's a lot to ask.
The I-PASS handoff framework was designed to standardize shift transitions, but generating a complete briefing requires synthesizing overnight vitals, medications, allergies, lab trends, and deterioration risk — a process that takes 15-20 minutes per patient and is often done from memory.
PediRounds was built to close that gap. Not as a chatbot that answers questions, but as an AI co-resident that does the pre-rounds prep work: pulling FHIR data, computing scores the EHR missed, flagging medications that should never have been ordered, and generating the documents that make handoffs safe.
What it does
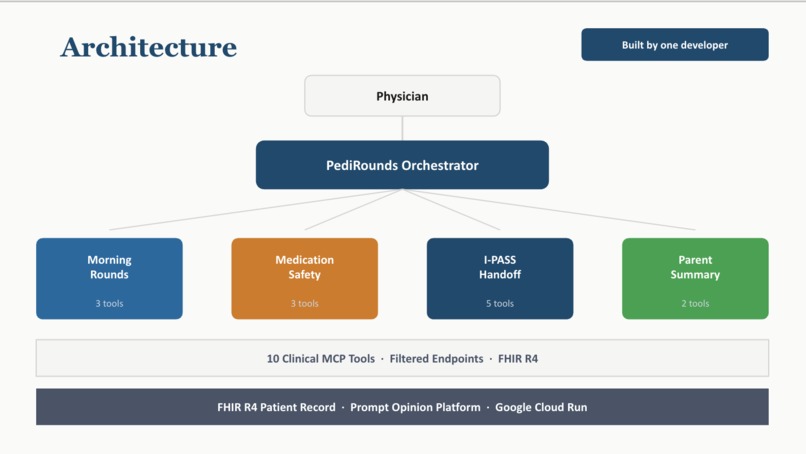
PediRounds orchestrates four specialist agents across ten clinical MCP tools, all operating on live FHIR R4 patient data.
Morning Rounds Agent
Pulls overnight vital sign trends, auto-calculates PEWS from raw vitals using the Bedside PEWS methodology (Parshuram et al., Critical Care, 2009), computes SIPA, and detects PEWS underscoring by comparing:
$$\Delta_{PEWS} = PEWS_{auto} - PEWS_{documented}$$
If Δ_PEWS ≥ 2, the system flags an underscore alert. It classifies the patient using a composite deterioration model with graded escalation tiers adapted from institutional protocols:
| Classification | Criteria | Evidence Basis |
|---|---|---|
| CRITICAL | PEWS ≥ 8 OR cardiac arrest indicators | Parshuram 2009 (AUROC 0.91, sensitivity 82%, specificity 93% at threshold ≥ 8) |
| WATCHER | PEWS 4–7, OR SIPA > age-specific threshold, OR Δ_PEWS ≥ 2, OR ≥ 3 parameters deteriorating simultaneously | Graded escalation per institutional protocols; Acker 2015; Nordin 2018 |
| STABLE | All assessed parameters within normal limits | — |
The original Parshuram validated threshold of ≥ 8 triggers ICU evaluation. PediRounds implements graded escalation starting at ≥ 4 for increased monitoring frequency and ≥ 6 for senior clinician review, reflecting how pediatric hospitals operationalize PEWS in practice.
Medication Safety Agent
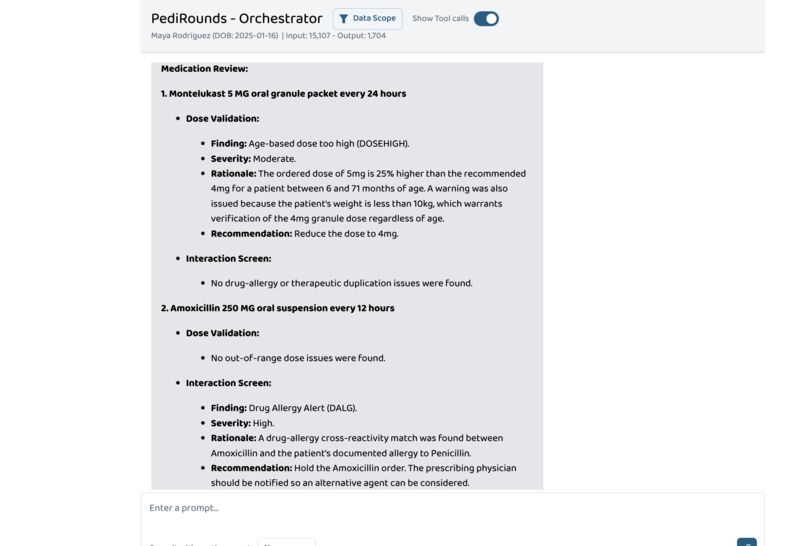
Validates every active medication dose against age/weight-based pediatric ranges. For a 14-month-old weighing 9.8 kg on Montelukast 5 mg:
$$\text{Recommended dose} = 4\text{ mg (age 6-71 months)}$$ $$\text{Overage} = \frac{5 - 4}{4} \times 100 = 25\%$$
The agent flags this as DOSEHIGH and catches that Amoxicillin should never be given to a patient with a Penicillin allergy (DALG — drug-allergy cross-reactivity). With approximately 1 in 5 hospitalized children experiencing at least one dosing error (Gates et al., 2019), automated dose validation is not a convenience — it's a safety requirement.
I-PASS Handoff Agent
Generates a complete, structured I-PASS briefing (Illness Severity → Patient Summary → Action List → Situation Awareness → Synthesis) as a FHIR Composition resource with linked Task resources for each action item. Situation awareness contingencies are generated via Gemini 2.5 Pro, with a deterministic fallback engine that activates when Gemini is unavailable or generates a contingency outside the patient's active problem list. The fallback substitutes evidence-based rules matching vital sign breaches to standard escalation protocols — for example: "IF SpO₂ < 90% on current O₂ support THEN high-flow nasal cannula + PICU consult." Four such rules are pre-built for respiratory deterioration scenarios, ensuring the I-PASS always contains actionable contingencies regardless of LLM availability.
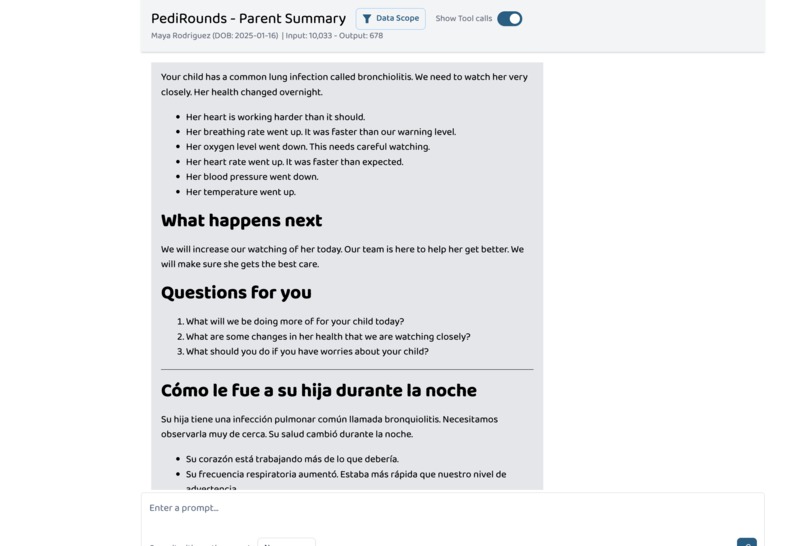
Parent Summary Agent
Generates a bilingual, parent-friendly summary following NIH health literacy guidelines at a target reading level of FK_grade ≤ 6.0, using the Flesch-Kincaid formula:
$$FK = 0.39\left(\frac{\text{words}}{\text{sentences}}\right) + 11.8\left(\frac{\text{syllables}}{\text{words}}\right) - 15.59$$
Detects the family's preferred language from FHIR patient records and produces both English and translated versions with teach-back questions to verify understanding. When only 1 in 3 parents fully comprehend their child's discharge plan (Uong et al., Pediatrics, 2021), and those who don't are nearly 9 times more likely to make dangerous errors at home (Glick et al., J Pediatr, 2019), clear communication isn't optional — it's the care team's responsibility.
Orchestrator
A coordinator agent routes natural language requests ("do rounds", "check medications", "prepare handoff") to the appropriate specialist via platform-managed agent GUIDs. The orchestrator accepts patient-scoped queries today — extending to panel-level commands ("do rounds for all my patients") is an iteration on the existing routing pattern, not a new architecture.
How we built it
Architecture
Python MCP server exposing 10 clinical tools via the Streamable HTTP transport. Four route-based endpoints each expose only the tools their specialist agent needs — a design choice that proved critical for reliability:
Telling an LLM "only call these 2 tools" in a system prompt is a suggestion. Giving it an MCP endpoint with only 2 tools is a constraint.
| Endpoint | Tools | Agent |
|---|---|---|
/mcp-rounds |
3 | Morning Rounds |
/mcp-medsafety |
3 | Medication Safety |
/mcp-handoff |
5 | I-PASS Handoff |
/mcp-parent |
2 | Parent Summary |
/mcp |
10 | All (backward compat) |
Clinical Tools (10)
get_patient_context— Patient demographics, weight, medications, conditions, allergies from FHIRget_overnight_delta— Vital sign trend analysis with age-specific threshold breach detectioncompute_deterioration_flags— PEWS auto-scoring, SIPA calculation, underscore detection, multi-parameter deterioration classificationvalidate_dose_range— Weight/age-based pediatric dose validation against a 24-drug reference databasescreen_interactions— Drug-allergy cross-reactivity and therapeutic duplication screeningget_pending_results— Outstanding lab/imaging result trackinggenerate_ipass_briefing— Full I-PASS document generation with FHIR Composition + Task resourcesgenerate_parent_summary— Gemini-powered bilingual parent communication with reading level measurement- Plus two supporting tools for clinical reference lookups
Platform Integration
Built as BYO agents on the Prompt Opinion platform with FHIR context propagation. SHARP (Secure HTTP Access to Resources via FHIR) is the platform's context mechanism — functionally equivalent to a SMART-on-FHIR launch context, passing patient ID, server URL, and bearer token via HTTP headers (X-Patient-ID, X-FHIR-Server-URL, X-FHIR-Access-Token). In a production EHR deployment, this would be replaced by a standard SMART-on-FHIR launch sequence with appropriate patient/*.read scopes and OAuth2 token exchange. A patient resolver maps platform UUIDs to FHIR resource IDs through a registry cache.
Multi-Agent Orchestration
The orchestrator routes user intent to specialist agents via SendAgentMessage using platform GUIDs injected through template variables ({{ OrchestratorAgentsFragment }}). Each agent operates independently with its own filtered MCP endpoint. Because all outputs are FHIR-native, they could be embedded directly into Epic or Cerner as a SMART-on-FHIR app, requiring zero workflow deviation from the clinician.
FHIR R4 Compliance
All tool outputs are valid FHIR resources — Compositions, Tasks, DocumentReferences, Communications. The I-PASS briefing is a FHIR Composition with LOINC-coded sections and Composition.author referencing Device/pedirounds-mcp — ensuring every AI-generated document is clearly distinguished from human-authored clinical notes in the medical record. Parent summaries create both a Communication resource (delivery tracking) and a DocumentReference (clinical record).
Safety Architecture
A PediSource GuardRail validates all user prompts before they reach the LLM. It operates as a pre-prompt classification layer on the platform: prompts requesting data gathering, analysis, and clinical decision support pass through; prompts requesting autonomous clinical actions (ordering, modifying treatments, diagnosing) are blocked with an explanation. Every clinical recommendation in the output includes "physician review required" language. The system is decision support, not decision making.
Testing & Deployment
- 541 automated tests covering unit, integration, and clinical scenario validation
- Deployed on Google Cloud Run with min-instances=1
- Gemini 2.5 Pro powers I-PASS situation awareness contingencies and parent summary generation
Challenges we ran into
Platform beta navigation. Prompt Opinion is a new platform with evolving documentation. We discovered undocumented behaviors through trial and error: the orchestrator requires template variables ({{ OrchestratorAgentsFragment }}) to inject agent GUIDs for routing, the FHIR proxy doesn't support batch bundles, guardrails aggressively block clinical-sounding phrases like "do rounds" as autonomous actions, and patient IDs arrive as platform UUIDs that must be resolved to FHIR resource IDs.
Token budget management. Each agent call consumes 8K–30K input tokens depending on the tool chain. The orchestrator accumulates conversation history, causing timeouts by the third sequential agent call. We solved this by making heavy tools (I-PASS, Parent Summary) self-contained — they gather their own data internally instead of requiring the LLM to stitch outputs from multiple prior tool calls.
LLM tool argument reliability. The platform's LLM occasionally omits required parameters or passes patient context where deterioration data is expected. Filtered MCP endpoints (2-5 tools instead of 10) dramatically improved reliability by constraining the LLM's choice space — a constraint is more reliable than an instruction.
PEWS scoring implementation. Auto-calculating PEWS from raw vitals requires age-specific thresholds that aren't standardized across institutions. We implemented the Parshuram/Monaghan Bedside PEWS methodology (Parshuram et al., 2009) with graded escalation tiers (≥ 4 increased monitoring, ≥ 6 senior review, ≥ 8 ICU evaluation) and explicit citations so clinicians can verify the scoring basis and adapt thresholds to their institution.
Temporal data freshness. FHIR vital signs have absolute timestamps. Demo data goes "out of window" as days pass. We built a refresh script that re-dates all Observations relative to now before each session — a small thing that consumed real debugging time.
Accomplishments that we're proud of
The PEWS underscore catch is real. In our demo, the nurse documented PEWS 2 but the auto-calculated score is 6 — a Δ_PEWS = 4 that triggers senior clinician review. PediRounds catches this automatically from raw vital signs, exactly the kind of error that the literature shows: 47% of patients had at least one underscored PEWS before emergent PICU transfer (Kowalski et al., 2021).
Ten tools, four agents, one orchestrator — live on FHIR. Every tool call hits a real FHIR server, resolves real patient resources, and returns valid FHIR R4 output. The I-PASS briefing generates actual Task resources with urgency priorities. Nothing is mocked.
Bilingual parent communication with equity focus. The parent summary detects the family speaks Spanish, generates both English and Spanish following NIH health literacy guidelines, and includes teach-back questions — ensuring the care team communicates clearly regardless of family background.
541 tests for a hackathon project. Clinical software demands coverage. Edge cases for extreme prematurity dosing, obesity-adjusted calculations, and multi-drug interaction chains are all tested.
The architecture scales. Adding a new specialist agent: define a tool set, create an MCP endpoint, configure a BYO agent, link to orchestrator. Repeatable for any clinical domain.
What we learned
Filtered tool sets > prompt engineering. Telling an LLM "only call these 2 tools" in a system prompt is a suggestion. Giving it an MCP endpoint with only 2 tools is a constraint. The latter is dramatically more reliable and saves ~2,000 tokens per agent call.
Self-contained tools beat tool chains. When an LLM must call Tool A → pass output to Tool B → pass both to Tool C, it frequently drops or misroutes data. Making each generator tool internally gather its own dependencies eliminated an entire class of orchestration failures.
Clinical AI needs citations. Every PEWS threshold, every SIPA cutoff, every dose range traces back to a published source. Clinician trust requires evidence provenance, not just correct numbers.
Multi-agent orchestration on a beta platform requires resilience. Template variables, GUID resolution, token accumulation, guardrail tuning — each layer introduced failure modes that don't exist locally. Building for a hosted platform means building for the platform's assumptions.
The demo is the product. Every architectural decision was filtered through "will this show in 3 minutes?" This discipline prevented scope creep and kept focus on clinical value over technical novelty.
What's next for PediRounds — AI Co-Resident for Pediatric Morning Rounds
Multi-patient panel management. A resident carrying 8-12 patients gets a prioritized pre-rounds summary with the sickest patients surfaced first, ranked by composite deterioration risk score. The orchestrator already accepts patient-scoped queries — extending to "do rounds for all my patients" is an iteration on the existing routing pattern. Picture a PGY-2 arriving at 6 AM with 10 patients: PediRounds returns a panel summary — 2 WATCHERs (one with PEWS underscore, one with SIPA breach), 8 STABLE. She taps the first WATCHER and gets the full morning rounds assessment in 12 seconds.
Adolescent privacy and age-gated content. Pediatrics spans 0-18, and the privacy implications change dramatically across that range. For adolescent patients (≥ 12), the parent summary will apply age-gated content filtering to exclude sensitive categories (reproductive health, mental health, substance use) per state-specific minor consent laws — ensuring the system respects both family-centered care and adolescent autonomy.
Continuous monitoring integration. Connecting to bedside monitor streams via FHIR Observation resources and FHIR Subscriptions would enable real-time PEWS calculation and proactive alerting — not just morning rounds prep.
Full formulary coverage. Expanding from 24 medications to institution-specific formularies with customizable dose ranges and preferred alternatives. The dose validation logic is drug-agnostic — institutional formularies plug in as configuration, not code changes.
EHR integration via SMART-on-FHIR. The I-PASS briefing and action items are already FHIR Compositions and Tasks. Because the outputs are FHIR-native, embedding PediRounds as a SMART-on-FHIR app in Epic or Cerner would require no translation layer — the resources write directly to the chart.
A2A federation. PediRounds exposes an A2A-compliant agent card. Other clinical AI systems could consult PediRounds as a specialist — an ED triage agent requesting a deterioration assessment before admission.
Retrospective validation. The ultimate goal: would PediRounds have caught deterioration signals that were missed? The PEWS underscore detection algorithm is designed for exactly this kind of study against real PICU transfer data, targeting sensitivity ≥ 0.80 and specificity ≥ 0.90 on a historical cohort.
References
Kowalski RL, Lee L, Spaeder MC, Moorman JR, Keim-Malpass J. Accuracy and Monitoring of Pediatric Early Warning Score (PEWS) Scores Prior to Emergent Pediatric Intensive Care Unit (ICU) Transfer: Retrospective Analysis. JMIR Pediatr Parent. 2021;4(1):e25991. doi:10.2196/25991
Chapman SM, Oulton K, Peters MJ, Wray J. Missed opportunities: incomplete and inaccurate recording of paediatric early warning scores. Arch Dis Child. 2019;104(12):1208-1213. doi:10.1136/archdischild-2018-316248
Parshuram CS, Hutchison J, Middaugh K. Development and initial validation of the Bedside Paediatric Early Warning System score. Crit Care. 2009;13(4):R135. doi:10.1186/cc7998
Acker SN, Ross JT, Partrick DA, Tong S, Bensard DD. Pediatric specific shock index accurately identifies severely injured children. J Pediatr Surg. 2015;50(2):331-334. doi:10.1016/j.jpedsurg.2014.08.009
Nordin A, Coleman A, Shi J, Wheeler K, Xiang H, Acker S, Bensard D, Kenney B. Validation of the age-adjusted shock index using pediatric trauma quality improvement program data. J Pediatr Surg. 2018;53(1):130-135. doi:10.1016/j.jpedsurg.2017.10.012
Parshuram CS, Duncan HP, Joffe AR, et al. Multicentre validation of the bedside paediatric early warning system score. Crit Care. 2011;15(4):R184. doi:10.1186/cc10337
Acker SN, Bredbeck B, Partrick DA, Kulungowski AM, Barnett CC, Bensard DD. Shock index, pediatric age-adjusted (SIPA) is more accurate than age-adjusted hypotension for trauma team activation. Surgery. 2017;161(3):803-807. doi:10.1016/j.surg.2016.08.050
Gates PJ, Meyerson SA, Baysari MT, Westbrook JI. The Prevalence of Dose Errors Among Paediatric Patients in Hospital Wards with and without Health Information Technology: A Systematic Review and Meta-Analysis. Drug Saf. 2019;42(1):13-25. doi:10.1007/s40264-018-0715-6
Uong A, Philips K, Hametz P, et al. SAFER Care: Improving Caregiver Comprehension of Discharge Instructions. Pediatrics. 2021;147(4):e20200031. doi:10.1542/peds.2020-0031
Glick AF, Farkas JS, Mendelsohn AL, et al. Discharge Instruction Comprehension and Adherence Errors: Interrelationship Between Plan Complexity and Parent Health Literacy. J Pediatr. 2019;214:193-200.e3. doi:10.1016/j.jpeds.2019.04.052



Log in or sign up for Devpost to join the conversation.