-
-
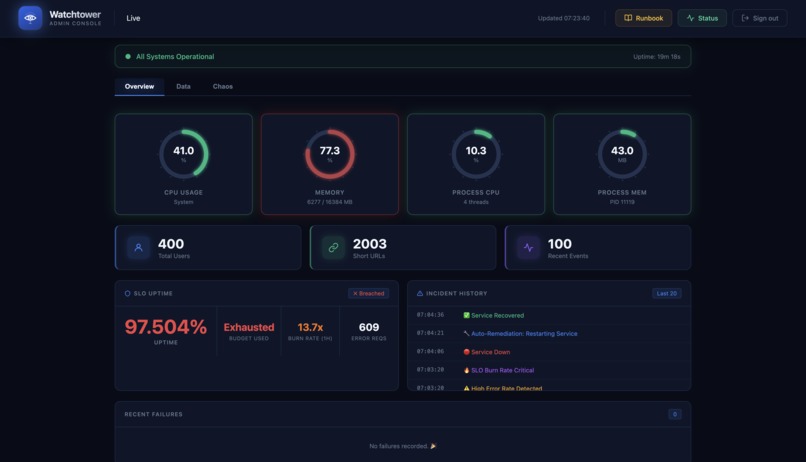
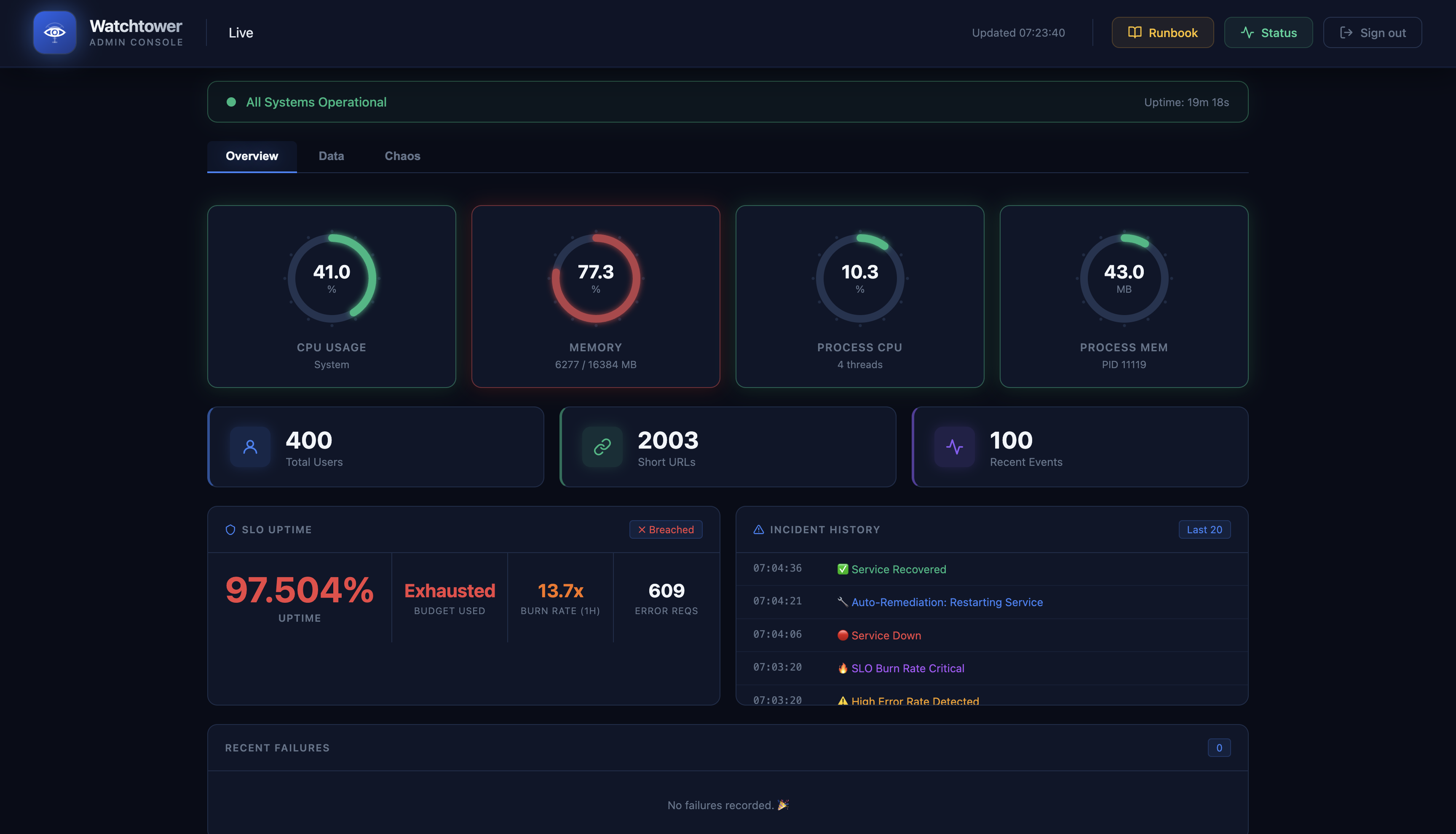
Dashboard
-
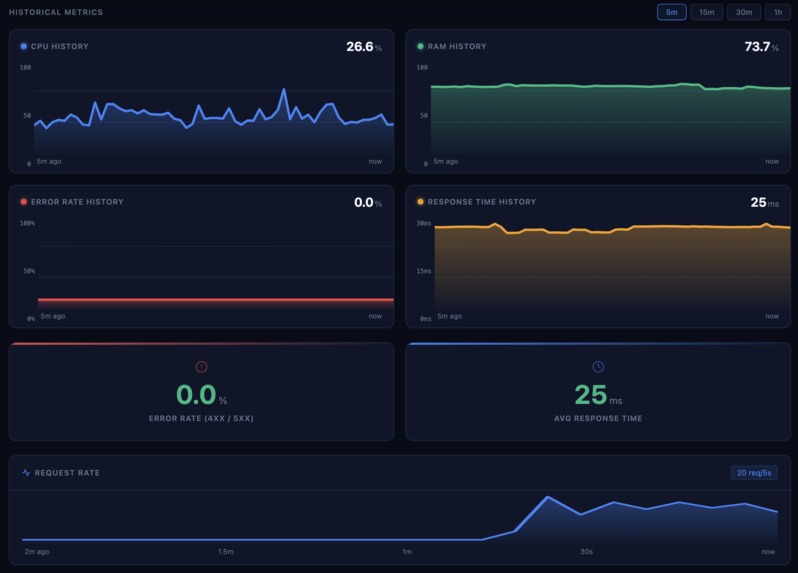
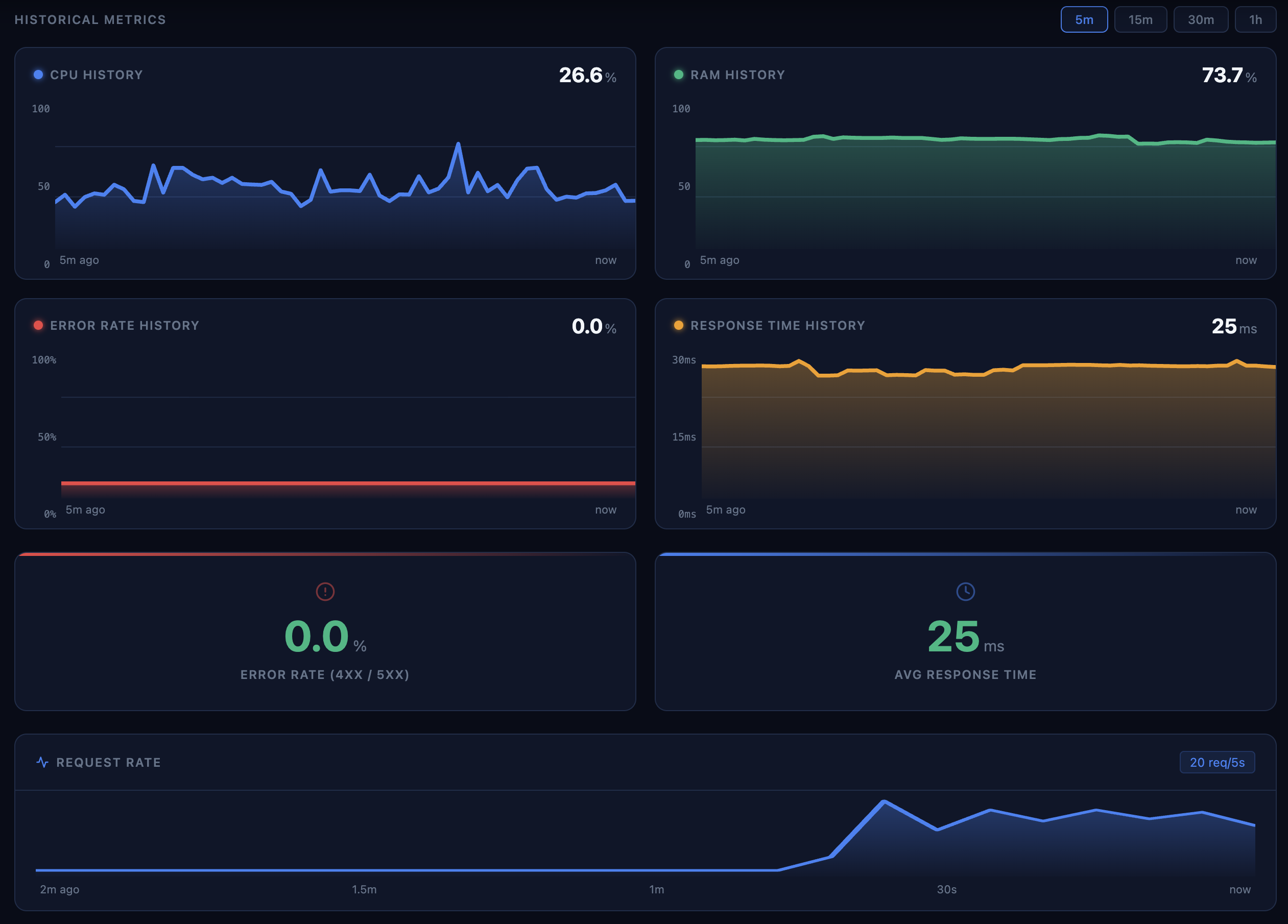
Metrics
-
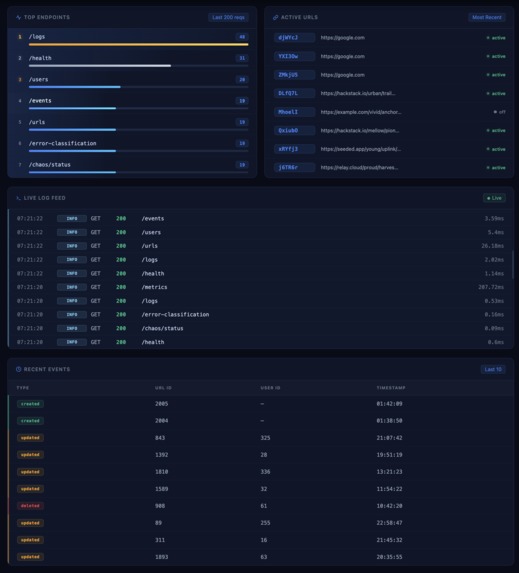
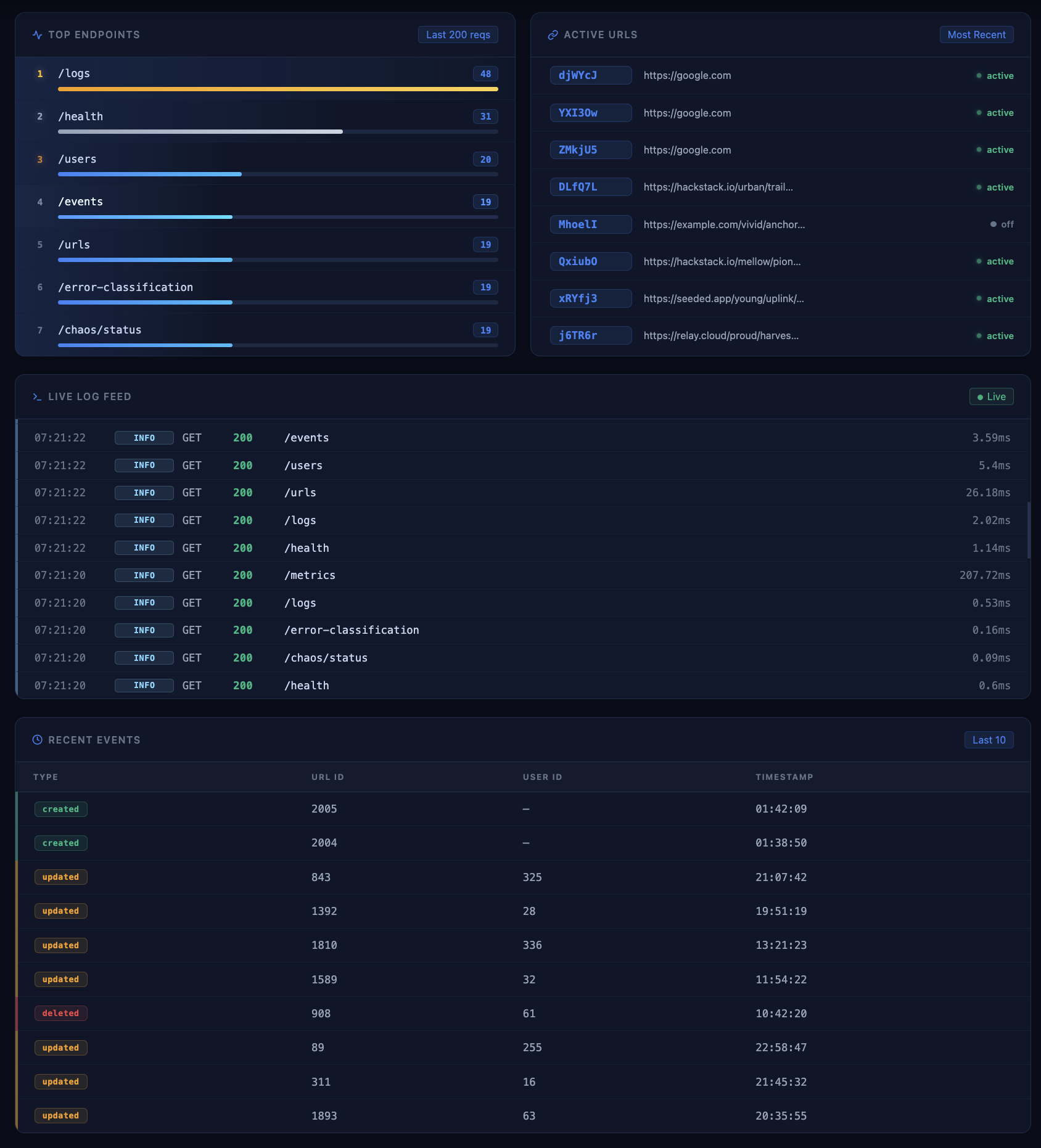
Data Tab
-
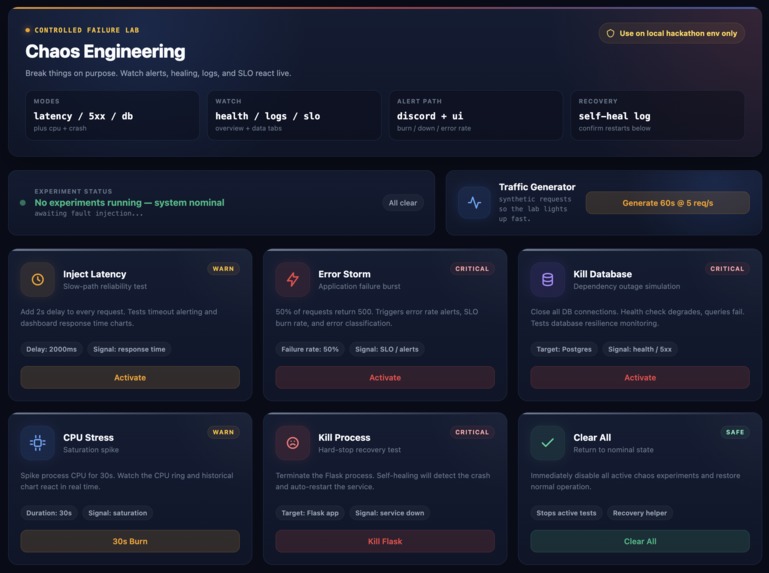
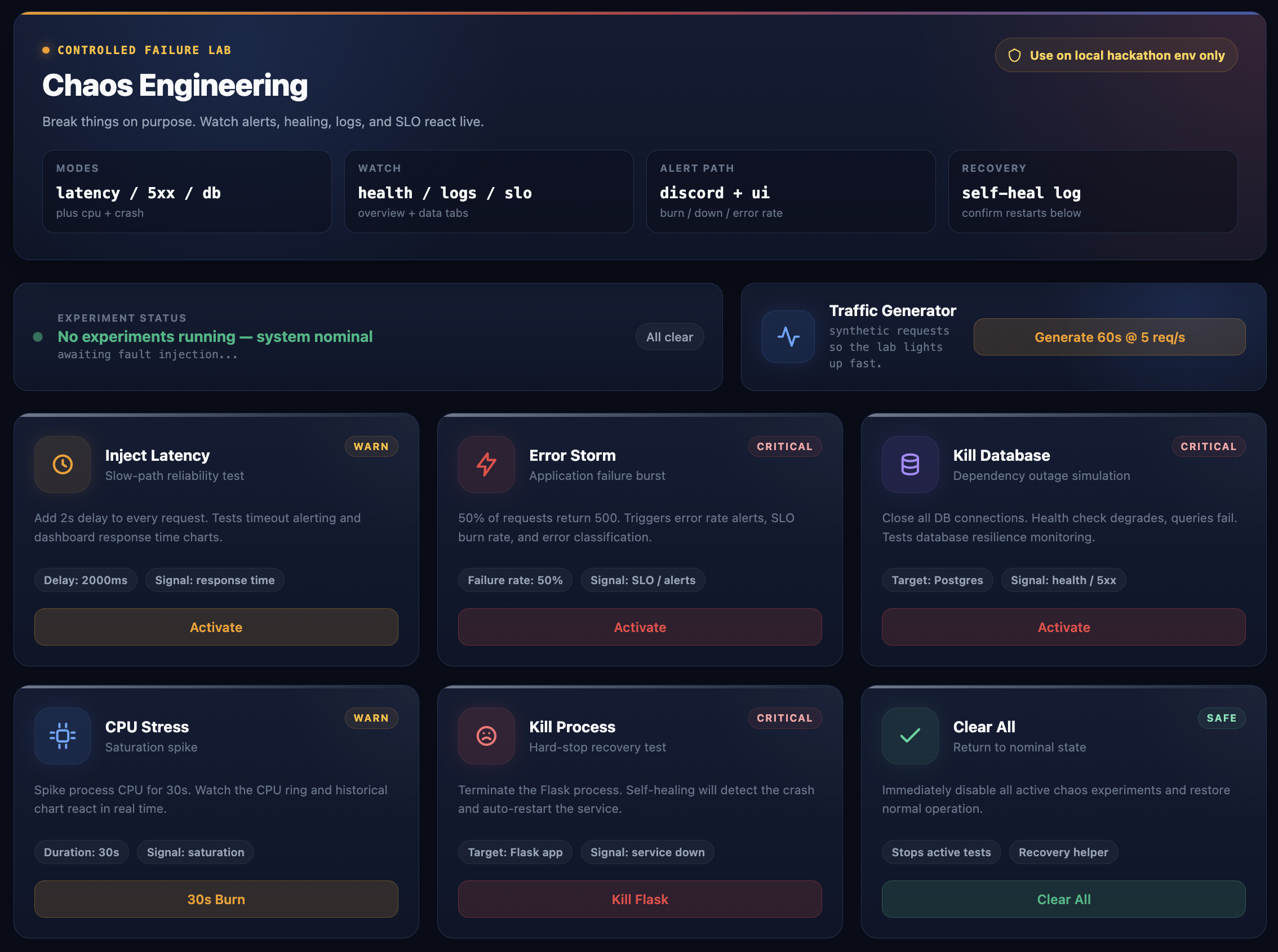
Chaos Engineering
-
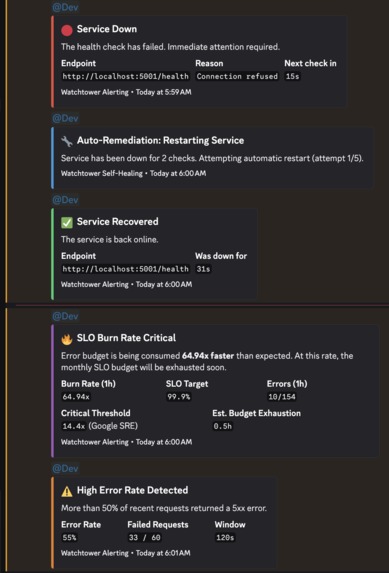
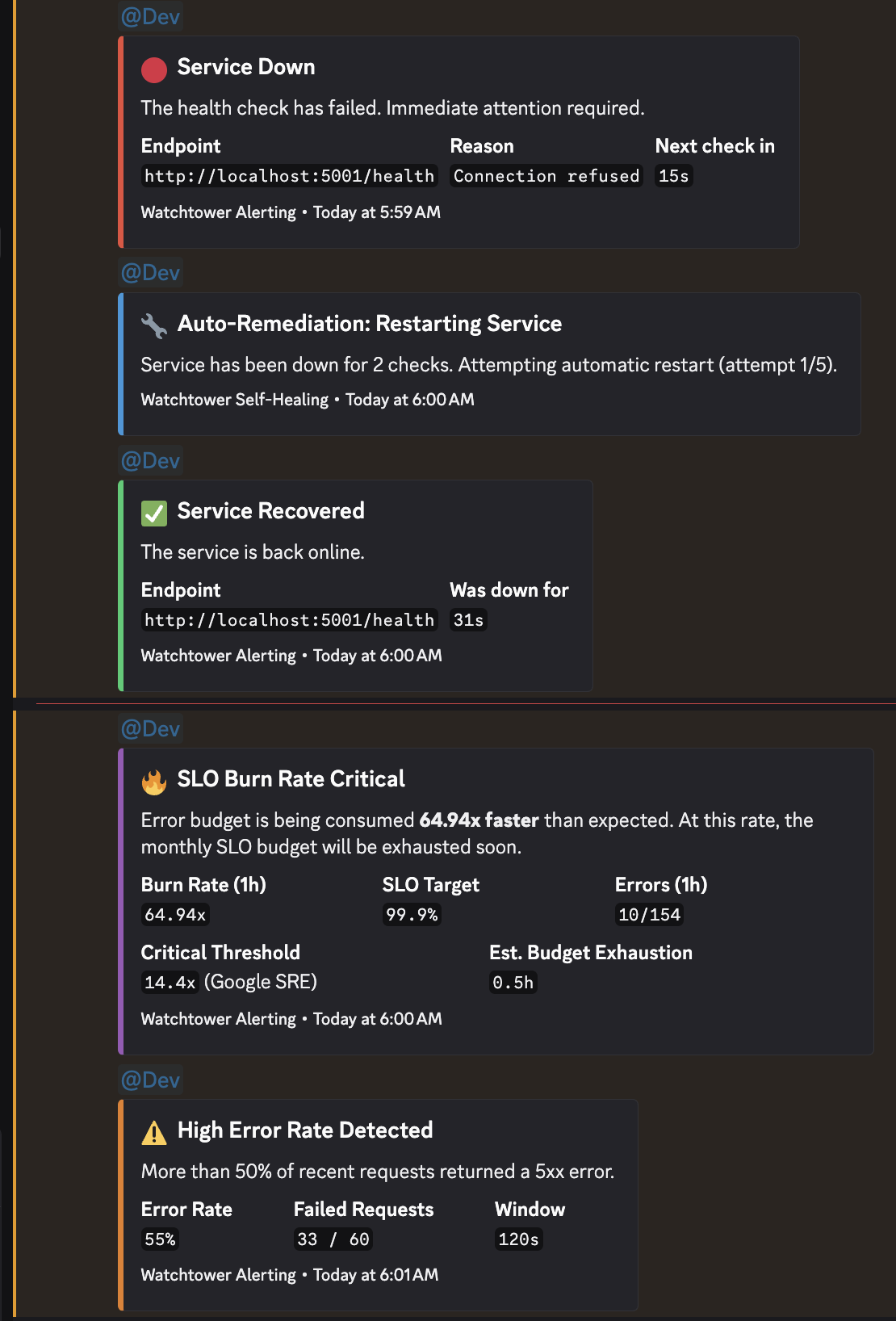
Discord Alerts
-
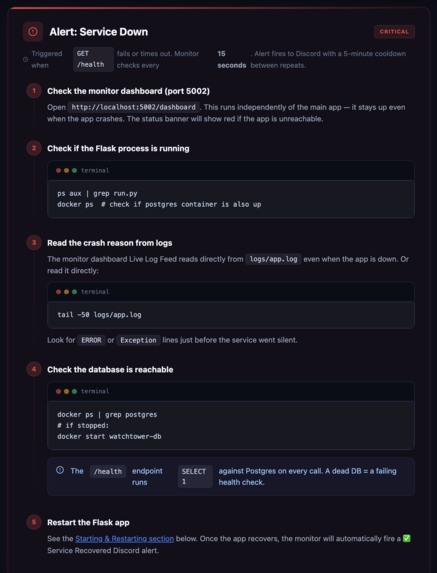
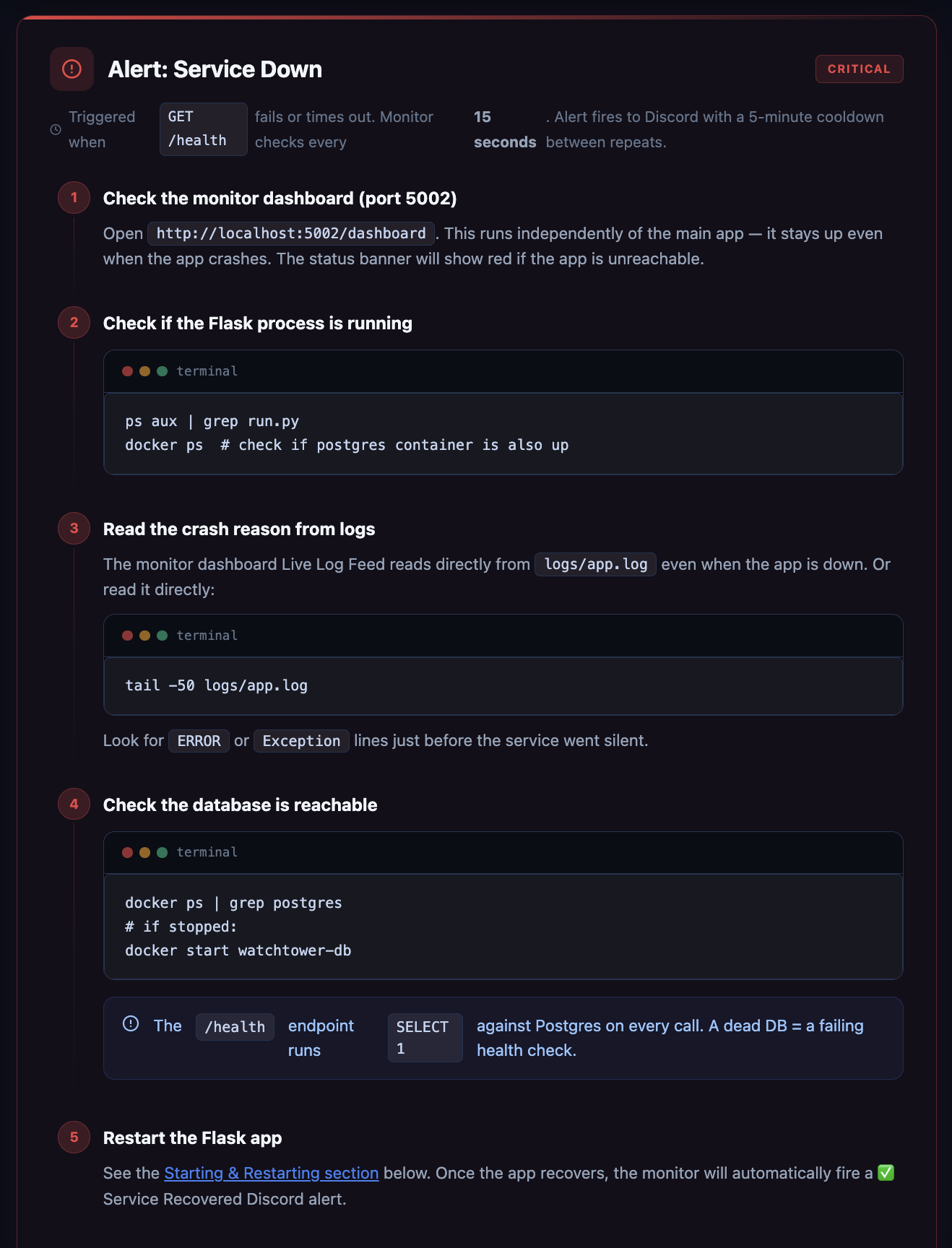
Runbook
-
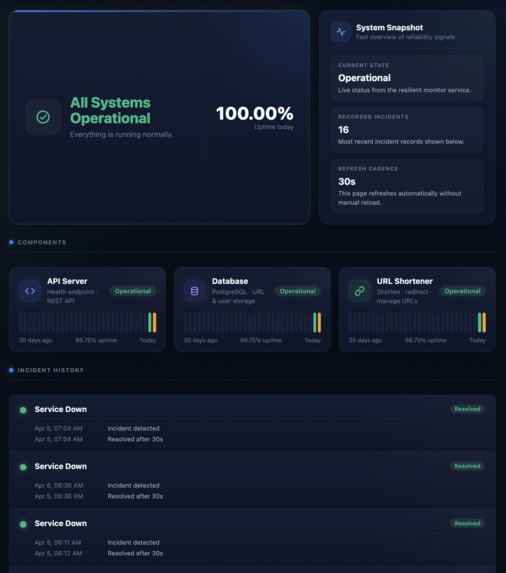
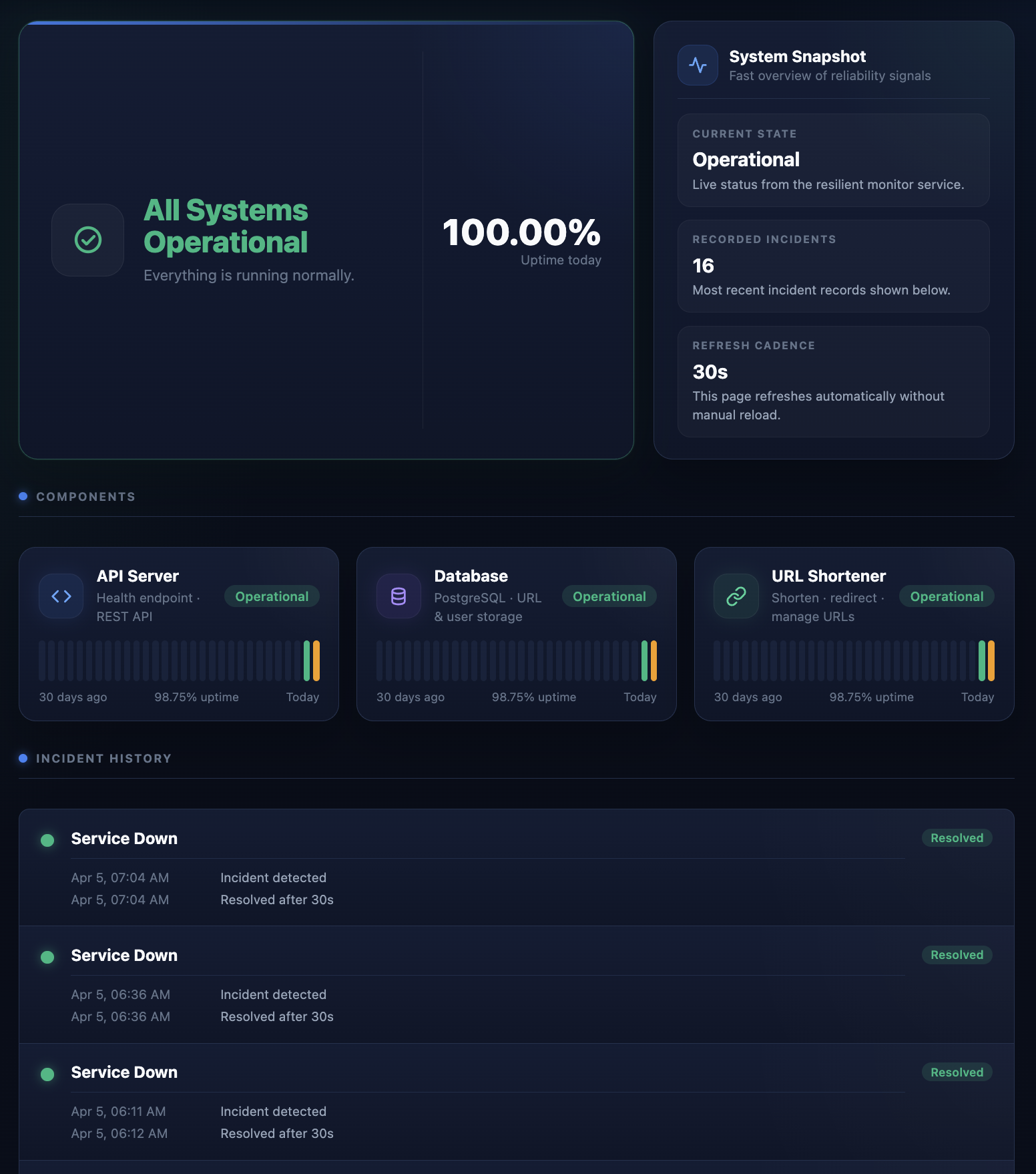
Public Status Page
Inspiration
We wanted to build something that felt closer to real production engineering than a typical CRUD demo. Instead of stopping at “the app works”, we focused on the question production engineering teams actually care about: what happens when it doesn’t?
That led us to build PE Watchtower, an incident response sandbox designed to make failures visible, testable, and manageable. Our goal was to create a system where we could deliberately trigger failures, observe them in real time, alert on them, recover from them, and document the response process in one place.
What it does
PE Watchtower is an incident response and reliability platform built around a live service.
It provides:
- structured JSON logs for every request
- health checks and live metrics
- a resilient monitoring dashboard and public status page
- Discord alerting for service-down, high-error-rate, and burn-rate conditions
- incident tracking and uptime/SLO views
- self-healing and remediation logging
- chaos experiments that inject latency, errors, CPU stress, database failures, and crashes
- a runbook so responders know exactly what to do during incidents
The core idea is simple: don’t just claim a system is reliable — prove it under failure.
How we built it
We built the project using Flask, Peewee, PostgreSQL, and Docker, then layered production-engineering capabilities on top of the core application.
The app exposes operational endpoints such as /health, /metrics, /logs, /slo, /incidents, and /uptime-history. We added structured logging, request tracing, and database-aware health checks so failures become visible immediately.
To make the monitoring experience more realistic, we separated the monitor from the main application. Our independent monitor.py process serves the dashboard and status page on a separate port, allowing the monitoring layer to stay available even if the main service goes down. This gave the project a much more realistic incident-response architecture.
On top of that, we built:
- an admin dashboard for live observability
- a public-facing status page
- Discord-based alerting
- a remediation log for self-healing actions
- an operational runbook
- a chaos testing interface for controlled failure injection
Challenges we ran into
One of the biggest challenges was keeping the monitoring system alive when the main application failed. Early on, parts of the interface were too tightly coupled to the app itself, which meant the dashboard could become unavailable at the exact moment we needed it most. Splitting the monitor into its own process solved that problem, but it also forced us to rethink routing, data access, and how to degrade gracefully when the main app was unreachable.
Another challenge was balancing ambition with hackathon speed. Reliability work can expand endlessly, so we had to stay focused on the features that formed one coherent workflow: detection, visibility, response, and recovery.
We also had to collaborate carefully in parallel, which meant being deliberate about modular file ownership and minimising merge conflicts while still moving quickly.
Accomplishments that we're proud of
We are proud that PE Watchtower became more than just a dashboard with charts.
We built a system where:
- failures can be simulated intentionally
- alerts actually fire
- incidents are recorded
- the status page reflects degradation
- recovery is visible
- responders have a runbook to follow
We are especially proud of the resilient monitor architecture and the chaos engineering interface, because together they turn the project from a passive observability demo into an active incident-response playground.
What we learned
We learned that observability is only one part of incident response. Metrics and logs are useful, but their real value comes from how they connect to alerting, runbooks, recovery workflows, and failure testing.
We also learned how important system boundaries are. Moving the monitor outside the main application changed the design significantly, but it made the system far more realistic and resilient.
Most of all, we learned that production engineering is about confidence under stress. A system feels very different once you can deliberately break it and still understand what is happening.
What's next for PE Watchtower
Next, we want to make PE Watchtower feel even closer to a real production environment.
Planned next steps include:
- persistent long-term metrics storage
- richer incident timelines and automatic postmortem generation
- authentication and role-based access for responders
- more advanced chaos scenarios and scheduled drills
- deeper self-healing workflows
- deployment to a real hosted environment for end-to-end testing
Our long-term vision is to turn PE Watchtower into a hands-on reliability training ground: a place where people can practise incident response, not just talk about it.



Log in or sign up for Devpost to join the conversation.