-
-

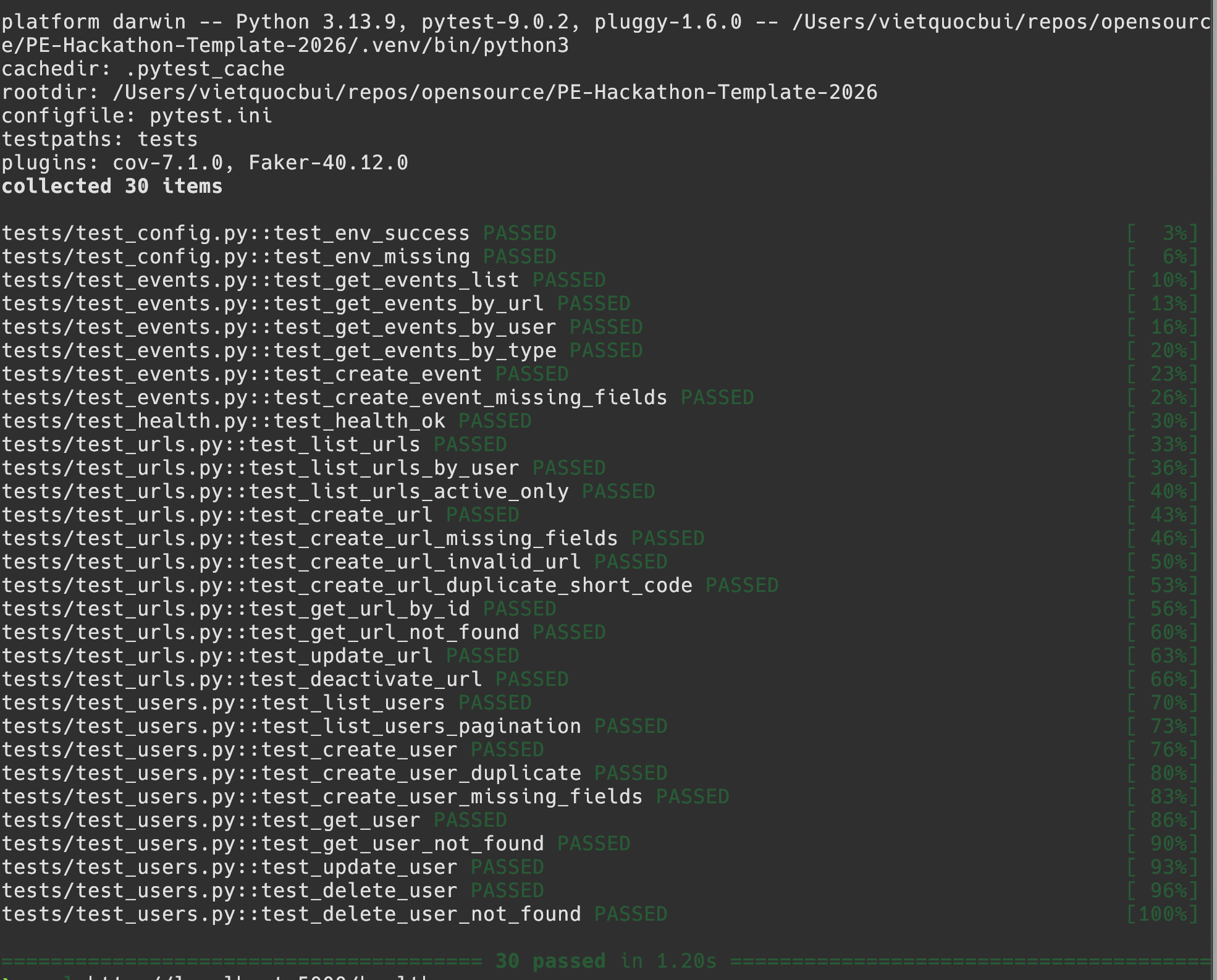
Check health returns status ok 200.
-
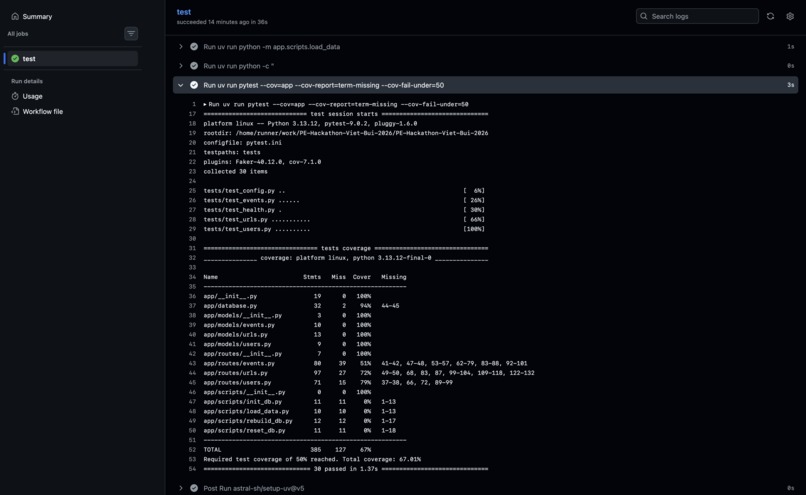
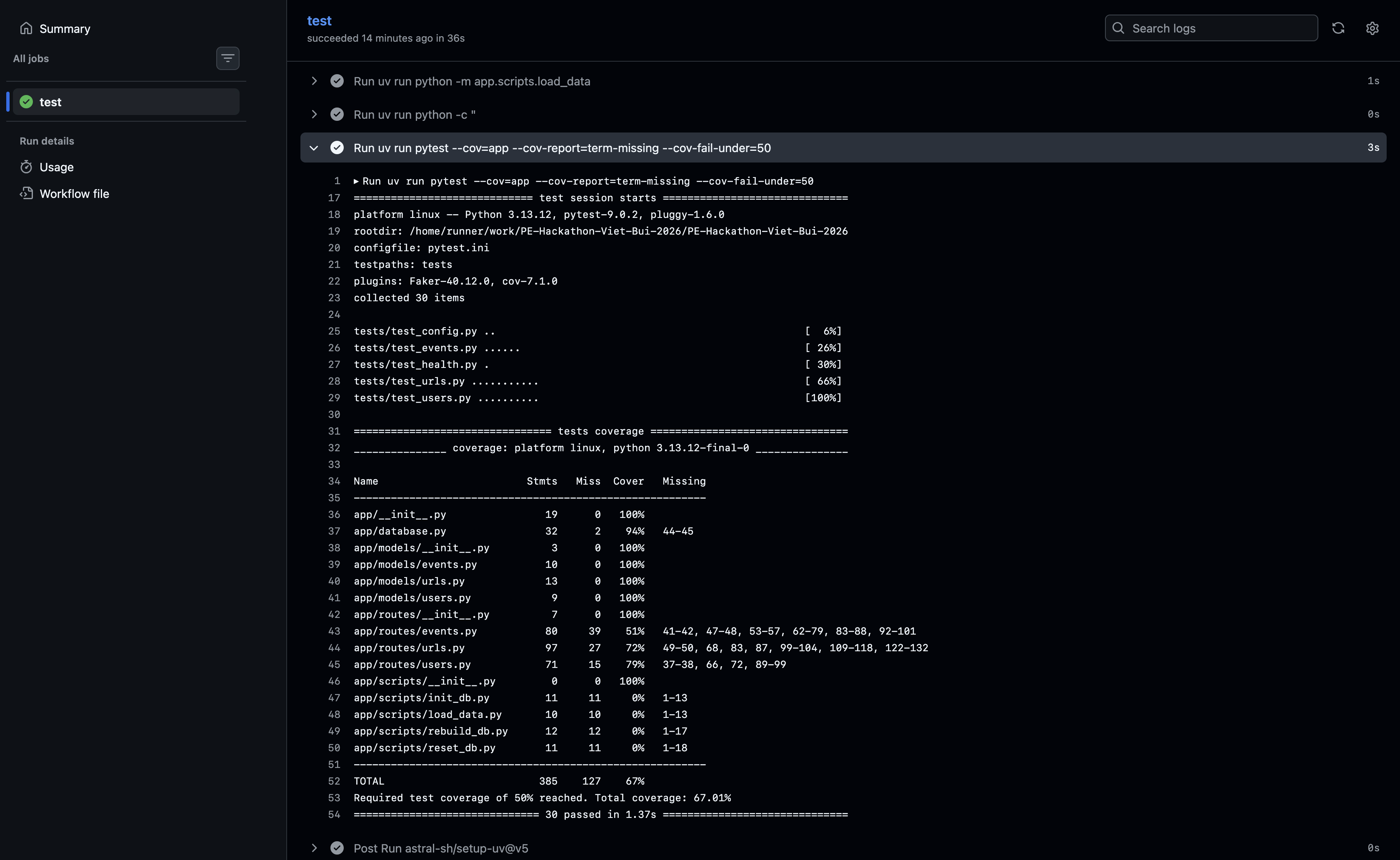
Test coverage for 30 unit tests and on Github CI actions.
-
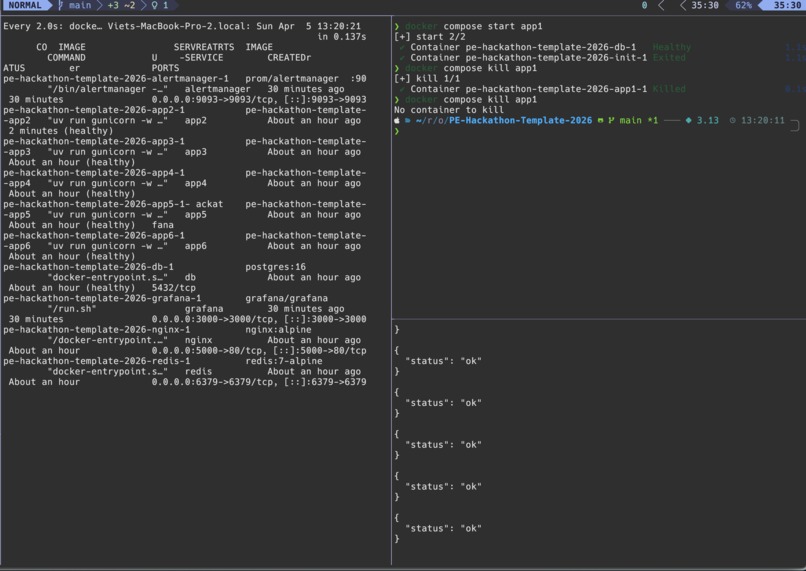
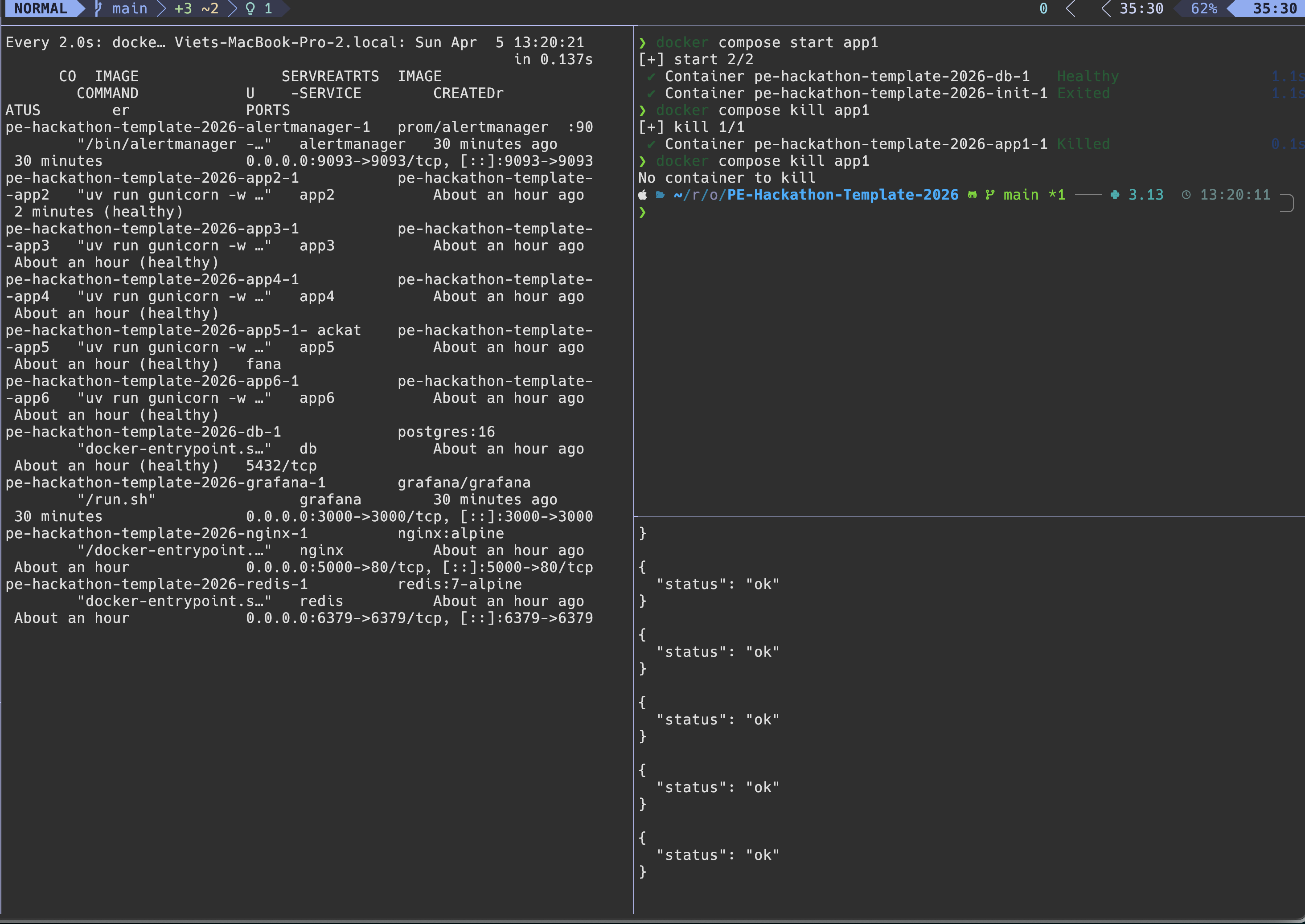
Abrupt killing app will restart the app gracefully
-
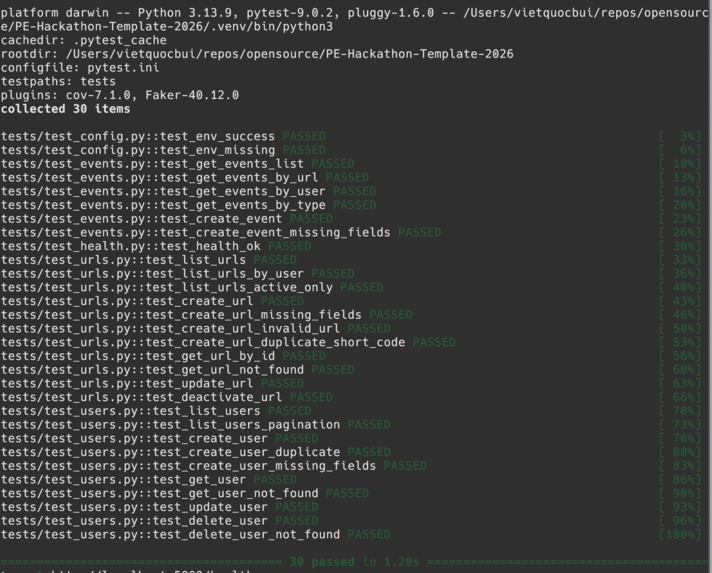
Test coverage for 30 unit tests local.
-
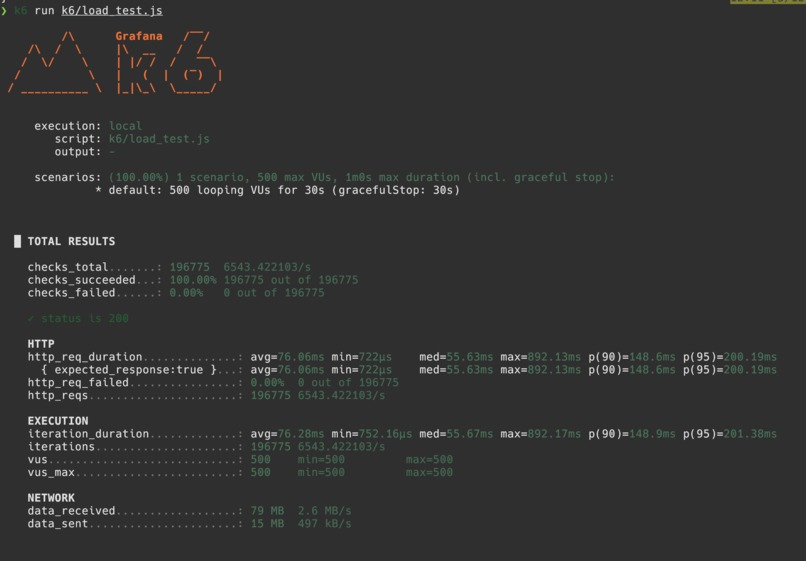
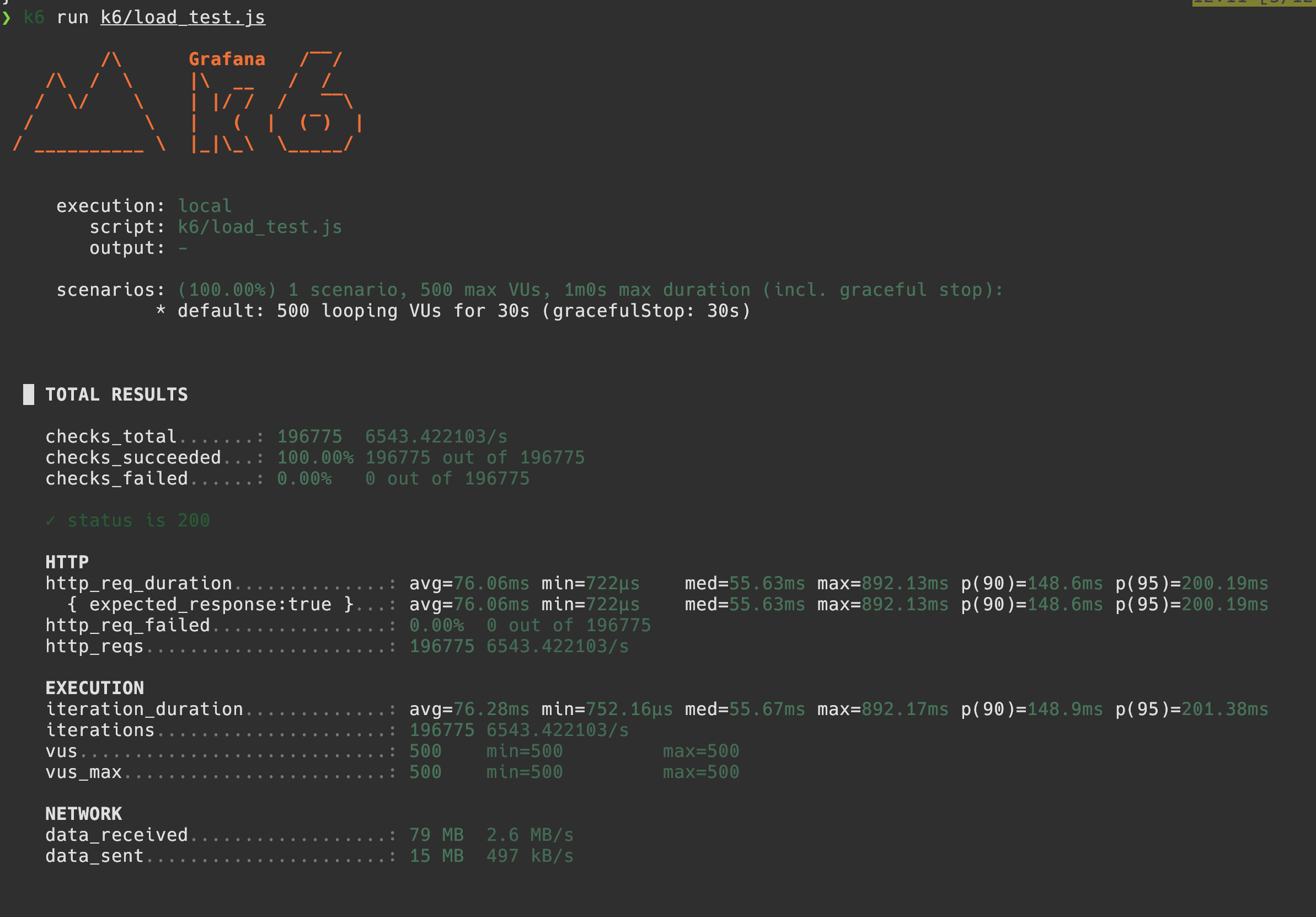
k6 stress test with gunicorn workers, nginx load balancing, and redis caching for urls for 50-500 users.

MLH PE Hackathon 2026 — URL Shortener with SRE Practices
What We Built and Tested
A URL shortener service with full SRE practices layered on top:
- [x] REST API — Flask + Peewee ORM + PostgreSQL with full CRUD for users, URLs, and click events
- [x] Reliability — 30 pytest tests, 66% code coverage, CI/CD via GitHub Actions that blocks deploys on test failure
- [x] Scalability — 6 Gunicorn app instances behind Nginx load balancer, Redis caching, connection pooling
- [!] Observability — Structured JSON logging, Prometheus metrics, Grafana dashboards tracking the four golden signals, Alertmanager with Discord notifications
- [x] Chaos Engineering — Docker restart policies, graceful shutdown with SIGTERM drain, zero-downtime rolling restarts
How we approached the challenge
We followed the template and instructions from the official MLH challenge template on Github. Starting with a Flask + Peewee template, we first focused on getting the data model right — three tables (users, urls, events) with proper relationships and a bulk CSV loader for seed data. After getting the endpoints and relationships figured out, we started implementing incremental unit tests on our local machines.
For scalability, we learned that Flask's development server is single-threaded so if we scaled from 50 to 500 concurrent users, the server would produce a 100% error rate. We found a package to use multi-thread workers called Gunicorn and used 4 workers and 2 threads per container for the k6 tests. Leveraging Nginx load balancing with 6 containers behind, also in addition to redis caching and connection pool for url data with expiration times, dropped errors to 0% at 500 VUs with p95 latency of 200ms.
The load test math:
$$\text{Total connections} = N_{\text{apps}} \times C_{\text{pool}} = 6 \times 15 = 90$$
$$\text{Safety margin} = \frac{\text{max_connections} - \text{total_connections}}{\text{max_connections}} = \frac{500 - 90}{500} = 82\%$$
Keeping total pool connections well under Postgres max_connections eliminated
the "too many clients" errors that caused 45% failure rate at 200 connections.
Redis caching on GET /urls/<id> meant most requests never touched the database:
$$\text{Cache hit rate} \approx \frac{\text{cached requests}}{\text{total requests}} \rightarrow \text{DB load} \propto (1 - \text{hit rate})$$
Challenges that we faced
Database sequence desync was the most recurring bug. Every time CI loaded seed data, subsequent inserts would collide on the primary key. The root cause was
INSERT ... VALUES (explicit_id)didn't update the sequence counter. We found that always callingsetvalafter bulk loads would resolve the issue.Docker networking caused hours of debugging. Nginx couldn't resolve
app1:5000because it started before the app containers were healthy. The fix wascondition: service_healthyindepends_oncombined with proper healthchecks.Flask dev server bottleneck was invisible until load testing. The single-threaded server serialized every request, so 500 VUs meant 499 were always waiting. We immediately thought of using workers to utilize multi-threading and concurrency.
Connection pool exhaustion** at 6 apps × 20 connections > Postgres default 100 max_connections. The fix that we implemented was just scaling horizontally by increasing server capacity and reduce per-client pool size to stay within limits.
What we Learned
- Measure before optimizing: every bottleneck we fixed was invisible until k6 showed me the data.
- The DB is usually the bottleneck: caching, pooling, and connection limits all point back to the database.
- Idempotent scripts can reduce headaches:
on_conflict_ignore,safe=True,setvalafter bulk loads really made managing DB easier. - Restart policies are more complex than we thought: graceful shutdown requires the app to handle SIGTERM, drain connections, and exit cleanly.
Tech Stack
We used Flask, Peewee for the API configurations. PostgreSQL for database, and Redis for caching recent data. We used Nginx for load balancing, with combination of Gunicorn, k6 for measuring scalability and distribution for horizontal scaling. We tried to add Prometheus + Grafana for Monitoring stack as well as Discord + Alertmanager. We used Github Actions for automated CI/CD on Github. Docker for containerization, and pytest, pytest-cov for unit testing and coverage testing.
