-

Sample document page.
-

Color-coded bounding boxes of document objects.
-
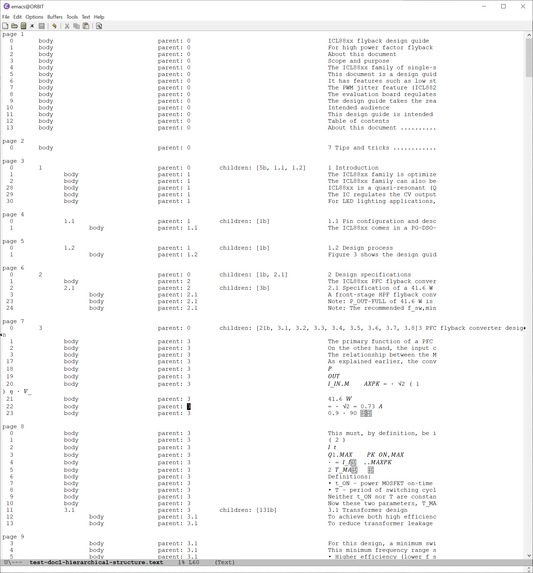
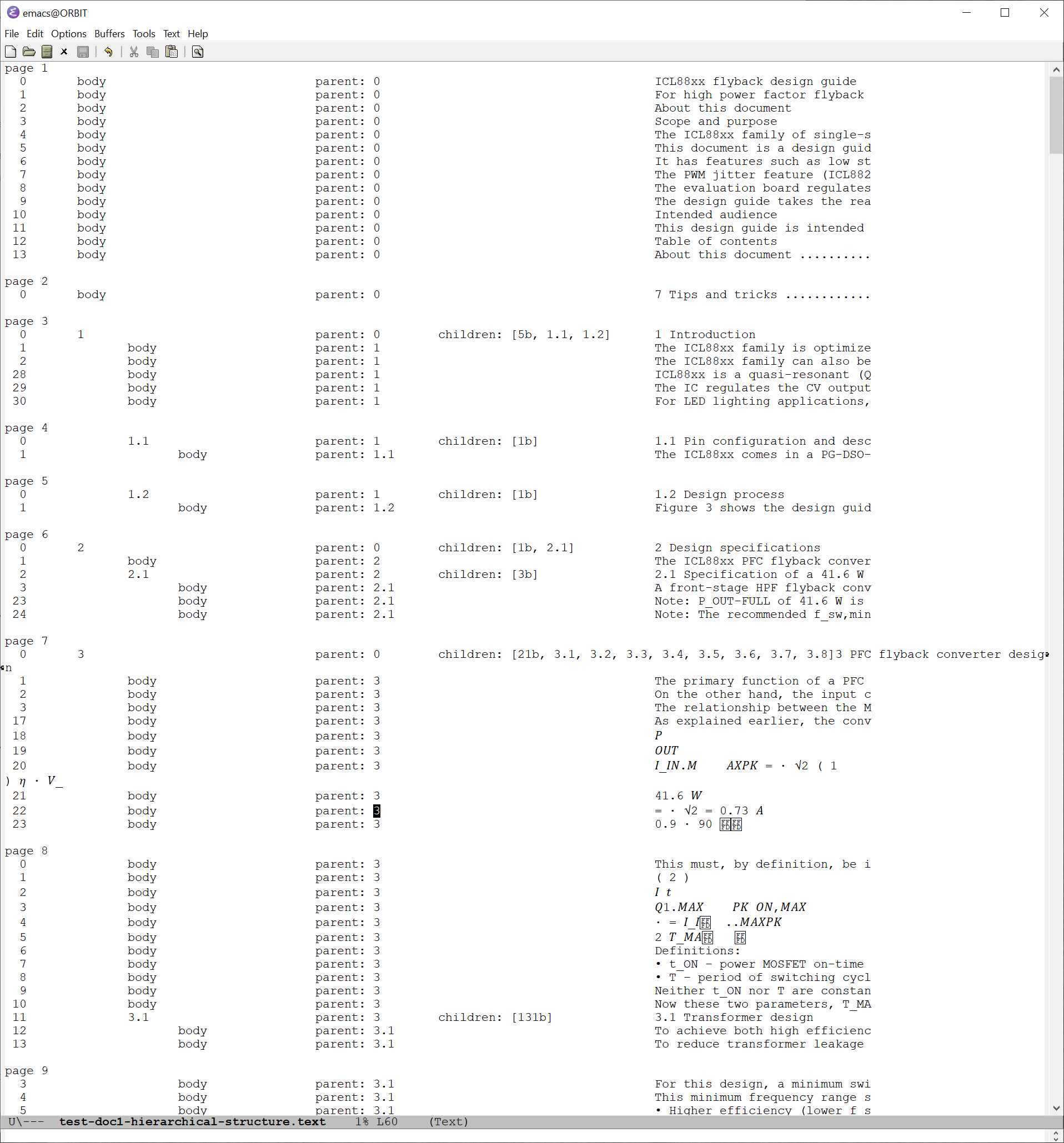
Screen shot of printout of hierarchical structure showing section and body objects across several pages (figs & tables not listed here).


Document logical structure extraction from certain types of pdf documents. Not any and all pdf docs! This is a very heuristic, rule-based approach to extracting logical structure such as section hierarchy; figure & table objects and their captions; headers & footers. Currently targeted to single-column technical documents. Uses pdfplumber for raw pdf extraction, then table detection & parsing relies on camelot. Important for RAG to extract meaningful chunks both for retrieval and LLM context. Not yet released---would love more examples from real use cases.


Log in or sign up for Devpost to join the conversation.