-
-

-
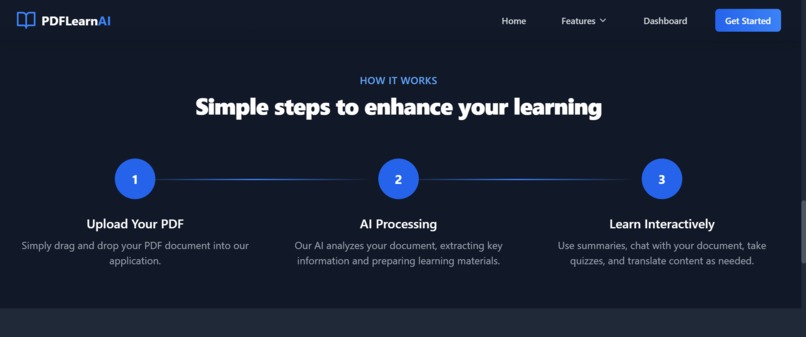
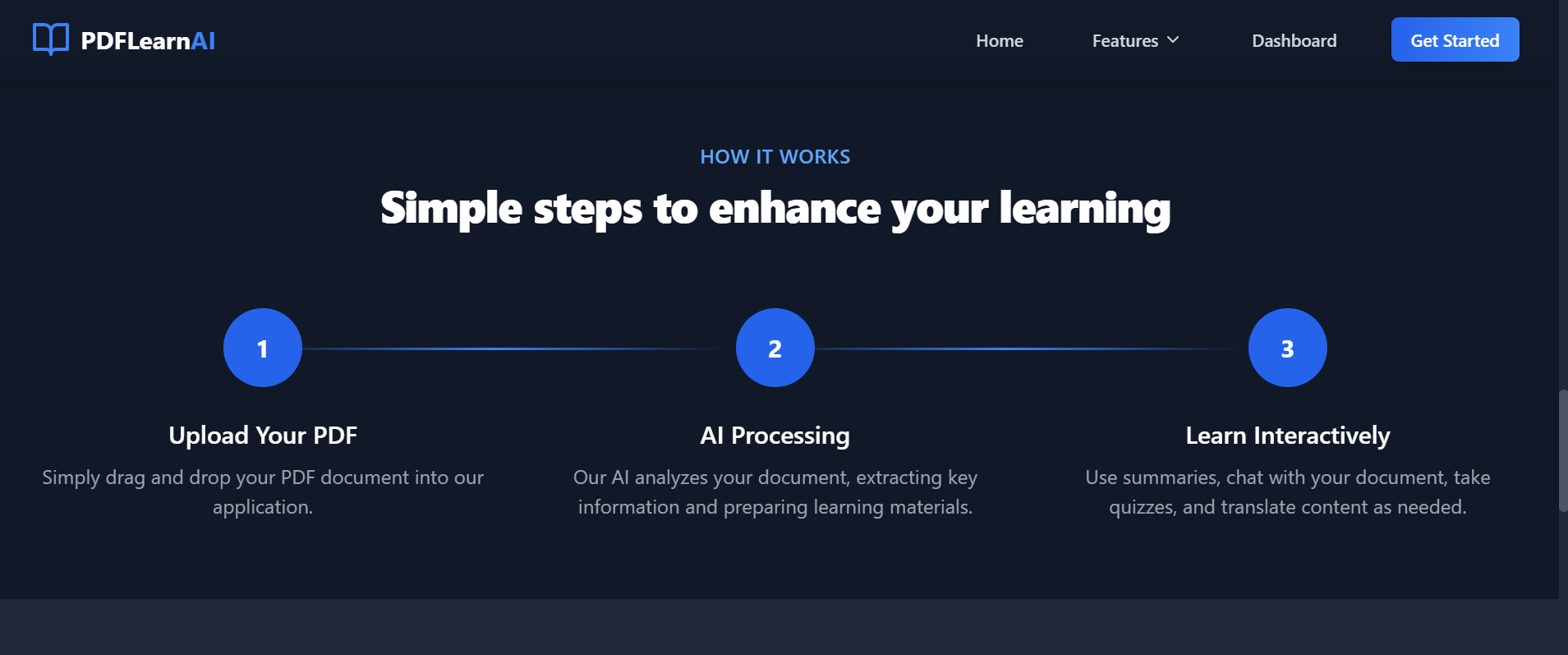
How it works
-
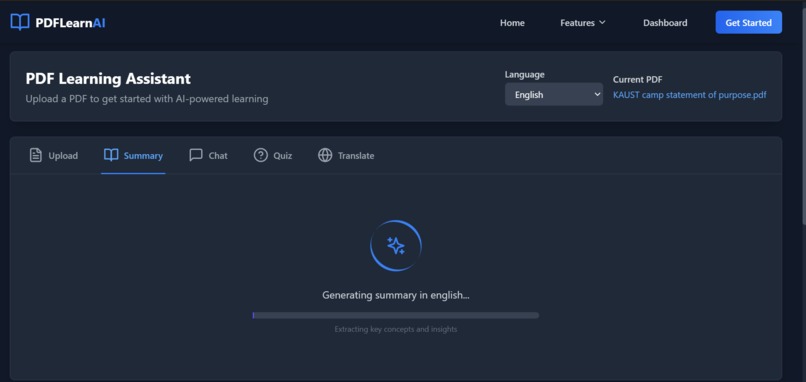

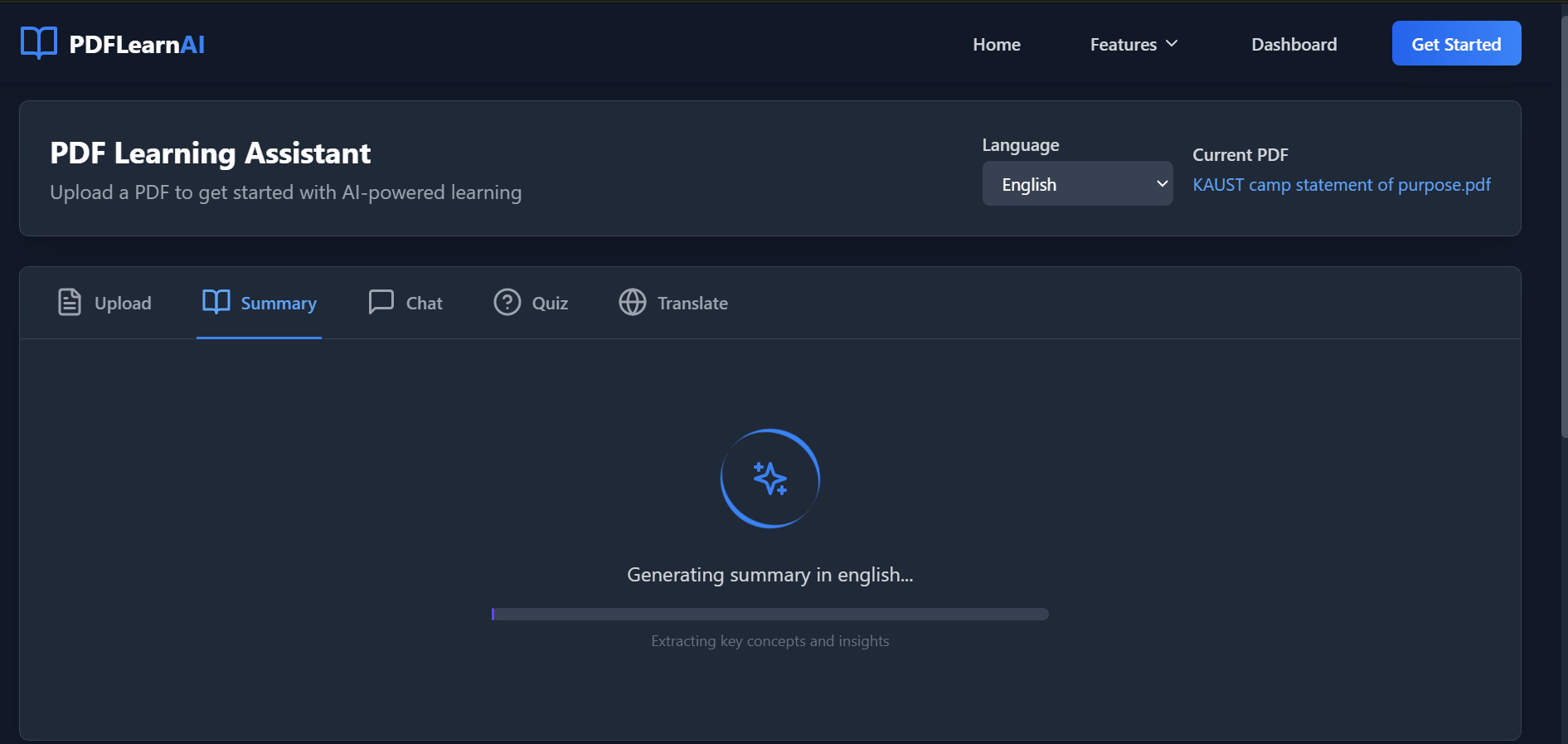
Inspiration
In today’s fast-paced world, processing and understanding large PDF documents can be overwhelming, especially for non-native speakers or those who lack access to educational resources in their local languages. We were inspired to create PdfLearnAI to bridge this gap by leveraging AI to make PDFs more interactive, accessible, and engaging for learners, professionals, and researchers regardless of language barriers.
What it does
PdfLearnAI is an AI-powered platform that transforms static PDFs into dynamic learning tools. It allows users to:
Summarize lengthy documents into concise, easy-to-understand summaries.
Translate PDFs into multiple languages(French, Kinyarwanda for now), breaking language barriers and making education accessible to everyone, especially in Africa with diverse local languages.
Chat with the PDF to ask questions and get instant answers.
Generate quizzes based on the content to test understanding and reinforce learning.
How we built it
Frontend: Built with Reac (vite)t and Tailwind CSS for a responsive and user-friendly interface.
Backend: Powered by Node.js and Express for handling file uploads, API requests, and data processing.
AI Models:
OpenAI GPT-4o-mini for summarization, chat, and quiz generation.
Facebook’s NLLB-200-3.3B for translation, supporting over 200 languages, including many African languages.
Database: PostgreSQL with Row-Level Security (RLS) for secure data storage.
APIs: Integrated OpenAI and Hugging Face APIs for AI functionalities.
Challenges we ran into
Accomplishments that we're proud of
- Successfully integrating multiple AI models (OpenAI and Hugging Face) into a seamless workflow.
- Creating an intuitive and visually appealing user interface.
- Building a robust backend that handles file uploads, processing, and secure data storage.
- Delivering a platform that saves users time and enhances their learning experience.
- Breaking language barriers by supporting translation into over 200 languages, including many African languages.
What we learned
- The importance of token management when working with large documents and AI models.
- How to effectively combine computer vision (for PDF parsing) and natural language processing (for summarization, chat, and translation).
- The value of user feedback in refining features like quiz generation, chat interactions, and translation accuracy.
- Best practices for secure database management with Row-Level Security (RLS).
- The challenges and opportunities of supporting underrepresented languages in AI models.
What's next for PdfLearnAI
- Expand Language Support: Improve translation quality for underrepresented African languages by fine-tuning models on local datasets.
- Multimodal Support: Add image analysis for PDFs with diagrams, charts, and graphs.
- Mobile App: Develop a mobile version for on-the-go learning, especially in regions with limited access to computers.
- Collaborative Features: Allow users to share and collaborate on PDFs in real-time.
- Advanced Analytics: Provide insights into user learning patterns and quiz performance.
- Custom AI Fine-Tuning: Fine-tune AI models for specific domains (e.g., medical, legal, or academic PDFs).
- Offline Mode: Enable offline access to summarized content, quizzes, and translations.
- Community Contributions: Allow users to contribute translations and educational content in their local languages.


Log in or sign up for Devpost to join the conversation.