



Inspiration
This summer I found out about the Philly Bail Fund during the BLM protests. Another person wrote a number on my arm in marker and told me that if I needed to post bail to give them a call. When I got home safely, I looked up the number and found out about PBF's great work on their website.
What it does
I created a series of visualizations and predictive models to help better understand the data.
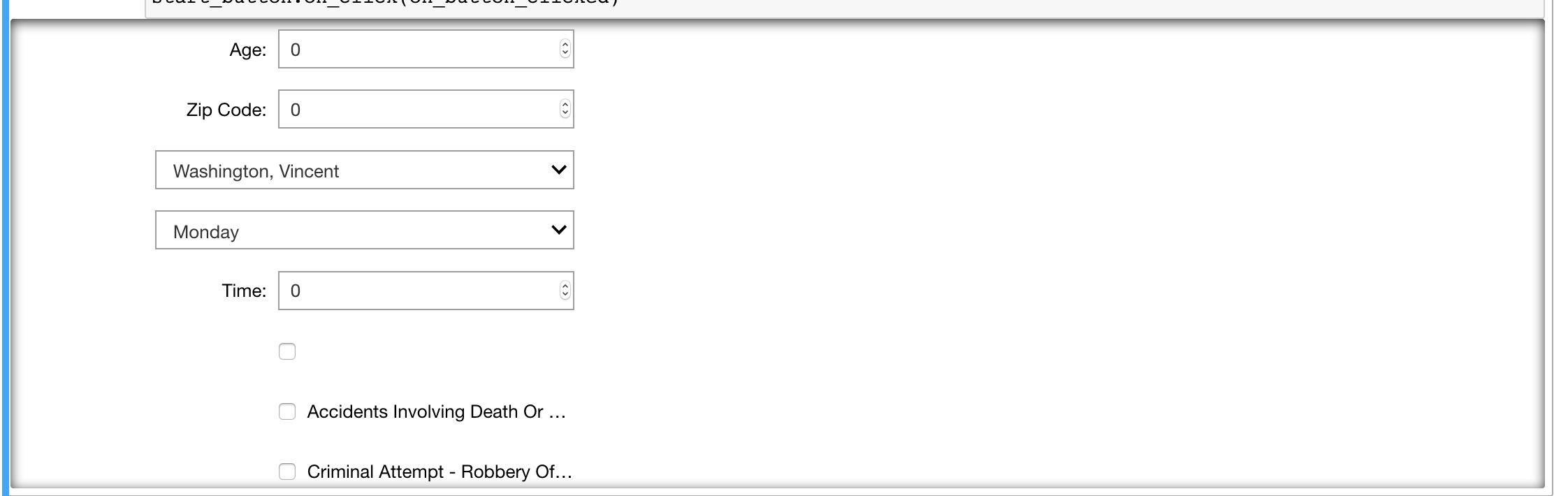
I created a RandomForest machine learning model to predict bail amount based on a number of relevant variables. I also created a web interface to enter information for prediction. Unfortunately, I ran out of time so clicking the button doesn't run the prediction, but the interface and model all work.
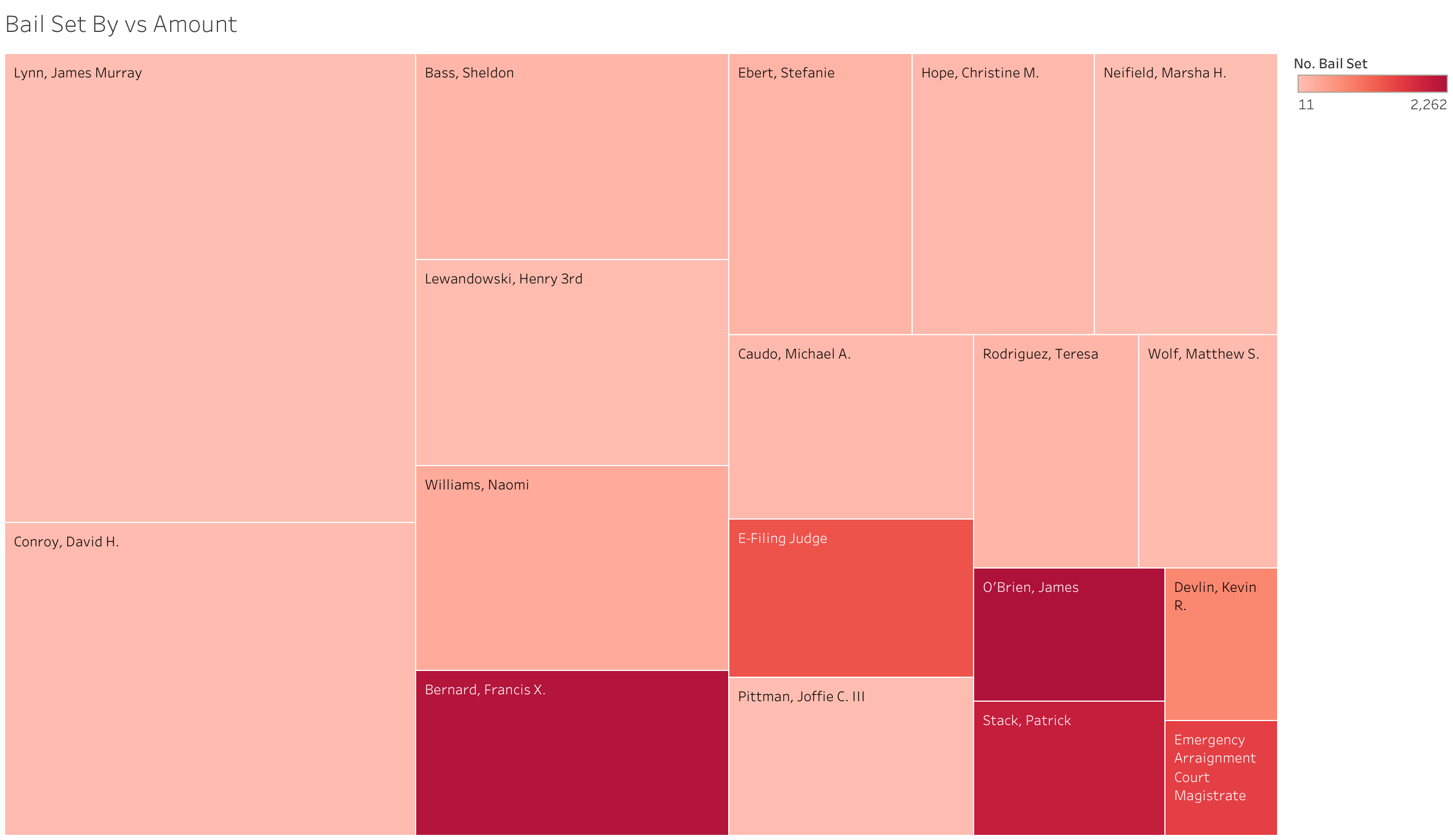
Bail Set vs Amount) This is a heatmap of which person sets the highest median bail (for people who have set it more than 10 times). The darker colors represent a higher volume of bails being set.
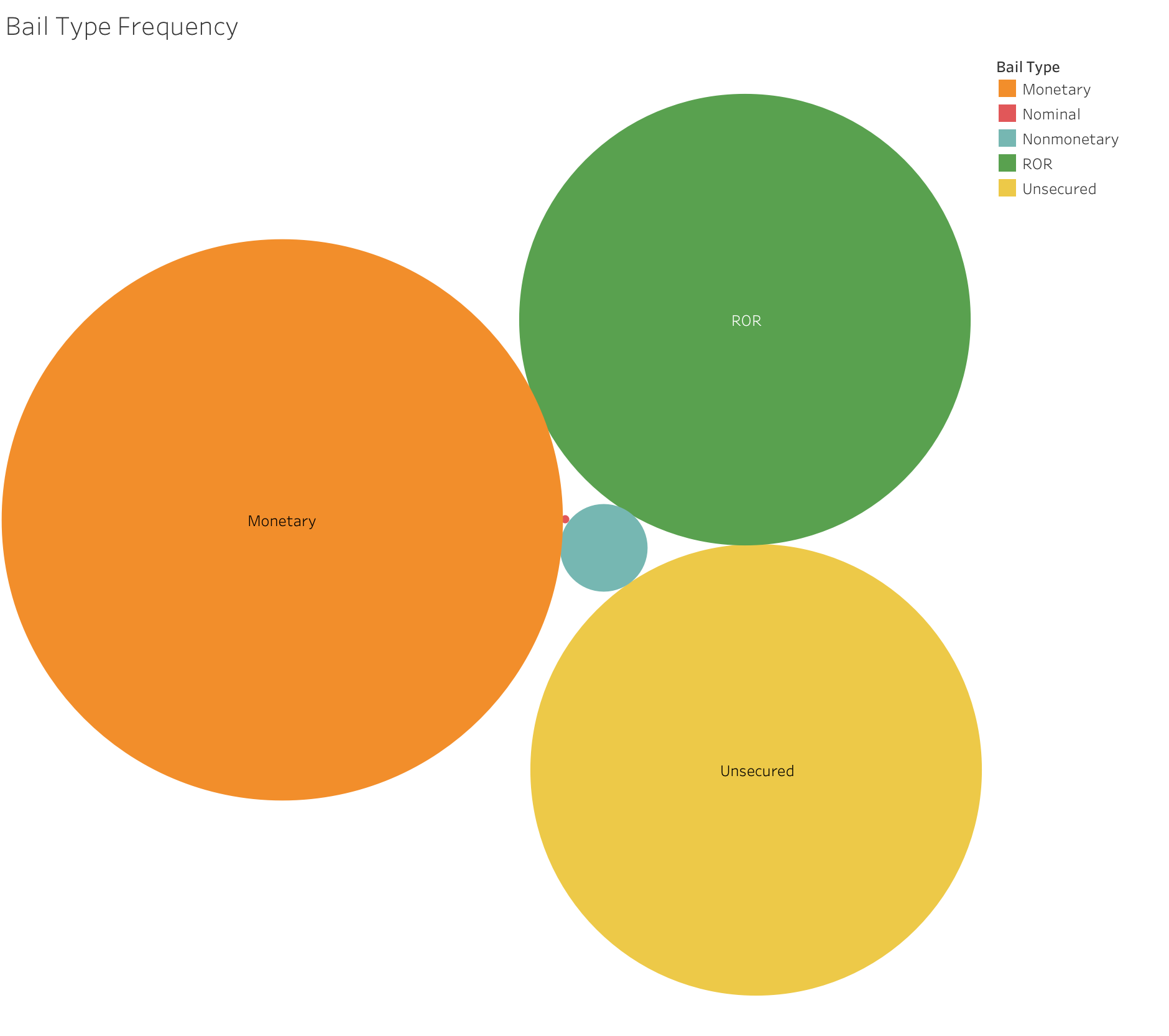
Bail Type Frequency) This unique chart shows the frequencies of the different types of bail set.
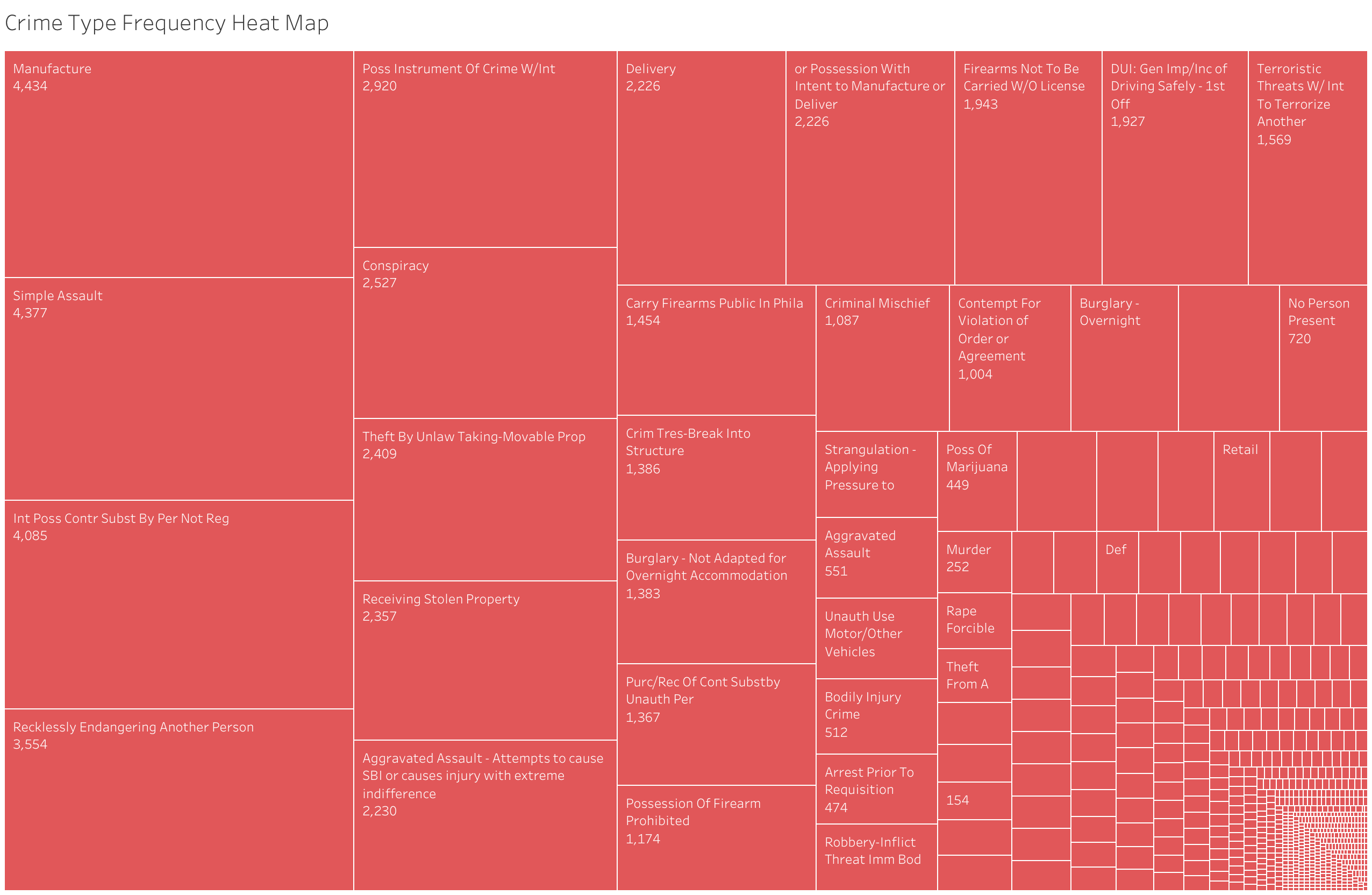
Crime Type Frequency) This shows the most common offenses individuals were arrested for.
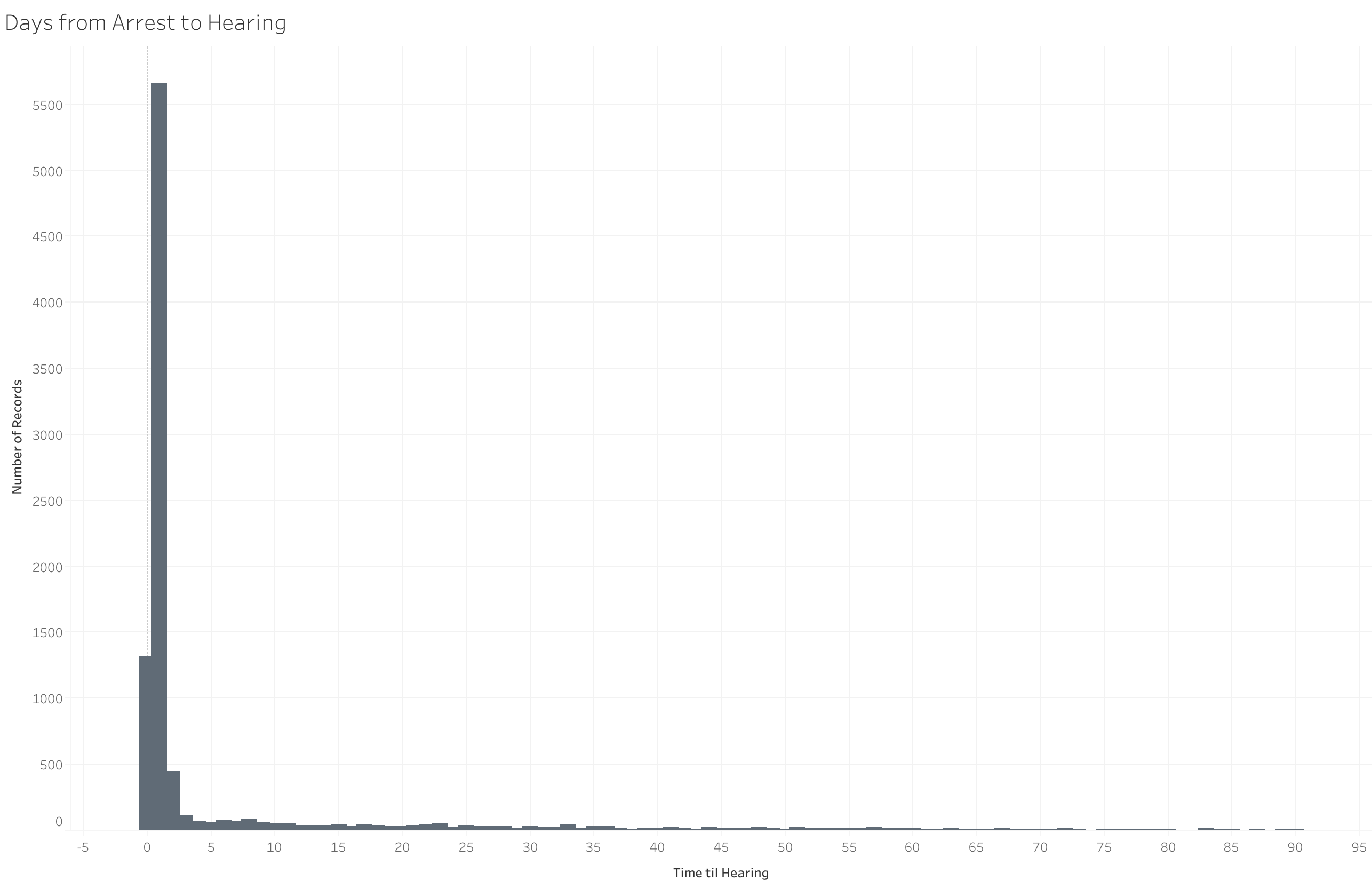
Days from Arrest to Hearing) This chart shows the # of days from a person being arrested to having a preliminary hearing. Ideally this number should be low due to the guarantee of a speedy trial, but sometimes it can slip.
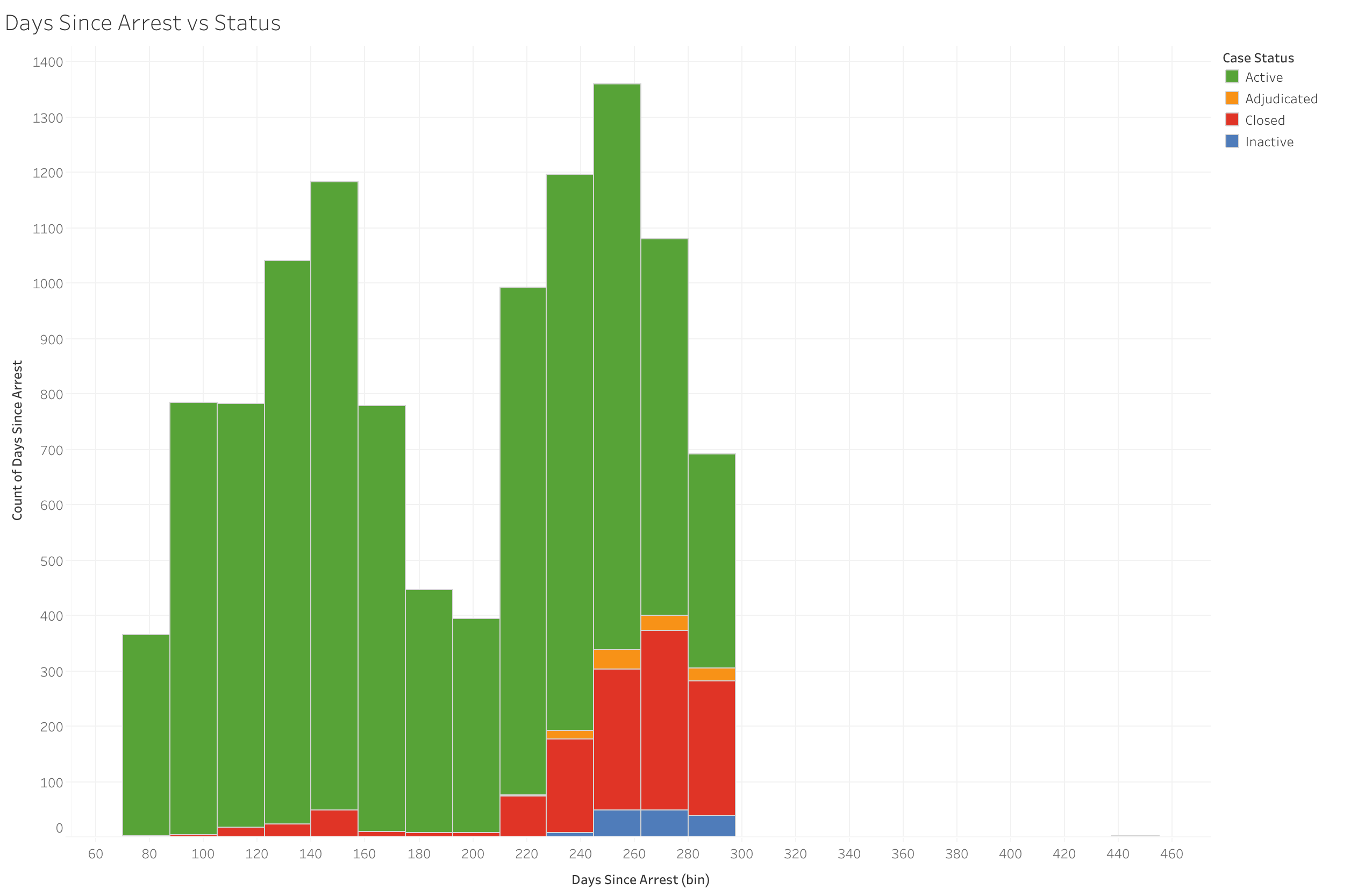
Days Since Arrest vs Status) This shows the number of days it has been since the person was arrested and the current status of the case.
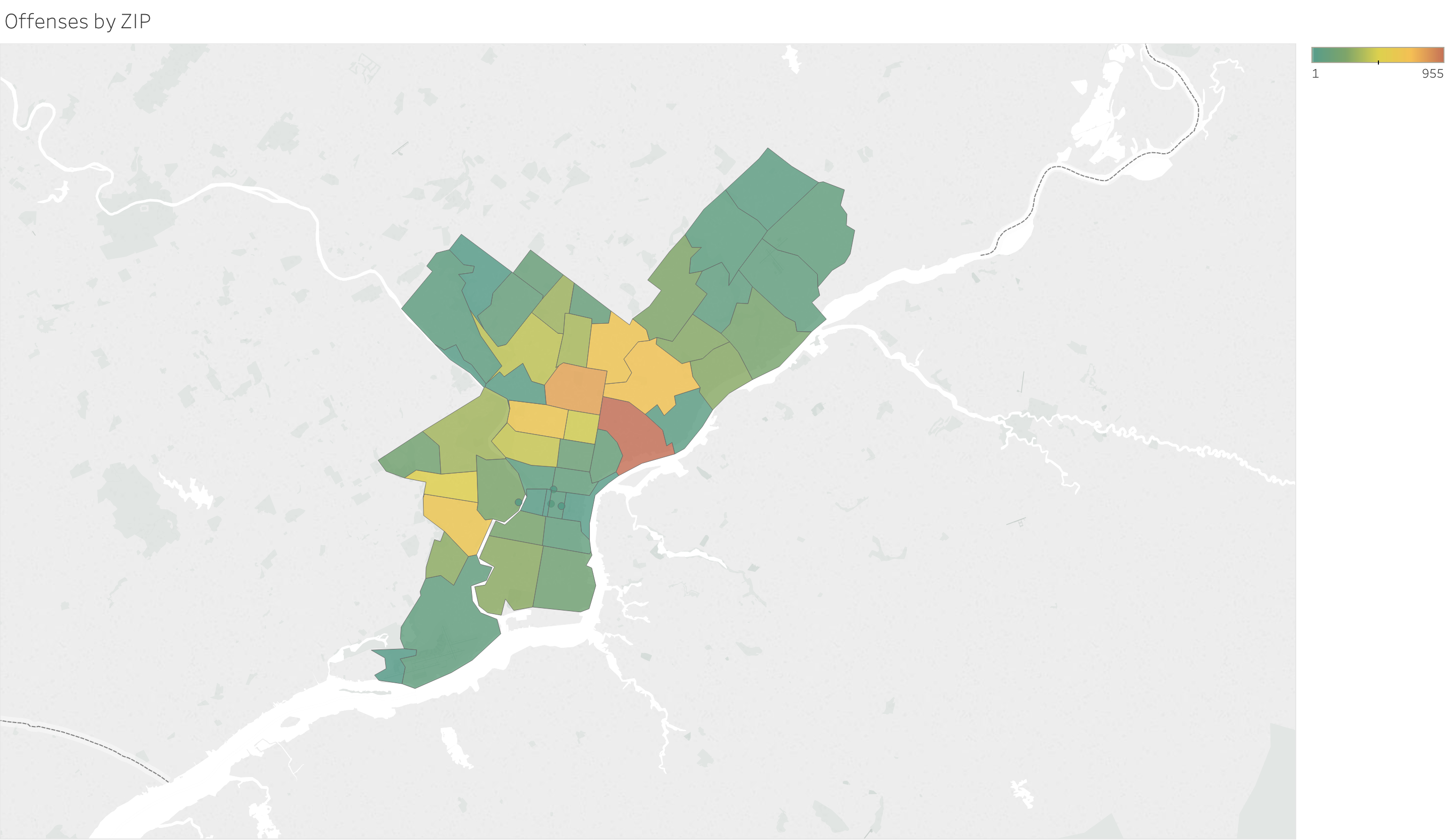
Offenses by ZIP) The # of offenses by Philadelphia zip code
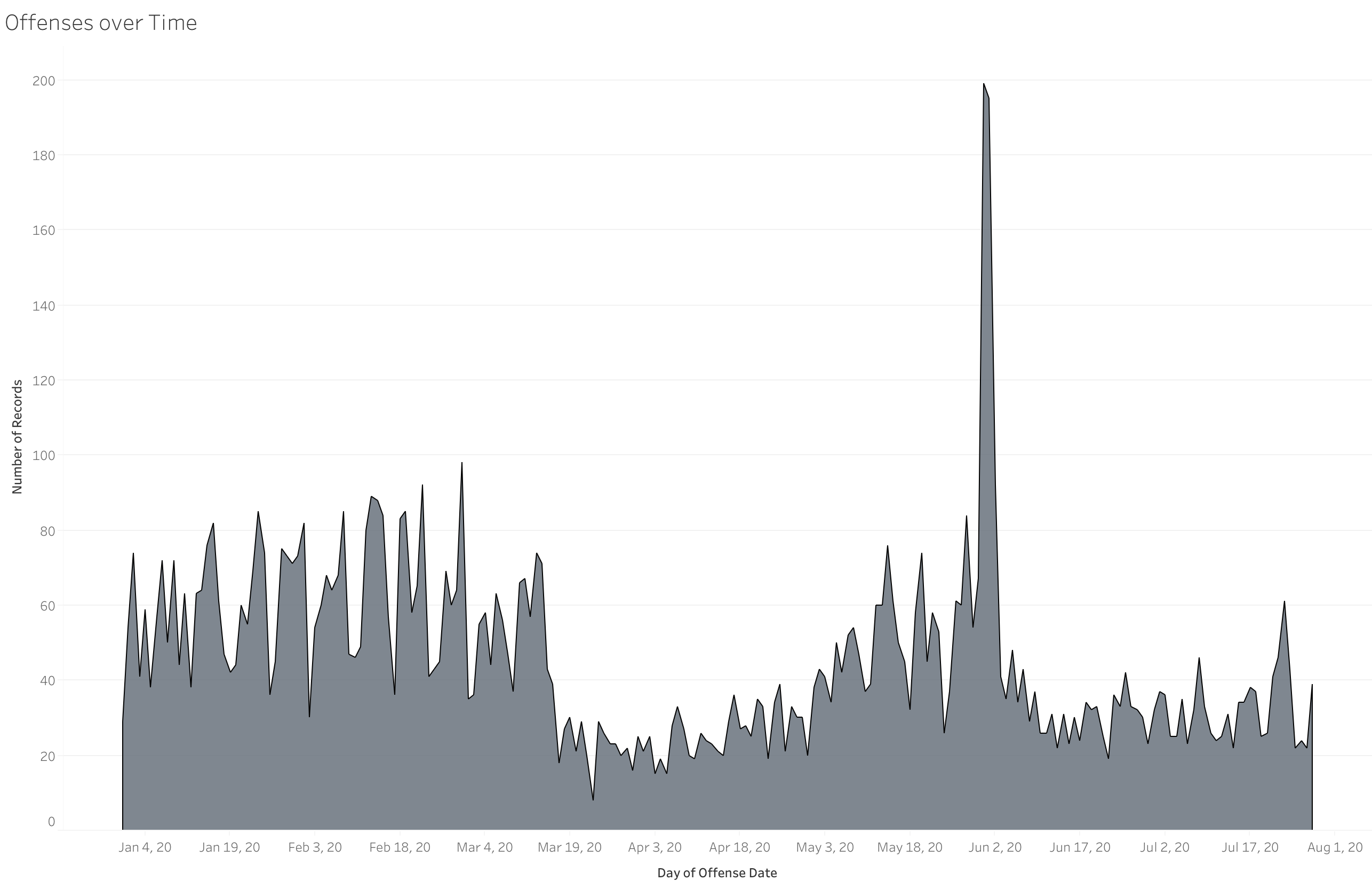
Offenses over Time) This shows the number of arrests for the past year. Note the dip in mid-March when people started quarantining and the spike during this summer's BLM protests.
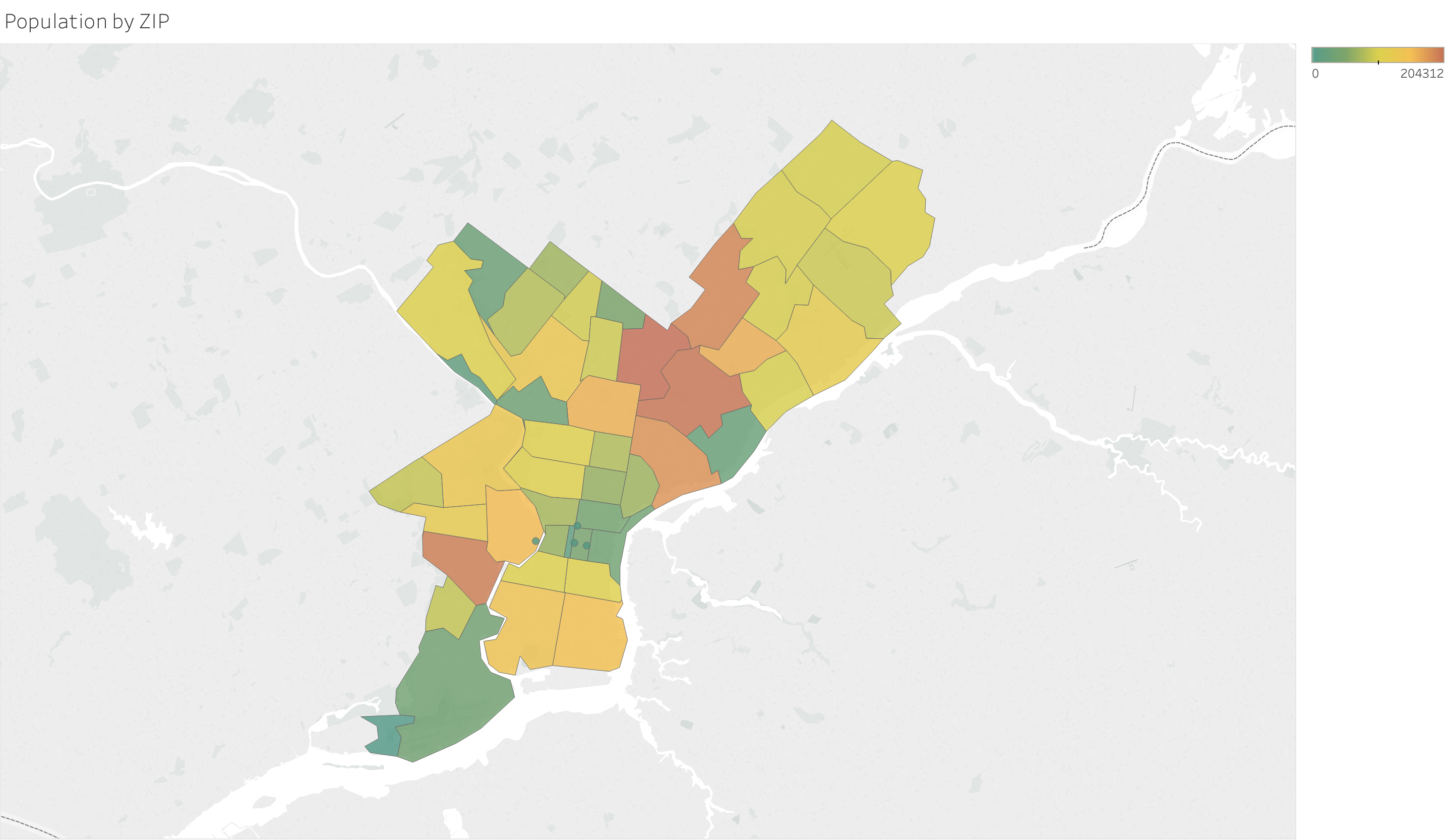
Pop by ZIP) Shows the population by Philadelphia Zip Code
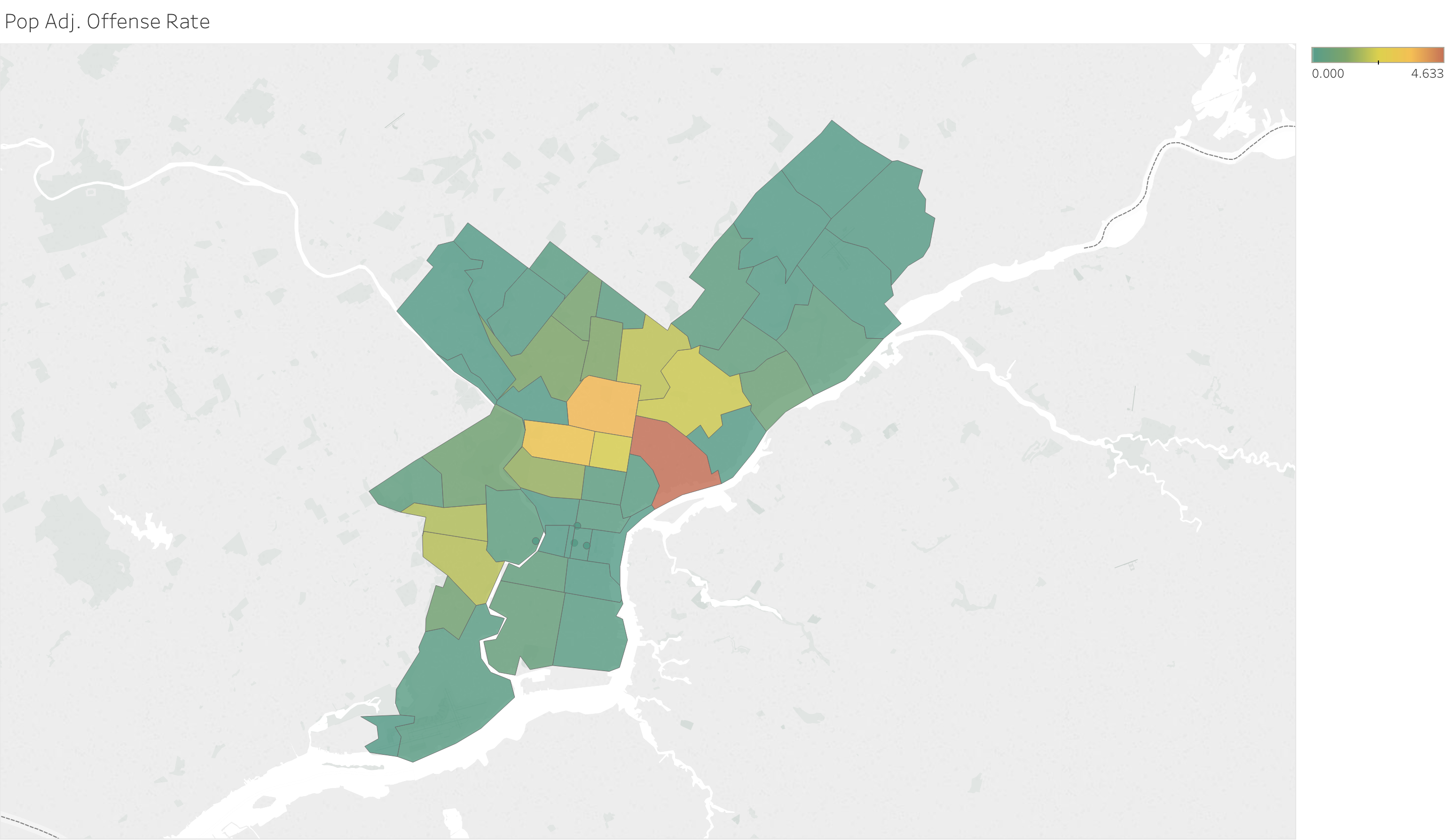
Pop Adj. Offense Rate) Shows the rates of offenses in each Philadelphia zip code adjusted for population. The highest number occur in upper north Philadelphia.
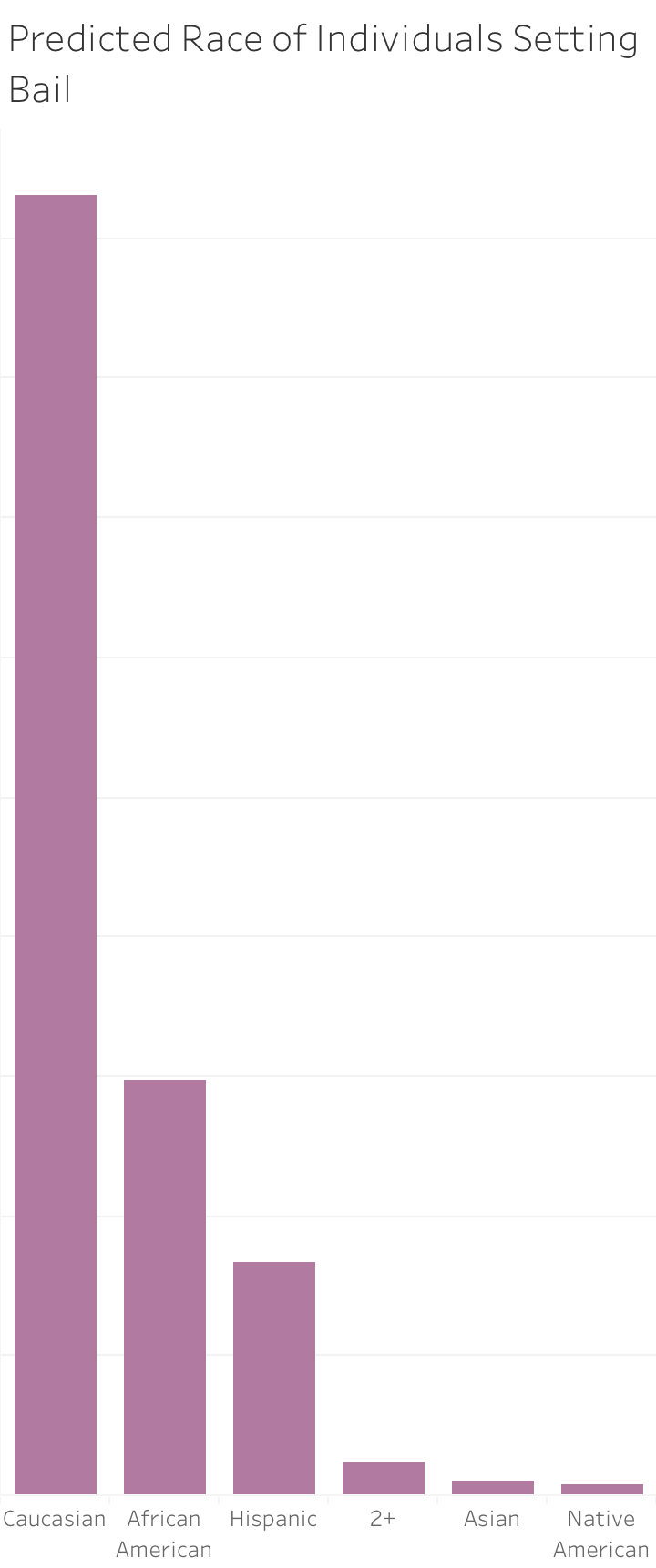
The data for these next charts was created in R. I used a library which takes a surname and tries to predict race based on US Census data. The goal was to analyze the names of bail setters and arresting officers and see how well the race demographics are representative of the Philadelphia community. Due to the method in which this is predicted take it with a grain of salt, but it was an interesting idea to put the name data to use.
How I built it
I used Python to process and clean data. I also used it to create the RandomForest Regression model using SKLearn and built the web interface for users to interact with.
I used R to predict the bail setter and arresting officer's races based off surnames.
I used Tableau to create charts from the CSV files exported from R and Python.
Challenges I ran into
I ran into challenges coming up with ideas, getting code to run, and PyCharm crashing on me. Overall, I'm proud of my work and of how much I learned and accomplished in 24 hours.
Accomplishments that I'm proud of
I'm proud that I was actually able to build my first ML model on a real dataset outside of simple book examples. I also thought the dataset was fun to work on giving what PBF does. It was also my first time making a web interface in a Jupyter library and I'm surprised how easy it is. Finding that R library was super neat as well.
What I learned
I strengthened my skills with R/Python identified weak areas to work on.
What's next for PBF Data Analysis
I plan to potentially polish it up and turn it into a project I can showcase to potential employers on my website (https://jaredstef.me/). Maybe given an extra couple hours I can get the web interface working and in the future I can apply more advanced machine learning techniques. Overall I'm happy and had fun.


Log in or sign up for Devpost to join the conversation.