-
-
fraud detection
-
fraud data generation
PaymentGuard: Our Story
Inspiration
Fraud detection in finance faces two core problems: scarce fraud data and hard-to-detect patterns. Real fraud is rare (often under 1% of transactions), so teams struggle to train models. At the same time, PCI-DSS and privacy rules limit how much real payment data can be used. We wanted to build a system that (1) generates same-distribution synthetic fraud data from only a few labeled examples, and (2) performs reliable, explainable fraud detection—not just a 0/1 label but a clear reason for each decision. That combination—few-shot data generation plus explainable detection—is what inspired PaymentGuard.
What it does
PaymentGuard is a multi-agent system for FinTech that does two main things:
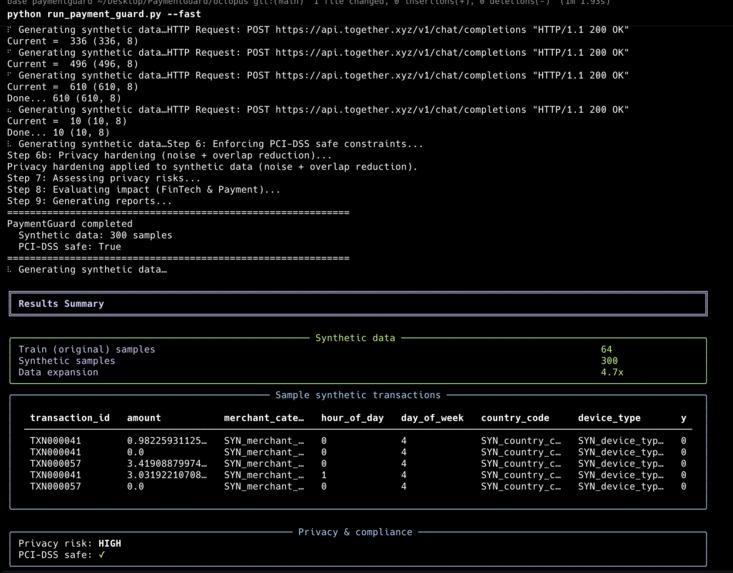
Few-shot synthetic fraud data generation: Given a small set of real (and optionally synthetic) transaction rows, the system uses prompt-based context-learning so a large language model generates new rows that match the same distribution. The pipeline enforces schema alignment, value ranges, and PCI-DSS safety (no real PAN/CVV). Teams can use the synthetic data to augment scarce fraud samples for training or testing.
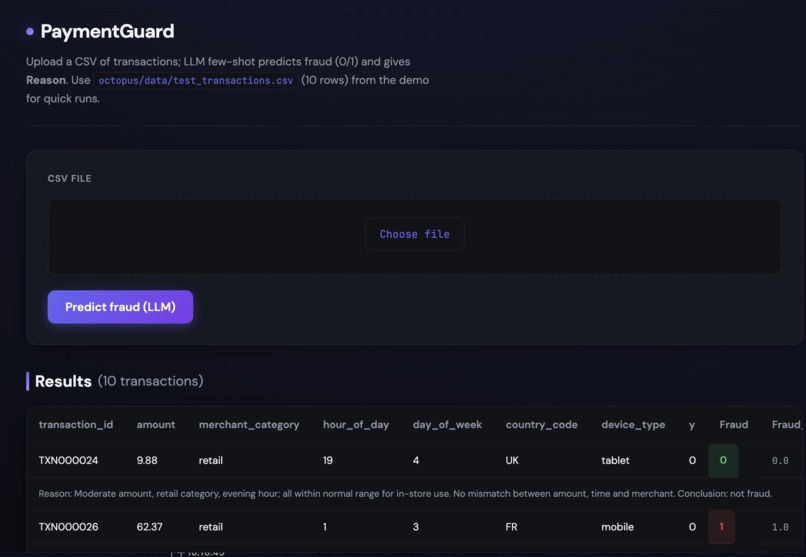
Explainable fraud detection: Users upload a CSV of transactions (e.g. via the web app). The system runs few-shot LLM prediction: it uses labeled examples plus domain background to predict Fraud (0/1) and a Reason (2–3 sentences of judgment logic) for each transaction. So every decision is interpretable—not just a score but why it was flagged or cleared.
The demo runs end-to-end: run the pipeline once to produce original + synthetic data and an HTML report; then start the web app and upload a test CSV to see predictions and reasons in the results table.
How we built it
- Synthetic data generation (few-shot, same distribution)We built a prompt-based pipeline so the model performs context-learning on a small set of real (and optionally synthetic) rows:
- MetaOptimizer V7 analyzes the training data (class balance (y), feature distributions, correlations) and produces a short statistical summary.
- A class-conditional template is built: the prompt includes
{data}(few-shot rows) and{format_instructions}(JSON schema). The LLM is asked to generate new rows that match the same distribution as the provided examples. - We filter generated rows (schema alignment, value ranges, optional PCI checks) and rank them. If the LLM output is invalid, we fall back to a statistical (e.g. sampling from marginals) generator so the pipeline always returns data.
The pipeline is implemented in synthetic_pipeline_v7.py; the LLM generation step uses the same API (e.g. Together) as the rest of the project.
- Reliable fraud detection with reasonsWe wanted predictions to be explainable: for each transaction, the system outputs Fraud (0/1), a score, and a Reason (2–3 sentences of judgment logic).
- Few-shot prompt: We build a prompt with (a) a short background on fraud vs legitimate indicators (amount, time, merchant, PCA-style features), (b) labeled examples sampled from original + synthetic data (balanced fraud/non-fraud), and (c) the query transactions without labels.
- We ask the model to output one line per transaction:
{"prediction": 0 or 1, "reason": "detailed judgment logic"}. The "reason" must describe what stands out, how it relates to fraud/legitimate behavior, and a clear conclusion. - Parsing:
_parse_prediction_reason_linesscans the LLM response line-by-line, extracts JSON objects, and fills in default prediction/reason when parsing fails. We batch transactions (e.g. 50 per request) to keep latency and token usage reasonable.
This lives in llm_fraud_predictor.py; the web app in app_fraud_detection.py displays Fraud, Fraud_Score, and Reason in the results table.
- Multi-agent orchestration- FinTech Payment Agent (
fintech_payment_agent.py): Infers payment/transaction schema (amount, merchant, time, fraud label), enforces PCI-DSS safe constraints (no real PAN/CVV in output). - Privacy Guard Agent (
privacy_guard_agent.py): Detects PII/PCI-sensitive columns and applies policies before data is sent to the generator. - Pipeline V7 (
synthetic_pipeline_v7.py): Statistical audit → one-shot prompt optimization → class-conditional LLM generation → deterministic filter and rank. - Impact Evaluator (
impact_evaluator_agent.py): Quantifies business impact (e.g. fraud prevented, cost savings) for reports.
The demo script run_payment_guard.py wires these together: it loads (or creates) payment data, runs the pipeline to produce last_original.csv and last_synthetic.csv, and generates an HTML report. The web app then uses those two files as few-shot sources for the LLM fraud predictor when the user uploads a CSV.
Challenges we ran into
LLM output format: The model sometimes returned extra text, markdown, or malformed JSON. We addressed this with line-by-line parsing, regex fallbacks for a single 0/1 when JSON fails, and a fixed per-line format in the prompt so the model is more likely to output parseable lines.
Schema and distribution alignment: Generated rows had to match the training schema (column names and types) and plausible value ranges. When the dataset had many numeric columns (e.g. PCA features V1–V28), LLM-generated values could fall outside observed ranges. We added validation and filtering; if all candidates were rejected, we fall back to statistical generation so the pipeline still returns data.
Balancing fraud vs normal in few-shot: For both generation and prediction, we need enough fraud and non-fraud examples in the prompt. We implemented stratified sampling (e.g. (n/2) fraud, (n/2) non-fraud when available) so the model sees both classes and does not collapse to a single label.
Latency vs batch size: Larger batches reduce API calls but increase delay and token limits. We tuned batch size (e.g. 50 for prediction) and max tokens per request so the web app remains usable while keeping cost and latency acceptable.
Accomplishments that we're proud of
End-to-end multi-agent pipeline: From schema and privacy detection to synthetic generation and impact reporting, all agents work together in one run. One command produces PCI-safe synthetic data and an HTML report.
Explainable fraud detection: Every prediction comes with a Reason—a short, human-readable judgment (what stands out, how it relates to fraud/legitimate behavior, conclusion). No black-box score only.
Few-shot data generation that stays in-distribution: Using only prompt + context-learning (no fine-tuning), the LLM generates new rows that align with the provided examples. When the LLM output fails validation, we fall back to statistical generation so the pipeline never dead-ends.
Usable web app: Upload a CSV, get Fraud (0/1), Fraud_Score, and Reason per row. The UI shows the selected filename and displays results in a clear table with reason rows.
What we learned
Context-learning from few examples: Large language models can imitate the structure and statistics of a small dataset when given a concise description of the data and a few labeled rows in the prompt. We use this for both synthetic data generation (LLM outputs new rows that match the seen distribution) and fraud prediction (few-shot examples + domain background → prediction and reason per transaction).
Multi-agent design: Splitting the pipeline into dedicated agents—schema/privacy, generation, impact—keeps each part testable and replaceable. The FinTech Payment Agent enforces PCI-safe outputs; the Privacy Guard strips PII before generation; the synthetic pipeline handles prompt optimization and class-conditional generation; the fraud predictor focuses only on inference and reasons.
Output structure matters: For the LLM to return both a prediction and a reason, we had to constrain the format (e.g. one JSON object per line) and add robust parsing so that occasional malformed lines do not break the whole batch.
What's next for PaymentGuard
Hosted demo: Deploy the web app so judges and users can try it without running the repo locally.
More data sources: Support additional fraud datasets (e.g. different schemas, regions) and make the domain adapter and schema detection more robust.
Stronger evaluation: Add quantitative metrics for synthetic data utility (e.g. downstream classifier performance with vs without synthetic data) and for explanation quality (e.g. human or model-based consistency checks on reasons).
API and integrations: Expose the pipeline and the fraud predictor as APIs so other FinTech tools can plug in synthetic generation and explainable detection.


Log in or sign up for Devpost to join the conversation.