-
-
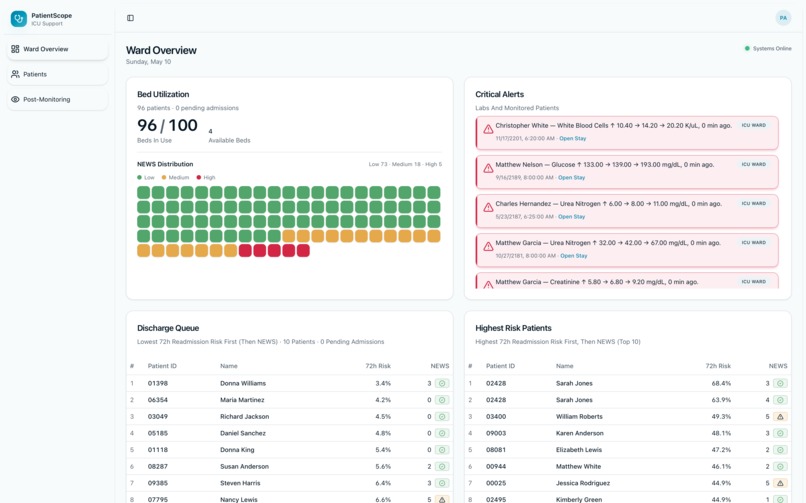
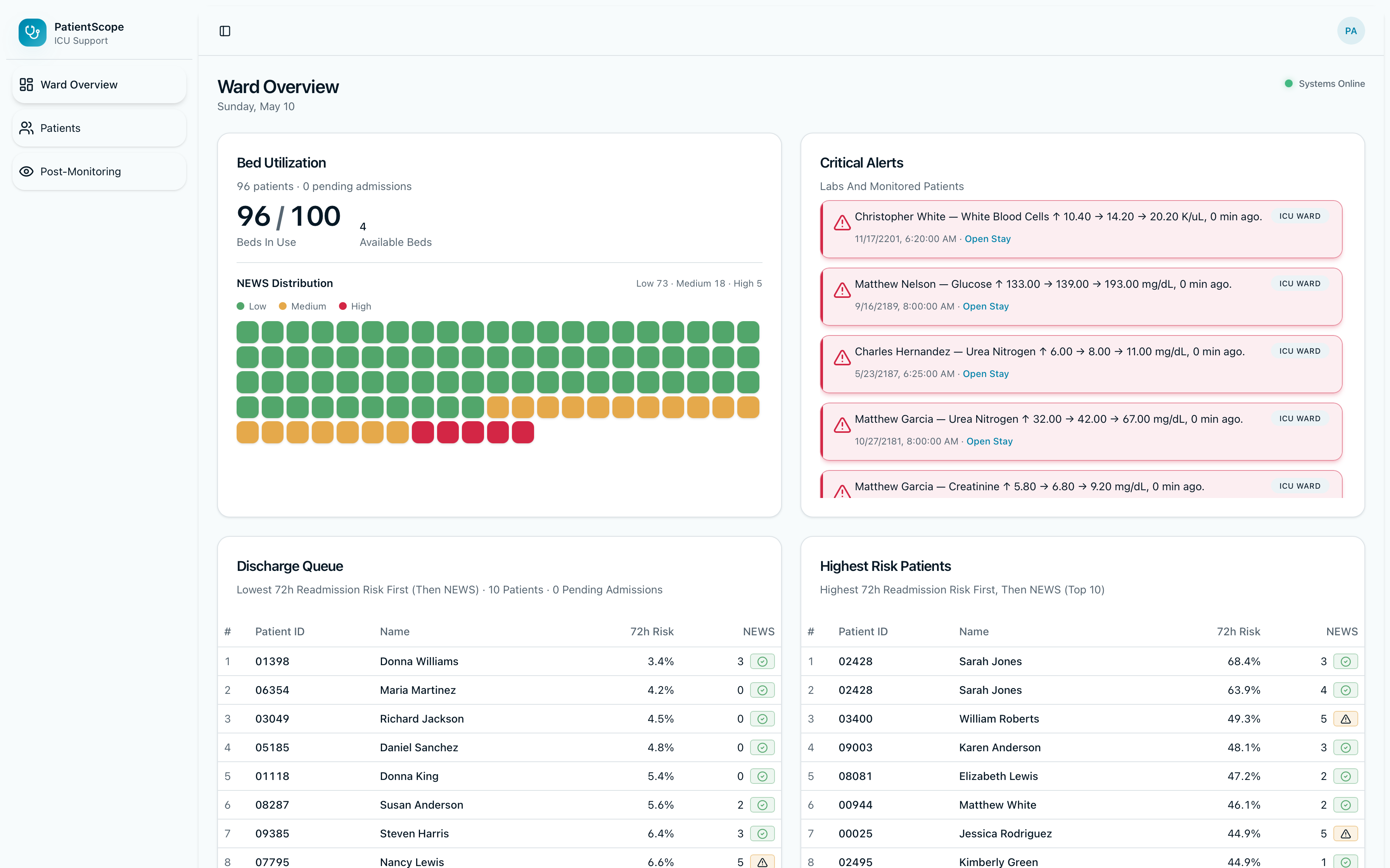
Ward Overview Page
-
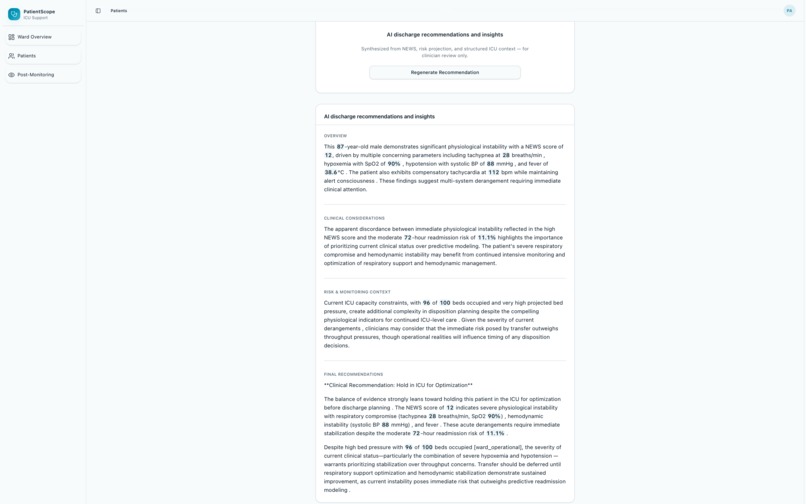
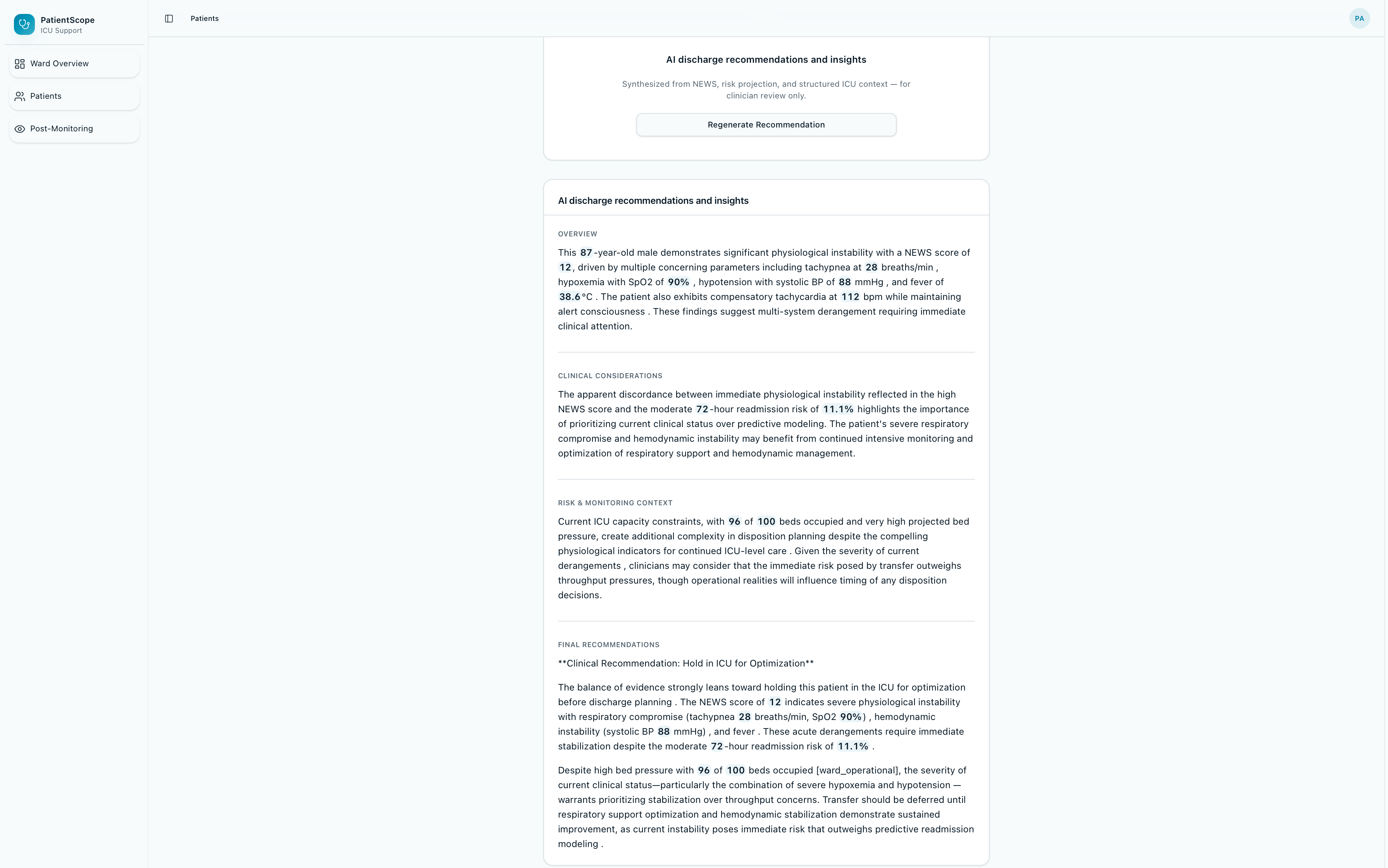
AI Recommendation Feature
-
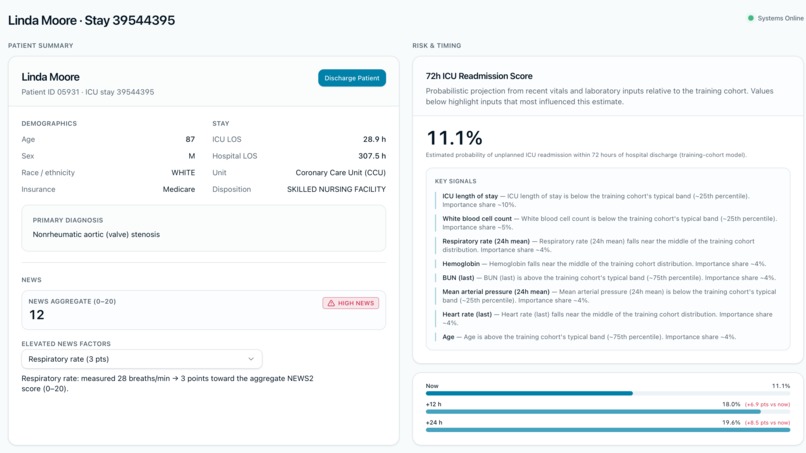
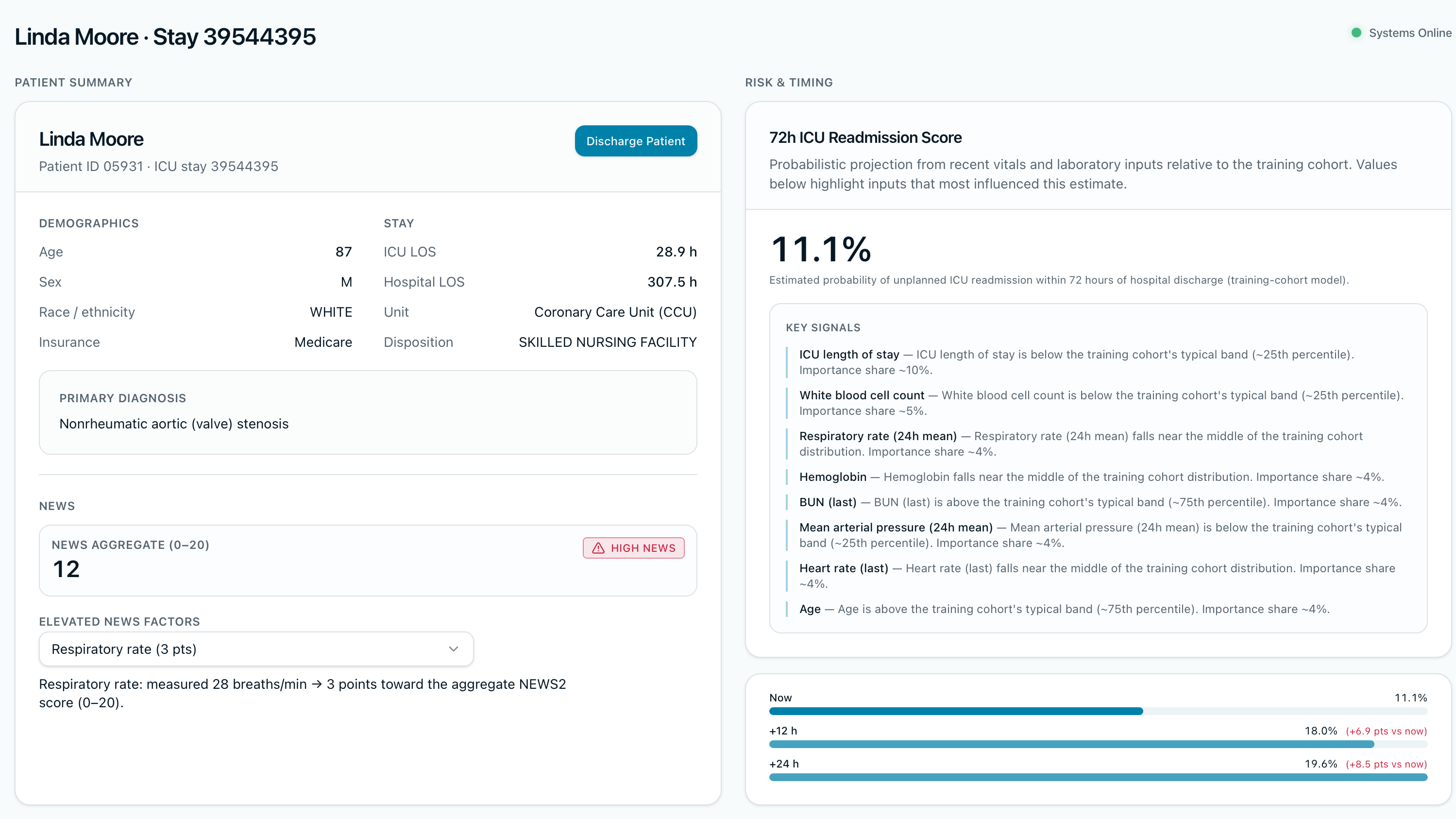
Patient Summary (left) and In-House Risk Prediction Score created from random forest model (right)
-
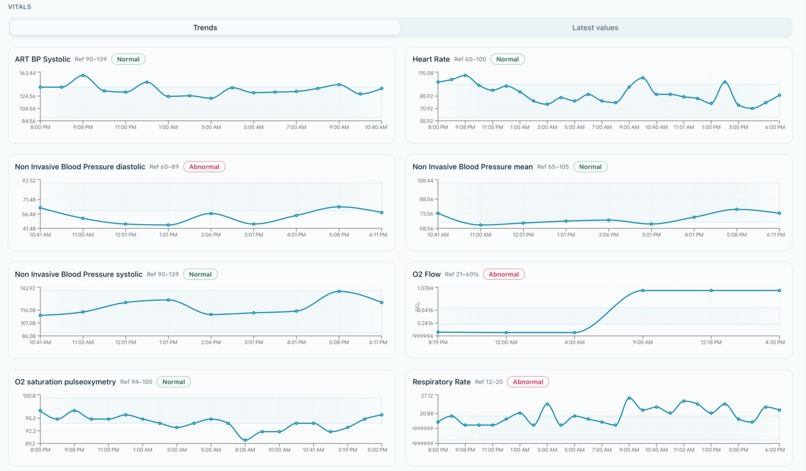
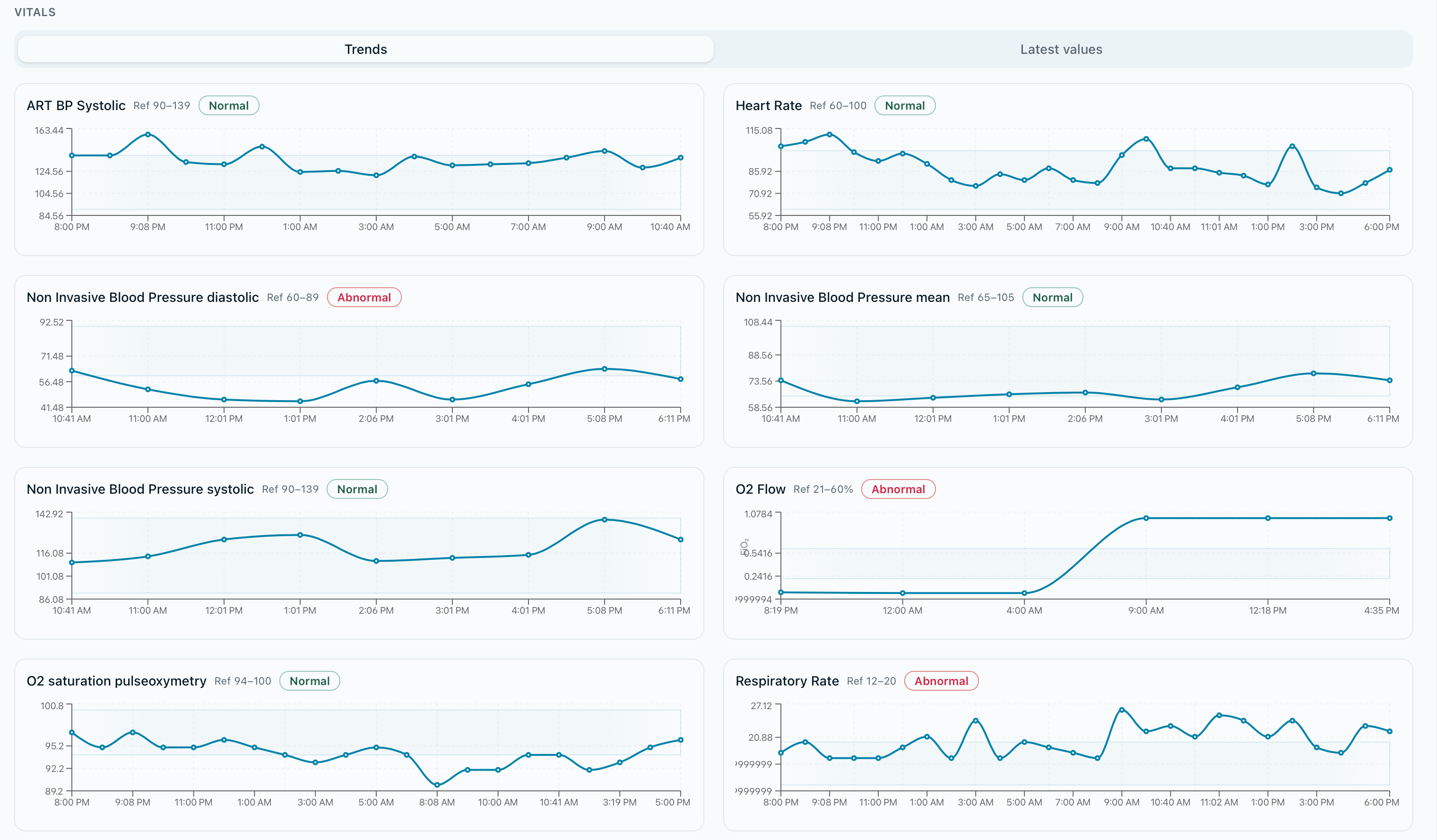
Patient Vitals
-
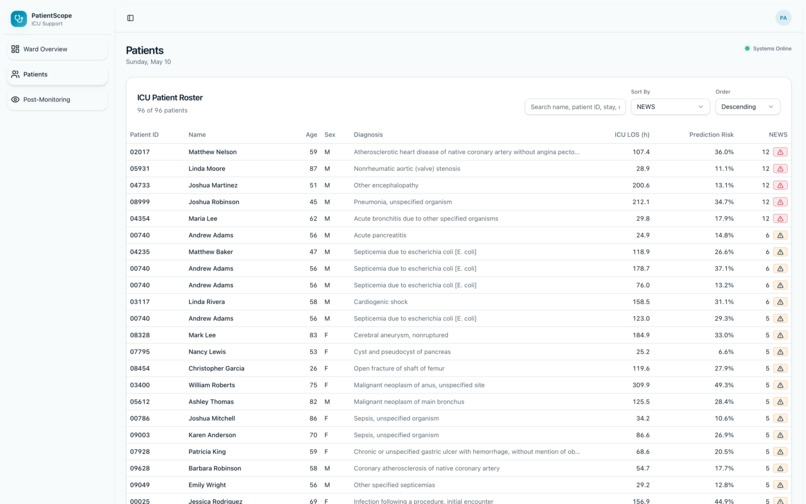
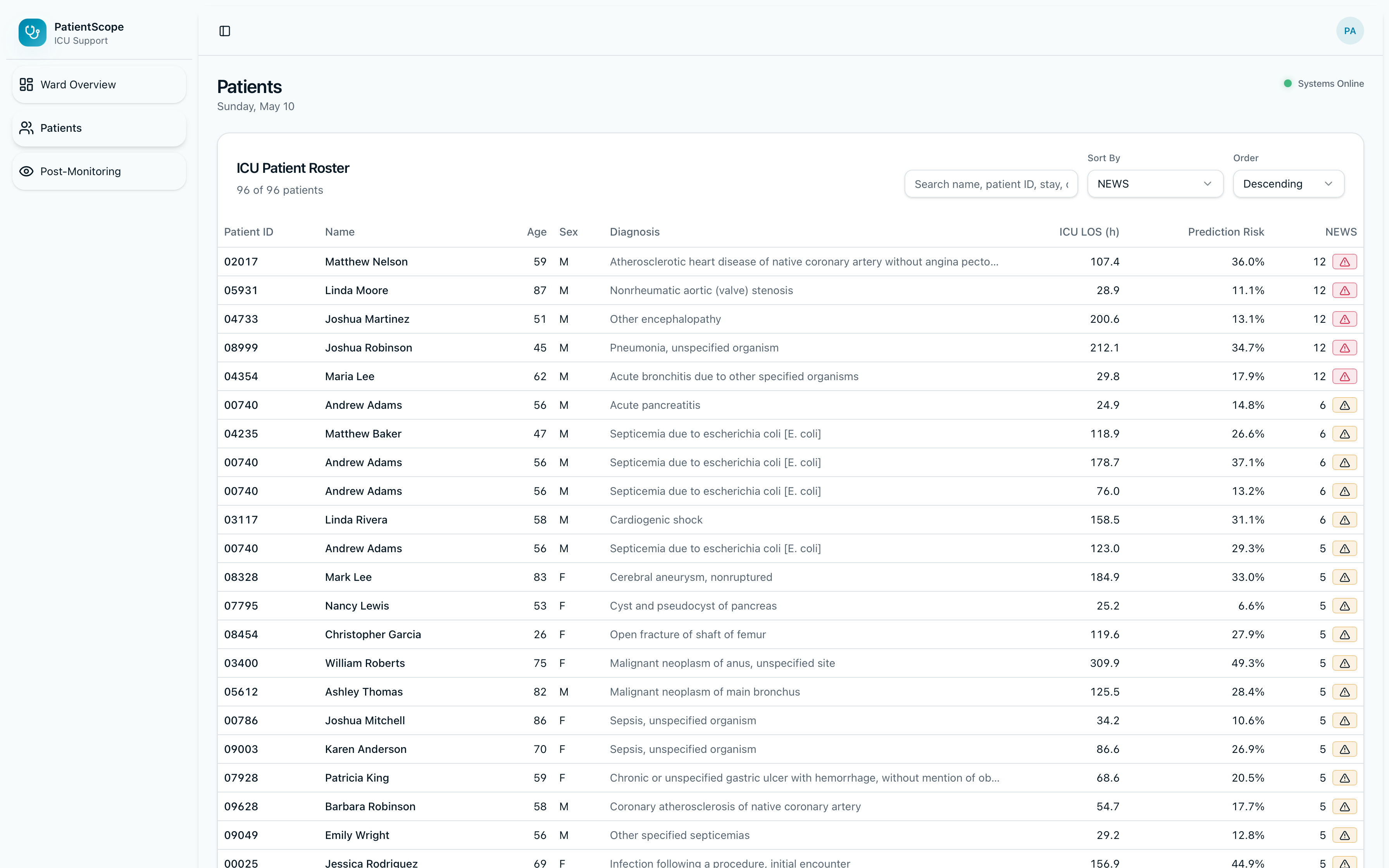
Patient Roster View
PatientScope AI
Inspiration
This project grew out of an AI in Healthcare Applications course at Carnegie Mellon, where I examined the gap between what clinical machine learning promises and what actually reaches the bedside. Around the same time, I began working hands-on with the MIMIC-IV demo dataset — reconstructing ICU cohorts via chained CTEs, reproducing published prediction pipelines, and observing firsthand how messy real critical-care data can be.
The readmission problem was a persistent focus throughout. ICU discharge is one of the highest-stakes transitions in critical care: discharging a patient to the floor too soon can result in readmission within days, often in a worse condition than before. Approximately one in ten ICU patients is readmitted, and a meaningful share of those discharges were premature in retrospect — labs not fully resolved, medication regimens not yet optimized, patients at the margin of stability rather than clearly past it. Clinical teams typically have access to the relevant data; what they often lack is a tool that synthesizes it under the pressures of bed availability and time constraints.
Existing risk tools collapse this decision into a single opaque vendor score — precisely the kind of uninterpretable output the CMU course had taught me to scrutinize. PatientScope AI is the result of those converging threads. The goal was decision support that grounds every claim in cohort definitions and source data, surfaces multiple readmission definitions rather than a single incomparable rate, and gives the discharge team something they can engage with critically — less black-box probability, more clinical reasoning at the bedside.
What It Does
PatientScope is a clinical-style ICU dashboard backed by MIMIC-style ICU stays in PostgreSQL:
- Ward and census views — roster and stay summaries, with API connectivity and database latency surfaced to the UI through a live status endpoint (no silent failures obscured by a green indicator).
- Per-stay assessment — NEWS-style readiness scoring, multi-definition readmission framing (several operational definitions documented explicitly rather than collapsed into a single incomparable rate), and 72-hour readmission risk from a trained scikit-learn Random Forest pipeline served via the API.
- Vitals and trajectories — structured pulls from MIMIC-like schemas powering charts and clinical panels.
- Narrative layer — Anthropic Claude generates clinician-facing narrative text using a tool-use pattern, with optional persistence and audit paths integrated with MongoDB Atlas.
- Methodology transparency — the UI surfaces methodology and known limitations prominently, so reviewers can see what was measured, how it was measured, and where the approach falls short.
How It Was Built
Data and SQL. MIMIC-IV demo was loaded into Postgres using MIT-LCP-style build scripts (create, load, constraints, indexes), with documented cohort and outcome SQL covering ICU baselines, readmission outcomes, and the full feature build. Feature snapshots align to ICU windows for modeling and discharge-timing sensitivity analysis.
Machine learning. A Random Forest with SimpleImputer in a scikit-learn Pipeline, with optional SMOTE / imbalanced-learn support for larger cohorts, hyperparameter search, and stratified splits. Artifacts are serialized as joblib files alongside JSON reports to support reproducibility.
API. A FastAPI application with CORS, dedicated health and status endpoints (API and database ping with live latency reporting), and a clean REST surface. Database access supports either a single DATABASE_URL (with psycopg normalization for postgresql+psycopg://) or discrete environment variables. Modular routers cover stays, ward, patient, risk, news, narrative, vitals, watchlist, and audit.
Frontend. A Vite + React + TypeScript SPA with shadcn/ui and Tailwind, a typed API client, build-time configuration for the production API origin, and a Vite proxy to FastAPI in development. The deployment is configured as a static-only frontend to avoid conflicts with Vercel's reserved serverless conventions.
Operations. The API runs under uvicorn; the production pattern is a reverse proxy (nginx) routing to the local FastAPI port with TLS, hosted separately from the static frontend.
Challenges
- Split hosting. Vercel serves only static assets without a custom backend, and the API origin baked into the frontend must match the actual API origin — mismatches cause the browser to call the wrong host (e.g., an apex-to-www 307 redirect returning HTML in response to a JSON request).
- HTTPS and mixed content. A SPA served over HTTPS requires an HTTPS API; raw
http://IP:portis rejected by the browser. - Postgres configuration on the server. Status endpoints silently reported
database_ok: falsewhenever the connection configuration disagreed with the actual Postgres exposure — local Docker used port 5433 while the VM used 5432, a one-character difference that proved costly in time. - Packaging and platform conventions. Routing the backend around Vercel's reserved serverless conventions required more planning than anticipated.
Accomplishments
- An end-to-end pipeline — SQL to features to scikit-learn model to API to React UI — on realistic ICU schemas, built and integrated independently.
- Explicit cohort and outcome documentation, with multi-definition readmission framing that avoids a single hidden composite score.
- A polished dashboard UI with typed client code and modular FastAPI design.
- Operational honesty: status endpoints and methodology views that surface uncertainty rather than concealing it.
What I Learned
- Environment parity is essential. Local Docker, the deployment VM, and the production connection string must be consistent, or the status endpoint will silently misreport while the API appears functional.
- Frontend environment variables are build-time. Changes require a redeploy — straightforward in principle, easy to overlook under time pressure.
- Platform boundaries are real. Static hosts are well-suited to the UI layer; long-lived FastAPI and Postgres deployments belong on a VM or managed container host, not on a static CDN.
What's Next for PatientScope AI
- Hardening production paths: managed Postgres (or persistent Neon), secrets rotation, tighter CORS configuration, and structured logging.
- Credentialed MIMIC-IV and BigQuery paths for training parity with the larger-cohort workflows the pipeline already supports.
- Stronger validation: calibration plots and notebook-backed audits aligned with the project's scoring methodology.
- Optional infrastructure consolidation: migrating the API to Railway, Render, Fly.io, or Cloud Run to avoid self-managing VMs while preserving the existing FastAPI codebase.
Built With
- claude
- css
- docker
- fastapi
- mongodb
- postgresql
- python
- react
- sql
- tailwind
- typescript
- uvicorn
- vite



Log in or sign up for Devpost to join the conversation.