slide deck at https://patients-like-me-080boq1.gamma.site/
Inspiration
Long COVID is treated as one disease. It isn't.
The same diagnosis is given to someone with racing-heart orthostatic
intolerance (POTS), someone with histamine flares and food reactions
(MCAS), and someone bedbound by post-exertional crashes (ME/CFS).
They get lumped into one bucket, handed the same generic advice, and
told research is "still early." Meanwhile, the people living it have
already run thousands of n-of-1 experiments and written the results
down in patient forums.
We were inspired by a simple observation: the evidence patients need
already exists; it's just trapped in unstructured stories. A
newly-sick person asking "will low-dose naltrexone help me?" has to
read 400 Reddit threads to guess. We wanted to turn that lived
experience into something you can actually query: what happened to
patients like me?
What it does
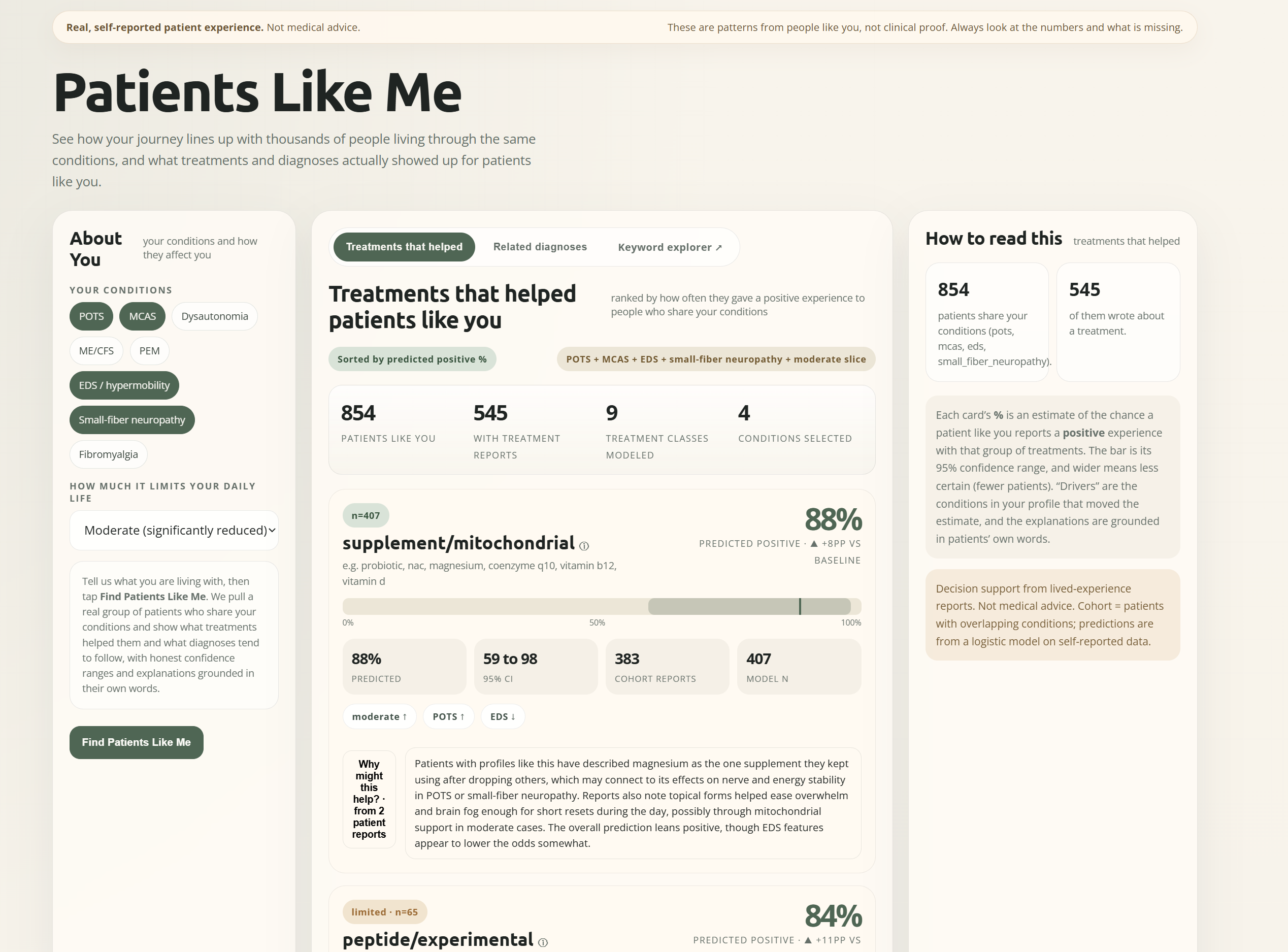
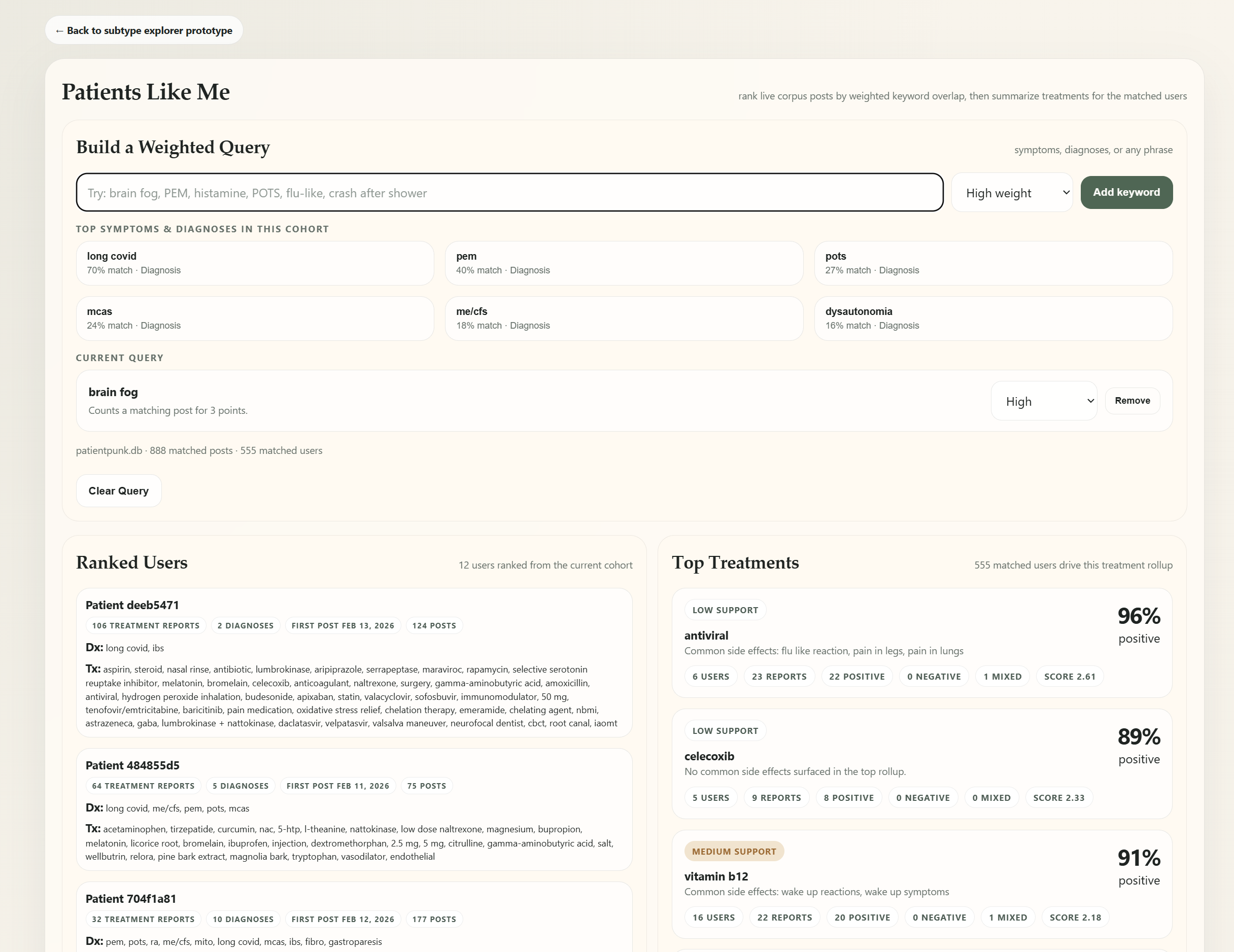
You tell Patients Like Me about yourself — your conditions (POTS, MCAS, ME/CFS, PEM, EDS, dysautonomia, small-fiber neuropathy, fibromyalgia) and your functional status — and it pulls a real cohort of patients who share your phenotype, then answers three questions:
- Treatments: which drug classes actually gave people like you a
positive experience, ranked, each with a 95% confidence interval and
a real-time, profile-specific explanation grounded in the actual
patient quotes (not generic mechanism text).
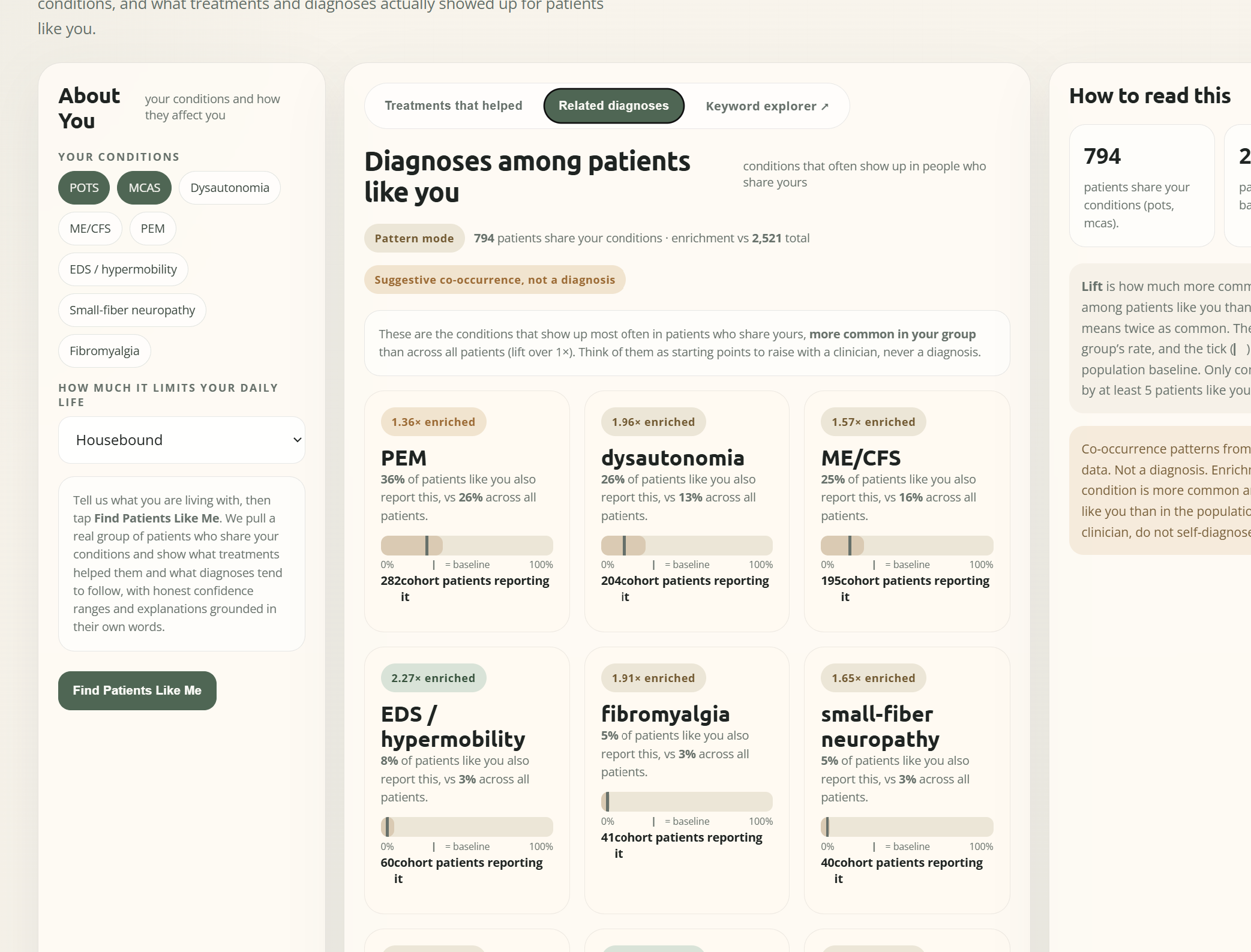
- Diagnoses: which other conditions are enriched in your cohort —
co-occurrence patterns that are prompts to raise with a clinician,
never a diagnosis.
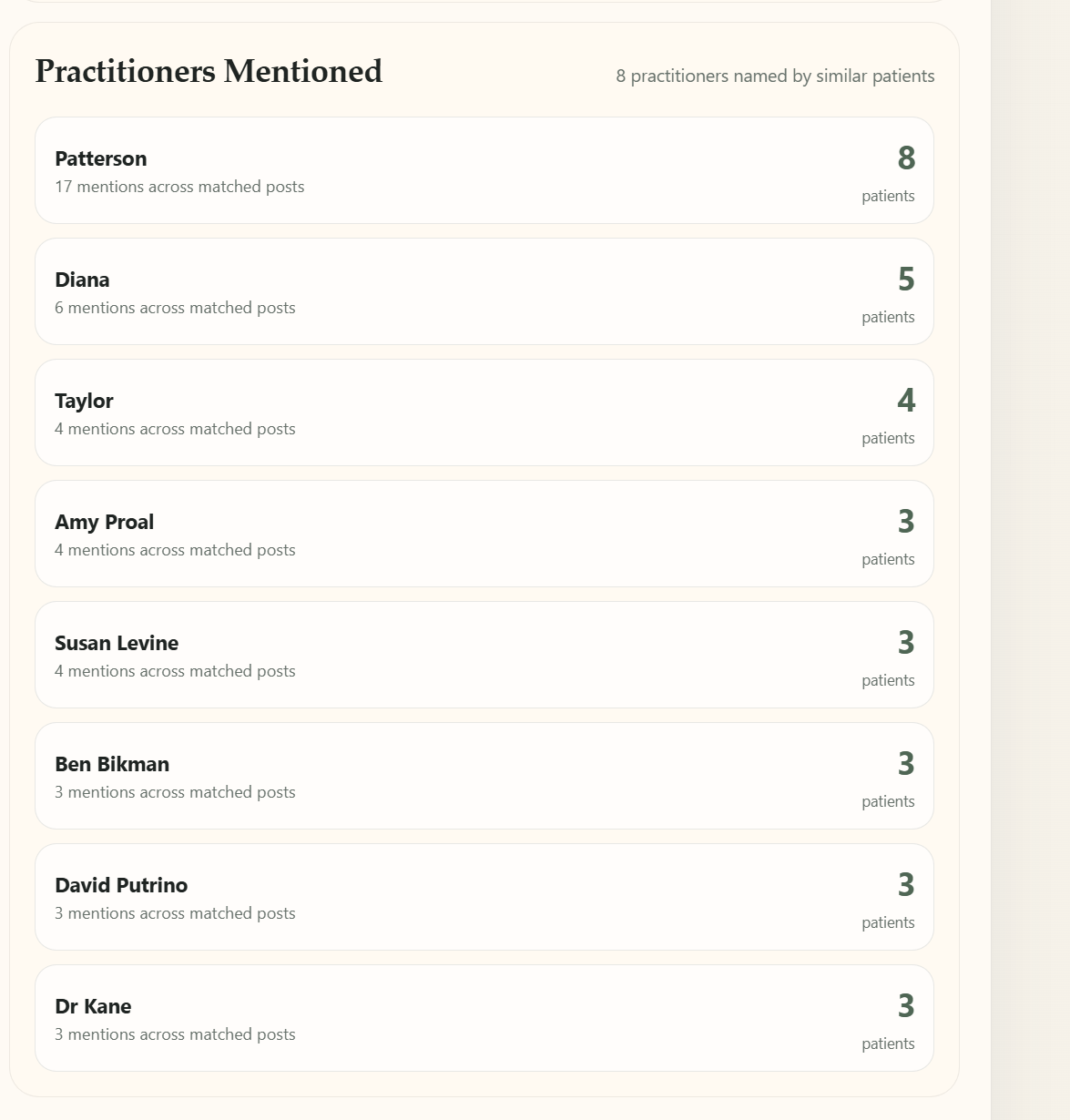
- Doctors: which clinicians and researchers patients like you
actually mention.
Every number is backed by real reports, real denominators, and a
visible "what's missing." It is decision support from lived
experience, explicitly not medical advice.
How we built it
A pipeline from raw forum text to calibrated, queryable evidence:
1. Extraction. ~35k posts from ~4,300 patients, run through an LLM +
spaCy NER to pull structured conditions, treatment_reports (with
sentiment), and practitioner mentions into a SQLite corpus.
2. Phenotype matrix. We multi-hot encoded ~95 fields into a patient ×
feature matrix and asked the obvious question: are there clean
subtypes?
3. Per-drug-class outcome models. For each treatment class we fit a
logistic model on corrected, self-reported outcomes:
$$
\text{logit} = \mathbf{x}^\top \boldsymbol\beta, \qquad p =
\sigma(\mathbf{x}^\top\boldsymbol\beta) =
\frac{1}{1+e^{-\mathbf{x}^\top\boldsymbol\beta}}
$$
with confidence intervals via the delta method on the coefficient
covariance $\Sigma$:
$$
\text{CI}_{95%} = \sigma!\left(\mathbf{x}^\top\boldsymbol\beta \pm
1.96\sqrt{\mathbf{x}^\top \Sigma, \mathbf{x}}\right)
$$
4. Comorbidity enrichment. For the "diagnoses" view we rank
co-conditions by lift:
$$
\text{lift}(c) = \frac{P(c \mid \text{cohort})}{P(c \mid
\text{population})}
$$
5. Serving + explanations. A FastAPI backend
(/api/treatment-evidence, /api/comorbidity, /api/explain) and a
"Patients Like Me" frontend. Explanations are generated by an LLM
(xAI Grok / OpenRouter) grounded in the retrieved cohort quotes, with
a deterministic fallback when no key is set.
Challenges we ran into
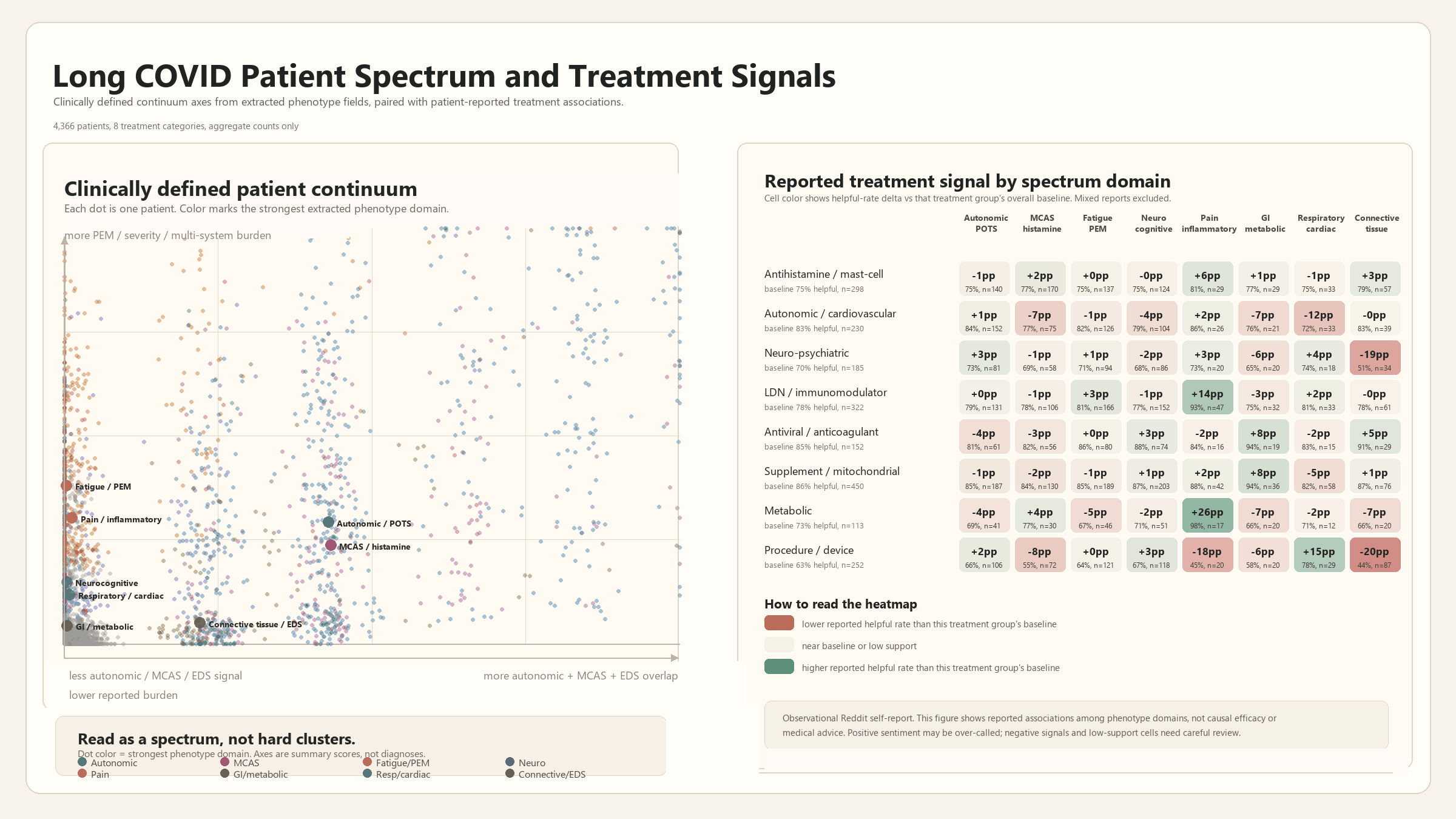
- There were no clean clusters. We expected to find 3–4 crisp Long
COVID subtypes. Instead the data is a continuum — conditions overlap,
patients sit on a spectrum. So we pivoted from hard clustering to
$k$-NN similarity ("patients like you") and per-axis modeling, which
is the honest representation.
- The verbosity confound. Presence-encoding meant a 0 could mean
"doesn't have it" or "didn't mention it." Patients who wrote more
looked similar to each other regardless of phenotype — PC1 correlated
with fields-filled at $r \approx +0.95$. We fixed it with IDF
weighting and $L_2$/cosine normalization, collapsing the confound to
$r \approx +0.02$ while preserving real clinical signal.
- The LLM mislabeled sentiment. Our first sentiment pass over-called
positive (~20–25% false positives, asymmetric — negatives were
reliable), inflating how well everything "worked." We diagnosed it
with a manual audit, rewrote the prompt (attribution required, added
a no-effect class), and re-ran — then rebuilt all downstream models
on the corrected labels.
- Keeping patient data controlled while still shipping a demo: DBs
live in controlled storage, pulled at runtime, never committed to the
public repo.
Accomplishments that we're proud of
- A working, end-to-end product that turns messy forum text into
calibrated, uncertainty-aware treatment predictions — confidence
intervals, not false precision.
- Honesty as a feature: we measured and corrected our own confounds
(verbosity, sentiment) instead of shipping a prettier-but-wrong
number.
- Quote-grounded explanations — the "why might this help?" text
paraphrases what real patients actually reported, good and bad,
rather than hallucinating a mechanism.
- Reframing the whole experience around "patients like me," so a sick
person sees their own journey reflected back, not a dashboard.
What we learned
Distrabution seems to be less in extreme clusters and more along a spectrum. We went into this expecting to use kNN and being able to make some sort of clear treatment tree: we found that normal assumptions and regression were much more explanatory.
What's next for Patients like me
We need to incorporate much larger datasets, and make sure that our analysis holds.
Built With
- fastapi
- python

Log in or sign up for Devpost to join the conversation.