-
-
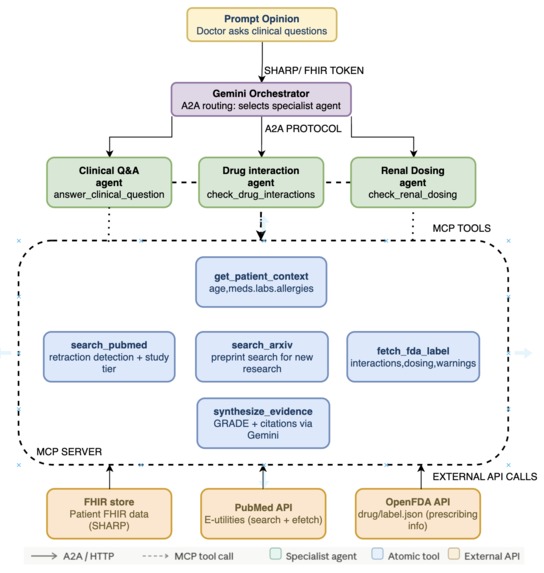
workflow diagram
-
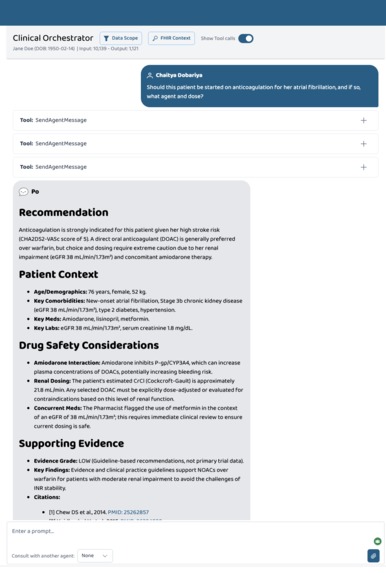
Sample A2A agent calls
-

MCP call testing
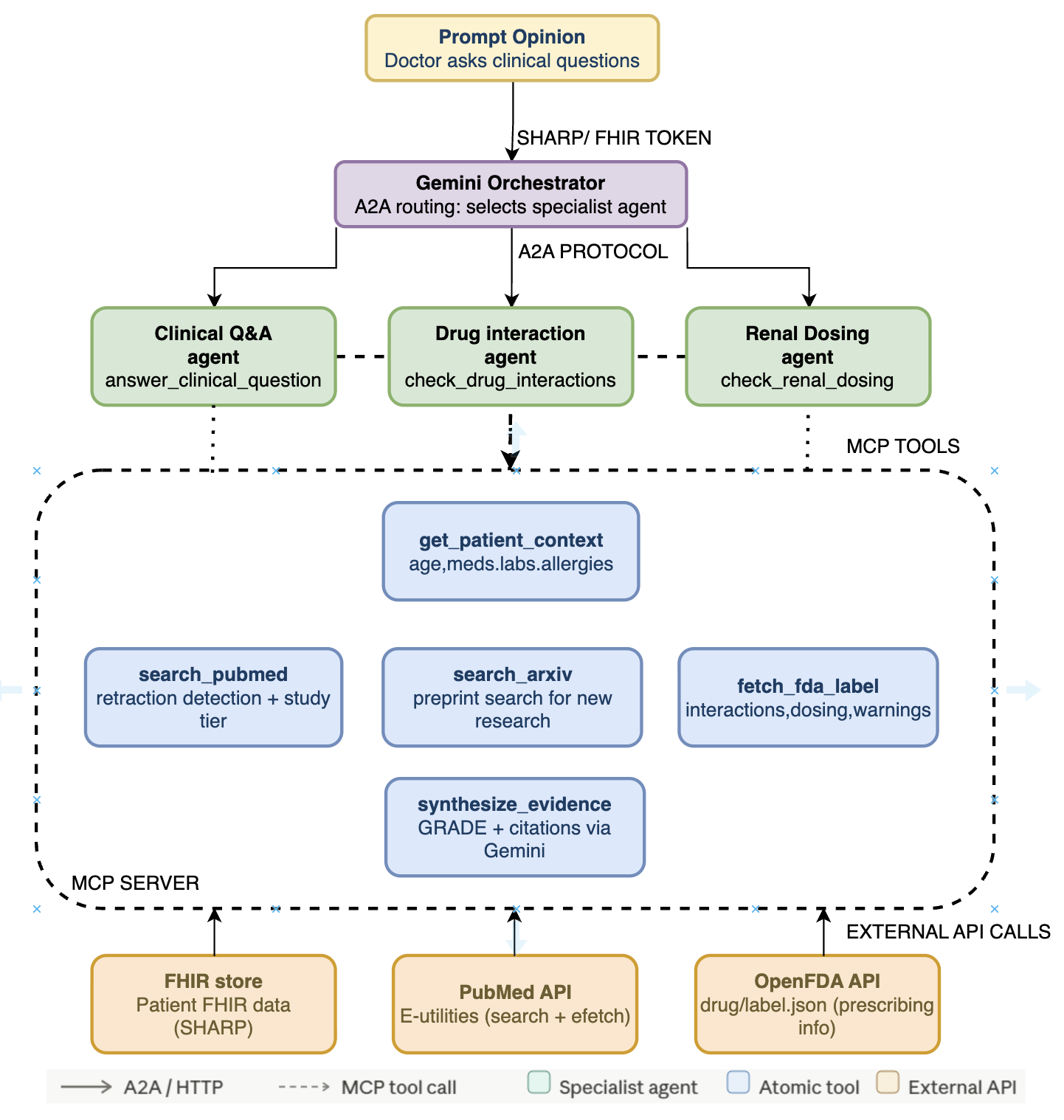
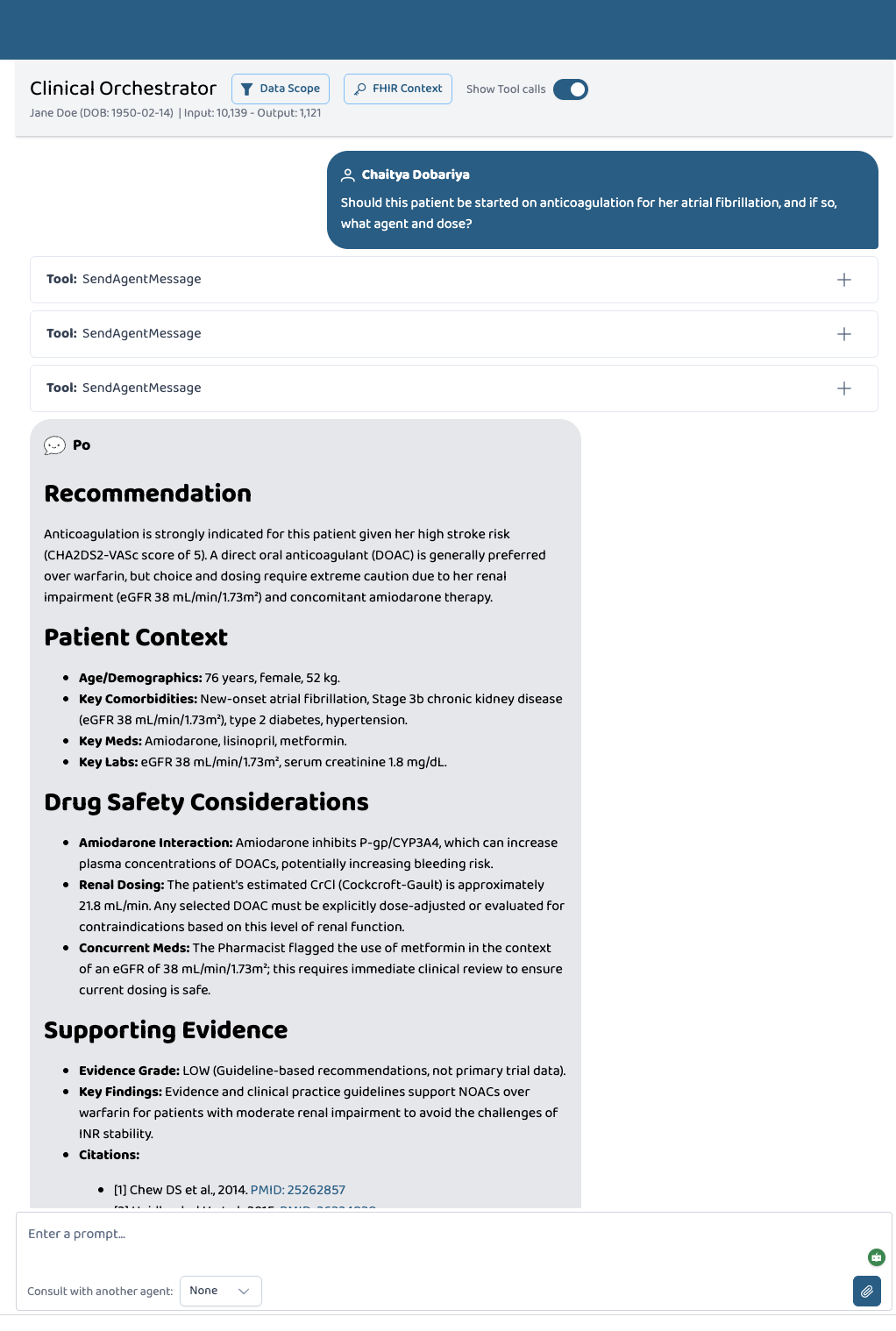

Inspiration
Doctors waste hours searching PubMed and second-guessing whether a guideline applies to their specific patient. A 76-year-old woman with CKD, AFib, and Amiodarone isn't the average trial participant; generic AI answers miss the nuance that matters clinically. We wanted to build a tool that answers "should this patient start anticoagulation?" rather than just "how is AFib treated?"
What it does
Patient-Aware Clinical Evidence is an MCP server that plugs into Prompt Opinion and answers clinical questions with three layers of intelligence:
- Patient context—Reads the active patient's FHIR record (demographics, conditions, medications, labs, and allergies) via the SHARP platform.
- Real evidence—Reformulates the question as a PICO query and fetches up to 8 peer-reviewed PubMed articles.
- Patient-specific synthesis—Gemini reads both the research and the patient's profile together and produces a cited, graded recommendation tailored to that individual.
It also supports:
- Drug interaction checking — Bidirectional FDA label DDI analysis for any proposed medication against the patient's current drug list.
- Renal dose review—Cockcroft-Gault CrCl calculation + FDA label renal dosing review for every patient medication.
How we built it
- FastMCP (Python) as the MCP server framework, with
POFastMCPhandling FHIR SMART launch context from Prompt Opinion headers (x-fhir-server-url,x-fhir-access-token,x-patient-id). - FHIR R4 resources via
fhir.resourcesandhttpx— Patient, Condition, MedicationStatement, Observation, AllergyIntolerance. - PubMed E-utilities API for free, real-time literature search.
- OpenFDA drug label API for FDA prescribing information (drug interactions, renal dosing sections).
- Google Gemini (
gemini-3.1-flash-lite-preview) for PICO query generation, evidence synthesis, DDI extraction, and renal dose interpretation. - A synthetic FHIR patient bundle (Jane Doe — clinically complex) for demo use when live FHIR context isn't available.
Challenges we ran into
- FHIR context threading—MCP tools are stateless HTTP handlers; passing FHIR credentials through request headers cleanly without leaking them across tool calls required careful scoping.
- Prompt engineering for clinical accuracy—Gemini needs precise instructions to cite PMIDs correctly, grade evidence honestly, and flag patient-specific deviations without hallucinating interactions.
- FDA label parsing—OpenFDA returns raw label text; extracting structured DDI and renal dosing information reliably required a dedicated Gemini extraction pass.
- Demo patient design — Jane Doe needed to be clinically complex enough that the answers actually differ from generic AI, while remaining realistic and synthetic (no real patient data).
Accomplishments that we're proud of
- A single
answer_clinical_questiontool call does FHIR fetch → PICO reformulation → PubMed search → patient-aware synthesis end-to-end. - Evidence is graded (HIGH / MODERATE / LOW / INSUFFICIENT), and every claim is tied to a real PMID.
- The drug interaction checker runs bidirectional FDA label lookups—checking both the proposed drug's label for mentions of current meds and each current med's label for mentions of the proposed drug.
- The renal dosing tool automatically computes Cockcroft-Gault CrCl from the patient's age, sex, weight, and creatinine, then maps it against each drug's FDA label.
What we learned
- SMART on FHIR context injection via HTTP headers is surprisingly clean once you have the right wrapper—the
POFastMCPpattern is reusable for any clinical MCP tool. - Gemini Flash Lite is fast and cheap enough to use for multiple LLM passes per tool call (query reformulation + synthesis) without making latency unacceptable.
- PubMed's E-utilities API is free, reliable, and underused in clinical AI applications.
What's next for Patient-Aware Clinical Evidence
- Expand FHIR scopes to include Procedure, Encounter, and DocumentReference for richer patient context.
- Add arXiv preprint search alongside PubMed for cutting-edge research.
- Cache PubMed results to avoid redundant API calls for the same query within a session.
- Support multi-patient comparison for population-level queries.
Built With
- europe-pubmed-central
- fastmcp
- fhir
- gemini
- httpx
- openfda
- pydantic
- python
- uv

Log in or sign up for Devpost to join the conversation.