-
-
Path-level reachability triage, powered by GitLab Orbit
-
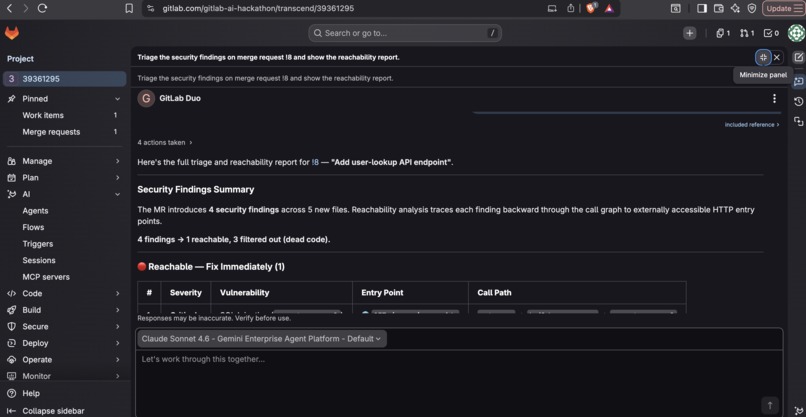
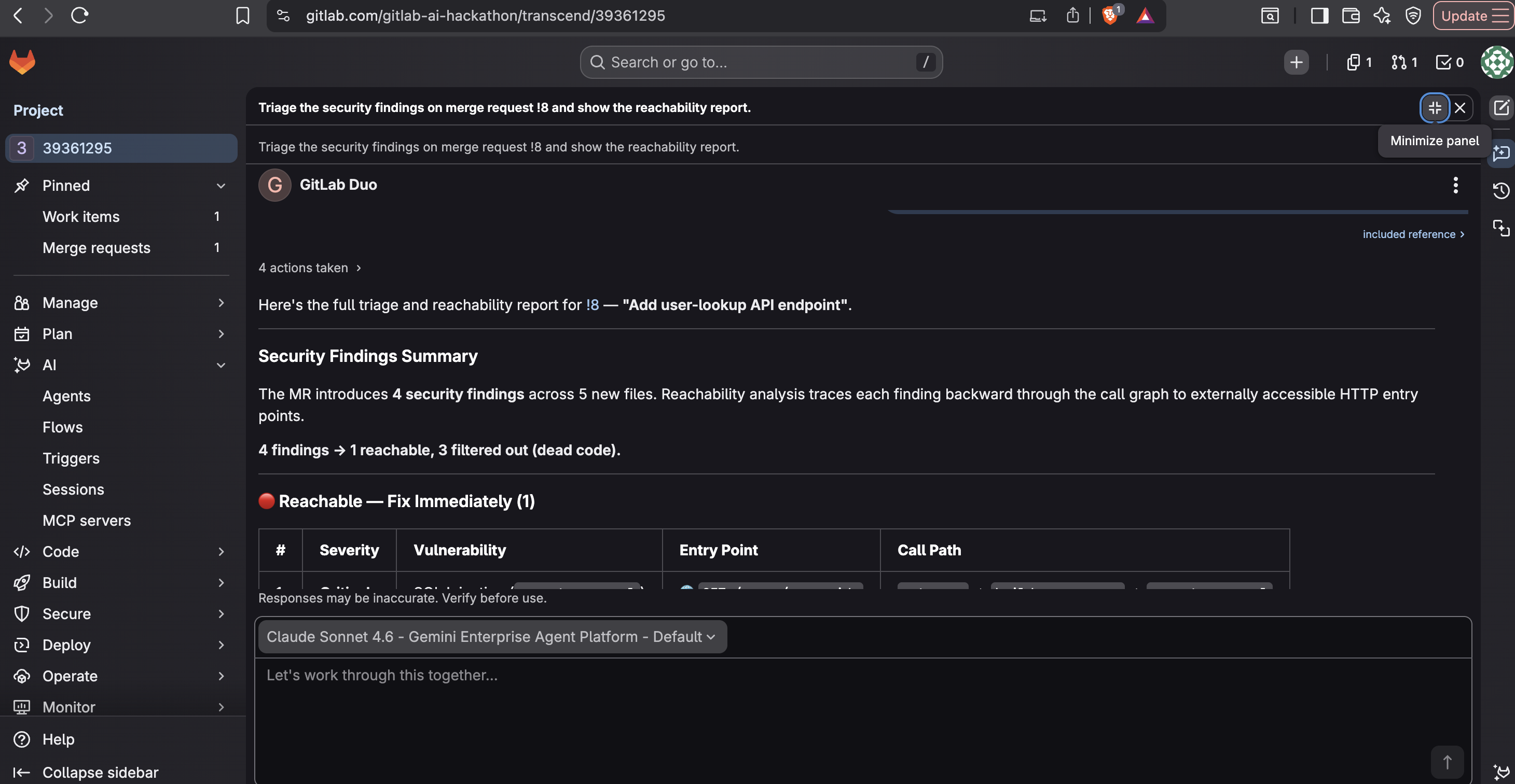
Live as a GitLab Duo agent, triaging a real MR via Orbit
-
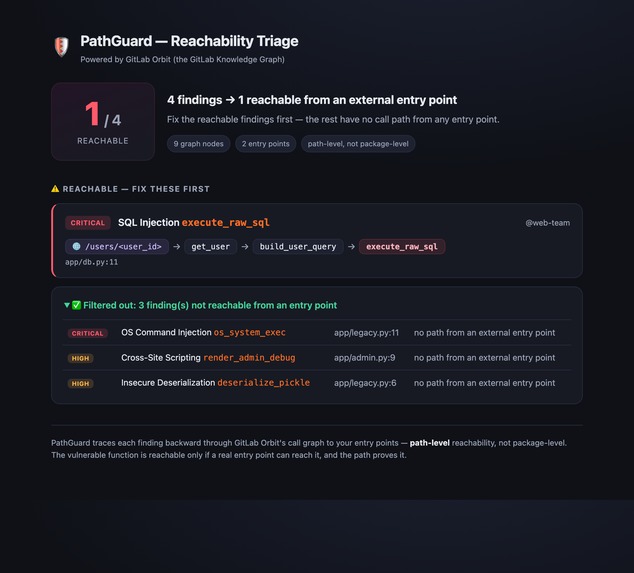
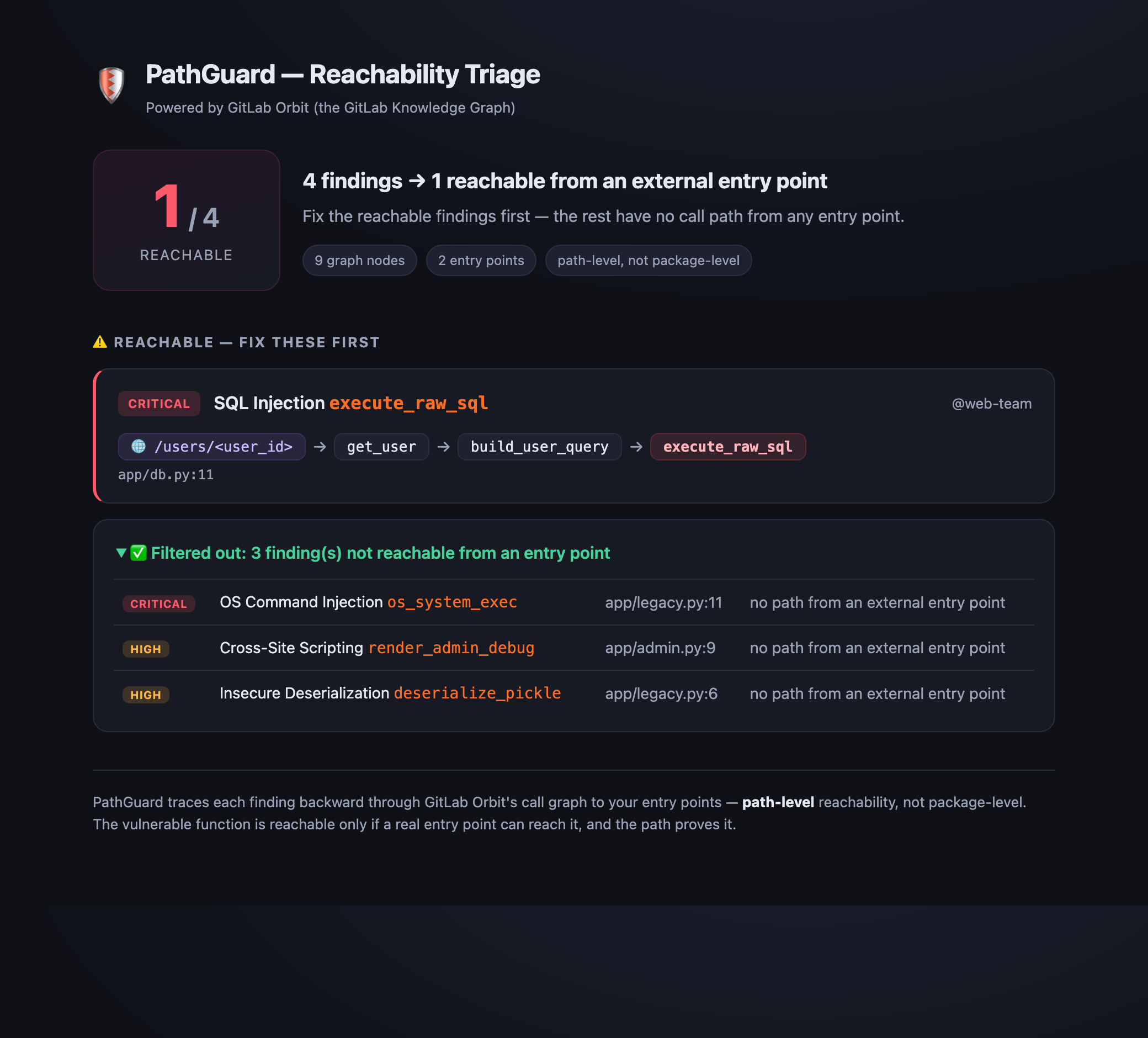
4 findings → 1 actually reachable, with the path
-
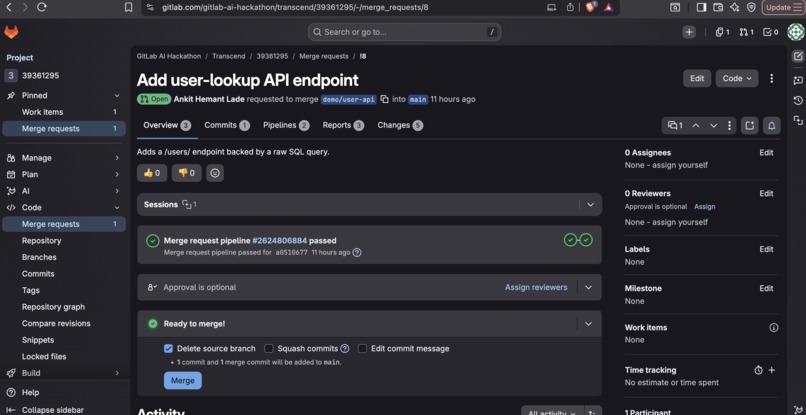
The vulnerable merge request PathGuard triaged
-
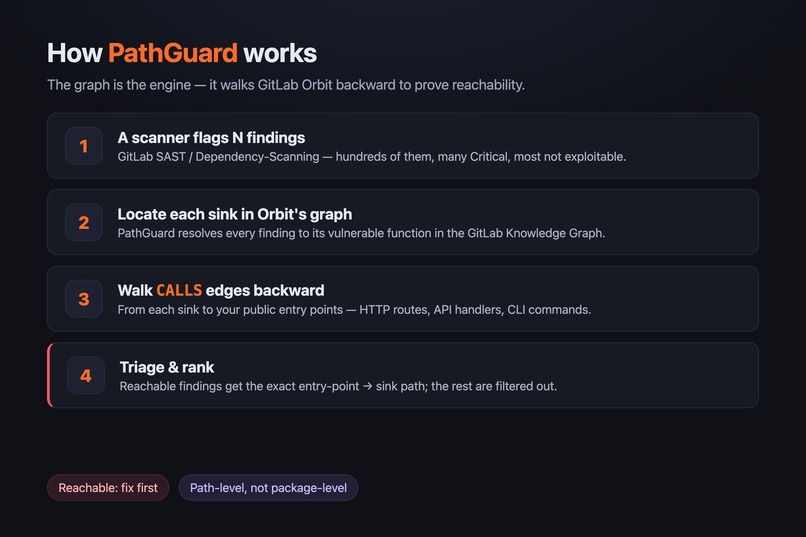
Trace each finding backward through Orbit's call graph

Inspiration
Every security scan ends the same way: a wall of findings — often hundreds, many of them "Critical" — and no reliable way to know which ones actually matter. So teams either fix everything (slow) or triage by CVSS score (misses the point).
GitLab already ships reachability analysis, but it stops at the package boundary: it tells you a vulnerable dependency is imported, and when a direct dependency is marked "in use," every transitive dependency under it inherits that label. You never see the actual call path.
But the one signal that separates exploitable from theoretical — the path from a public entry point to the vulnerable function — is exactly what a code graph can compute and a scanner cannot. When GitLab Orbit (the Knowledge Graph) put a real call graph one query away, the missing piece was there. PathGuard fills the gap: not package-level, but function-level, path-level reachability.
What it does
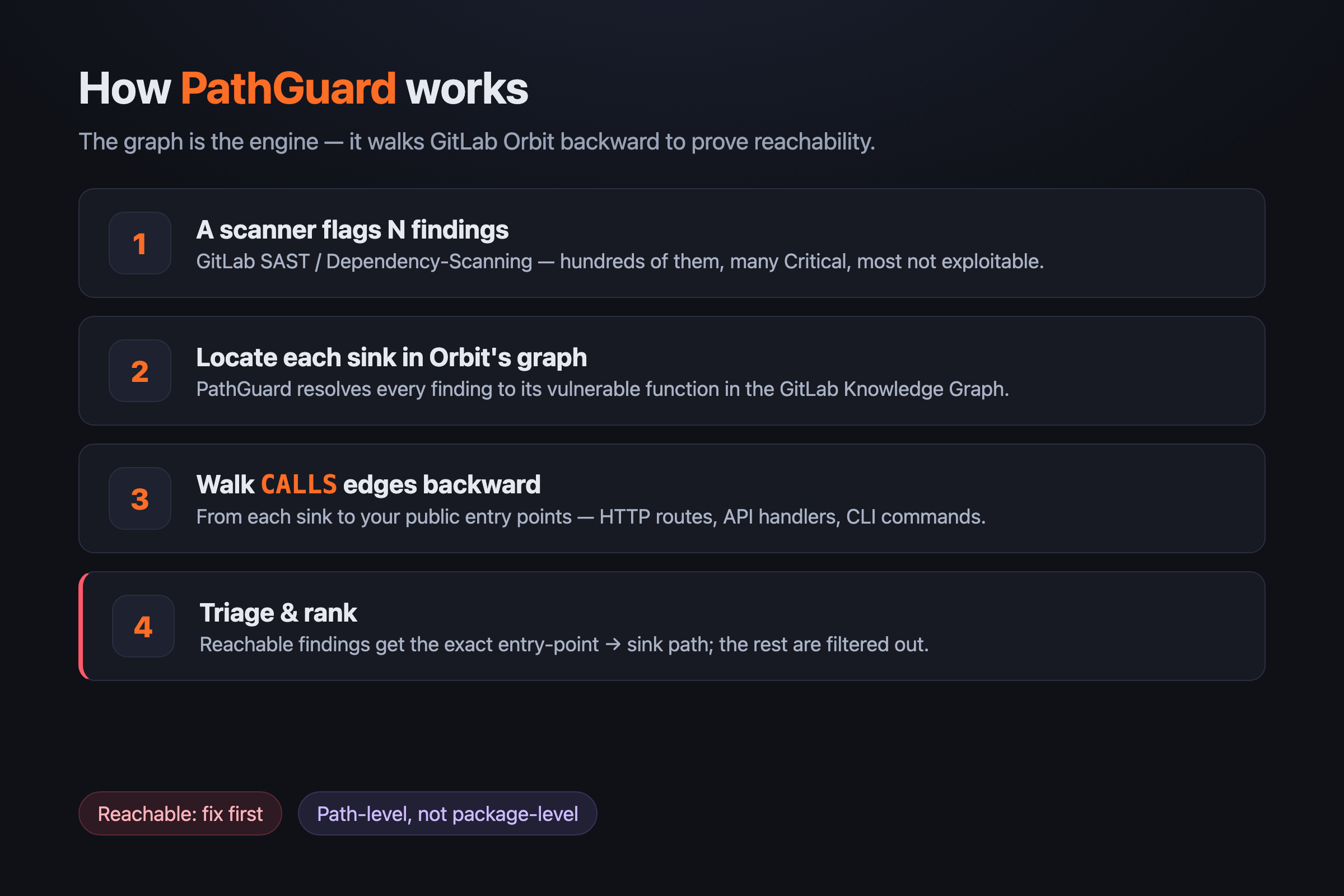
For every security finding on a merge request, PathGuard:
- Locates the vulnerable function inside GitLab Orbit's call graph.
- Walks the
CALLSedges backward from that sink to see whether any public entry point — an HTTP route, an API handler, a CLI command — can actually reach it. - Emits the exact
entry-point → … → sinkpath when one exists, ranked by exploitability. - Posts a single, ranked note on the merge request — a wall of hundreds re-ranked down to the handful that are genuinely reachable from outside, each with its path and owner.
In the bundled demo, a scanner reports four findings — two of them Critical. PathGuard shows
that only one is actually reachable from the internet (a SQL injection via
GET /users/<id> → get_user → build_user_query → execute_raw_sql). The other Critical — a command
injection — sits in dead code and is filtered out. Severity alone would tell you to fix both;
reachability tells you which one can actually hurt someone today.
It ships two ways: a CLI (pathguard demo / pathguard triage) and a published GitLab AI
Catalog flow + skill any team can enable to run on every merge request.
How we built it
- A dependency-free Python engine (standard library only): a normalized code-graph model, the entry-point model, a backward breadth-first reachability search, a GitLab SAST/SBOM findings loader, exploitability ranking, a Markdown report renderer, and an MR poster.
- GraphSource adapters behind one interface — Orbit Local (DuckDB), Orbit Remote, and a JSON fixture — so the engine never depends on a backend and the demo runs with zero setup.
- An entry-point model, because Orbit has
Definitionnodes andCALLSedges but does not label routes/handlers/CLI commands. PathGuard supplies that (Flask, FastAPI, Spring, NestJS, Django REST, and conventionalroutes/controllers/views/urlsmodules). - A GitLab Duo flow and a skill published to the AI Catalog, plus a CI job that runs the triage on merge requests.
- Verified end-to-end against real Orbit Local 0.78.0: index a repository, read the live DuckDB graph, and reproduce the exact result — packaged as a one-command script.
- 56 tests (including a real DuckDB round-trip), ruff-clean, with CI.
Challenges we ran into
- The platform's docs were thin in two specific places — the exact Orbit Local DuckDB schema and the Duo custom-flow YAML schema. I isolated each behind a single module so every gap was a one-file fix, never a redesign.
- Orbit stores structure, not source text. My first decorator-detection approach read source
from the graph — which doesn't exist on a real index. I fixed it by reading the indexed files from
disk (the repo path comes from Orbit's manifest) and adding a file-stem heuristic so
routes.py/views.pyhandlers are caught even without decorators. - The real schema differed from my first guesses (
file_path, notprimary_file_path;relationship_kind, nottype). Indexing the demo app with real Orbit 0.78.0 and reading the live schema turned guesses into facts. - Publishing to the AI Catalog surfaced undocumented requirements —
prompt_templatemust be asystem/userdictionary and the flow block needsentry_point— which I resolved iteratively against the validator until it shipped as v1.0.0.
Accomplishments that we're proud of
- The path-level vs package-level distinction is real and lands in 30 seconds — and it fills a genuine gap between what SRA gives you and what a developer actually needs.
- Verified on a real Orbit Local index, not mocked —
pathguard triage --graph orbit-localreproduces the demo on a graph Orbit built itself. - Published to the GitLab AI Catalog as both a flow and a skill.
- A deterministic safety engine — every verdict is a transparent function of the graph; there is no LLM in the reachability path.
- Dependency-free core, 56 tests, ruff clean — it reads as a product, not a prototype.
What we learned
- Orbit's graph is a genuinely powerful substrate. The valuable work isn't querying it — it's the thin layer on top (entry points + backward reachability) that turns "definitions and edges" into "is this exploitable?"
- "Routes aren't modeled in the graph" sounded like a blocker and became the differentiator — defining what counts as an entry point is the product's core IP, exactly the part a package-level tool can't replicate.
- Building against a real index early, instead of trusting docs, is what made it correct.
What's next for PathGuard
- Rank by exploitability signals — prioritize entry points fed by untrusted input, deepened with lightweight taint.
- Pull SDLC signals from Orbit Remote to confirm a reachable path actually ships to production.
- One-click handoff into GitLab's existing vulnerability-resolution flow to open a fix MR.
- CODEOWNERS-based ownership, line-pinned inline diff comments, and broader language/framework entry-point coverage.
Built With
- ai-catalog
- duckdb
- gitlab
- gitlab-duo-agent-platform
- gitlab-knowledge-graph
- gitlab-orbit
- gitlab-sast
- hatchling
- pytest
- python
- ruff


Log in or sign up for Devpost to join the conversation.