-
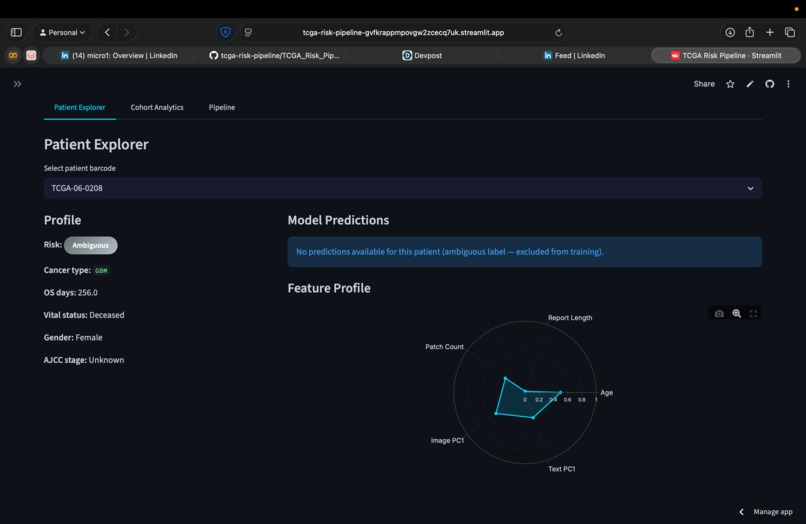
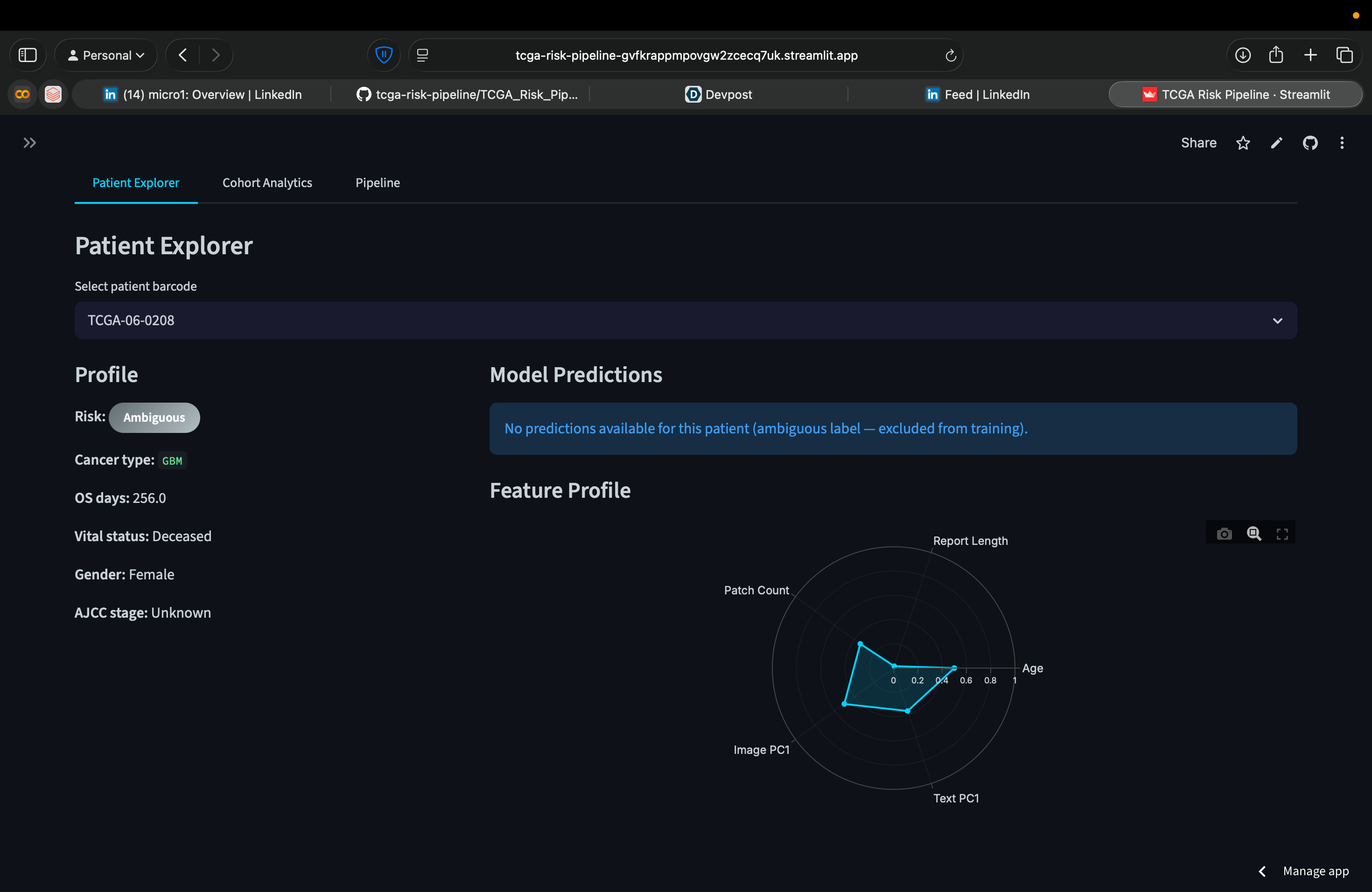
Data Graph for each patient
-
-
Landing Page
Inspiration
Cancer patients generate tissue slides, pathology reports, and clinical records. These live in separate systems and get looked at separately. Nobody combines all three into one risk prediction. TCGA has 11,000+ patients with all three modalities publicly available. We wanted to build the system that fuses them.
What it does
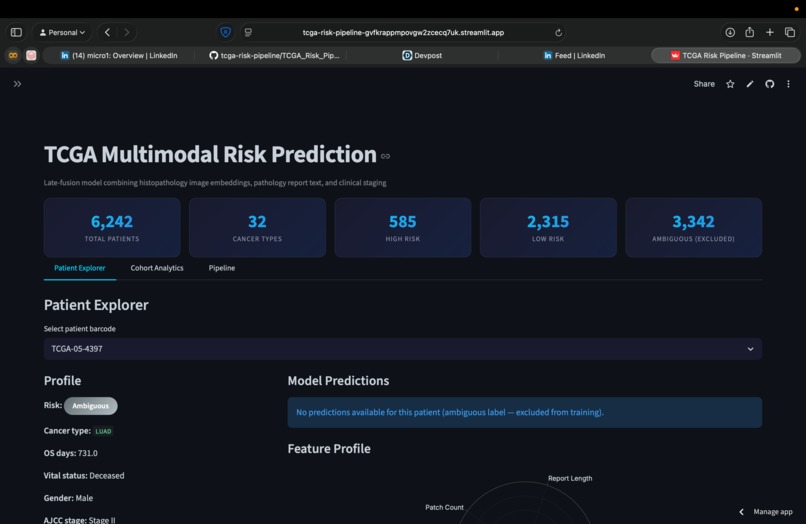
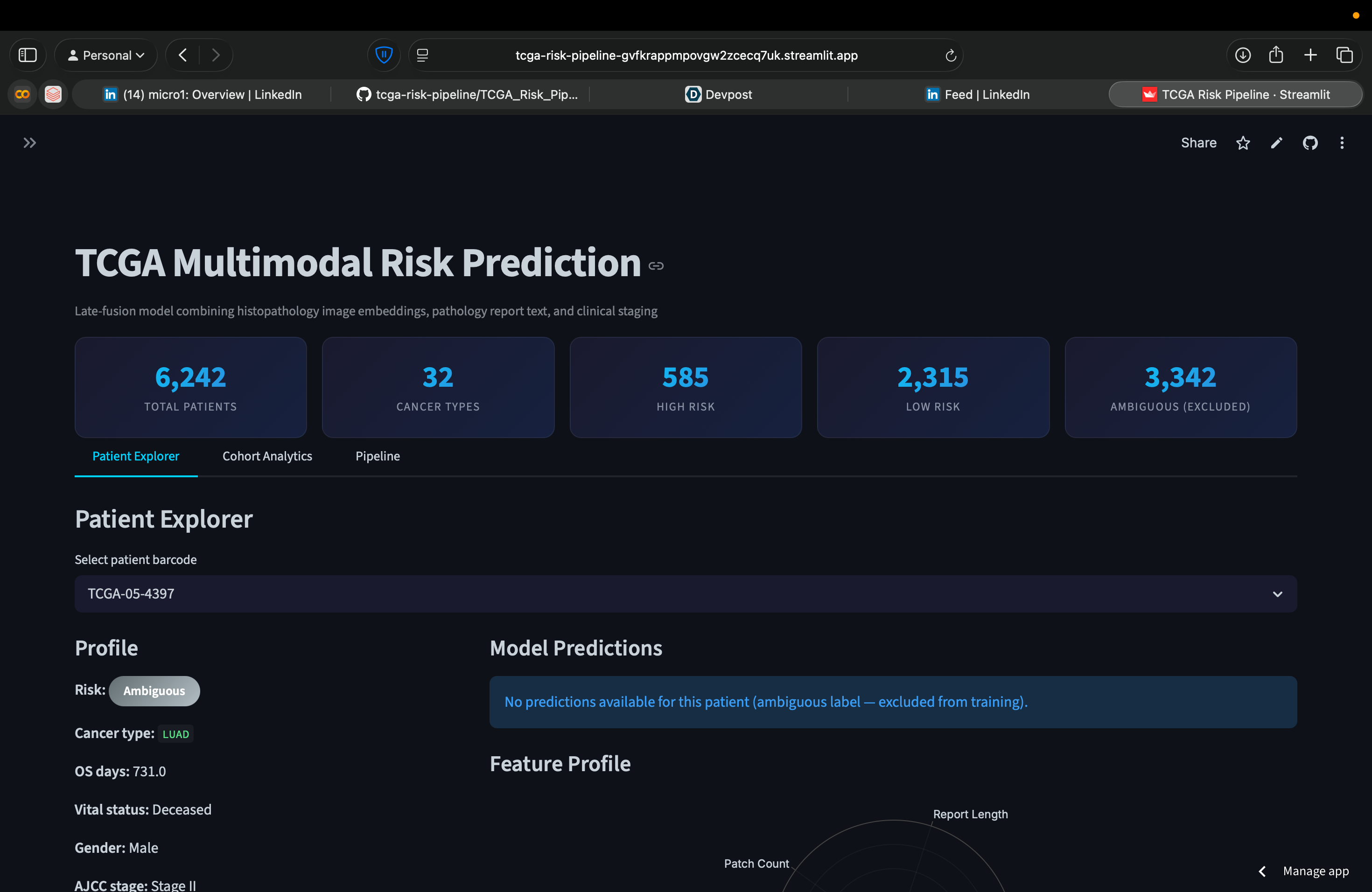
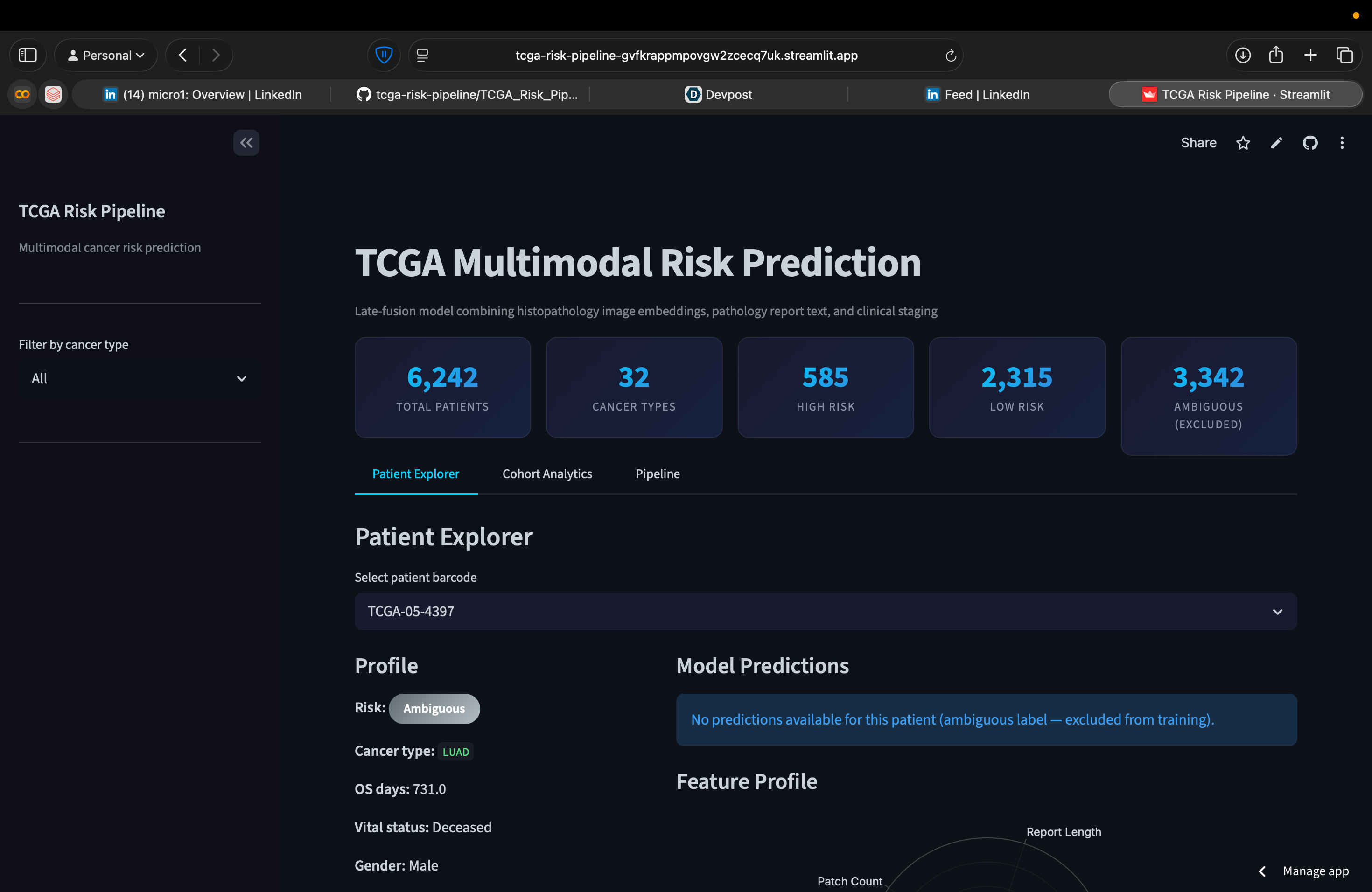
Takes a patient's histopathology patches, pathology report text, and clinical staging, outputs a high-risk or low-risk prediction. Works across 31 cancer types, 6,242 patients. The live app lets you search any patient, see predictions from three models, and explore the feature space interactively.
How we built it
Databricks medallion architecture (Bronze/Silver/Gold) with Delta Lake. Images processed on Colab T4 GPU: ResNet-18 extracts patch embeddings, then a Gated Attention MIL network learns which patches show tumor vs benign tissue. Text goes through TF-IDF + PCA. Clinical data gets one-hot encoded. Everything fuses into a 101-feature vector per patient with zero nulls. Three classifiers compared: logistic regression, LightGBM, PyTorch MLP. Also trained per-cancer-type models for the six largest cancer types.
Challenges we ran into
Caught a data leakage bug early: survival time was accidentally used as a feature while the label was derived from it. Model hit 94% which was completely fake. Removing it dropped to 70% which is honest. Class imbalance was brutal: Random Forest hit 79% accuracy but was just predicting majority class (50% balanced = coin flip on minorities). Had to switch metrics and models entirely.
Accomplishments that we're proud of
GBM-specific model hits 72.5% balanced accuracy with no leakage and no test contamination. The attention mechanism genuinely assigns high weights to tumor patches and low weights to benign stroma. Zero nulls across the entire feature matrix. Entire pipeline automated end-to-end on Databricks.
What we learned
Balanced accuracy is the only honest metric under class imbalance. PCA is not optional with 4K samples and 500+ features. Attention pooling is categorically better than mean pooling for histopathology. Per-cancer-type models beat global models when the disease is distinctive enough.
What's next for PathFusion
Adding genomic data as a fourth modality. Replacing binary classification with a proper survival model (DeepSurv). Validating on external cohorts outside TCGA.
Log in or sign up for Devpost to join the conversation.