-

Our homepage, with automatically named workspaces determined by browser history.
-

Our full-stack system has a frontend React app, a Flask/Python backend, interactions with ML frameworks/APIs, and a Firebase database.
-

Our NLP capabilities are listed here, which results from pre-processing our URL data into embeddings, clusters, and extracted text.
-

This is a visualization of what a sample workspace (Algorithm) might look like after being launched.
-

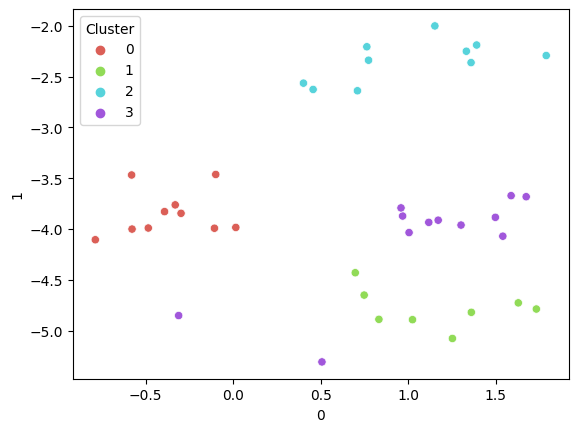
This is a t-SNE visualization of our URL embeddings. Our NLP infrastructure can identify these clusters to create separate workspaces.




Inspiration
Has your browser ever looked like this?
 ... or this?
... or this?

Ours have, all the time.
Regardless of who you are, you'll often find yourself working in a browser on not just one task but a variety of tasks. Whether its classes, projects, financials, research, personal hobbies -- there are many different, yet predictable, ways in which we open an endless amount of tabs for fear of forgetting a chunk of information that may someday be relevant.
Origin aims to revolutionize your personal browsing experience -- one workspace at a time.
What it does
In a nutshell, Origin uses state-of-the-art natural language processing to identify personalized, smart workspaces. Each workspace is centered around a topic comprised of related tabs from your browsing history, and Origin provides your most recently visited tabs pertaining to that workspace and related future ones, a generated textual summary of those websites from all their text, and a fine-tuned ChatBot trained on data about that topic and ready to answer specific user questions with citations and maintaining history of a conversation. The ChatBot not only answers general factual questions (given its a foundation model), but also answers/recalls specific facts found in the URLs/files that the user visits (e.g. linking to a course syllabus).
Origin also provides a semantic search on resources, as well as monitors what URLs other people in an organization visit and recommend pertinent ones to the user via a recommendation system.
For example, a college student taking a History class and performing ML research on the side would have sets of tabs that would be related to both topics individually. Through its clustering algorithms, Origin would identify the workspaces of "European History" and "Computer Vision", with a dynamic view of pertinent URLs and widgets like semantic search and a chatbot. Upon continuing to browse in either workspace, the workspace itself is dynamically updated to reflect the most recently visited sites and data.
Target Audience: Students to significantly improve the education experience and industry workers to improve productivity.
How we built it

Languages: Python ∙ JavaScript ∙ HTML ∙ CSS
Frameworks and Tools: Firebase ∙ React.js ∙ Flask ∙ LangChain ∙ OpenAI ∙ HuggingFace
There are a couple of different key engineering modules that this project can be broken down into.
1(a). Ingesting Browser Information and Computing Embeddings
We begin by developing a Chrome Extension that automatically scrapes browsing data in a periodic manner (every 3 days) using the Chrome Developer API. From the information we glean, we extract titles of webpages. Then, the webpage titles are passed into a pre-trained Large Language Model (LLM) from Huggingface, from which latent embeddings are generated and persisted through a Firebase database.
1(b). Topical Clustering Algorithms and Automatic Cluster Name Inference
Given the URL embeddings, we run K-Means Clustering to identify key topical/activity-related clusters in browsing data and the associated URLs.
We automatically find a description for each cluster by prompt engineering an OpenAI LLM, specifically by providing it the titles of all webpages in the cluster and requesting it to output a simple title describing that cluster (e.g. "Algorithms Course" or "Machine Learning Research").
2. Web/Knowledge Scraping
After pulling the user's URLs from the database, we asynchronously scrape through the text on each webpage via Beautiful Soup. This text provides richer context for each page beyond the title and is temporarily cached for use in later algorithms.
3. Text Summarization
We split the incoming text of all the web pages using a CharacterTextSplitter to create smaller documents, and then attempt a summarization in a map reduce fashion over these smaller documents using a LangChain summarization chain that increases the ability to maintain broader context while parallelizing workload.
4. Fine Tuning a GPT-3 Based ChatBot
The infrastructure for this was built on a recently-made popular open-source Python package called LangChain (see https://github.com/hwchase17/langchain), a package with the intention of making it easier to build more powerful Language Models by connecting them to external knowledge sources.
We first deal with data ingestion and chunking, before embedding the vectors using OpenAI Embeddings and storing them in a vector store.
To provide the best chat bot possible, we keep track of a history of a user's conversation and inject it into the chatbot during each user interaction while simultaneously looking up relevant information that can be quickly queries from the vector store. The generated prompt is then put into an OpenAI LLM to interact with the user in a knowledge-aware context.
5. Collaborative Filtering-Based Recommendation
Provided that a user does not turn privacy settings on, our collaborative filtering-based recommendation system recommends URLs that other users in the organization have seen that are related to the user's current workspace.
6. Flask REST API
We expose all of our LLM capabilities, recommendation system, and other data queries for the frontend through a REST API served by Flask. This provides an easy interface between the external vendors (like LangChain, OpenAI, and HuggingFace), our Firebase database, the browser extension, and our React web app.
7. A Fantastic Frontend
Our frontend is built using the React.js framework. We use axios to interact with our backend server and display the relevant information for each workspace.
Challenges we ran into
- We had to deal with our K-Means Clustering algorithm outputting changing cluster means over time as new data is ingested, since the URLs that a user visits changes over time. We had to anchor previous data to the new clusters in a smart way and come up with a clever updating algorithm.
- We had to employ caching of responses from the external LLMs (like OpenAI/LangChain) to operate under the rate limit. This was challenging, as it required revamping our database infrastructure for caching.
- Enabling the Chrome extension to speak with our backend server was a challenge, as we had to periodically poll the user's browser history and deal with CORS (Cross-Origin Resource Sharing) errors.
- We worked modularly which was great for parallelization/efficiency, but it slowed us down when integrating things together for e2e testing.
Accomplishments that we're proud of
The scope of ways in which we were able to utilize Large Language Models to redefine the antiquated browsing experience and provide knowledge centralization.
This idea was a byproduct of our own experiences in college and high school -- we found ourselves spending significant amounts of time attempting to organize tab clutter systematically.
What we learned
This project was an incredible learning experience for our team as we took on multiple technically complex challenges to reach our ending solution -- something we all thought that we had a potential to use ourselves.
What's next for Origin
We believe Origin will become even more powerful at scale, since many users/organizations using the product would improve the ChatBot's ability to answer commonly asked questions, and the recommender system would perform better in aiding user's education or productivity experiences.
Built With
- firebase
- flask
- huggingface
- pytorch
- react
- scikit-learn












Log in or sign up for Devpost to join the conversation.