-
-

-
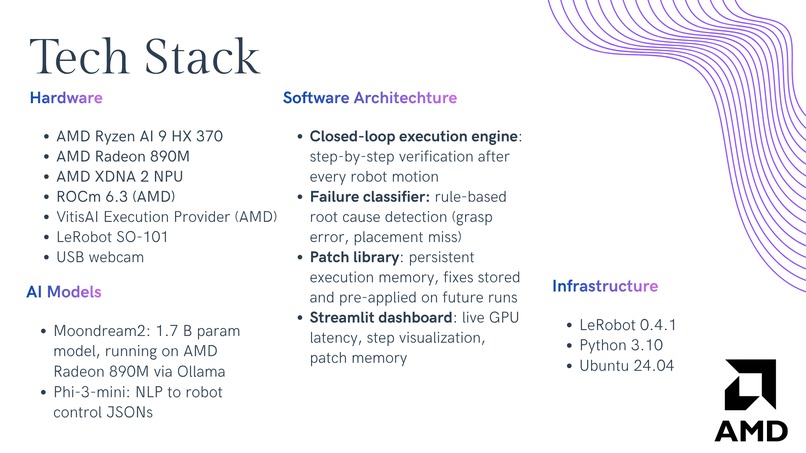
Tech Stack
-

GPU Benchmarking


Inspiration
Robot manipulation systems fail 15-35% of pick attempts in real-world deployment (Source: MarketsandMarkets). In massive fulfillment centers like Amazon warehouses, where thousands of robots handle millions of items, these small percentages translate into significant downtime and operational burden. Every failure requires a human engineer to diagnose, re-program, and restart at a cost of $150/hr, across a $30B industry. Existing solutions require cloud infrastructure, manual retraining, or expensive custom hardware. We wanted to build a system that can save repair costs by detecting its own failures and patching itself back to success without human intervention.
What it does
PatchWork is an on-device AI execution layer for robot arms. It compiles natural language commands into structured skill programs, then executes and verifies each action in real time using a vision-language model running entirely on AMD silicon. When a step fails, PatchWork diagnoses the root cause, patches the program automatically, and retries: no human intervention, no cloud dependency, no retraining.
How we built it
We used Phi-3-mini-4k-instruct, running via llama.cpp, which translates natural language operator commands into structured skill programs. The LeRobot SO-101 arm executes these programs via two modes: a trained ACT (Action Chunking Transformer) policy for learned motions, and record/replay for demonstrated trajectories. At each execution step, Moondream2, running on the AMD Radeon 890M via ROCm, runs a visual verification query against a live camera frame targeting a latency of under 200ms per check. A rule-based failure classifier categorizes outcomes into four failure types: GRASP_FAIL, PLACEMENT_MISS, PLACEMENT_COLLISION, and DROP_DURING_TRANSIT.
The patch library maps failures to corrective maneuvers. An asyncio orchestrator ties it all together, coordinating robot execution and VLM (Vision-Language Model) feedback with a MAX_RETRIES of 2 before flagging for human review. A trace logger writes events to a JSONL append log that a Streamlit dashboard polls every 500ms for real-time status.
We set up and stabilized the SO-101 leader-follower robot execution layer, including motor setup, calibration, USB/serial port mapping, and teleoperation validation. We also validated repeatable record/replay execution on the physical arm, turning the robot side into a reliable execution substrate for the rest of the system rather than just a teleoperation demo. To ensure a repeatable demo environment, we designed and CADed custom shelf slots in Autodesk Fusion to provide structured placement targets for the arm. We then designed the robot_api interface for skill recording, stepwise replay, and runtime patch control:
z_offset_mmspeed_scaleapproach_angle_deggripper_close_forceretry_count
Lastly, we got the VLA (Vision Language Action) loop working by linking natural language task structure to physical robot execution. In practice, that meant turning task-level intent into reusable robot skills, executing them through record/replay, and structuring the execution flow so each robot action could be checked and corrected inside the larger loop.
Challenges we ran into
Getting the AMD XDNA 2 NPU fully operational on Linux required navigating a driver stack at the frontier of what the platform supports. We successfully installed XRT drivers, validated the NPU (Neural Processing Unit) firmware, created persistent device node permissions, and confirmed the VitisAI Execution Provider loading correctly (quicktest.py passed), proving the NPU is functional at the kernel level. However, the software ecosystem for running vision-language models on the NPU on Linux was incompatible with our operating system. Therefore, we chose to run inference on the AMD Radeon 890M via ROCm rather than lose demo stability.
Running a vision-language model in a real-time closed loop showed a gap between benchmark performance and real-world performance. Our initial benchmarks showed sub-100ms VLM latency. When we tested with unique webcam frames instead of cached images, latency jumped to 650ms. We traced the issue to the vision encoder, added an image preprocessing pipeline, and used grammar-constrained decoding to cut token generation from 40 tokens to 3, bringing the warm latency down to approximately 200ms.
Finally, hardware doesn’t stop for hackathons. In the last couple of hours, a servo on the follower arm of the SO-101 failed, forcing us to troubleshoot, disassemble, repair, and restore the robot to a stable baseline before demo time.
Accomplishments that we're proud of
- 36-Hour Build: We built a fully on-device, closed-loop robot execution system in 36 hours with no cloud or internet dependency.
- Self-Healing Loop: The system works end to end: the robot fails, PatchWork diagnoses why, patches the program, retries, and succeeds.
- VLM Optimization: Getting from a 6000ms CPU baseline to 200ms warm inference on AMD hardware required a custom Ollama Modelfile and grammar-constrained decoding.
- NPU Driver Success: We are proud of being among the first teams to get the full AMD XDNA 2 NPU driver stack running on bare Ubuntu 24.04.
What we learned
- The hardest problems in robotics aren't mechanical, they're observability problems.
- A robot that fails silently is expensive; a robot that fails, explains why, and fixes itself is a product.
- We learned how to work with NPUs, how to build a VLA model, and how to integrate SLMs (Small Language Models) into hardware.
What's next for PatchWork
The immediate next step is deploying Phi-3-mini on the AMD XDNA 2 NPU for skill compilation. Our infrastructure is ready, and the deployment just needs to run. That completes the original architecture, using the NPU for language reasoning and GPU for vision verification.
Beyond the hackathon, PatchWork's patch memory is a data flywheel. Every deployment accumulates failure-fix pairs that make the system more reliable. The natural extension is using that data to train a predictive failure classifier, shifting from reactive self-healing to proactive failure prevention.
The longer-term vision is PatchWork as infrastructure: a self-healing execution layer that sits between any natural language interface and any robot arm.




Log in or sign up for Devpost to join the conversation.