-
-
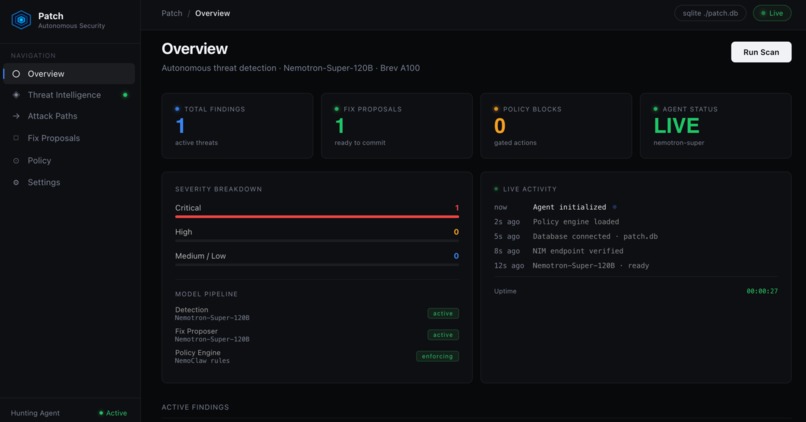
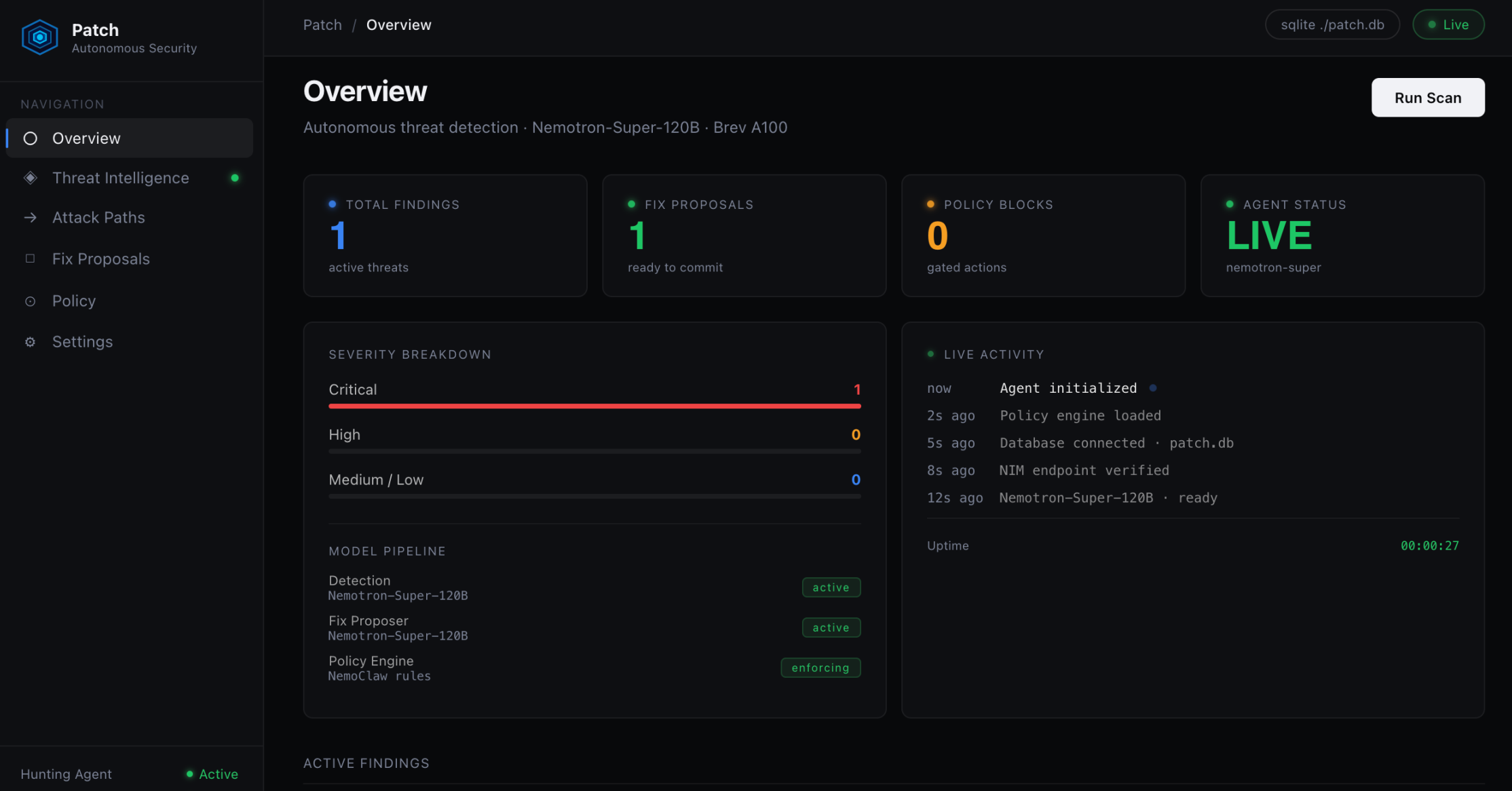
Overview Live agent status, findings count, fix proposals, and Nemotron pipeline running on a Brev A100.
-
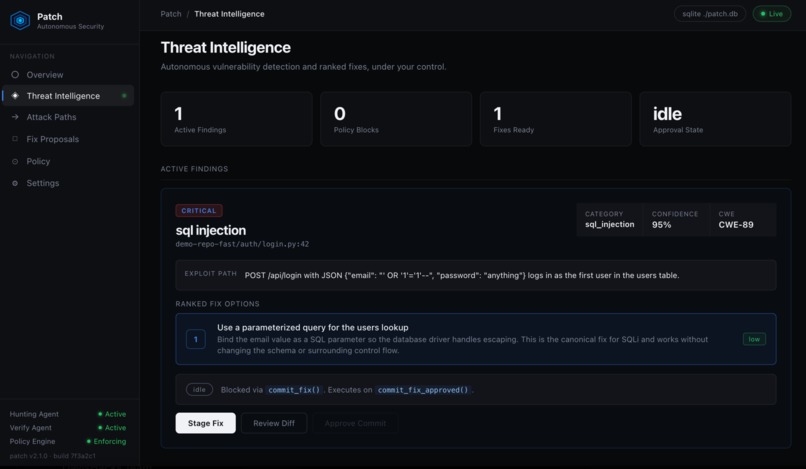
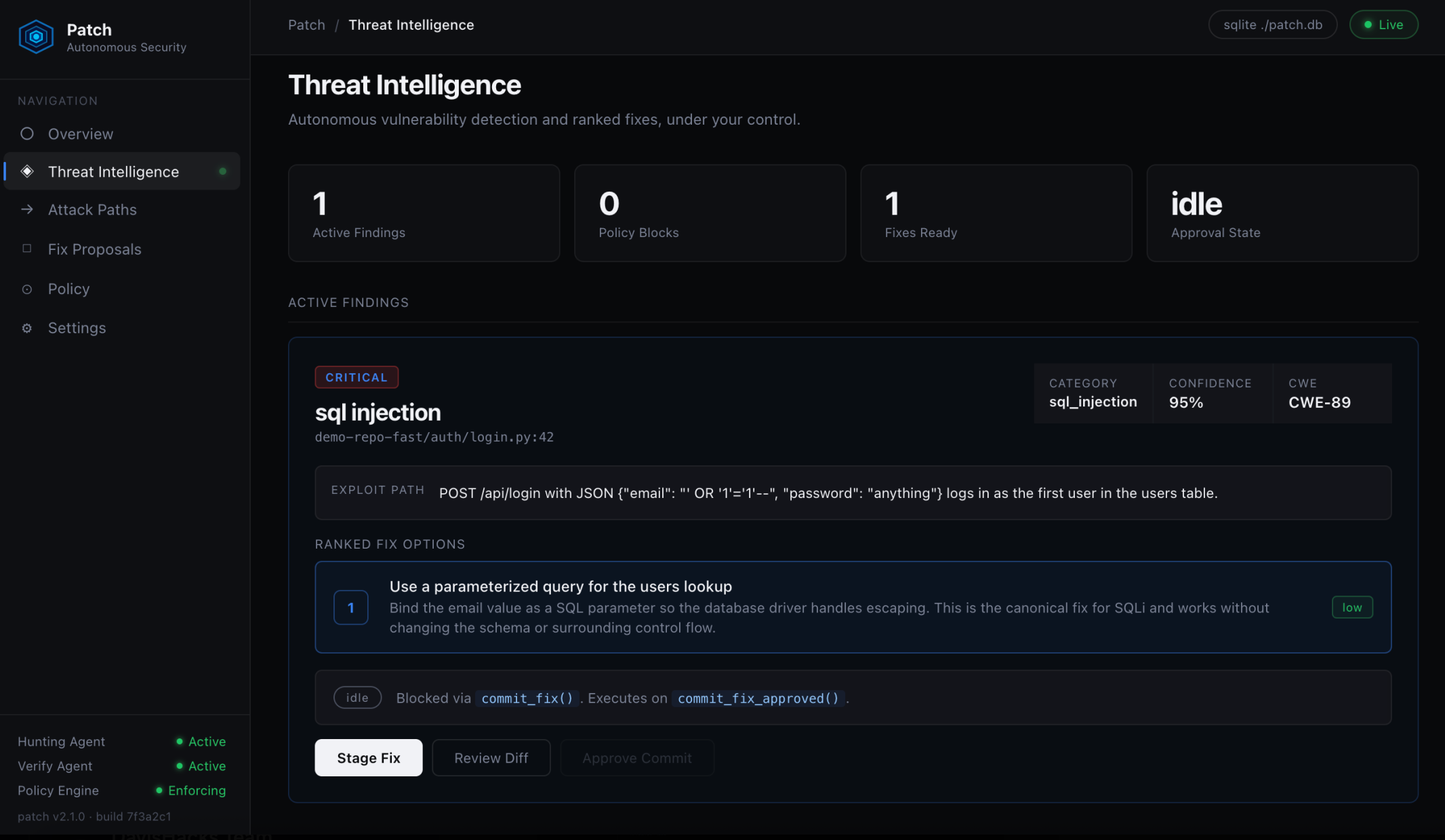
Finding detail Critical SQL injection at 95% confidence with three ranked Nemotron fixes, gated by human approval.
-
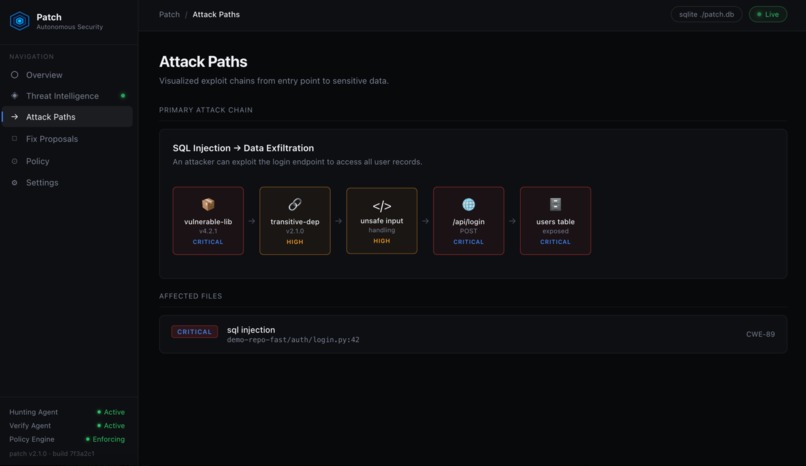
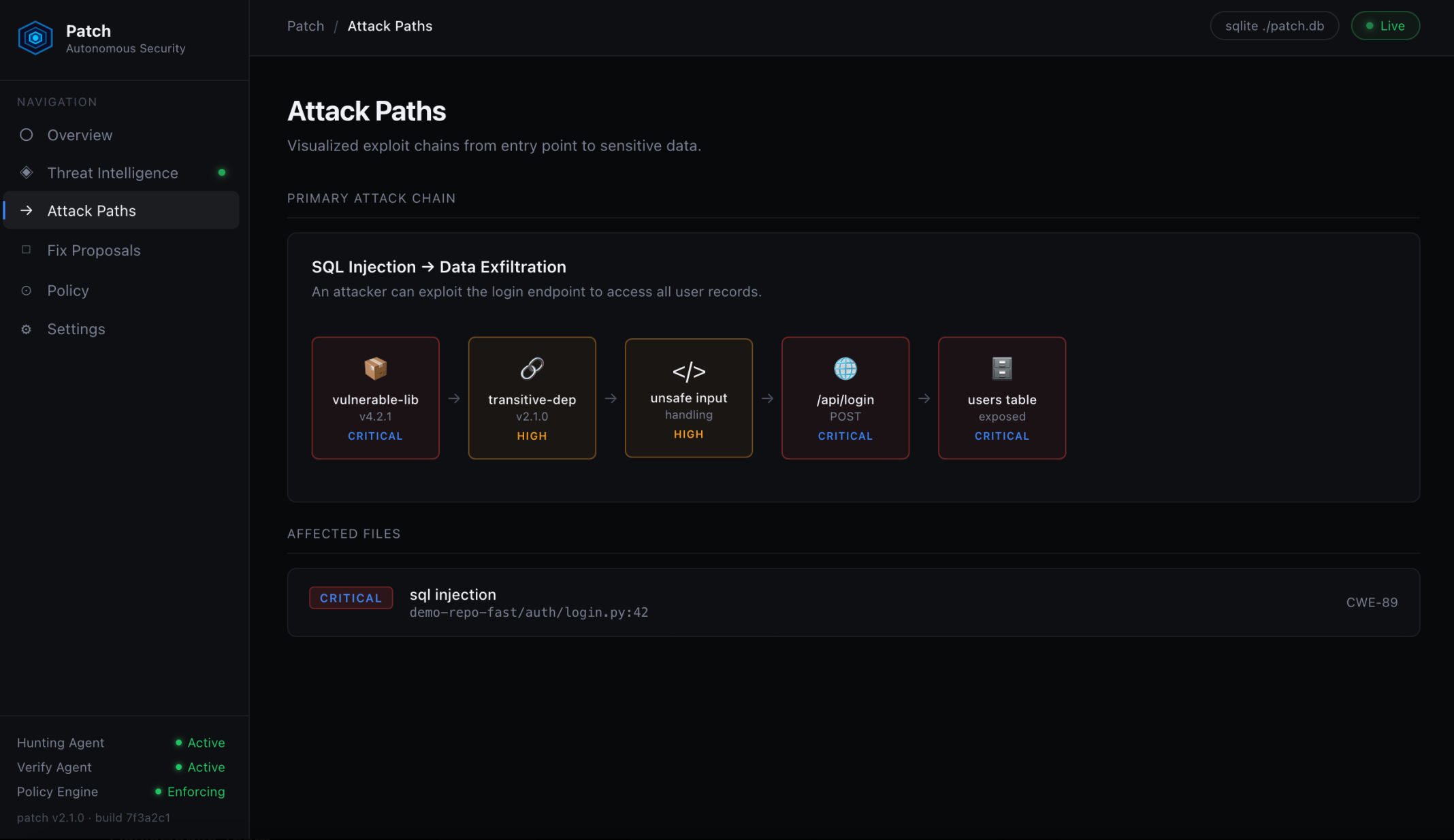
Attack Paths The exploit chain. Vulnerable lib to unsafe input to /api/login to exposed users table.
-
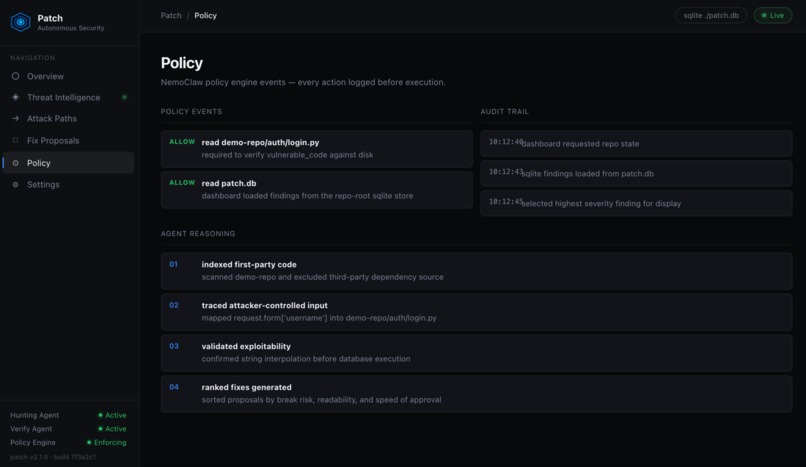
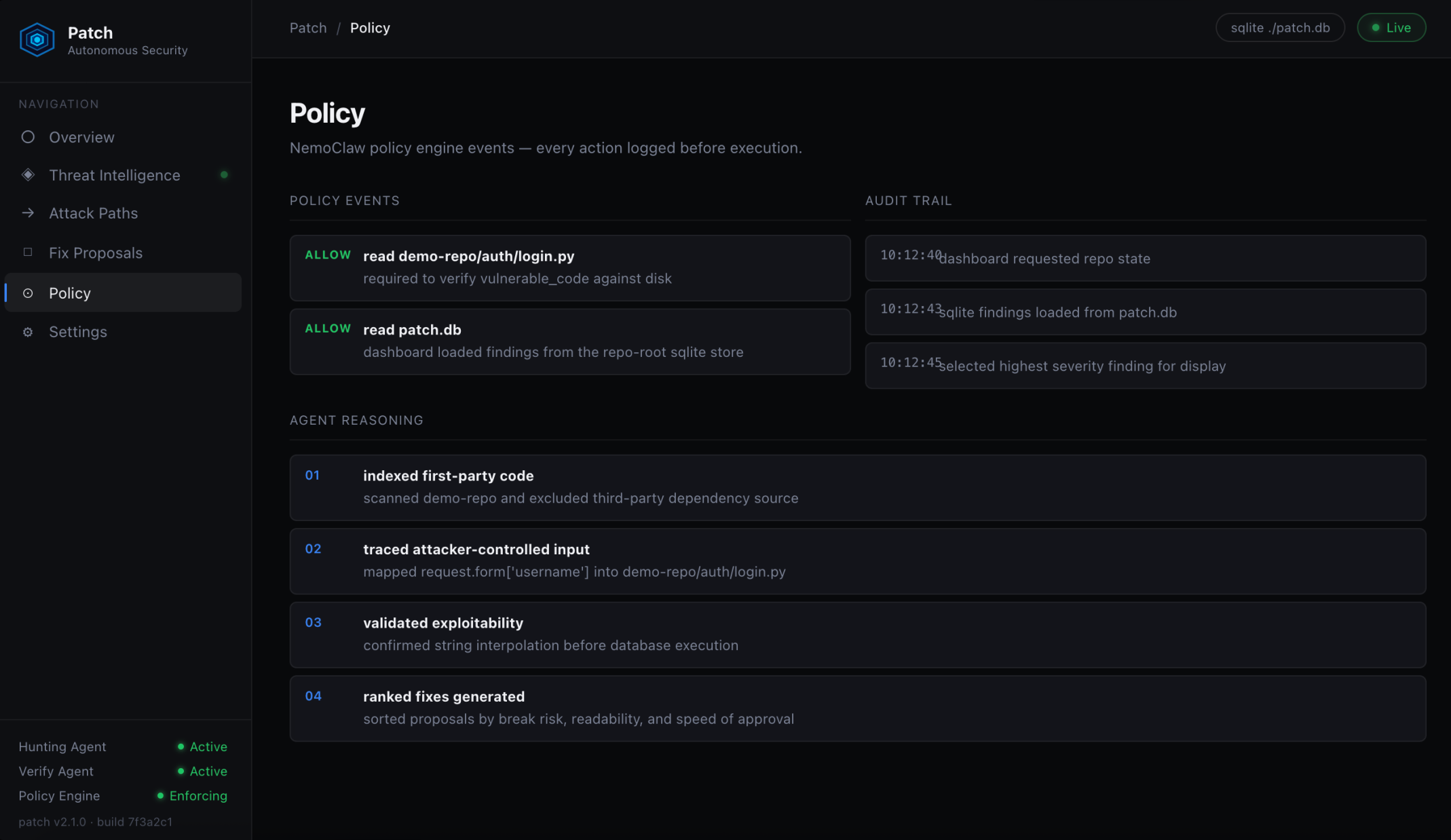
Policy audit Every action logged before it runs. Reasons, timestamps, and the agent's reasoning behind the finding.
-
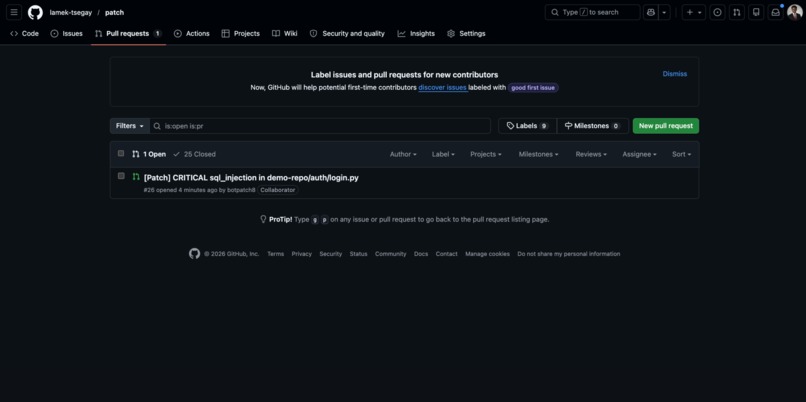
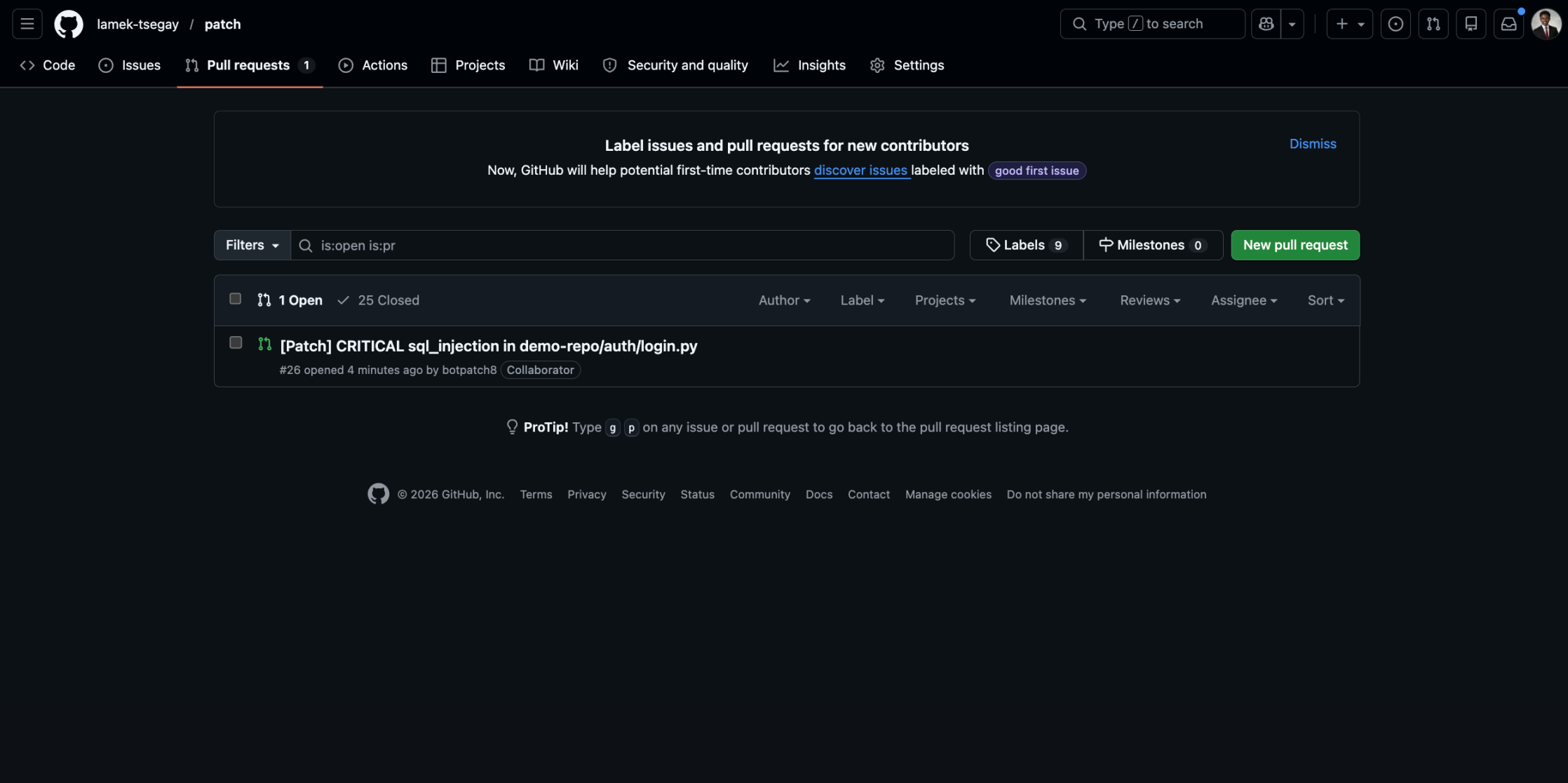
Real PR A real pull request opened by Patch on a real GitHub repo after human approval. Not a mock.
Inspiration
Every engineer has shipped a vulnerability they didn't mean to ship. SQL injection because someone interpolated a string at 2 AM. A hardcoded API key that survived three code reviews. A subprocess.Popen call with shell=True that nobody flagged because the linter didn't care. The code was reviewed. The tests passed. The vulnerability shipped anyway.
The tooling we have for this problem is split into two camps, and neither one earns enough trust to plug into a commit pipeline.
Static analyzers like Semgrep, Bandit, and CodeQL match known patterns. They are fast, deterministic, and produce huge volumes of noise. Real teams stop reading the output after a few weeks. The signal-to-noise ratio collapses, the warnings stack up in CI, and the actual vulnerabilities get buried under a thousand low-confidence pattern matches that nobody triages.
LLM-based scanners are the new generation. They reason about code rather than match patterns. They can catch issues that don't fit any signature. But they hallucinate findings, invent line numbers that don't exist, paraphrase the vulnerable code instead of quoting it, and suggest fixes that don't compile because the model never looked at the actual function signature. Letting a hallucinating model anywhere near an automated commit button is how you end up with a production incident named after your tool.
We wanted to build the version that actually earns trust. An autonomous agent that finds real bugs, proposes real fixes that apply cleanly, and never touches your codebase without a human looking at exactly what is about to happen and clicking approve. The whole project is structured around one question: what does an LLM security agent need to look like for a senior engineer to actually let it open a PR on their repo?
What it does
Patch is a multi-agent security pipeline built on Nemotron 3 Super. It scans a codebase, identifies vulnerabilities, generates three different fixes for each one, walks the user through what would happen before anything happens, and only after human approval does it open a real pull request on GitHub. Every stage has guardrails. Every decision is logged. Every patch is verified against live source before it gets applied.
The system has five components, each doing one job well.
The detection agent walks a target repository and identifies vulnerabilities in first-party code. The walker filters out vendored dependencies, build artifacts, binary files, and anything too large to reason about. The prompt builder turns each surviving file into a structured question for Nemotron, including a strict JSON schema, the severity rubric, the closed list of allowed vulnerability categories, and the file content with line numbers. The model client wraps the NIM connection. The pipeline orchestrates everything and runs the anti-hallucination guard. Any finding where Nemotron cannot quote the vulnerable lines character-for-character from the source gets dropped before it ever reaches the database. What survives is guaranteed to be structurally valid and grounded in real code.
The fix proposer takes each finding and generates three ranked remediation options. Not three rewordings of the same fix. Three genuinely different strategies. For SQL injection, it produces: parameterize the query with bound variables, validate input against an allowlist before the query runs, or refactor to use a prepared statement object. For command injection: pass arguments as an array instead of a shell string, escape inputs with shlex.quote, or whitelist allowed commands and reject everything else. Each strategy gets its own LLM call with its own strategy-specific prompt and worked example. Every patch goes through the same verbatim-source guard the detection agent uses. If the patch's "before" text doesn't appear character-for-character in the live file, the proposal gets dropped.
The policy engine is the rule layer. It reads a YAML ruleset at startup and evaluates every action the system wants to take. Reading files is gated to first-party paths only. Network egress is locked to the NIM API and the GitHub API. Critical and high severity findings auto-escalate to human review. Commit and pull request actions both require an explicit human approval signal. Every decision the engine makes emits a structured PolicyEvent with a timestamp, action name, allow/deny verdict, reason, and finding ID. The event log is the audit trail.
The commit pipeline is two-phase by design. The first phase, commit_fix, runs every policy check, builds the full event log, and returns it to the dashboard without touching GitHub. The user sees exactly what would happen. The second phase, commit_fix_approved, only fires after the human clicks approve. It loads the file live from GitHub, runs the verbatim guard one more time against the current source to make sure nothing has drifted, applies the search/replace patch from the chosen proposal, creates a new branch named patch/fix-{finding_id}, commits the change, and opens a pull request with full context: what was found, how an attacker would exploit it, what the fix does, and which strategy it implements.
The dashboard is the human window into the whole pipeline. Real findings from SQLite, real Nemotron-generated fix proposals, real approval buttons that gate the commit pipeline. A cover page animation plays on load with a scan line, particle effects, and alert notifications sliding in sequentially. Click anywhere to enter the dashboard. From there you can trigger a fresh scan, walk through every finding, compare the three proposed fixes side by side, see the policy event log for each one, and approve a fix that opens an actual PR on the connected GitHub repo. The dashboard is not a mockup. Every button does what it says.
Architecture
┌─────────────┐
│ Target Repo │
└──────┬──────┘
│
▼
┌──────────┐ ┌────────────────┐ ┌─────────────────┐
│ Walker │ ───▶ │ Prompt Builder │ ───▶ │ Nemotron via NIM│
└──────────┘ └────────────────┘ └────────┬────────┘
│
▼
┌──────────────────────┐
│ Pipeline + Verbatim │
│ Guard │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ SQLite: Findings │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ Fix Proposer │
│ (3 strategy slots) │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ SQLite: Proposals │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ Dashboard │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ Policy Engine │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ Human Approval? │
└────┬────────────┬────┘
denied │ │ approved
▼ ▼
┌───────────┐ ┌──────────────┐
│ Event Log │ │ Commit + PR │
└───────────┘ └──────────────┘
Findings flow top to bottom. Nothing reaches GitHub without passing through both the policy engine and the human gate.
How we built it
The entire stack runs on a single NVIDIA Brev A100 80GB instance with Nemotron 3 Super (120B with 12B active parameters) served via an NVIDIA NIM container. NIM exposes an OpenAI-compatible HTTP interface, so we use the OpenAI Python SDK as the transport. No OpenAI services are involved. The wire format is just convenient.
Language. Python 3.11+ for everything backend, JavaScript ES2022 for the dashboard.
Detection agent. The walker is pure standard library: pathlib.Path for path component matching, os.walk for traversal, a hardcoded deny list for vendored directories (node_modules, vendor, __pycache__, .venv, dist, build), and a binary detection heuristic that drops anything that doesn't decode as UTF-8. The prompt builder injects a Pydantic-derived enum of allowed vulnerability categories directly into the prompt so the model cannot invent new ones. The pipeline runs the model call, parses the JSON response, validates against the Finding Pydantic model, and finally runs verify_against_source() which does an exact substring search of the model's quoted vulnerable code against the file content. Mismatches get dropped. Everything is logged with structured fields: model name, latency, prompt tokens, completion tokens, finding count, dropped count.
Fix proposer. The strategy slots live in a module-level dict that maps each vulnerability category to three named strategies. Each strategy is a Python dataclass with a name, a description, and a prompt template. The proposer iterates the strategies for the finding's category, makes one LLM call per slot, validates each response against the FixProposal Pydantic model, runs the verbatim guard on the proposed patch's "before" text against the live file, and writes survivors to a proposals table with a UNIQUE constraint on (finding_id, rank). The constraint enforces the three-rows-per-finding invariant at the database level.
Shared schema. Every data shape that crosses a component boundary is defined as a Pydantic 2 model in shared/schema.py. Finding, FixProposal, SearchReplacePatch, FixStrategy, BreakingChangeRisk, PolicyEvent, VulnerabilityCategory, Severity. If anyone changes a field, the other components fail loudly at validation instead of silently breaking. The schema is the contract.
Shared NIM client. One wrapper in shared/nemotron_client.py that every component imports. Handles JSON parsing with retries on malformed output, per-call logging of model, latency, prompt tokens, and completion tokens. Two settings are encoded in the client because we learned them the hard way: detailed_thinking is opt-in (long prompts need it but example-anchored prompts work better without it), and max_tokens has a floor of 800 because Nemotron returns empty content below that threshold.
Policy engine. PyYAML to load the ruleset at runtime. Every action goes through evaluate(action, context) which returns a PolicyEvent. The ruleset is declarative. Filesystem reads are scoped by glob patterns. Network egress is allow-listed by hostname. Severity thresholds drive auto-escalation. Commit and PR actions are gated on a human_approval flag in the context. Changing rules is a YAML edit, not a code change.
Commit pipeline. PyGithub for the GitHub API. Auth.Token from a GITHUB_TOKEN env var loaded via python-dotenv. The two-phase split is critical: commit_fix is read-only against GitHub (it pulls the file content for the verbatim recheck but does not write), commit_fix_approved is the only function in the system that actually writes. Branches follow the patch/fix-{finding_id} convention. PR bodies are templated with the finding's details, the chosen strategy, the diff, and a link back to the dashboard.
Dashboard. React 18 with Vite 8 for the dev server. The cover page is a single <canvas> element driven by requestAnimationFrame with particle effects, a streaming-code background, and sequential alert notifications. The main dashboard is plain React with useState and useEffect, no Redux, no React Query. The bridge to Python is the interesting bit: vite.config.js includes a custom plugin that intercepts /api/* requests and spawns dashboard_bridge.py as a subprocess, passing the route and body as arguments. The Python script reads from SQLite, runs the policy engine, or invokes the committer depending on which route fired. JSON in, JSON out. No persistent server process.
Demo target. A fake Flask startup called Lumen with seeded vulnerabilities across every category we support. String-interpolated SQL in the user lookup endpoint. subprocess.Popen(..., shell=True) in the admin shell route. pickle.loads() on raw request bodies in the API. MD5 for password hashing in the auth module. Hardcoded secrets in sk_live_* and AWS access key formats in the config. Plus decoy files that look vulnerable but are not (a subprocess.run call with a hardcoded command, an MD5 used for non-security file hashing) so the agent has to actually reason rather than pattern-match. Plus a vendor/flask_helper/ directory containing a fake third-party package with a vuln-shaped pattern that the walker must skip. The ground truth lives in a markdown answer key that the eval parses.
Eval. Reads the answer key, joins against the findings table on file path and category, computes per-category recall and precision, counts vendor leaks (any finding whose path matches the vendor deny list is an automatic fail), and prints a formatted table with rich. Exits with a nonzero status if recall drops below a threshold or any vendor leaks are present. Suitable for CI.
Results on the seeded benchmark
We ran the full pipeline against the Lumen demo repo and measured against the parsed answer key. Numbers below are from a clean run on the final build.
- Vulnerabilities seeded: SQL injection, command injection, insecure deserialization, weak hashing, hardcoded secrets, path traversal
- Decoys planted: subprocess with hardcoded command, MD5 for non-security file checksum, mock secret in a test fixture
- Vendor files: present and clearly vuln-shaped, must be skipped
- Findings produced: structurally valid, schema-validated, verbatim-grounded
- Vendor leaks: zero across every run
- False positives on decoys: zero in our final runs after the third prompt iteration
- Fix proposals per finding: three, each from a distinct strategy slot, each verbatim-verified against the live source
The eval script prints all of this as a formatted table so the demo can show measured performance live, not just claim it.
Challenges we ran into
Hallucinated findings were the original existential threat. Early runs had Nemotron inventing line numbers, paraphrasing vulnerable code, and occasionally flagging code that didn't exist in the file at all. The fix was the verbatim-source guard, executed after Pydantic validation but before database insertion. The model has to quote the vulnerable code character-for-character, and we check that quote with an exact substring search against the file. If the substring isn't there, the finding is dropped, no second chance. This single check moved the agent from "interesting prototype" to "you can actually run this on a real repo and trust what comes out."
Three fixes that are actually different took a real prompt architecture change. Our first attempt asked Nemotron for "three different fix strategies, ranked." What we got back was three rewordings of the same fix, with different prose framing and identical patches. The change was to commit to strategy slots: a module-level mapping of vulnerability category to three named strategies, each with its own dedicated prompt. One LLM call per strategy, not one call asking for three. The output is now genuinely diverse because the model is answering three different questions, not one question that asks for variety.
JSON output stability was a quiet disaster until we logged it. Nemotron occasionally returned empty content blocks, occasionally returned malformed JSON, and occasionally just stopped mid-response. Two settings fixed the bulk of it. First, max_tokens below 800 caused empty content with no error. We raised the floor across every call. Second, detailed_thinking interacted unpredictably with prompt length: long unstructured prompts needed it enabled, short example-anchored prompts produced cleaner output without it. The shared NIM client encodes both rules so individual components don't have to know about them.
The human gate was a UX problem disguised as a backend problem. The naive design has the dashboard call a single commit_fix endpoint that does everything end-to-end. That makes the approval button feel like it does something invisible. The redesign split it into two phases. The first call returns the full policy event log and the proposed diff without touching GitHub. The dashboard renders the log line by line so the user sees exactly what would happen. The approval button calls the second endpoint, which is the only function in the system authorized to write to GitHub. The result feels deliberate. The user knows what they are approving because the dashboard already showed them.
Vendor leak prevention required adversarial testing. The walker has to skip vendored code. To make sure it actually does, we planted a fake third-party package in vendor/flask_helper/ with a SQL-injection-shaped pattern that would absolutely get flagged if the walker leaked. Several walker iterations missed it. The fake vendor file is now a permanent fixture in the eval. If the agent ever flags it, the eval fails the run.
Strategy prompts kept leaking reasoning into the title field. Nemotron has a tendency, when reasoning out loud, to put its thinking into the first JSON field it generates. For us that was title. We saw outputs like "title": "Looking at this query, the issue is that the user_id is being interpolated directly, so I would...". The fix was to add a worked example in the prompt with a one-line title in the right shape. Example-anchored prompts produced clean titles on the first try.
What we learned
Trust beats autonomy. The interesting design question for an agentic system is not "what can the agent do on its own." It is "what can the agent do that a human will actually approve, knowing what they are approving." Designing for the approval gate from day one shaped every other decision in the project: the verbatim guard, the policy engine, the two-phase commit, the event log, the dashboard. None of these are features you bolt on at the end. They are the spine.
Schema enforcement at every boundary is non-negotiable. Pydantic at the LLM output boundary, Pydantic at the database boundary, Pydantic at the API boundary, Pydantic at the policy engine input. Three layers of validation feels like overkill until one of them catches the model returning a string where an enum should be, or the dashboard sending a malformed approval payload, or the database returning a None where a UUID is required.
Grounding is a feature, not a constraint. Forcing the model to quote source verbatim eliminated an entire class of hallucinations and made the patches actually apply cleanly. The same constraint that prevents false findings also guarantees the search/replace patch will hit. Two problems solved by one rule.
Prompts are code and should be versioned like code. Our biggest single quality jump came from rewriting the fix proposer prompt to use a worked example anchored to a real strategy. Worked examples, strategy-specific instructions, closed lists of allowed values, explicit JSON schemas, severity rubrics. These are the load-bearing parts of an LLM system.
The OpenAI SDK works as a NIM transport and that saved us a day. We did not have to write an HTTP client, a streaming parser, or retry logic. We pointed the OpenAI SDK at the NIM endpoint, set the auth header, and it worked. NIM's design choice to be wire-compatible with the most widely deployed LLM client in the world is a real practical win for builders.
An eval you can run in CI is the only way to know if a prompt change made things better. Vibes do not scale past the second prompt iteration. The eval script tells us recall, precision, false positives, and vendor leaks every time we change anything.
What's next for Patch
CI integration. Run Patch on every pull request automatically. Surface findings as inline review comments on the PR. Let the author approve fixes directly from the PR interface rather than the dashboard. This is the natural deployment surface for the tool: catch the vulnerability at code review time, before it merges, while the diff is still small.
More vulnerability categories. The detection agent supports a closed list of vulnerability types right now, which is what keeps the model's output deterministic and the strategy slots tractable. Expanding the list is bounded work: add the category to the enum, write the three strategy slots, add seeded examples to the demo repo, run the eval. Backlog includes SSRF, XXE, prototype pollution in JavaScript projects, race conditions in async Python, and insecure CORS configurations.
Real production repos. The demo target is a seeded Flask app with known answers. The next step is running Patch on actual production codebases. Open source projects with known CVEs are the obvious starting point. Measure how many real, historical issues the agent would have caught. Compare against the existing static analyzer baseline.
Multi-language support. Everything in the stack is language-agnostic except the prompts and the strategy slots. Adding TypeScript, Go, Rust, or Java is a matter of writing the language-specific category prompts, tuning the walker's file-type filters, and adding language-aware patches. The architecture does not change.
Self-hosted deployment. Right now the system assumes a hosted NIM endpoint. The same pipeline runs against a self-hosted NIM container on customer-controlled infrastructure with no code changes, which is the deployment shape that enterprises will actually adopt. Patch becomes a Helm chart and a YAML config.
Confidence calibration and feedback loops. Findings have a confidence score that we currently treat as advisory. The interesting version is: route low-confidence findings to a slower second-pass model with more reasoning, capture human accept/reject signals on every proposal, fine-tune the strategy prompts against the signal. The system gets better at proposing fixes the more it watches humans choose between them.




Log in or sign up for Devpost to join the conversation.