-
-
Home page
-
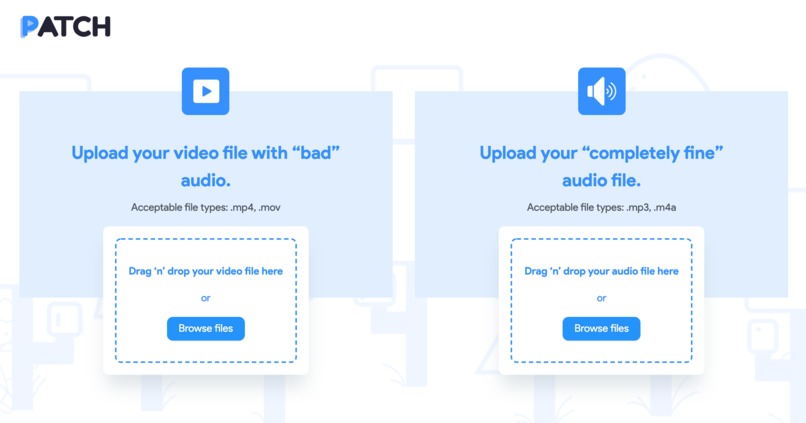
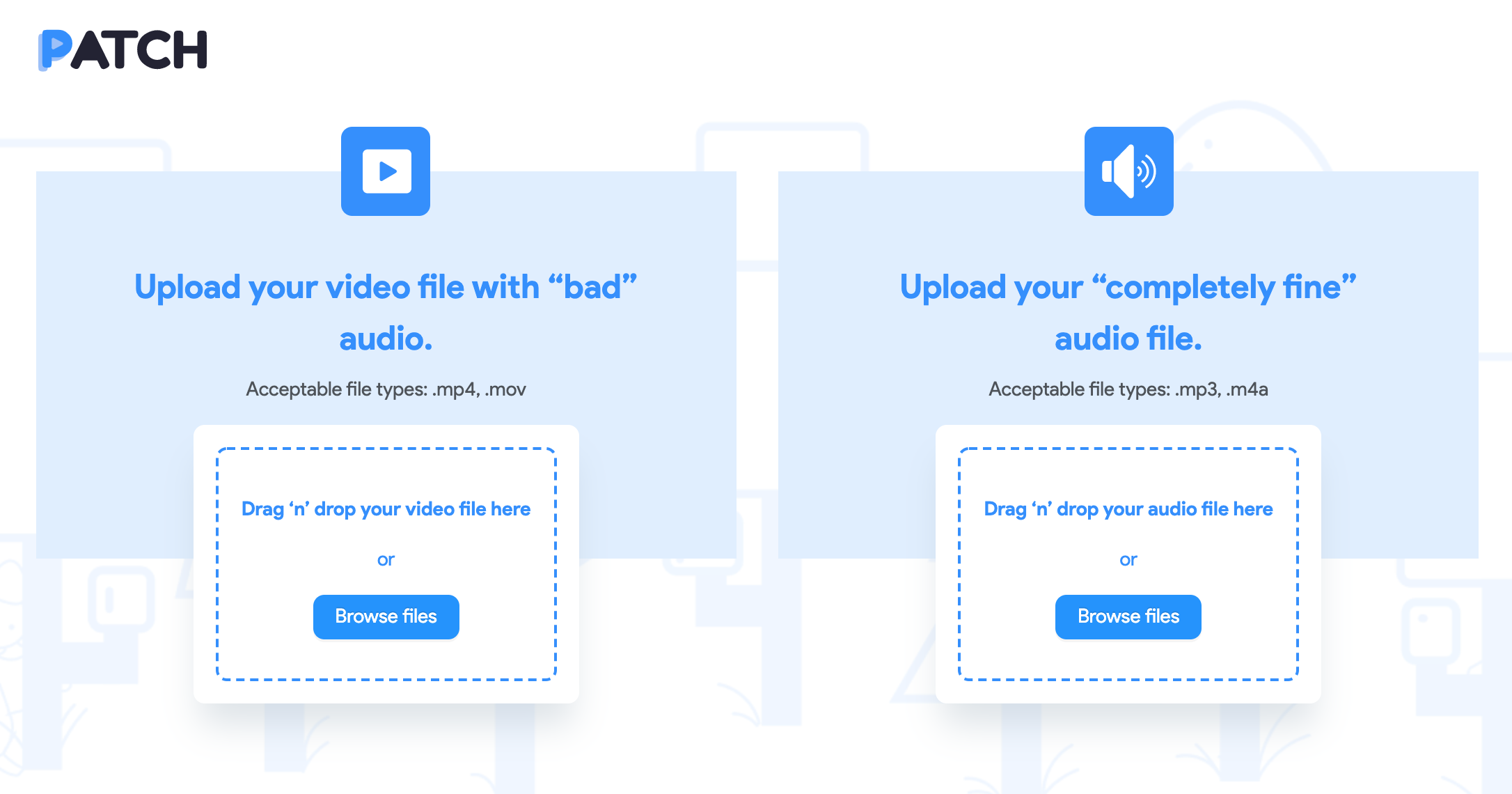
Select the Zoom video recording with corrupt audio and audio file in good condition
-
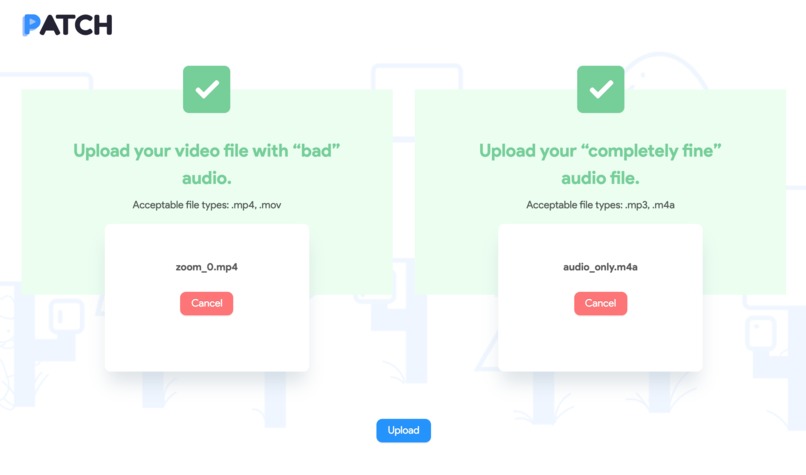
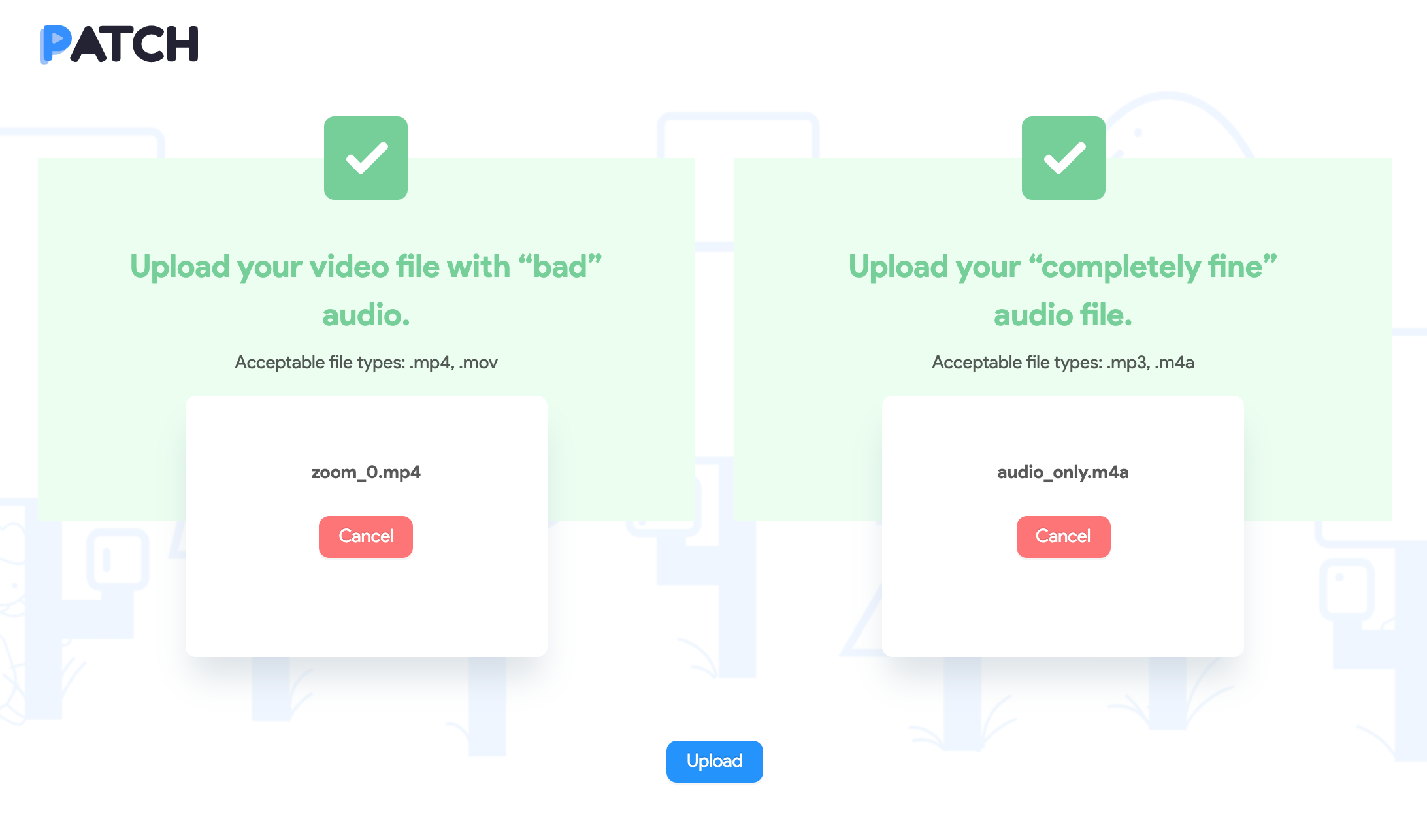
Once you select both files, you're good to upload!
-
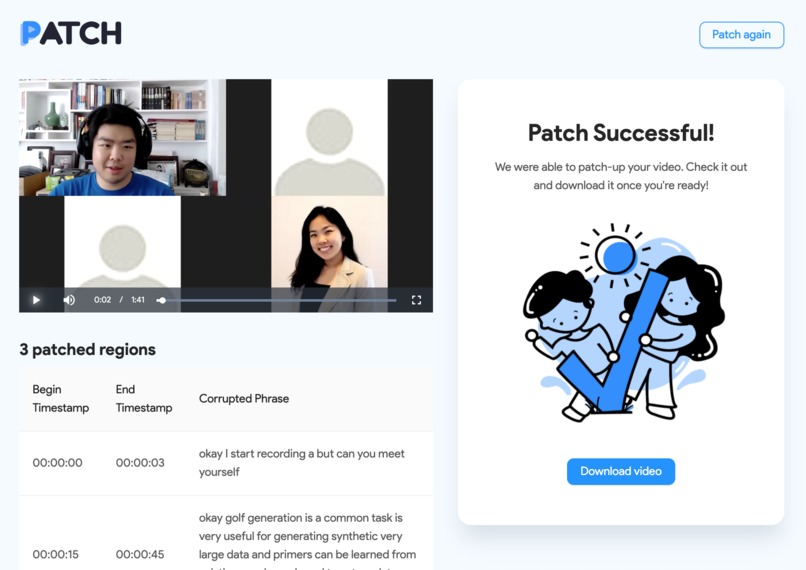
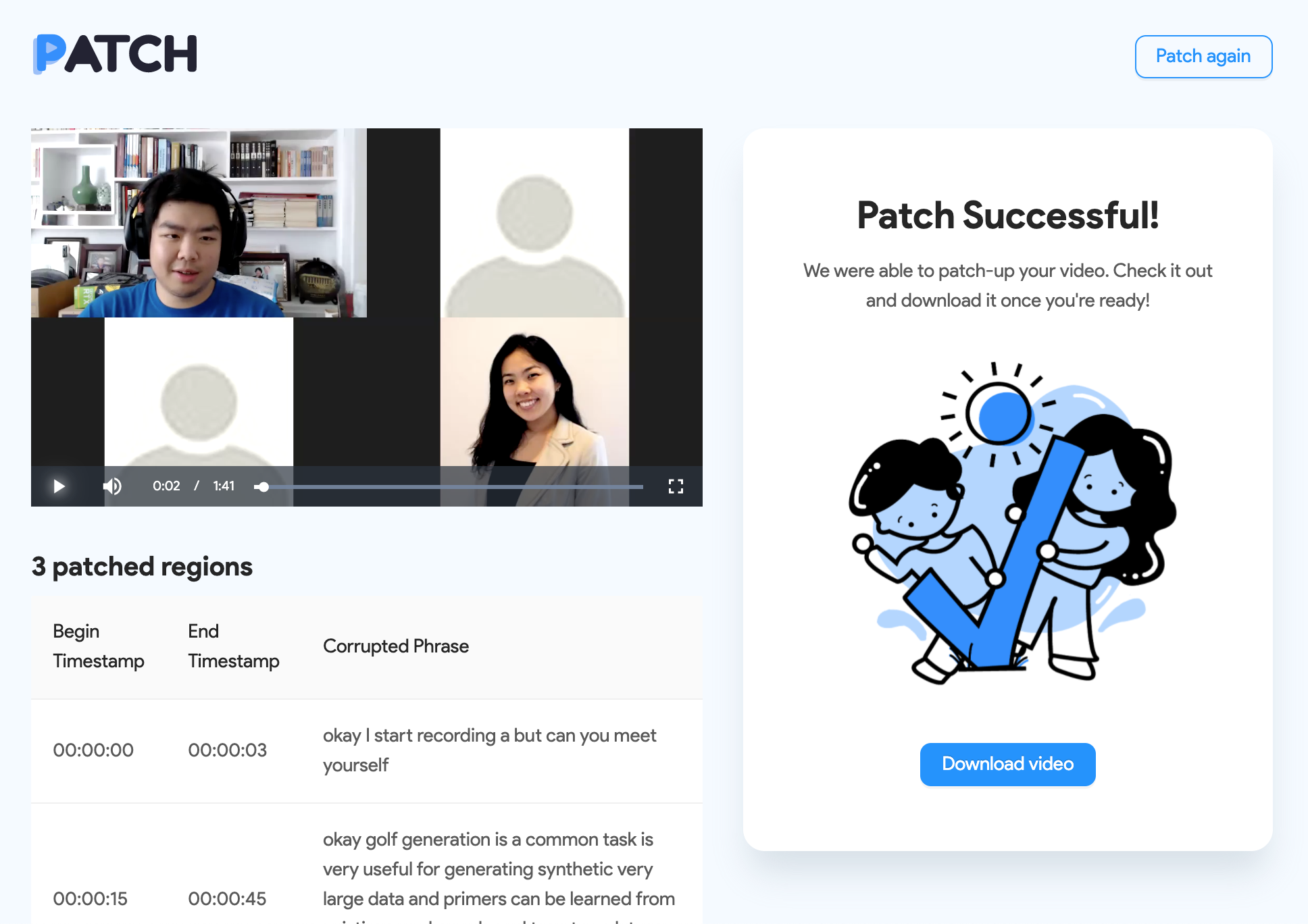
The patched-up video is ready for you to preview and download, as well as information about the corrupted segments
Inspiration
With social distancing in full effect, Zoom is more prevalent than ever. However, a common problem is that not everyone has the best internet connection. While there is not much that can be done during the meeting, Patch allows a user to retroactively patch the recording of the meeting.
What it does
Patch takes advantage of the fact that the full quality version of the user's voice passes though the computer first, before it is transmitted to Zoom. Any errors or connection issues typically occur during transmission.
Patch allows an user to upload their Zoom meeting recording and an audio recording of their own microphone that they took locally. It then analyzes the audio of the meeting recording and attempts to find sections that are corrupted. It then automatically synchronizes the two tracks, replaces the corrupted portions of the meeting recording, and reconstructs the video using the repaired audio.
You may wonder how this is different from simply replacing the meeting audio with the microphone-recorded audio. First, it is already non-trivial to precisely synchronize the two audio tracks. Second, and most importantly, this method allows us to the keep the audio of other speakers (although we cannot repair their audio).
We also caption the corrupted audio sections to allow a user to quickly see what information they might have missed in the meeting without having to rewatch the entire recording.
How we built it
Backend
We used the LibROSA Python library to read in the audio files as a vector of floating point values. We then performed a FFT, filtered, and an IFFT on the data to limit the frequency of the signal. We then used MASS (Mueen's Algorithm for Similarity Search) to synchronize the audio tracks.
We used the Matrix Profile to help identify segments of the track that were likely corrupted and patched. We were then able to demux the video with ffmpeg and replace the portions of the corrupted audio with the local recording. Finally, we remux the audio and video together to return the patched recording.
We also used GCP's Speech-to-Text API to caption the corrupted sections of the audio.
We used the following GCP services:
- Google Cloud Storage: to store and serve the repaired videos.
- Google Cloud Speech-to-Text: to caption the corrupted audio sections.
- Google Compute Engine: to serve the Flask backend and perform the steps described above.
- Google Cloud Memorystore: to cache requests and speed up responses for previously seen audio/video
Frontend
The frontend is created using React and consists of 3 main views: the Home page, Upload page, and Result page.
The Home page is where the user can learn more about the app, including what it is and how it works. This is where the user can be taken to begin the user flow, described next.
The Upload page is where the main user flow begins. The user is required to upload 2 files: a video file containing the corrupt audio and the audio file in good condition. Once these files are selected, a request is sent to the backend for upload and processing.
Once the backend process finishes, the user will be redirected to the Result page, which is composed of 3 main elements: a video preview of the fixed and patched-up audio, a download link, and a table displaying the timestamps with corrupt audio and the words that were lost in the original video file.
Challenges we ran into
None of our team members have much experience with signal/audio processing and we encountered a lot of new concepts and challenges. We had a hard time finding an effective way of synchronizing the audio tracks, especially since Zoom appears to do some audio processing in the meeting recordings. Finding the segments with corrupted audio was also very difficult without training data, so we had to rely on unsupervised methods.
A lot of the operations were also extremely computationally intensive, so we had to find workarounds in order for the operations to finish in a reasonable amount of time. For example, we used the SCRIMP++ algorithm to calculate the approximate matrix profile, rather than calculate the exact matrix profile. We also had to lower the audio sample rate for MASS in order for it finish more quickly.
Accomplishments that we're proud of
Amanda created all of the images for the frontend from scratch! We're also proud to have created a project that can help students learn during quarantine, as a poor connection can lead to lost content and negatively impact the Zoom learning experience.
What we learned
Members of our team unfamiliar with GCP learned a lot about utilizing various GCP APIs and integrating various components into the backend.
We also learned a lot about working with signals and time series data in general.
What's next for Patch
The method to find the corrupted segments of the track can be definitely improved. The current approach is not very accurate and can easily overestimate the amount of corrupted audio, replacing more than necessary. Although this is not an issue in the typical academic single-presenter setting, it would could an issue for meetings with more than one primary speaker.
This could possibly be made more accurate with more sophisticated supervised methods, such as by training a CNN or LSTM. However, this would require a large amount of training data in the form of marked corrupted Zoom meeting recordings, which we did not have.
Another useful feature would be to be able to accept multiple audio recordings, one from each person in the call. This would potentially allow for a near-perfect recreation of the meeting audio, without the risk of losing audio from other speakers. However, this would also require some method to identify the current speaker(s) since it would be otherwise extremely difficult to determine who had the faulty audio. This could possibly be done with computer vision on the Zoom meeting recording's video.










Log in or sign up for Devpost to join the conversation.