-

-
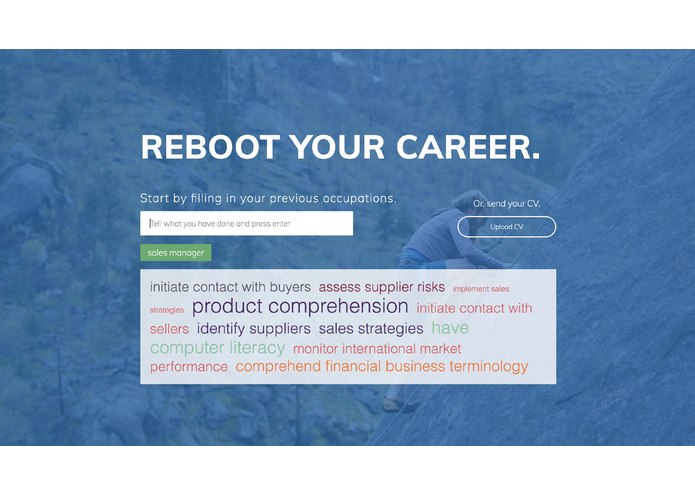
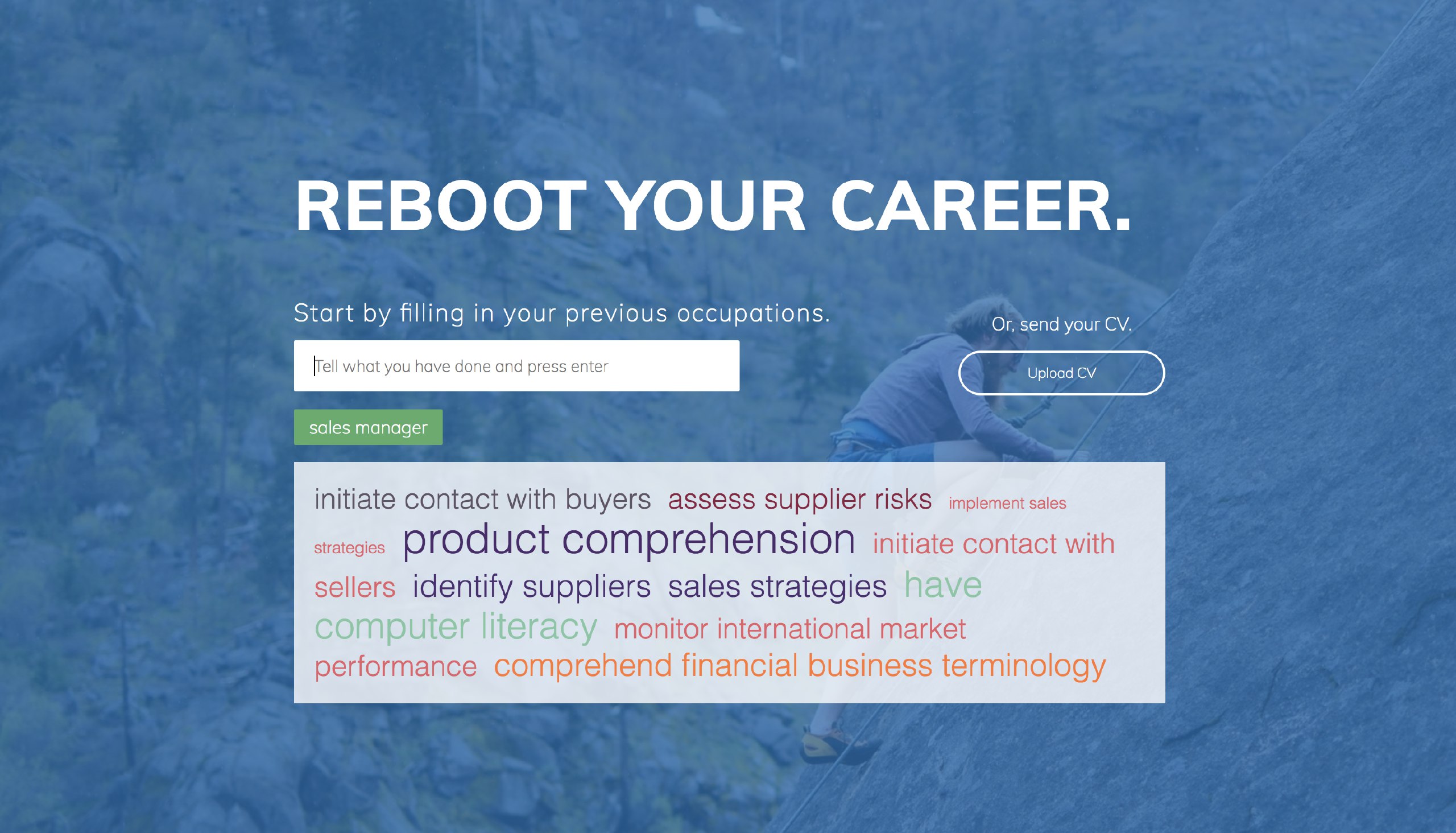
By entering 1-3 previous work experiences user gets a suggestion of new skills that would improve his/her career the most.
-

CV parsing and keyword mapping
-
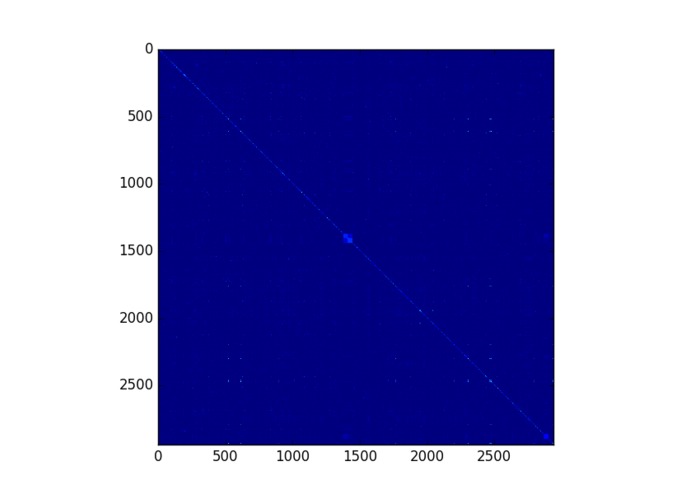
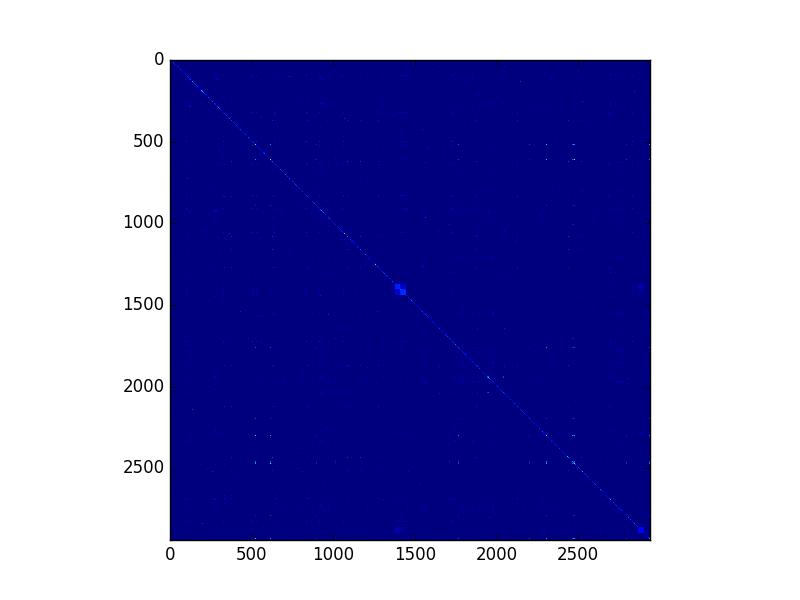
Example mapping of 2900 professions against each other by similar skills needed in professions to compare


Inspiration
We wanted to modernize the way recruitment works.
Job market is struggling with unemployment and especially unemployment of immigrants, bringing employers and possible employees together and educating the unemployed to match the needs of the market.
During our hack we found out that a huge amount of people can be employed again with one or two new skills. We wanted to allow job seekers to find all the possibilities matching their skills.
Big corporations recruit thousands of new workers every year. For an example, Kesko plans to recruit 5000 summer workers next summer. This means even more applications and reading through these thousands of applications is a demanding task and costs a lot.
What it does
Our solution is Duunitin. Duunitin offers various servicies for employers and job seekers. It utilises big data and machine learning to provide the following:
– Duunitin offers access to huge skill-profession-mapped database, which can be used to search for relevant professions based on experience or to figure out which new skills would gain most benefit for the job seeker.
– Duunitin has built-in Curriculum Vitae parser which handles PDF files. It also ranks CV’s based on certain job application and the employers preferences. Service also has support for summarisation of cover letters and other documents.
– Duunitin CV parser is based on machine learning, so it optimises itself countinously based on the user feedback.
How we built it
Duunitin’s core is based on huge database of profession titles and skills mapped to them. Most of the data is scraped from the European Commission’s database of European Skills and Competences. After fetching the data, we ran some matrix magic which produced us a database of 2900 professions, 13000 skills and over 100k of relations between them. Tool for job seekers is basically built on that data.
CV parser uses OCR and other tools to recognise text from the documents. It is then analysed by machine learning algorithm based on keywords and previous training. Keywords are selected from resumes and from the profession database. Based on these it provides an estimate how suitable the candidate is for the certain job.
Front end is built with React, back end uses Node.JS and some Python scripts.
Challenges we ran into
Getting data from the European commission ESCO database was exhaustingly hard. The database is complex and vast and we basically had to fetch everything to handle the data properly.
We also had some problems with defining our idea and scope – actually we had to refine our idea three times. While interviewing the partners of our challenge we found out some design flaws and had to return to the drawing board.
Collecting all the data and making searches from it was hard. This also caused problems with the machine learning mostly due to the complexity of it. Each occupation has skills which have relating skills that related to other jobs. This network was complex.
Parsing different kind of PDF documents was a mess.
Accomplishments that we're proud of
We are proud of the complexity of our product compared to the timeframe given. We have created a solution that has huge amount of potential applications in real life and we are happy about it!
Utilising the huge database was an enormous hurdle and when we got the correct data out from a total of thousands of rows we all jumped out of our chairs with excitement.
Parsing PDF’s is generally a hard task, but we got it to work with several test documents.
All in all gathering a working solution in a weekend makes up more than happy. Our team worked well together distributing tasks all around and we all still like each other in the end of the stressful hackathon, which is nice.
What we learned
Huge amount of things, e.g. maching learning principles, big data handling, OCR, hacking with Heroku. We tried several totally new things, but also we got actually some pretty good results and we’re proud of it.
What's next for Duunitin
rm -rf
npm init && git init --bare
Basically the first step would be cleaning the messy code, which is created under hurry and difficulties to have proper solutions. All the quick’n’dirty solutions should be done right.
The tool that parses CV’s and rates them is usable and has business value. It could be implemented e.g. in cooperation with some large company, so it could have more CV’s read in and the machine learning would be improved due to actual training. After first iteration it would definitely provide real help and save costs to the client.
Also the ESCO database could provide some useful information on for labour markets, however it would need much deeper research and better parsing methods, but the general idea of linking is good.






Log in or sign up for Devpost to join the conversation.