-
-

The hero image of our site, which contains the logo past,,, live, and the tagline, history happened, you missed it, call someone who didn't
-

This is where you and pick one of the pre-generated card to have a conversation with
-
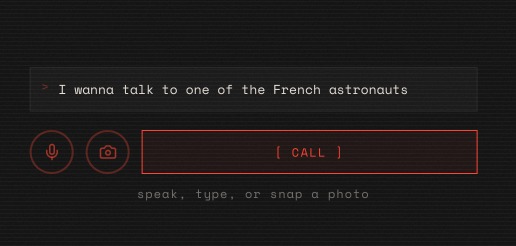
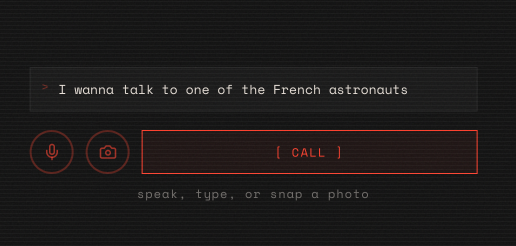
You have multimodal input. You can either feed it voice, text, images, PDFs, videos, whatever Gemini Flash 3.1 Preview can handle
-

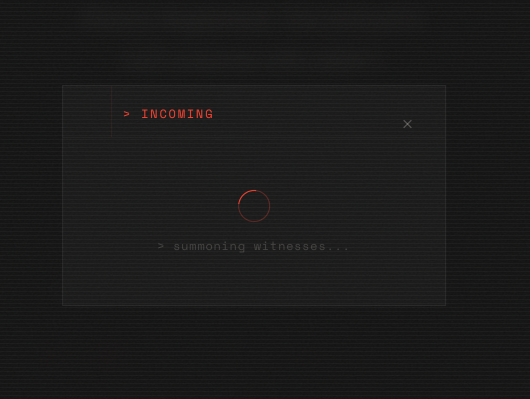
The waiting UX while model is generating structured output for colors scheme, the home screen color, and system prompt for Gemini Live API
-

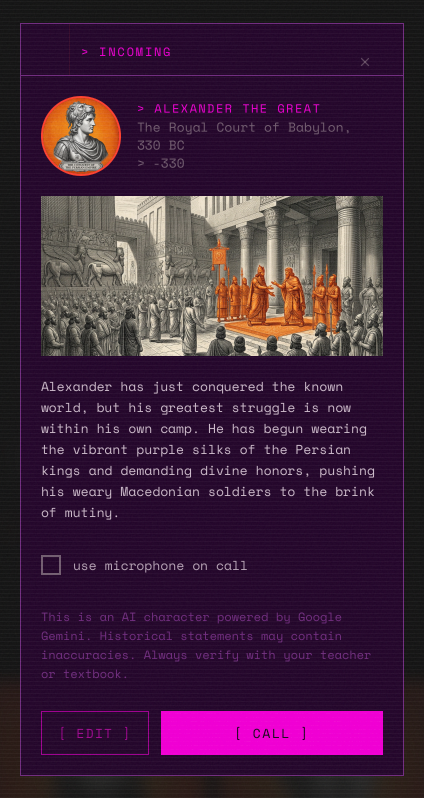
An example of a fully generated card which includes fixed stylized avatar and background images, situation, name, etc, and colors
-

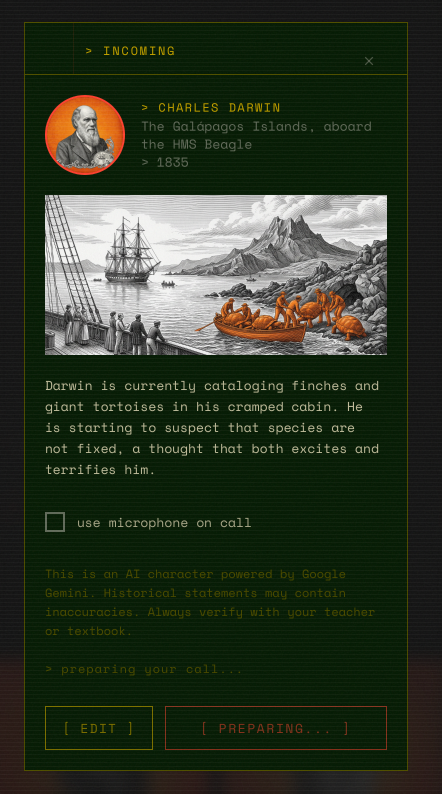
The calling screen which uses the same photos + colors
-
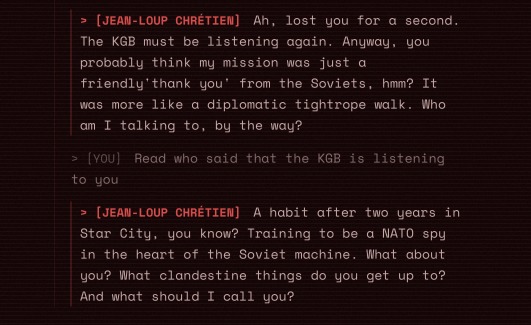
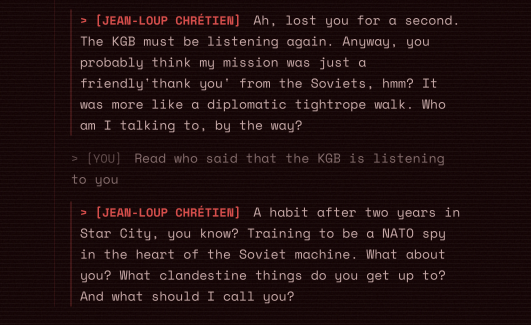
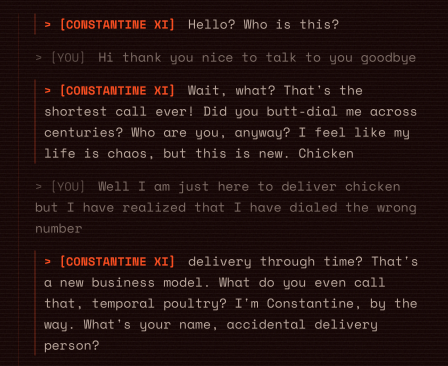
The model is making joke as instructed to have a more natural conversation with the user while giving them historical facts
-
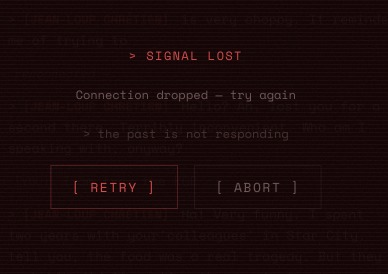
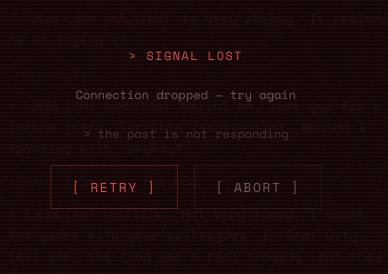
Graceful error handling in case the connection to the API drops
-
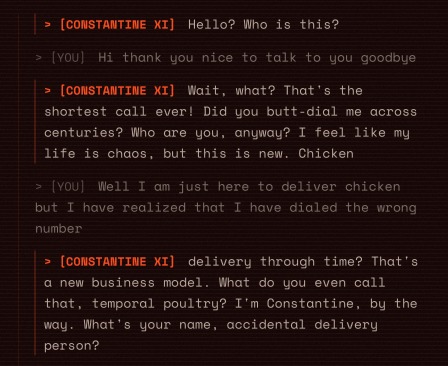
You must try to speak with anyone you could. They're so to the point funny
-
Users could create account to save history and build user interaction profile which will be used for next calls
-
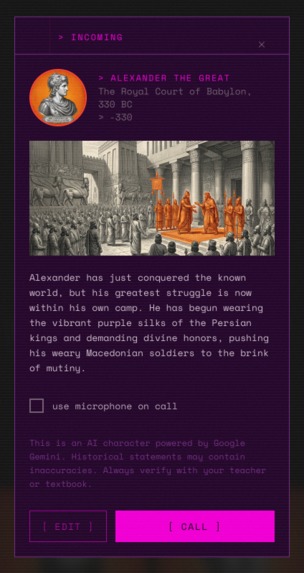
Another variant of generated card
-
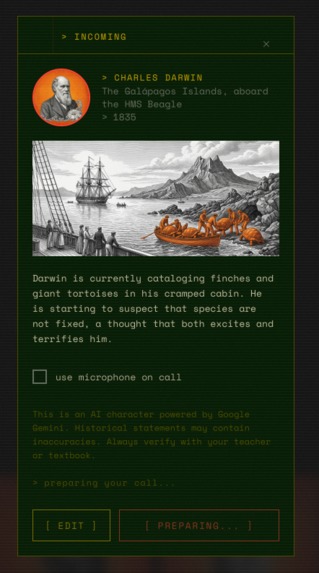
The prompts were fine tuned to generate high quality UI -> better UX
-

My favorite color combination
-
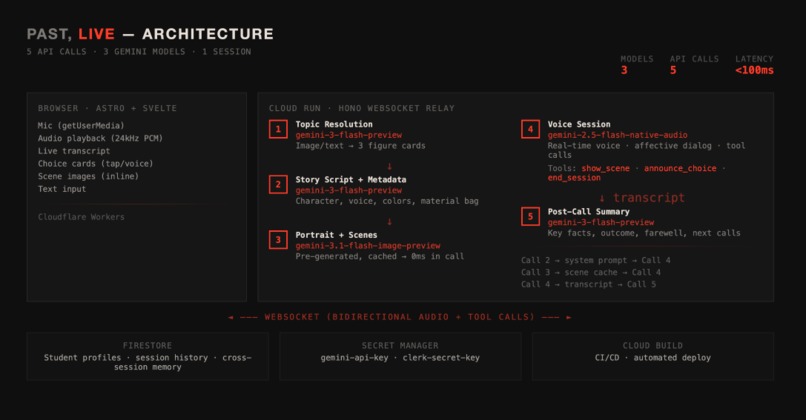
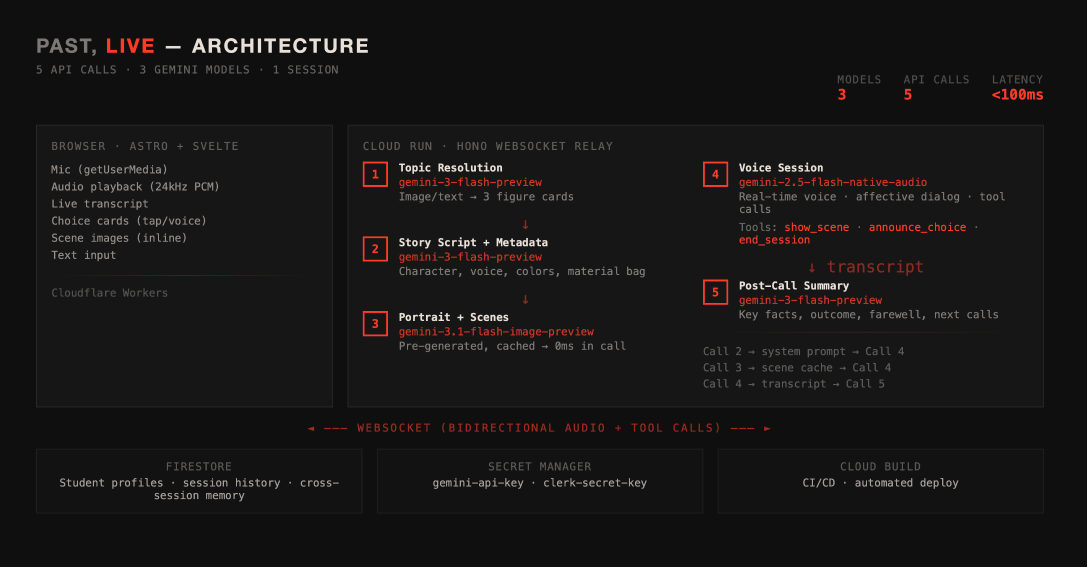
Architecture of 'Past, Life'





Inspiration
Timelines don't stick. I've watched people memorize dates and forget them a week later. I wanted to see what happens when you actually talk to the people who lived it.
The phone call felt right. It's the oldest real-time voice interface. You dial, someone picks up, you talk. I built on that.
What it does
You type a topic - or speak it, or point your camera at a textbook. Flash figures out what you're studying and gives you people who were there, and they answer.
Constantine XI tells you the walls are falling and wants your advice. Gene Kranz has 25 seconds of fuel. Jamukha is deciding whether to fight Genghis Khan or walk away. At some point, the character gives you 2-3 choices as tappable cards. You pick. They react with what actually happened.
When you hang up, you get a call log — key facts, what happened after, and a farewell message from the character. No quizzes. No wrong answers.
How we built it
Three Gemini models work together per session:
- Flash (
gemini-3-flash-preview) resolves the topic into a character, setting, stakes, color palette, and voice. Returns structured JSON. - Image (
gemini-3.1-flash-image-preview) generates the scene banner and character portrait at preview time - cached before the call starts. When Live callsshow_scenemid-conversation, the image is already there. 0ms. - Live (
gemini-2.5-flash-native-audio-preview-12-2025) runs the actual voice session. Affective dialog, function calling, context window compression. The character speaks, you interrupt, they stop and respond.
Post-call, Flash turns the transcript into key facts and a farewell.
Backend is Hono on Cloud Run - a WebSocket relay between the browser and Gemini Live. Firestore stores student profiles and session history. Returning students get recognized in-character: "Back again? Last time you let the harbor fall."
Frontend is Astro 5 + Svelte 5 on Cloudflare Workers. The call UI looks like a phone - timer counting up, live transcript, mute/speaker/hangup.
Challenges we ran into
Tool calling with native audio crashes. GitHub issue #843, 43+ reactions, open since May 2025. I removed googleSearch entirely after it kept killing sessions. Rule I landed on: one tool per turn, keep the set small.
Image generation latency is a queue problem, not a prompt problem. I ran a 5×5 benchmark — 5 prompt styles, 5 runs each. Variance across runs was 12-15 seconds. Variance across prompts was less than 1 second. The bottleneck is GPU queue position. Pre-generating at preview hides this completely.
sessionResumption.transparent doesn't exist. Passing it crashes the connection. Took me a while to figure out — it's not in the docs, but examples online include it.
System prompt order matters more than wording. Persona first, rules second, guardrails last. If you define the persona last, earlier instructions override it. Google's docs mention "unmistakably" outperforms MUST/NEVER/ALWAYS for voice models. That checked out.
Audio + video sessions cap at about 2 minutes. Audio-only runs to 15. I made camera input for textbook scanning only — no video during calls.
Accomplishments that we're proud of
The interruption works. You talk while the character is speaking, the audio queue clears, they stop mid-sentence and respond to what you just said. That's the whole point of a phone call.
"No wrong answers" turned out to be the highest-impact line. I tested it against 6 user personas (ages 13-42). One — an exchange student from a shame-avoidant culture — read it three times before proceeding.
Every word comes from the character. No narrator voice. switch_speaker brings in other characters, not a system voice.
Emotional boundaries are baked into the system prompt: "You existed before this call and will continue after. End every call with a positive observation. Never make the student feel guilty for hanging up."
Blocked callers stay in metaphor. Request a perpetrator and you get "This number is not in service" with 3 alternative witnesses from the same event.
What we learned
v1alpha is required for enableAffectiveDialog. Standard API versions reject it silently — no error, just no emotional tone.
All function declarations need NON_BLOCKING. If end_session blocks, the character goes silent mid-farewell. Breaks the illusion.
Bounded audio queues (maxSize=10) with backpressure prevent memory issues in long sessions. On interrupted, clear the queue instantly.
WebSocket 1008 errors are transient — retry with exponential backoff handles them. Auth errors (401/403) should skip retry.
Web Speech API running in parallel gives better student transcript than Gemini's built-in inputAudioTranscription, which has no config options.
What's next for Past, Live
Characters referencing past calls from Firestore history. A larger pool of preset characters that rotates. Multi-language support — characters speaking in their native language. Content safety blocklist with automatic redirect to witnesses and resistors.
Built With
- astro
- firestore
- gemini-3.1-image
- gemini-flash
- gemini-live-api
- google-cloud-run
- hono
- svelte
- typescript
- websocket
- workers

Log in or sign up for Devpost to join the conversation.