-
-

PASH Team
-
PASH Landing Page
-
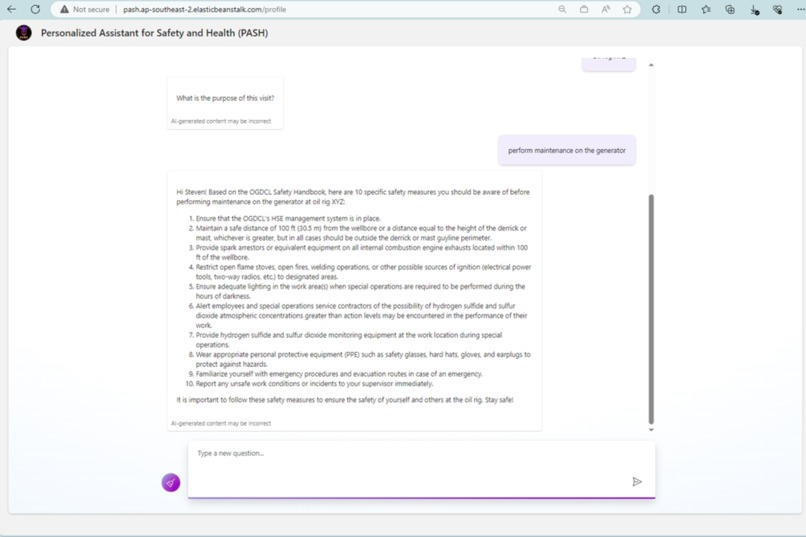
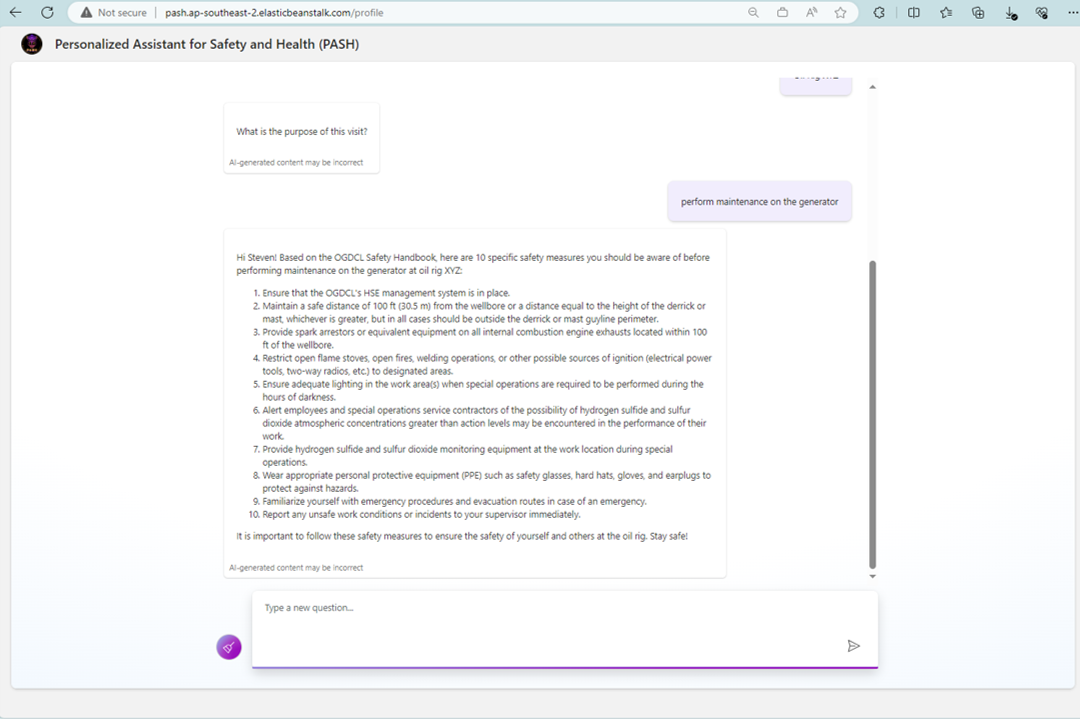
PASH Sample Conversation
-
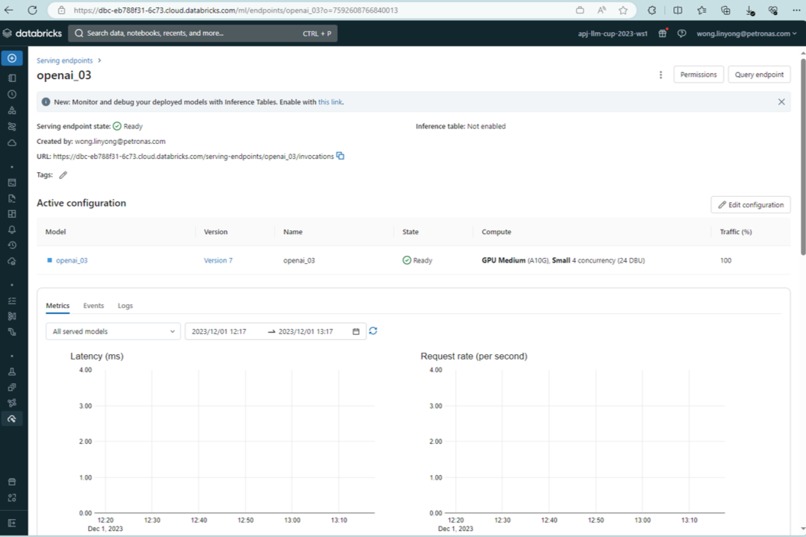
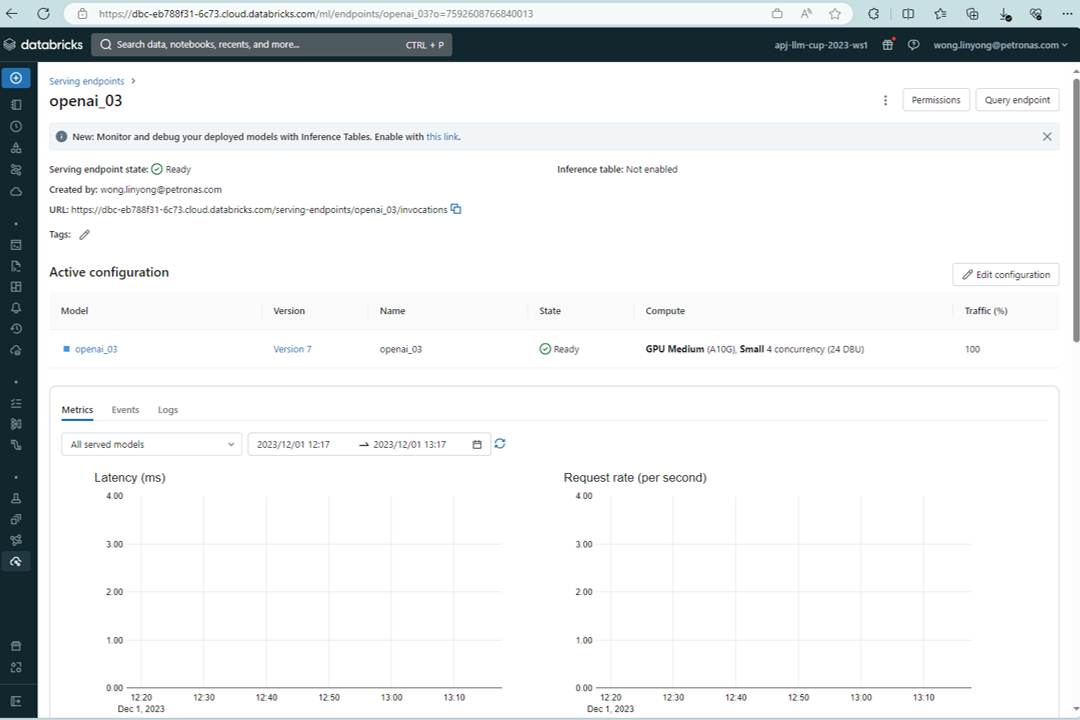
Databricks Serving Endpoint
-
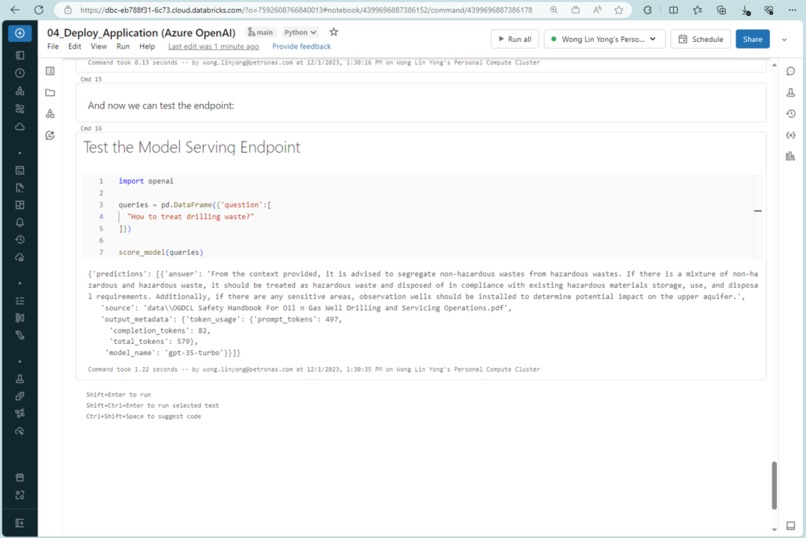
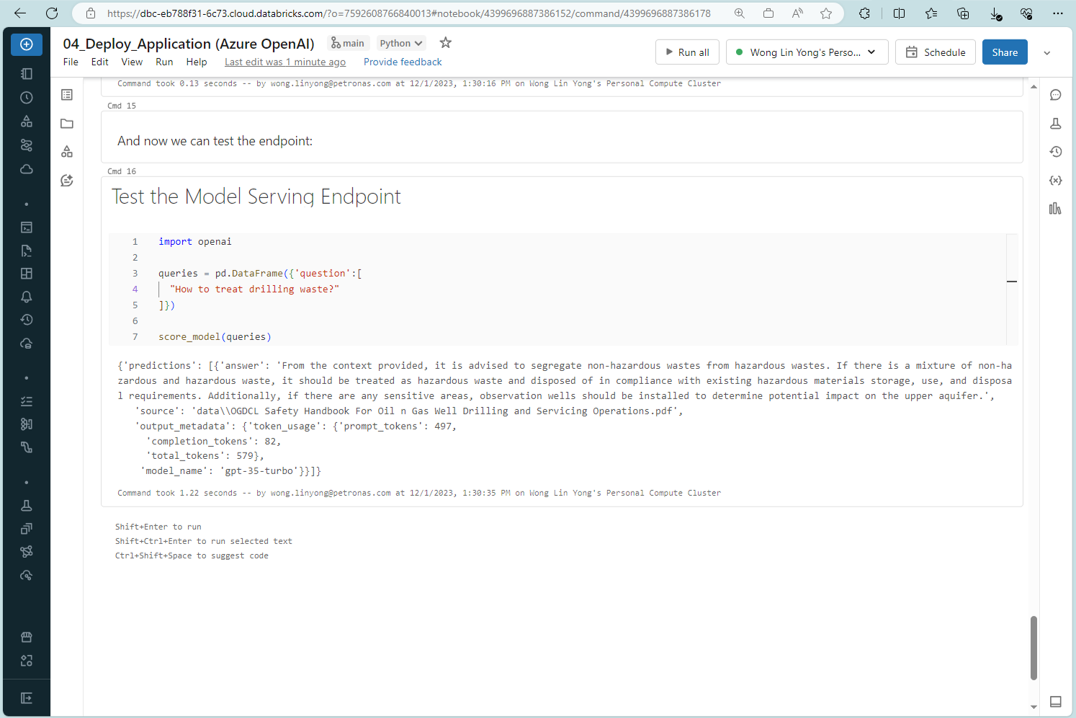
Databricks Serving Endpoint Testing


1.0 Inspiration
Upon arrival to a certain work location, most new and experienced engineers, technicians, and staffs are not fully aware of the safety checklists and policies related to the designated work location that may lead to accidental breaching and non-compliance in adhering to the safety measures. As there are no platform and libraries of the guideline on the staffs’ fingertips, most staffs had to go through the process of retrieving the required guideline or knowing it heart. The average minutes taken for staffs to gather safety related information and guideline may take more than thirty (30) minutes during both working and nonworking hours that can lead to delayed in exercising the safety regulations.
This can be used to describe a current pain point within the organization that may need to be addressed. Note that the statement specifies that the issue occurs within those staffs who have no access to immediate articles and guidelines that is related to the Health, Safety, Security and Environment during the company’s working hours as well as the nonworking hours. This is helpful in performing the root cause analysis and determining how this problem can be solved.
Problem:
- The average minutes taken for staffs to gather safety related information and guideline exceeds thirty (30) minutes during both working and nonworking hours that can lead to delayed exercise of the safety regulations.
- Most companies do not have any open platform and libraries of the guideline on the fingertips, that the staffs can refer to thus, most staffs had to go through the lengthy process of retrieving the guideline from a specific group.
Background:
Example company is facing a significant challenge in retrieving the related articles related to HSSE for a quick reference to assist in decision making. Currently, the company had designated team that manages all inquiries, retrievals and summarizing HSSE related cases for the company to refer to for decision making purposes, however, due to a combination of factors, including the overwhelming request and the delays in retrieving the articles that exceeded 30 minutes consistently. This has resulted in frustration and dissatisfaction among staffs, negatively impacting the decision making that may lead to safety related cases occurs
2.0 What It Does
PASH reduce the searching, retrieving and summarizing the HSSE related articles process. Prolonged retrieving times have a detrimental effect on staffs productivity, satisfaction and confidence, leading to potential delays in decision making that might lead to legal cases, non-compliance and loss of revenue for the company. Addressing this problem is of utmost importance to improve staffs experience and maintain a positive brand image for the HSSE cultures practiced by the company.
Objectives:

The primary objective of this project is to reduce the retrieval times for staffs to search, retrieve, summarized and comparing articles in relates to HSSE. The specific objectives include:
- Analyzing the current staff's retrieval workflow and identifying bottlenecks contributing to the increasing on retrieval times.
- Notifying the safety measures required to be taken by the staffs in work locations.
- Developing strategies and implementing measures to optimize the retrieval workflow and reduce retrieval times.
3.0 How We Built It
After brainstorming the identified problem, we came out with the idea of leveraging the Large Language Model (LLM) to build a chatbot in sorting out user queries regarding safety issue.

First, we gathered the relevant oil and gas safety data and upload to AWS S3 bucket, followed by chunking via LangChain library. These data will be embedded to create a vector database in Databricks to perform similarity search with the user queries afterwards. Next, we fetch the relevant information from the search to perform further enhancement via instruction led LLM model to refine the output. The overall model is registered in Databricks MLflow, where we use the MLflow model to create our endpoint in Databricks.
After that, we built a website on top of Python Flask in AWS EC2 server deployed in Elastic Beanstalk to serve as a landing page for the chatbot. The website is used to receive the user inputs while conversing with the model at the backend via the serving point that we have hosted in Databricks.
Throughout the hackathon, we tried with the following model:
| Sources | Embedding Model | Instruction Led LLM Model |
|---|---|---|
| Azure OpenAI | text-embedding-ada-002 | gpt-35-turbo |
| Hugging Face | S-PubMedBert-MS-MARCO | llama-2-7b-chat |
Based on our findings, Azure OpenAI provide a more accurate context with a relatively faster response.
Here are some of the snapshots of the Azure OpenAI Setup to be compatible for MLflow model deployment.
Embedding Models:
embeddings = OpenAIEmbeddings(
deployment=OPENAI_ADA_EMBEDDING_DEPLOYMENT_NAME,
model=OPENAI_ADA_EMBEDDING_MODEL_NAME,
openai_api_base=OPENAI_DEPLOYMENT_ENDPOINT,
openai_api_type="azure",
openai_api_key=OPENAI_API_KEY)
Instruction Led LLM Model:
llm = AzureChatOpenAI(deployment_name=OPENAI_DEPLOYMENT_NAME,
model_name=OPENAI_MODEL_NAME,
openai_api_base=OPENAI_DEPLOYMENT_ENDPOINT,
openai_api_version=OPENAI_DEPLOYMENT_VERSION,
openai_api_key=OPENAI_API_KEY)
4.0 Challenges We Ran Into
While deploying a serving endpoint in Databricks, we faced the challenge in identifying the essential environment variables required for the model, where we could not retrieve from the error message that showed only the general OpenAI error which is not applicable to Azure OpenAI. After a thorough review of the LangChain Azure OpenAI documentation, we successfully identified the precise environment variables needed for smooth deployment.
Another hurdle emerged during the testing phase when we observed instances of bot hallucination. The bot occasionally provided inaccurate or unrelated information, prompting us to delve deeper into refining our approach. After multiple rounds of testing, we discovered that the formulation of a well-crafted prompt plays a pivotal role in shaping the personality and behavior of the model.
5.0 Accomplishments that We're Proud of
- Successful implementation of Azure OpenAI in the Databricks MLflow model.
- Integration between the Databricks serving endpoint and a Python Flask application.
- Established chatbot continuity via chat history for a better understanding of user queries.
- Chatbot configuration where the response has been personalized based on their position, location, and purposes.
6.0 What We Learned
As a noteworthy suggestion, we explored the possibility of utilizing open-platform sources, such as Github or open platform cloud, for importation into Databricks DBFS, rather than relying solely on S3 buckets.
We also learnt that optimal text chunk size is crucial for improving response quality. Larger chunks offer more context, enabling the model to generate responses considering a broader scope. Conversely, smaller chunks may limit context, leading to narrow or disconnected responses. Finding the right size depends on the task, requiring experimentation to fine-tune inputs for optimal outcomes. This iterative process is essential when working with language models.
We also had our proof of concept to implement Azure OpenAI in Databricks MLflow model and serve it to the internet via Databricks serving endpoint. We had the opportunity to explore the end-to-end process from setting up the model up until deploying it in Databricks. From technical part, we learned that to achieve chain of thought, integration of chat history is required to maintain the continuity of the conversation with the bot. This enables the model to maintain a coherent and evolving dialogue, improving its ability to understand user intent and context.
Then, a well-crafted system prompt is important to prevent the bot from hallucinating. Good quality of prompt can be built through several rounds of test to allow the bot to produce more meaningful and engaging interactions.
Lastly, the indexing method used in this hackathon is proven effective to create a custom data chatbot without computational extensive fine-tuning process.
7.0 What's Next for PASH
As a continuity of this project, we have proposed the following to further enhance our application in the future.
1) Integration with Roster System
To automate population of user details to the bot, PASH can be integrated with company roster system so that PASH could provide immediate safety guideline to the user in a faster way prior to entering the workspace.
2) Speech Recognition System
With speech recognition intact, user is able to communicate with PASH via voice so that they could receive a faster response while performing their work in their designated area.
Please reach out to pash.safetyassistant@gmail.com for the access to the demo page. Thank you.
Built With
- amazon-ec2
- amazon-web-services
- azure
- css
- databricks
- elasticbeanstalk
- flask
- huggingface
- langchain
- mlflow
- openai
- python




Log in or sign up for Devpost to join the conversation.