-
-

-

-
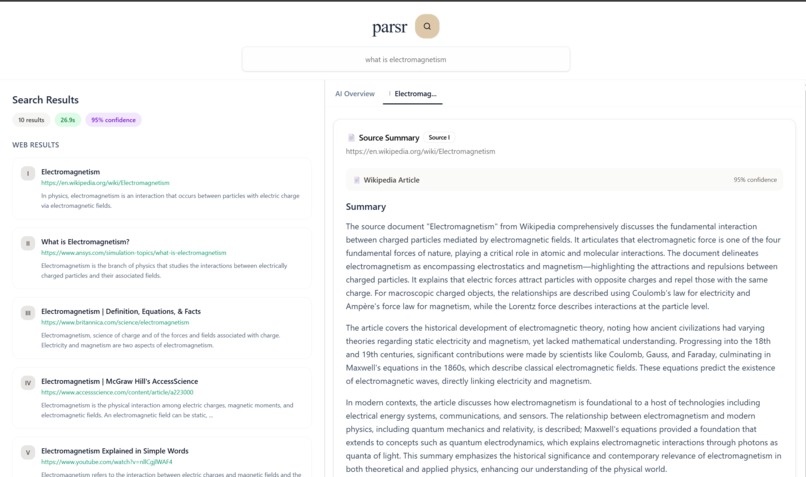
response
-
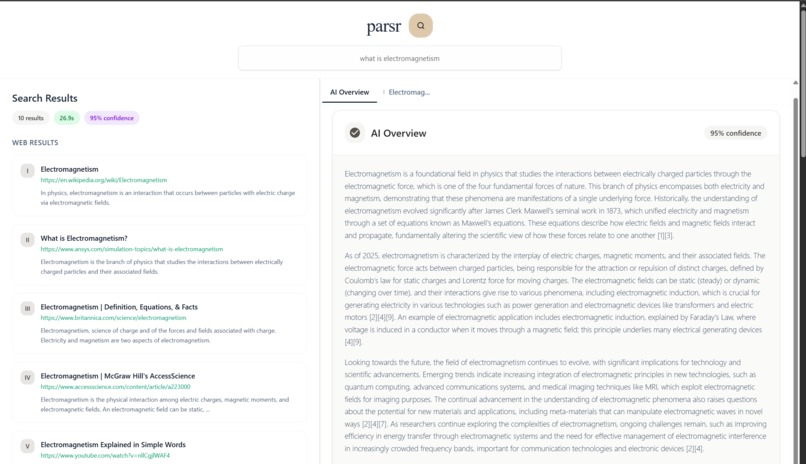
source summary


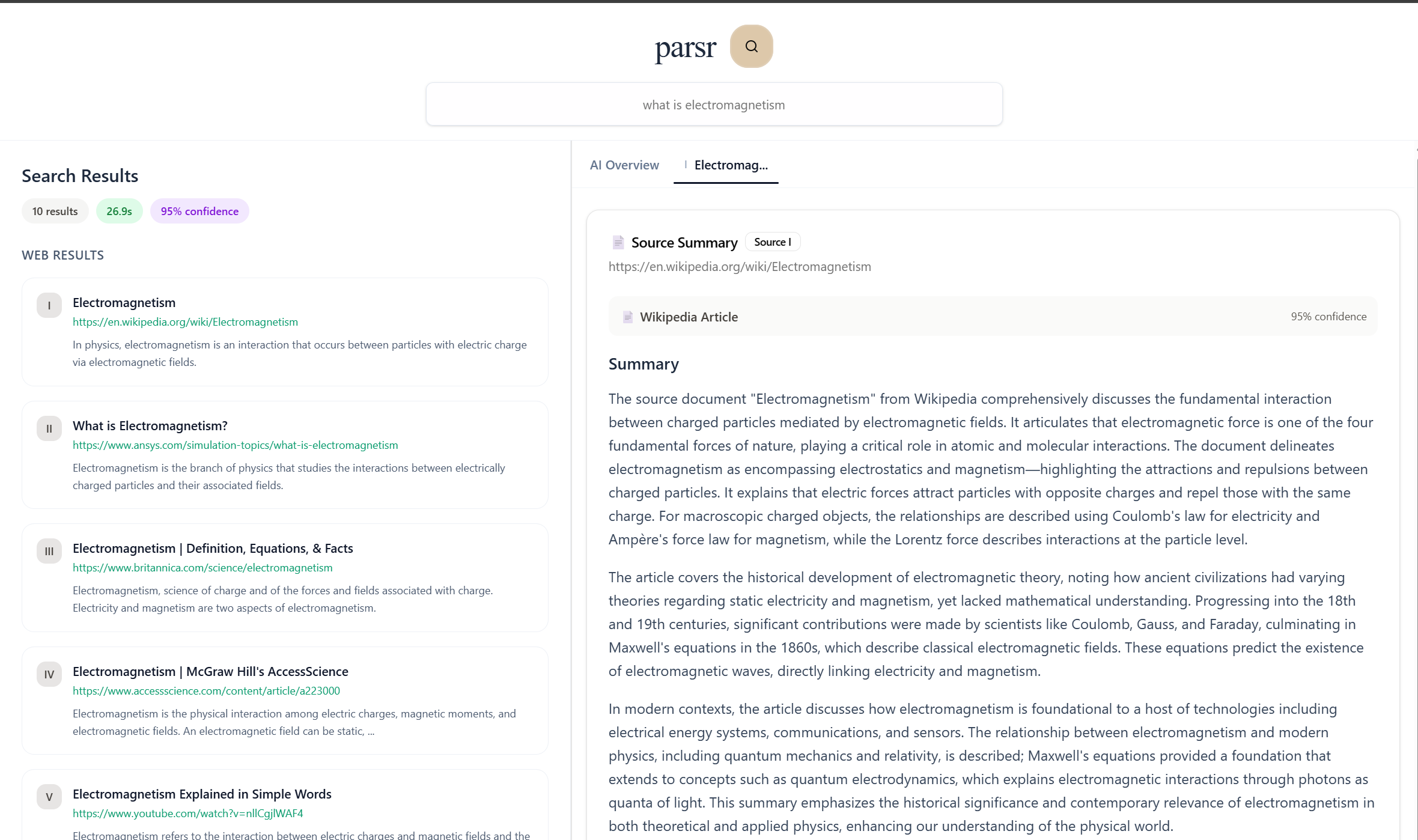
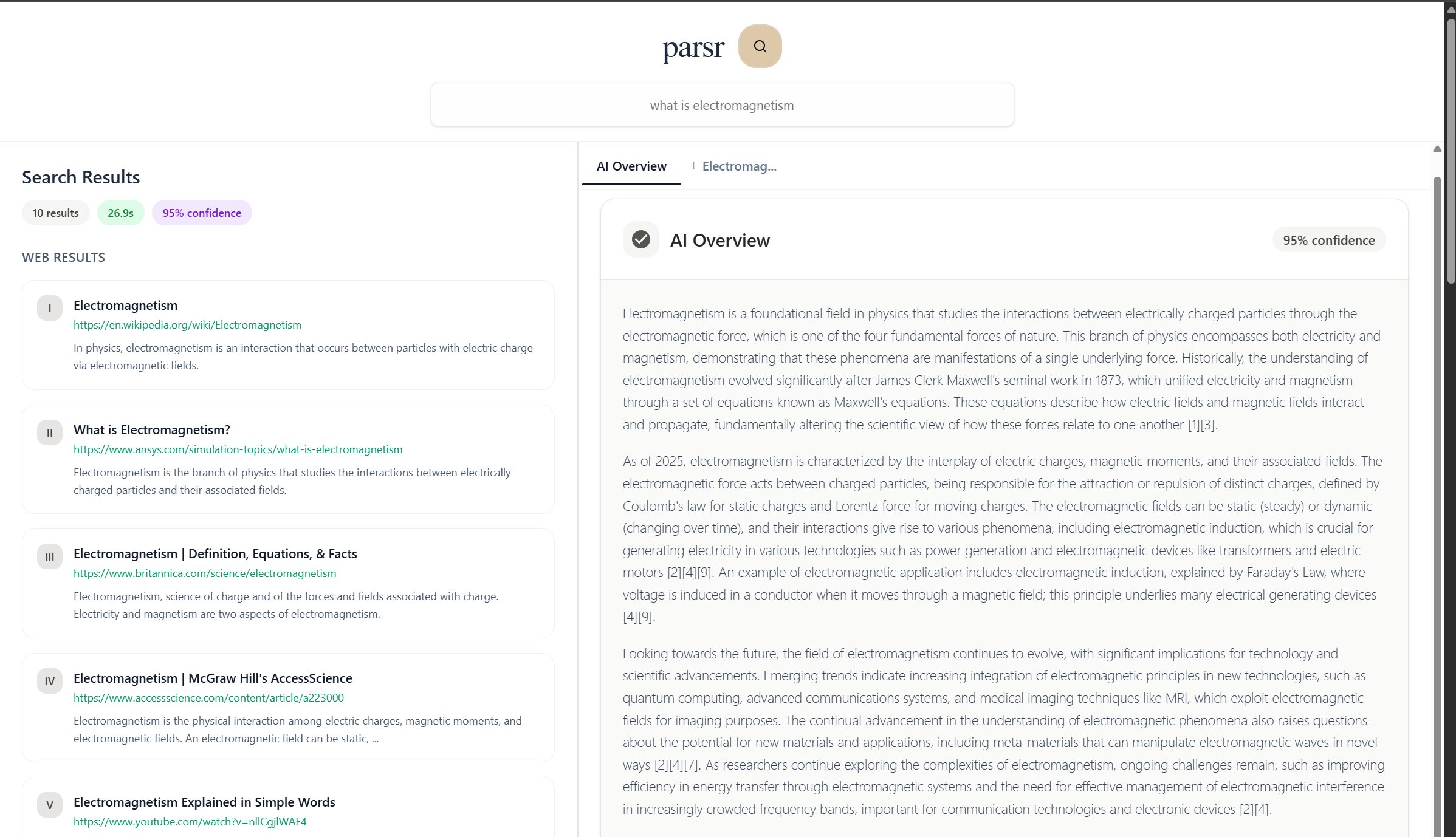
Inspiration
Over a billion people use Google Search worldwide, but ads and irrelevant information riddle search results and the AI overview feature. In addition, Google serves as a general knowledge search engine, where the algorithm can skip over research sources while promoting SEO slop.
What it does
Parsr utilizes Qdrant, a vector database, to retrieve semantically similar vectors found in the database to build relevant LLM results. Parsr prioritizes embedding research-based sources, ensuring users are faced with accurate information with every question. Furthermore, Parsr embeds ten additional vectors for each query, increasing the number of relevant sources with increased use.
How we built it
Stack-wise, we used Python for our AI/data pipeline and Next.js for the frontend. The backend utilizes Serper API to retrieve Google search results, the MiniLM v2 sentence transformer to create vectors of queries and results, and semantically searches against existing vectors using cosine similarity, an algorithm used by Qdrant to return truly relevant source responses. The reason this yields better results is through layers of QKV (query, key, value) matching that allows LLMs to "understand" word relationships and thus the purpose of the user's query, returning results that have the highest similarity between query and key vectors.
Cosine Similarity Formula
$$\cos(\theta) = \frac{\mathbf{A} \cdot \mathbf{B}}{|\mathbf{A}| |\mathbf{B}|}$$
Challenges we ran into
Choosing the number of relevant vectors to pull from the database to build a detailed, yet concise, summary for an educated non-expert audience. Setting up the domain and ensuring that merge conflicts were resolved were also a pain that we eventually got over.
Accomplishments that we're proud of
Connecting the frontend and backend into a comprehensive application that actually functions on a domain. In addition, we collaborated pretty nicely, with work being evenly split on both ends and promises about deadlines being kept.
What we learned
We learned a lot more frontend (React, Shadcn, and Reactbits to improve design), and also experimented with vector databases such as Pinecone and Qdrant, which we ultimately incorporated in our program. We also delved into exactly how vector databases could improve search retrieval quality and how they functioned mathematically under the hood - we wanted to make sure this tech was legit.
What's next for parsr
We plan to polish with ui, have it integrate properly as a search engine in the browser (extension potentially), and speed it up considerably; parsr currently has an average runtime of 40s per query due to a lack of financial resources for professional web scraping and anti-botting systems. Additionally, we both want to work on it in the near future by improving search capabilities and incorporating research-focused APIs to extract more peer-reviewed papers.
Built With
- next-js
- openrouter
- python
- qdrant
- serper
- typescript

Log in or sign up for Devpost to join the conversation.