-
-
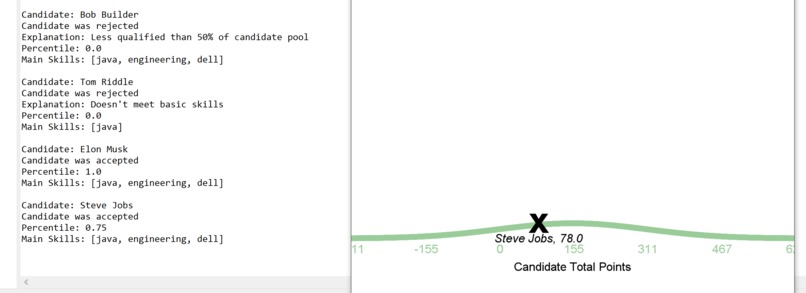
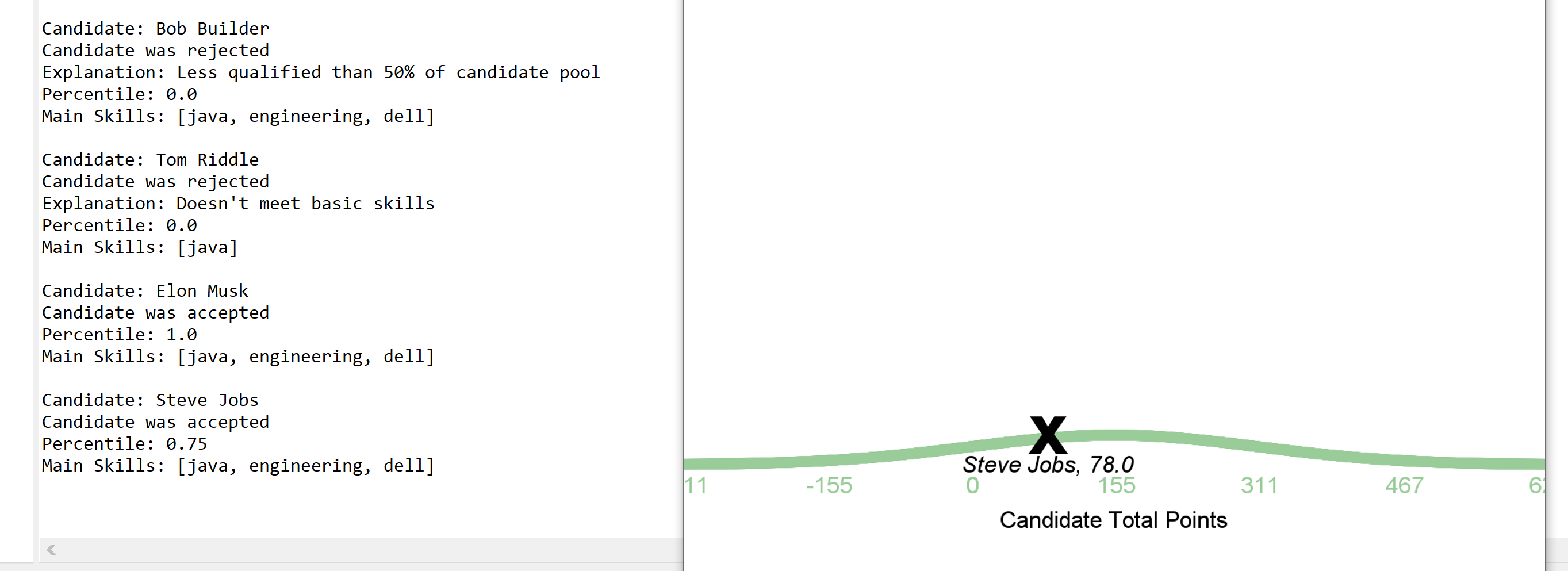
Bell Curve printed out for each candidate
-
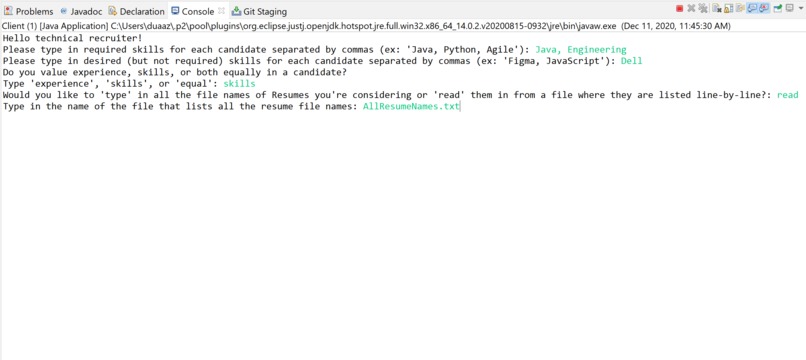
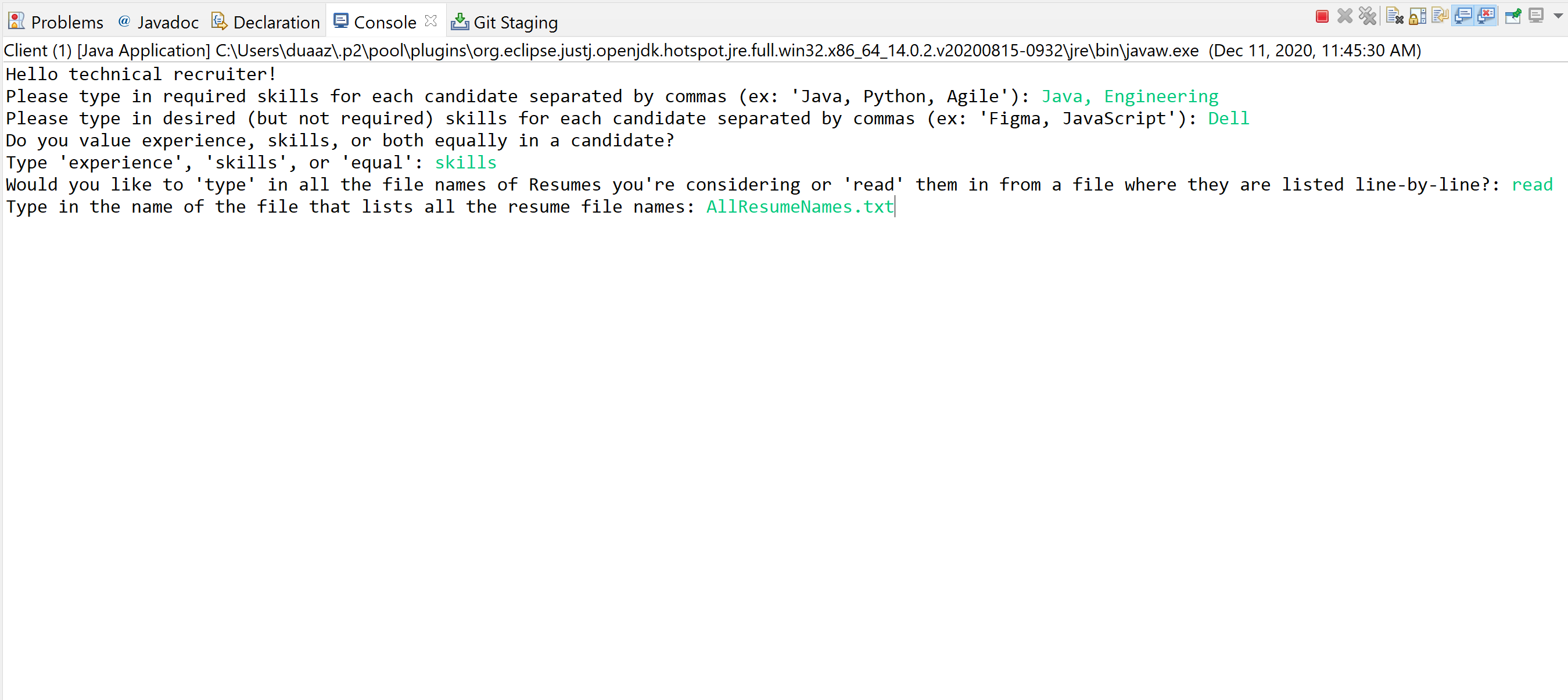
Recruiter given options to choose their evaluation methods
Inspiration
For recruiters who are looking for candidates in a large pool of resumes, it can be difficult to parse through and find candidates who have the right skillsets they are looking for. We wanted to create a tool that can help recruiters sort through candidates easily and find the right fit for their company!
What it does
Recruiters are prompted to enter in required and desired skills or keywords they are looking for in resumes, and whether they value length of experience associated with those skills or the skills themselves more (this determines how we weight the amount of "points" a candidate receives). Parsely then parses into uploaded resume files and prints out evaluation results for each resume in the candidate pool with information such as their name, whether they were accepted/rejected (candidates are rejected if they don't meet the basic skillsets or if they fall under the 50th percentile for the pool as a whole based on points), the percentile they fall under, and a list of the skills we parsed from their resume. Additionally, we used the Princeton StDraw package to generate graphical bell curves for each candidate using the mean and standard deviation of candidate points.
How we built it
We created a Resume class to parse into each resume, an Algorithms class to evaluate candidates and compare Resume objects to each other based on length of experiences and/or skills, a BellCurve class to generate the graphical bell curves using StDraw, and a Client class with the main method for the recruiter to interact with.
Challenges we ran into
Because we were taking on so much information from each resume, it was common for us to run into random NullPointer Exceptions for odd cases of keywords, which often caused a lot of confusion. We also had to improve our GitHub skills to work collaboratively.
Accomplishments that we're proud of
We have a working Resume Parser and what makes it really interactive is the fact that you can see a bell curve for each candidate which actually places where they fall onto the curve based on their total points.
What we learned
We've significantly improved our knowledge of HashSets, HashMaps, GitHub, and using graphical interfaces through tools such as StDraw!
What's next for Parsely
We plan to continue looking for any bugs and optimizing Parsely to work for resumes with varying formats and dates (people around the world might input their dates on resumes a little differently).
Built With
- java
- stdraw




Log in or sign up for Devpost to join the conversation.