-
-
Individual Patient Data
-
-
-
IntroScreen
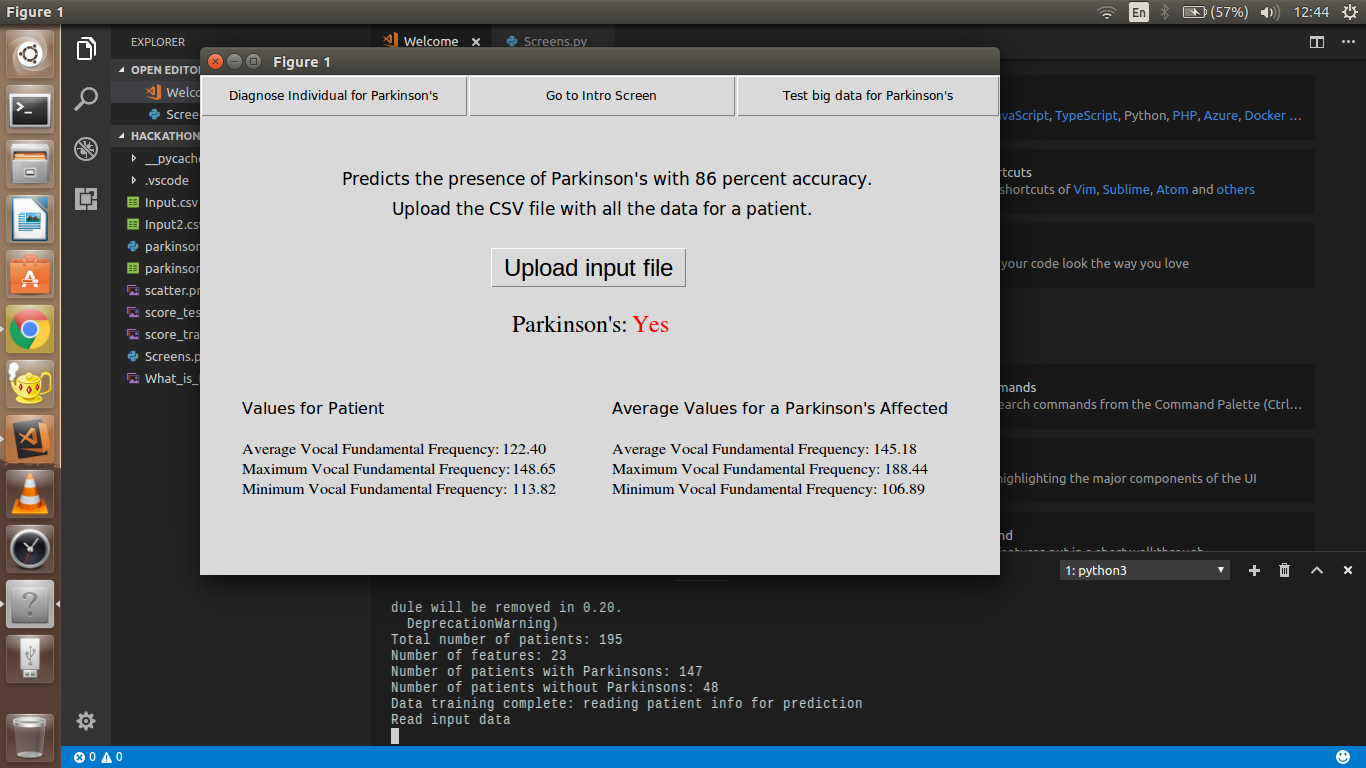
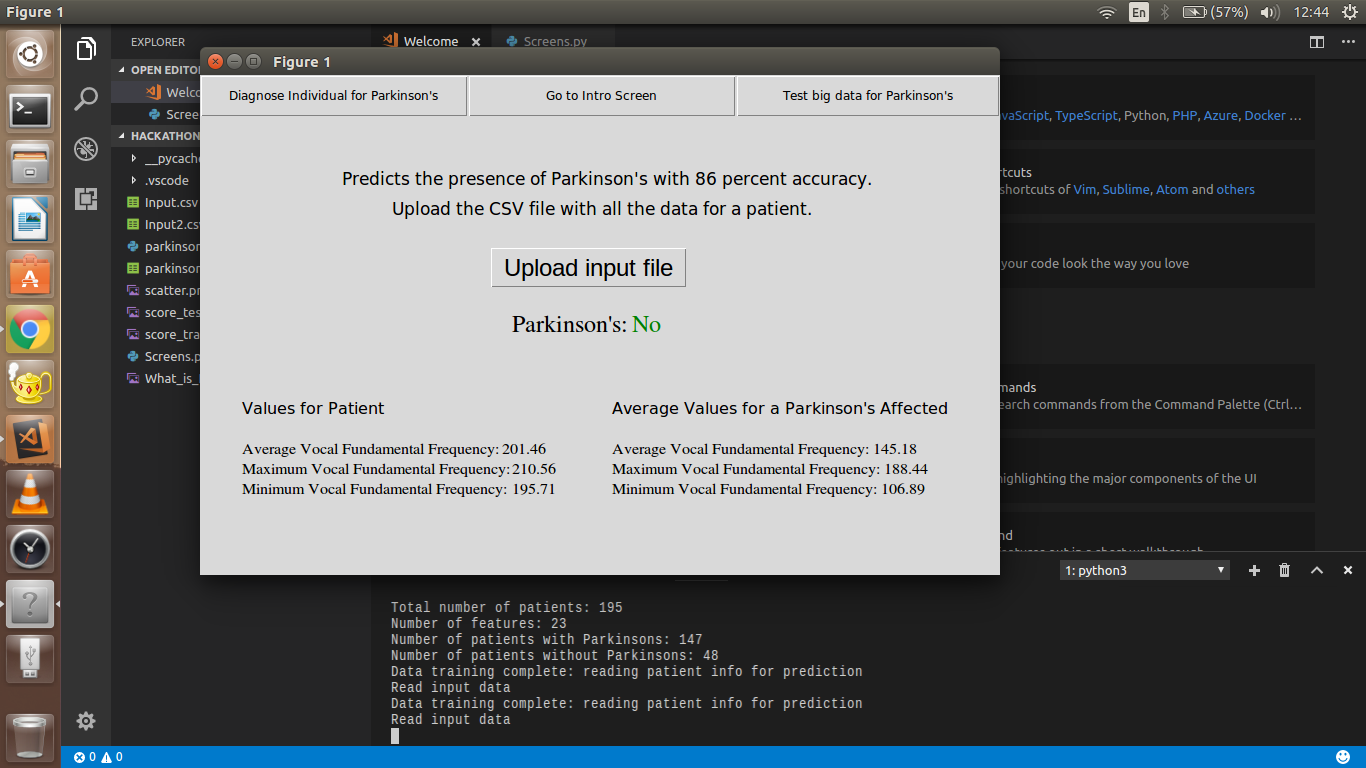
ParkinsonAnalysis
NOTE: To run the program, enter the command "python3 Screens.py" from the program directory in your terminal.
A program that uses Machine Learning and Regressions to predict the presence of Parksinson's Disease in a patient. It can be used by doctors who can enter the observations for a patient in a CSV file, and the program can then read the CSV file to predict the presence of Parkinson's. The regression is constructed on the basis of a dataset published in the UC Irvine Machine Learning repository. The dataset was created by Max Little of the University of Oxford, in collaboration with the National Centre for Voice and Speech, Denver, Colorado, who recorded the speech signals.
For more info about the database, go to: https://archive.ics.uci.edu/ml/datasets/parkinsons
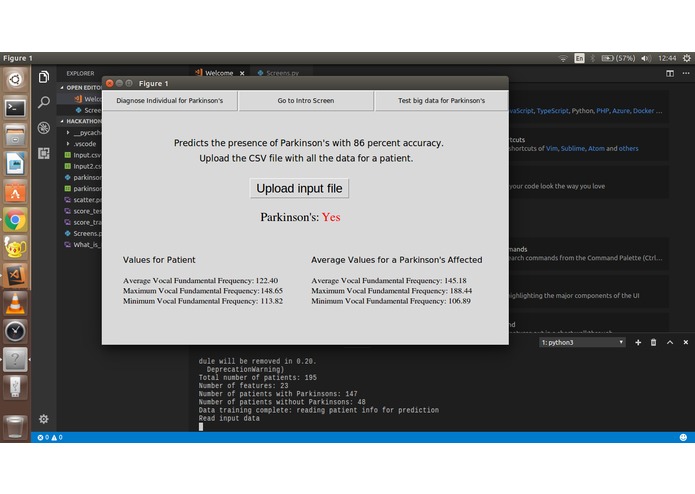
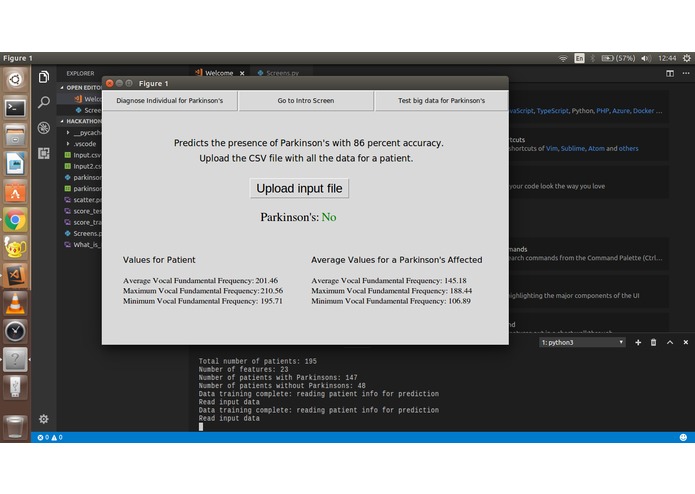
The program has two modes: one to predict Parkinson's in an individual patient (based on an input CSV) which uses a Simple Tree Regression Model to classify patients on the basis of their measurements. The measurements are fitted against the values from the main database.
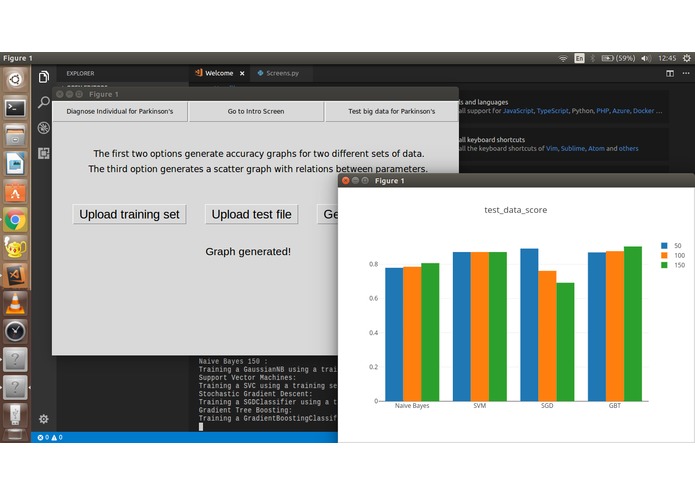
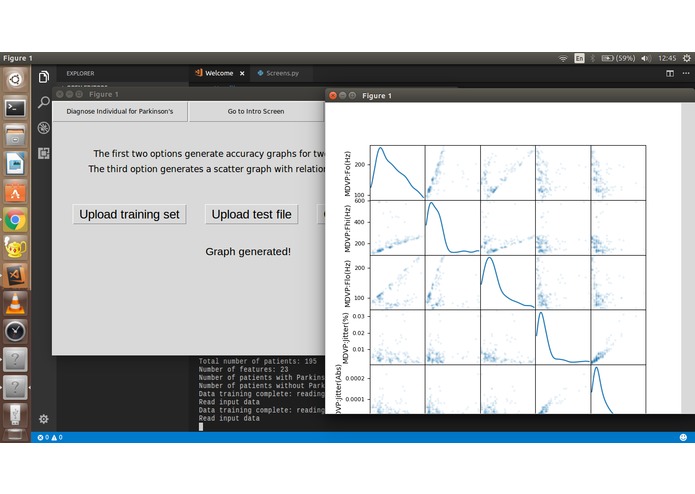
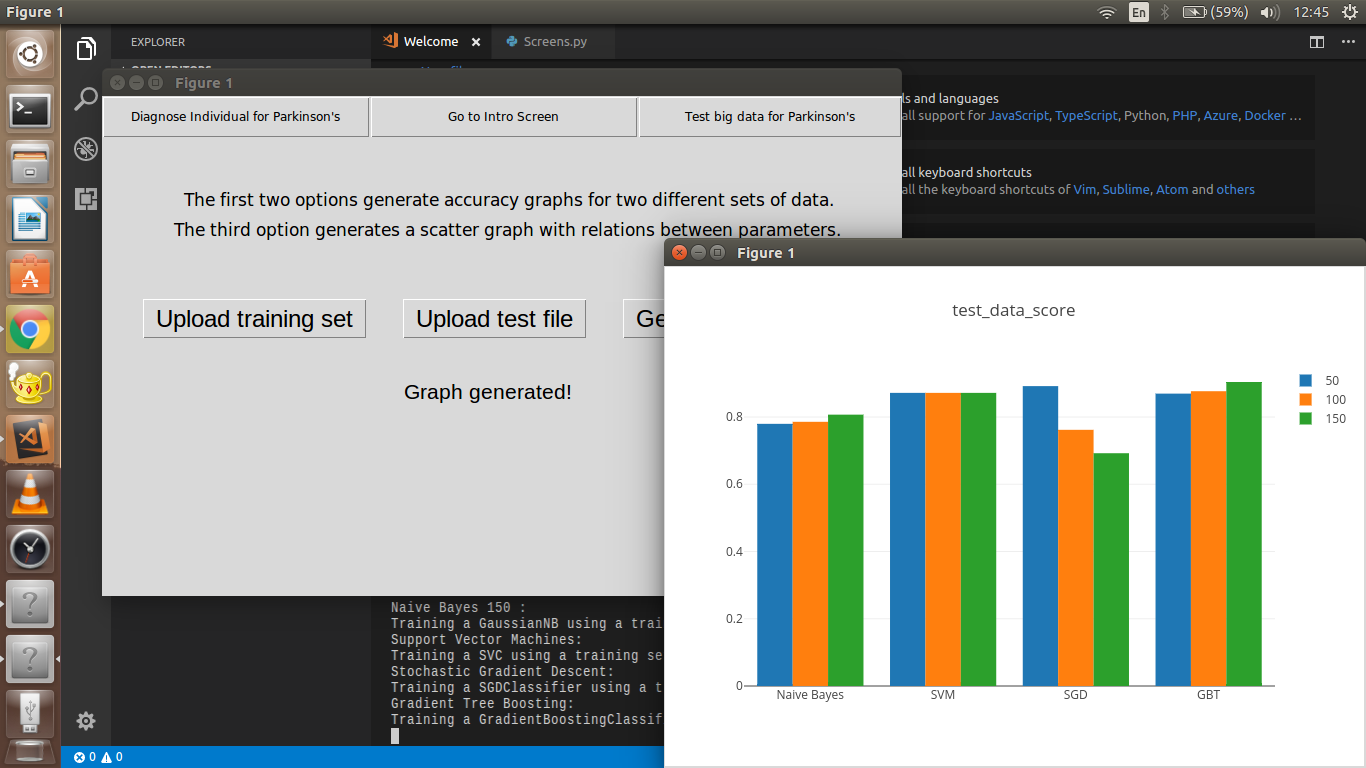
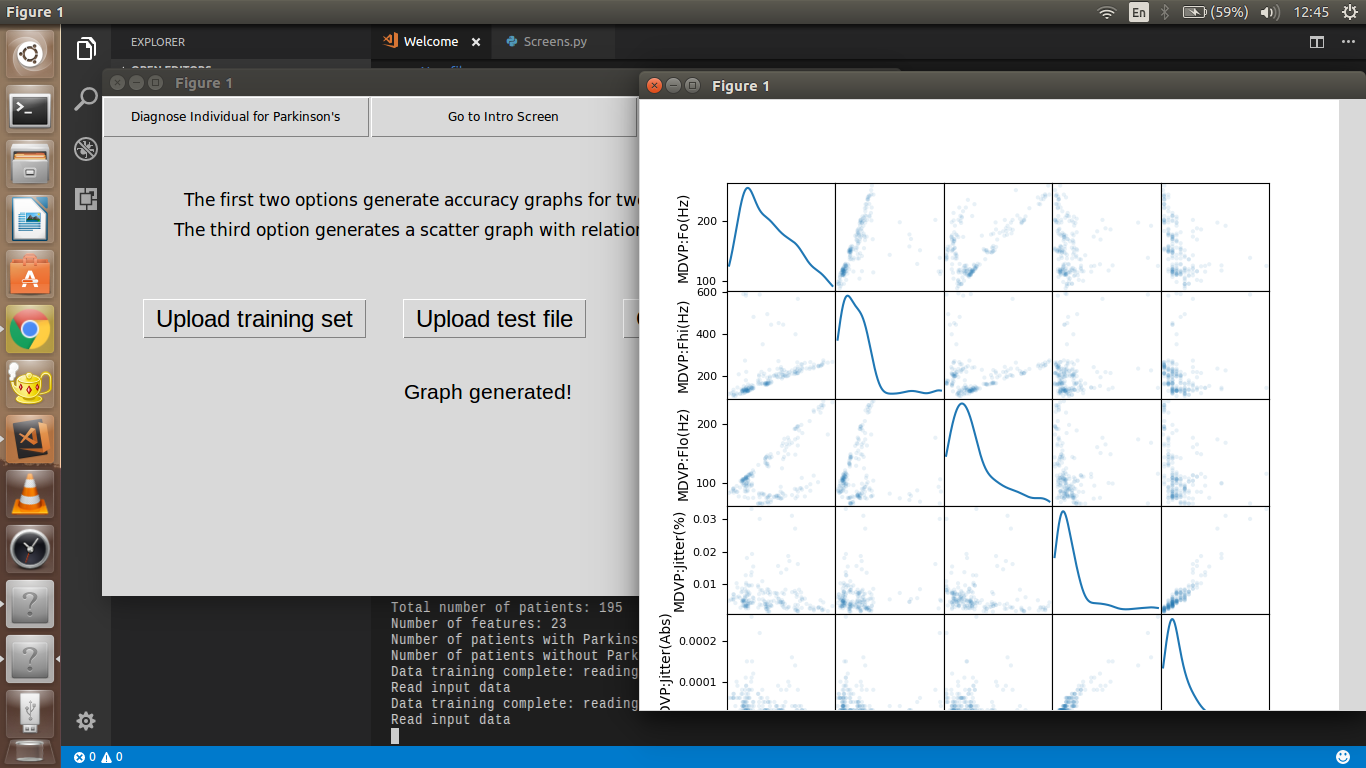
The second mode is used with the entire original database, creating a model based on the accumulation of four distinct ML algorithms, which are: Support Vector Machine (SVM), Stochastic Gradient Descent Classifier (SGD), the Gaussian Naive Bayes (NB), and the Gradient Boosting Classifier. The results from the four are collated over three distinct datasets having 50, 100 and 150 values respectively. There's also an option to display a Scatter Matrix to show the relationships between the parameters of the original dataset.
The UI has been developed by using the Tkinter extension in Python.
The app can greatly help doctors confirm the presence of Parkinson's in their patient by just inputting some known parameters, and the program then compares the parameters to a trusted dataset and predicts the presence of the disease.
Naïve Bayes: A classifier that makes use of Baye’s theorem to try and classify data. The use of Baye’s equation makes use of the likelihood of a specific classification based on probabilities returned from the features of the data. I decided to implement this classifier as it is known to only require a small training set to estimate parameters and is not sensitive to irrelevant features.
Support Vector Machines: A classifier that categorizes the data set by setting an optimal hyper plane between data. I chose this classifier as it is incredibly versatile in the number of different kernelling functions that can be applied. I hopes are that when tuned, this model can yield a high predictability rate.
Stochastic Gradient Descent: A classifier that applies the concept of gradient descent to reach an optimal predication rate. I chose this classifier because it has multiple parameters that could potentially be tuned if it produces strong results under my data set. My main concern is that it tends to work well with sparse data, but is sensitive to larger training sets.
Gradient Tree Boosting: An ensemble classifier (combines predictions of base estimators) that makes use of multiple decision trees - giving their contributions weights – to classify data. The weights are developed using the gradient descent algorithm. I decided to implement the GTB because of its strength in handling heterogeneous features and high accuracy. The problem I do expect with this classifier is that it scales poorly and so with larger sets of data, this would not be optimal. It is still interesting to see the results of this classifier however.
Built With
- machine-learning
- matplotlib
- numpy
- pandas
- python
- scipy
- sklearn
- svm
- tkinter


Log in or sign up for Devpost to join the conversation.