-
Landing page
-
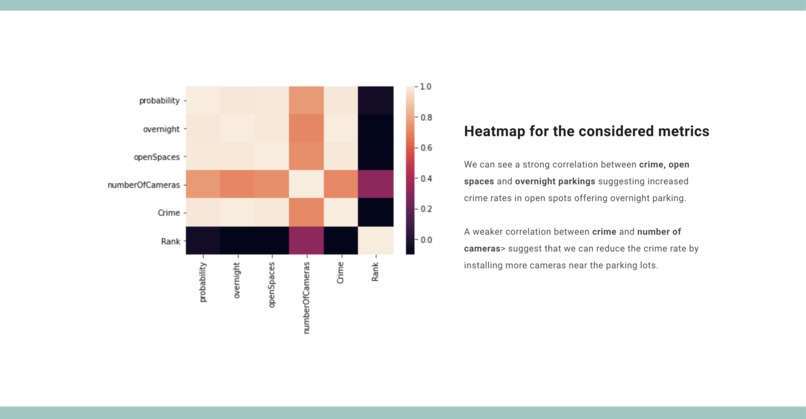
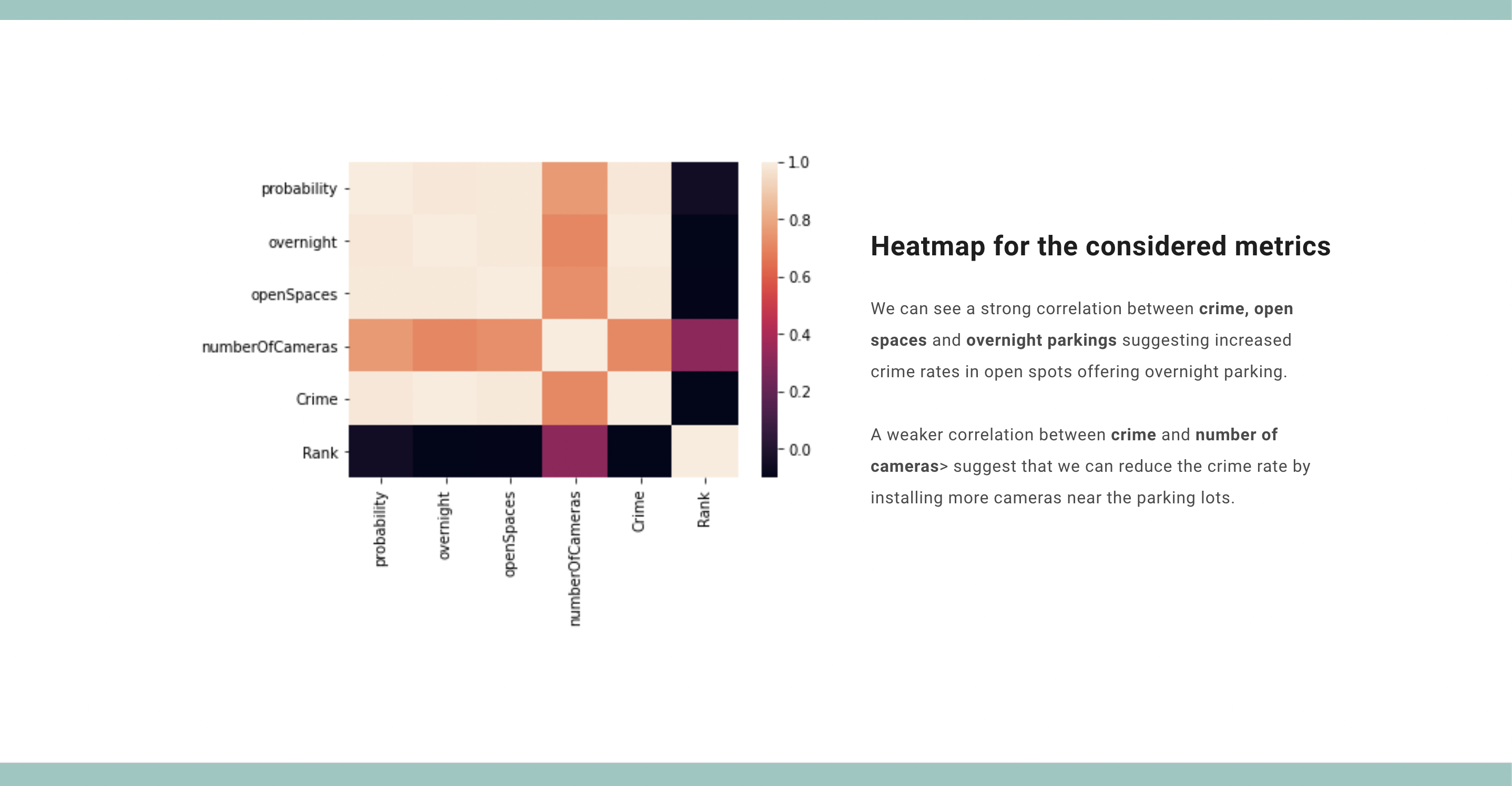
Stats
-
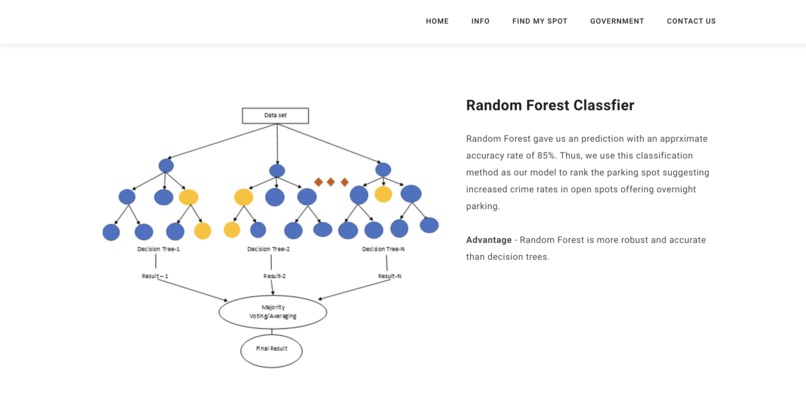
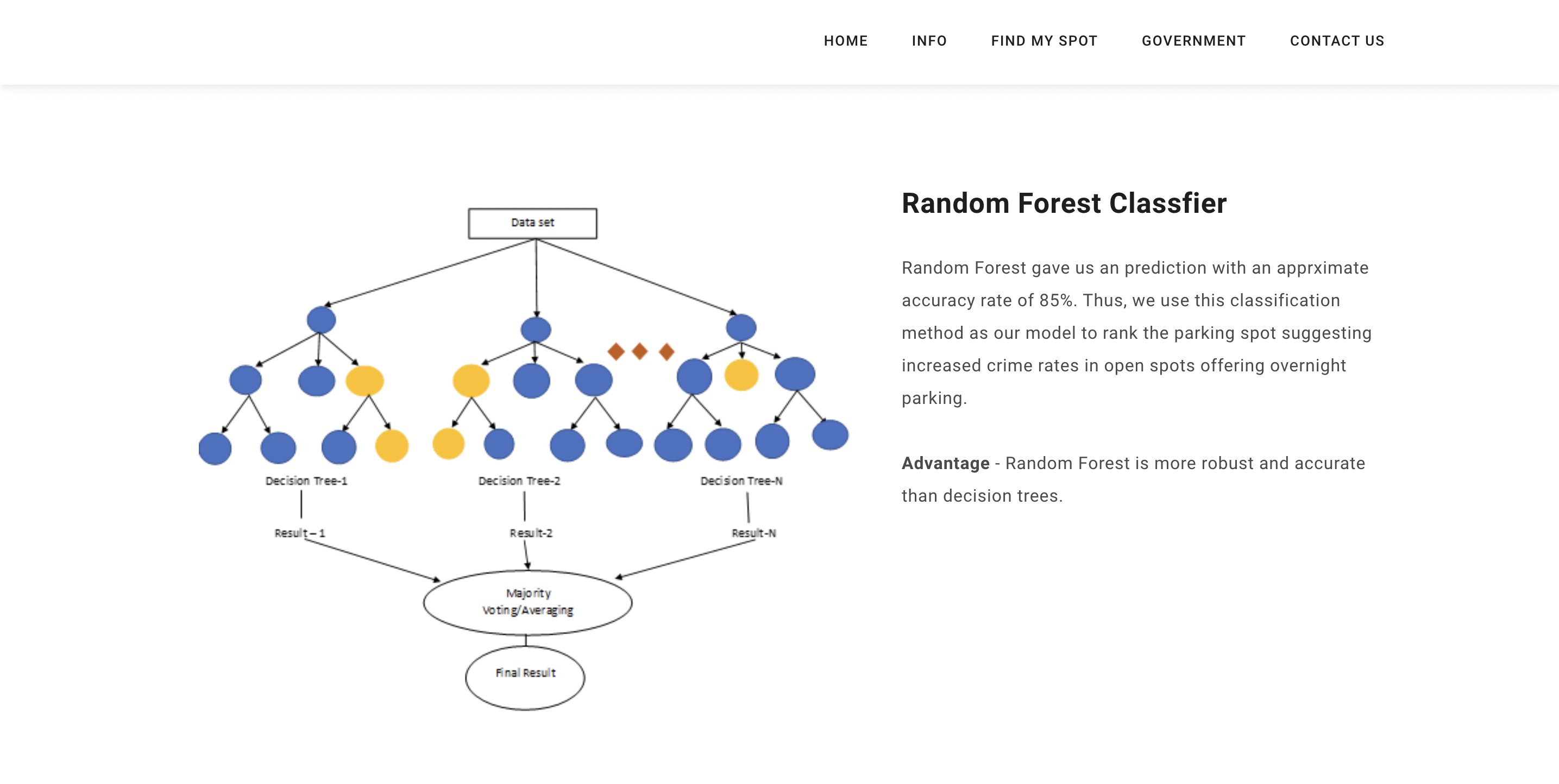
Random Forest
-

Decision Tree Model
-
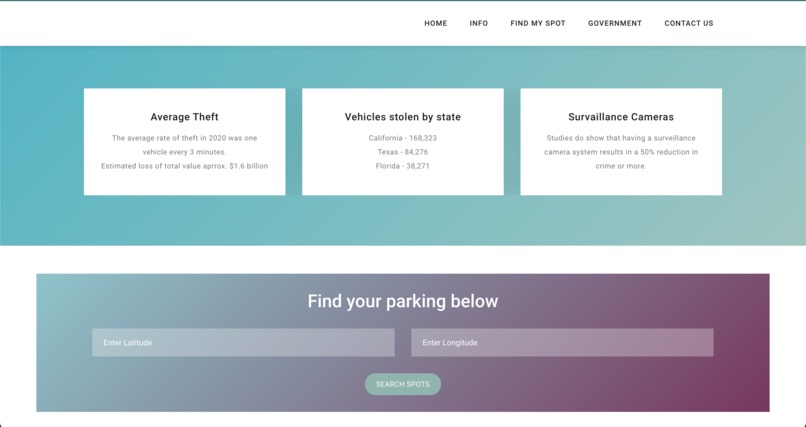
Output
-
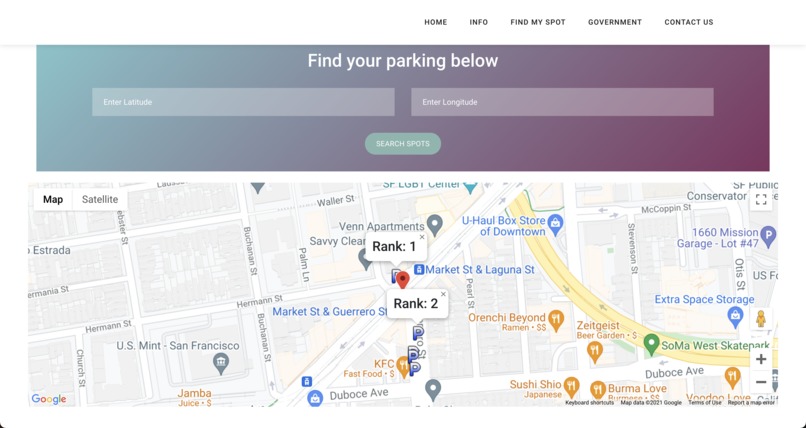
Output

Inspiration
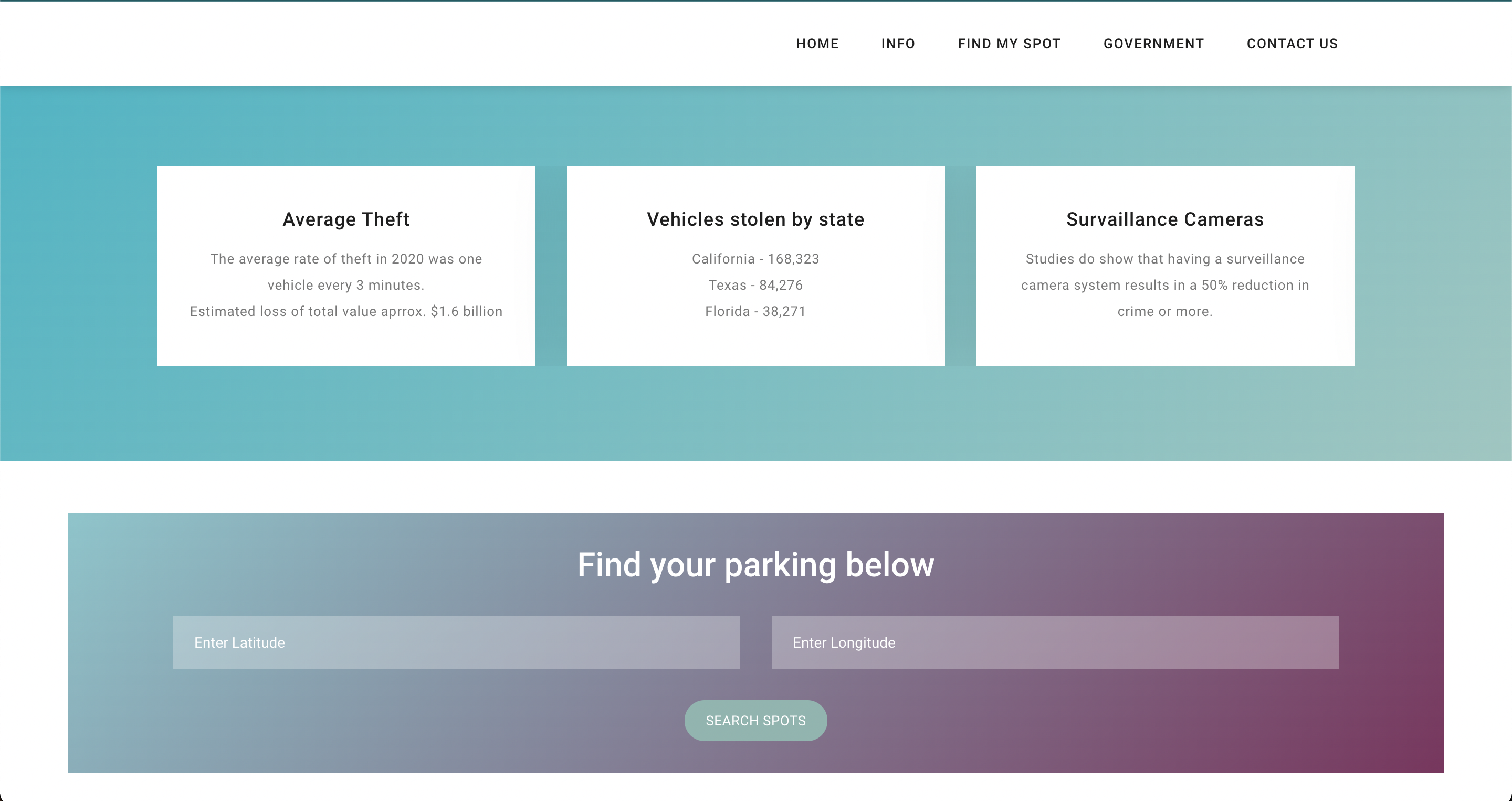
In 2020, 168,323 vehicles were stolen in California, at an estimated total value of approximately $1.6 billion.1 This is a 19.6 percent increase from the 2019 total for vehicle thefts statewide. The average rate of theft in 2020 was one vehicle every 3 minutes. Apart from vehicle thefts, we also considered other crimes while building our model that would guide the user by a simple ranking system to a safer and more cost-efficient on-street parking spot.
What it does
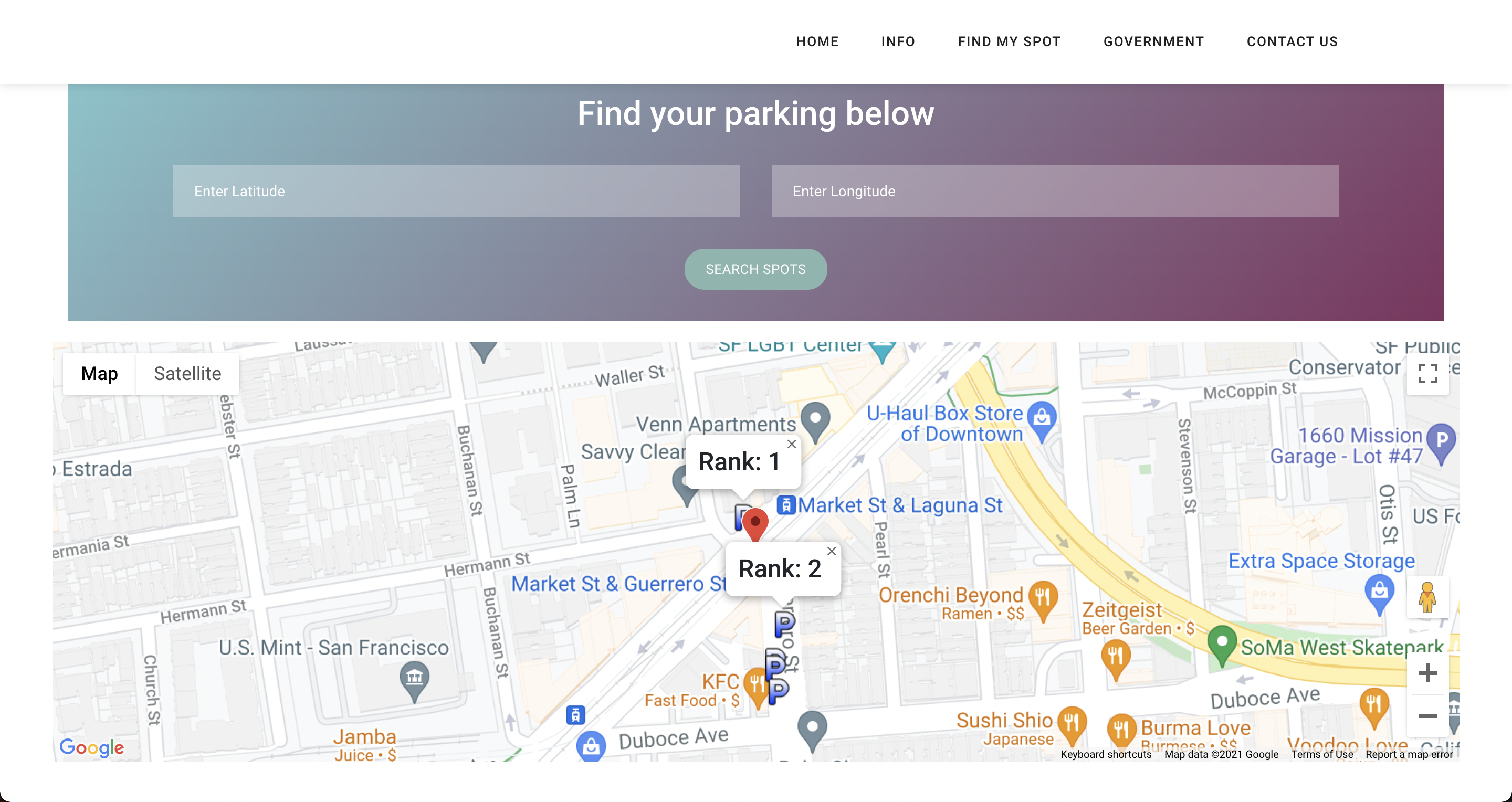
parKING is a progressive web application that lets city governments and communities gain analysis and find the best open on-street parking lots based on simple 1-5 rankings that are been trained by multiple ML models taking the safety (Crime Rate Dataset), Rates (INRIX Parking API Dataset), Proximity to destination (INRIX Segment Roads Polyline Source Proximity Dataset), spot covered with Traffic Cameras (INRIX Traffic Camera API Dataset) into consideration. First, on the government page, city planners enter the Latitude and Longitude for the location they want to analyze the parking lot on streets. Once this data is provided, it is sent to the server, where a model and Graphical User Interface (GUI) are created for that specific city. The GUI is built from training models in our backend server rendering data from sources such as INRIX Traffic Rules APIs, INRIX Segment Roads APIs, INRIX On-Street Parking APIs, Google Maps APIs, and we use polyline to geocode locations and perform distance/metric calculations. Our algorithm is trained on a dataset from San Francisco that contains crime rates, and their attributes such as midnight crime_rates. After aggregating data from the dataset that has crime rates at each street, so when we train our model, the model learns how each specific road safety individually affects ranking. Therefore, when given a prediction scenario with specific road features, the model can predict the new ranking, which is all derived from multiple factors like cost, proximity from users, open spots, Traffic cameras on the street. Our model is a Random Forest (Classification Algorithm) model, which we found performed best when compared to other Classification Algorithms like Decision Trees and Logistic Regression (models are well documented in notebooks). We trained our model for 4 segments and connected it to the GUI for San Francisco. Often, local governments hire private contractors for infrastructure endeavors. Using our product parKING, we allow private contractors to analyze better the existing city on street plans and then submit their proposals to the city government. This allows contractors to directly communicate and propose changes on public forums. Finally, in terms of the B2C perspective, community members can get more information about on-street parking and can use our visualization tool to visualize the parking lot ranks and a lot more information on the parameters its been ranked !!!
How we built it
We used the Inrix Lots API to get the data for parking cost and overnight parking. Also, we used the Inrix Traffic Camera API to get the data for the location of traffic cameras. The crime data and proximity from destination data were pulled from 3rd party API. Merging these datasets, we were able to create a data frame with the required metrics. We used Machine Learning to train and test our data with 75% accuracy. We coded the entire app in the following languages/frameworks: HTML, CSS, Javascript, and Python. We used Google Cloud for our backend and GUI. We developed our interactive GUI with INRIX APIs, Google Maps, and polyline functions. We built our ML models with Sklearn and Keras. We hosted our website through Heroku and Github. We collected our data from the SF Police Data website and other open-source sites.
Challenges we ran into
We believe we could’ve gathered much more insights and modeled a better ML tool if we had more data. For example, the Lots API data did not provide us with the latitude and longitude of the parking spot. The primary challenge that we ran into was developing our geographic models. Since the data was very complex and required cleaning, we weren’t sure how to start. Luckily, we were able to do enough EDA to understand how to develop the models and utilize the data. Training these models was also a huge challenge because of the sheer size of the data. While we were not able to deploy our models, as they are too large to deploy on free and available servers, as long as governments give us data, we can produce models and GUIs for them.
Accomplishments that we're proud of
Our tool successfully predicts the ‘best’ parking spot giving the user a lot more information and thus, helping them in better decision making while choosing the right spot to park their vehicle.
What we learned
Our team found it incredibly fulfilling to use our ML knowledge in a way that could effectively assist governments and customers. We are glad that we were able to develop models to help a vast range of people. Seeing how we could use our software engineering skills to impact people’s daily lives was the highlight of our weekend. From a software perspective, developing a large-scale model and a GUI was our focus this weekend. We learned how to use great libraries such as polyline and INRIX APIs. We grew our web development skills and polished our ML model selection and training skills.
What's next for parKING
We believe that our application would be best implemented on a local and state government level. City planners and government officials currently do not have a way to effectively optimize on-street parking lots, but with ML tools and solutions, we believe on-street parking can be made safer and efficient. In terms of our application, we would love to deploy our models on the web and streamline the process of collecting and preparing data, training a model, and creating a GUI all in one step. Given that our current situation prevents us from buying a web server capable of running all those processes at once, we look forward to acquiring a web server that can process high-level computation. Lastly, we would like to refine our algorithms to incorporate more important traffic parameters and road features.



Log in or sign up for Devpost to join the conversation.