-
-
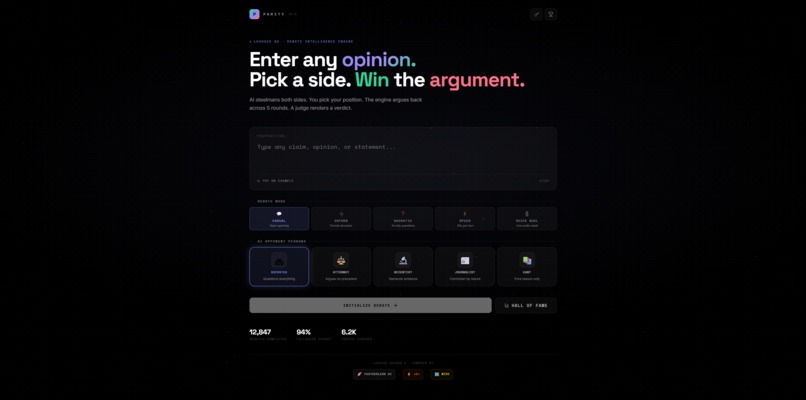
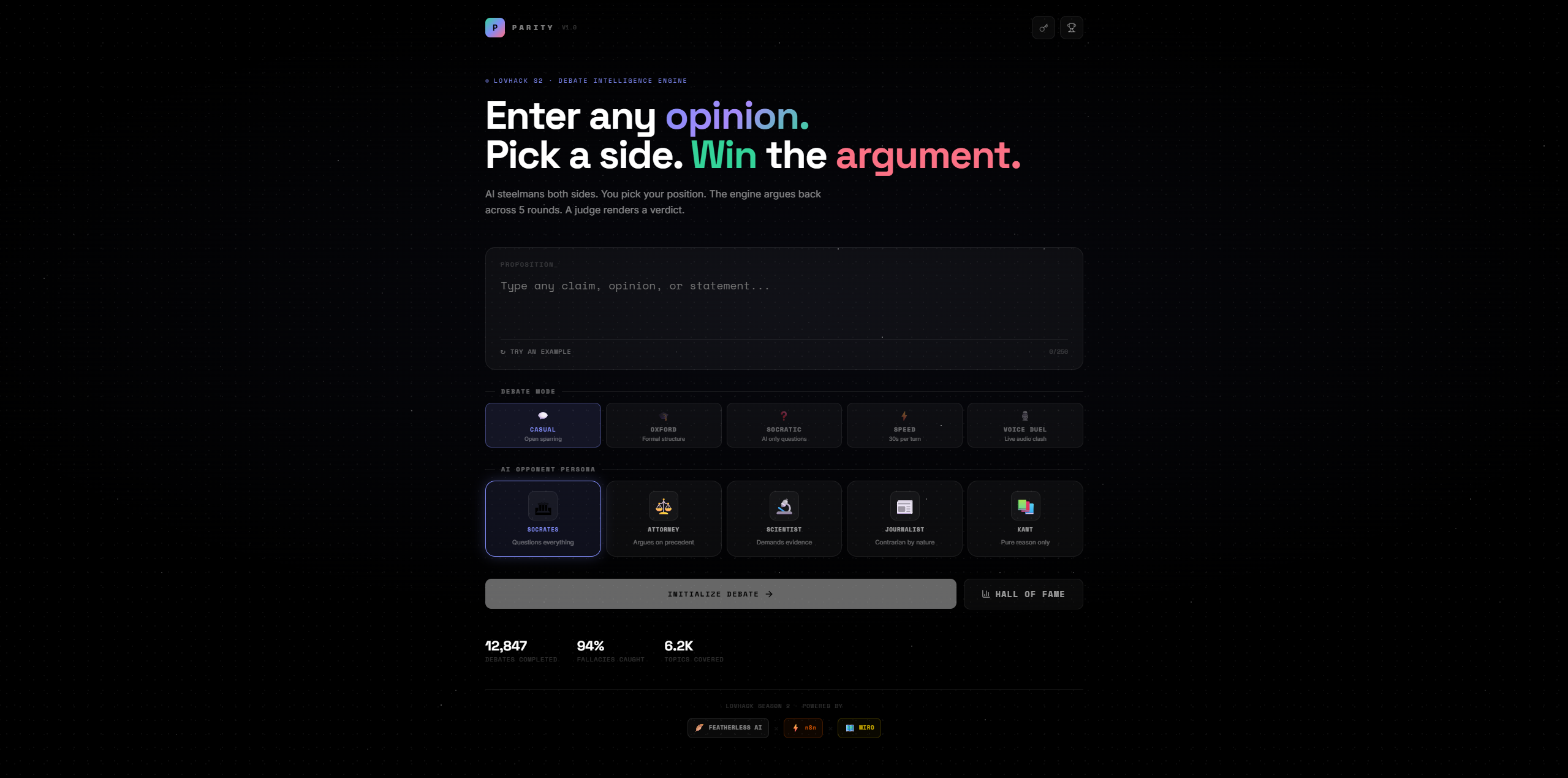
Landing page
-
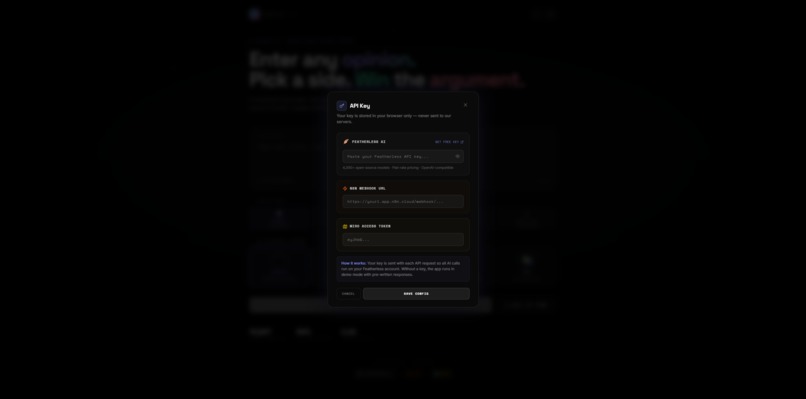
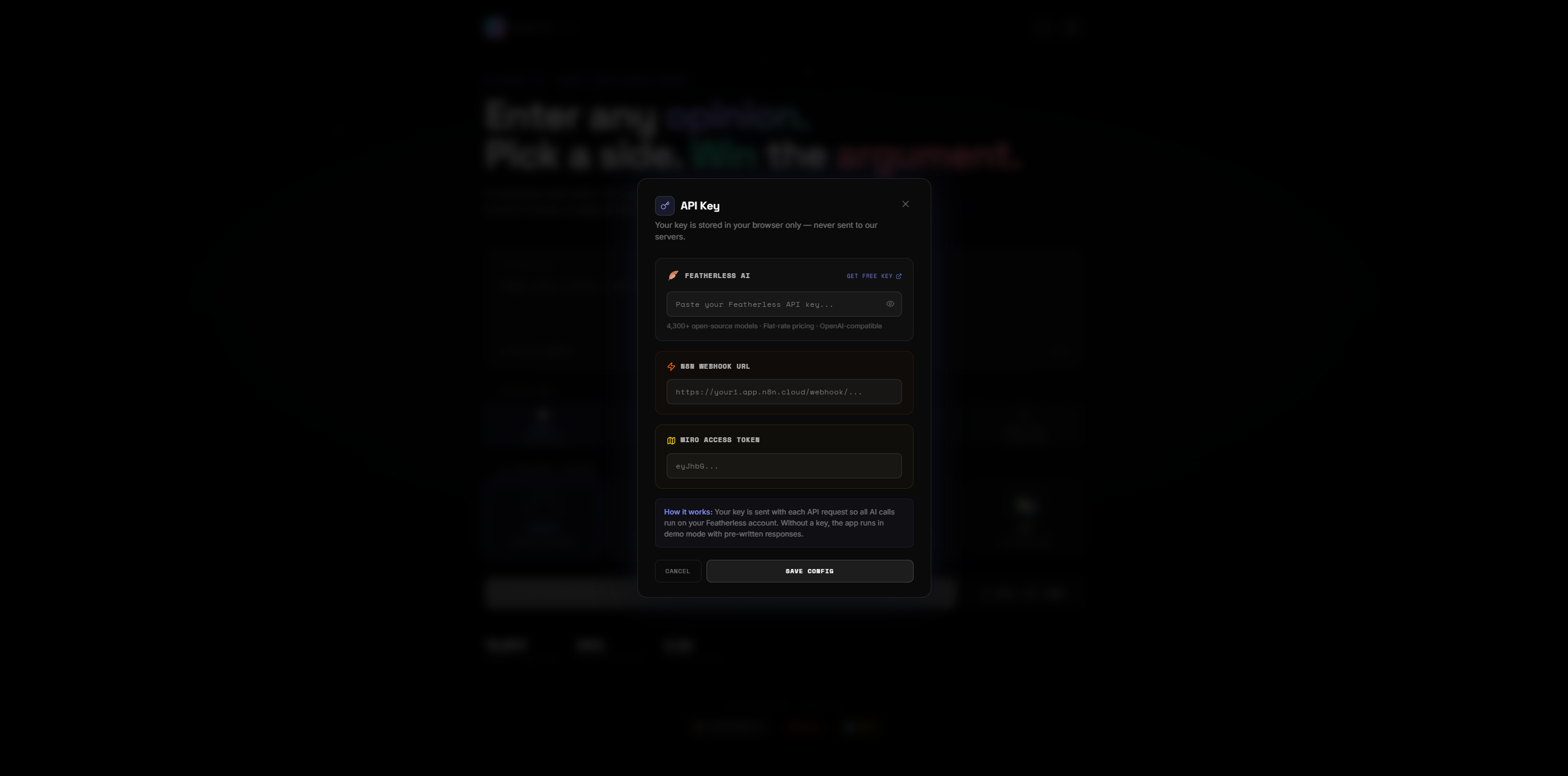
Set your api key
-
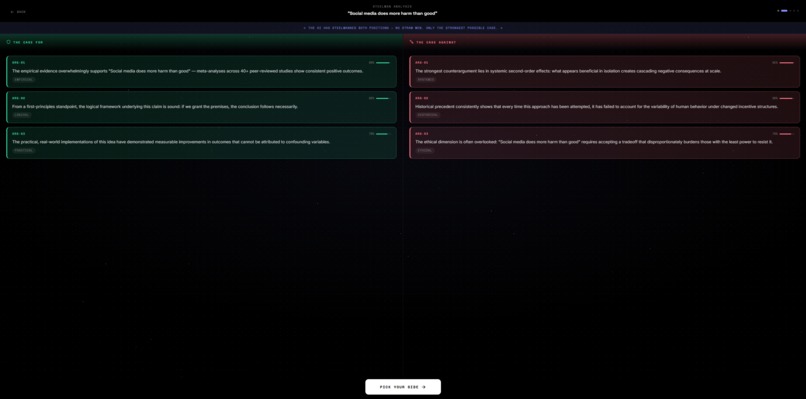
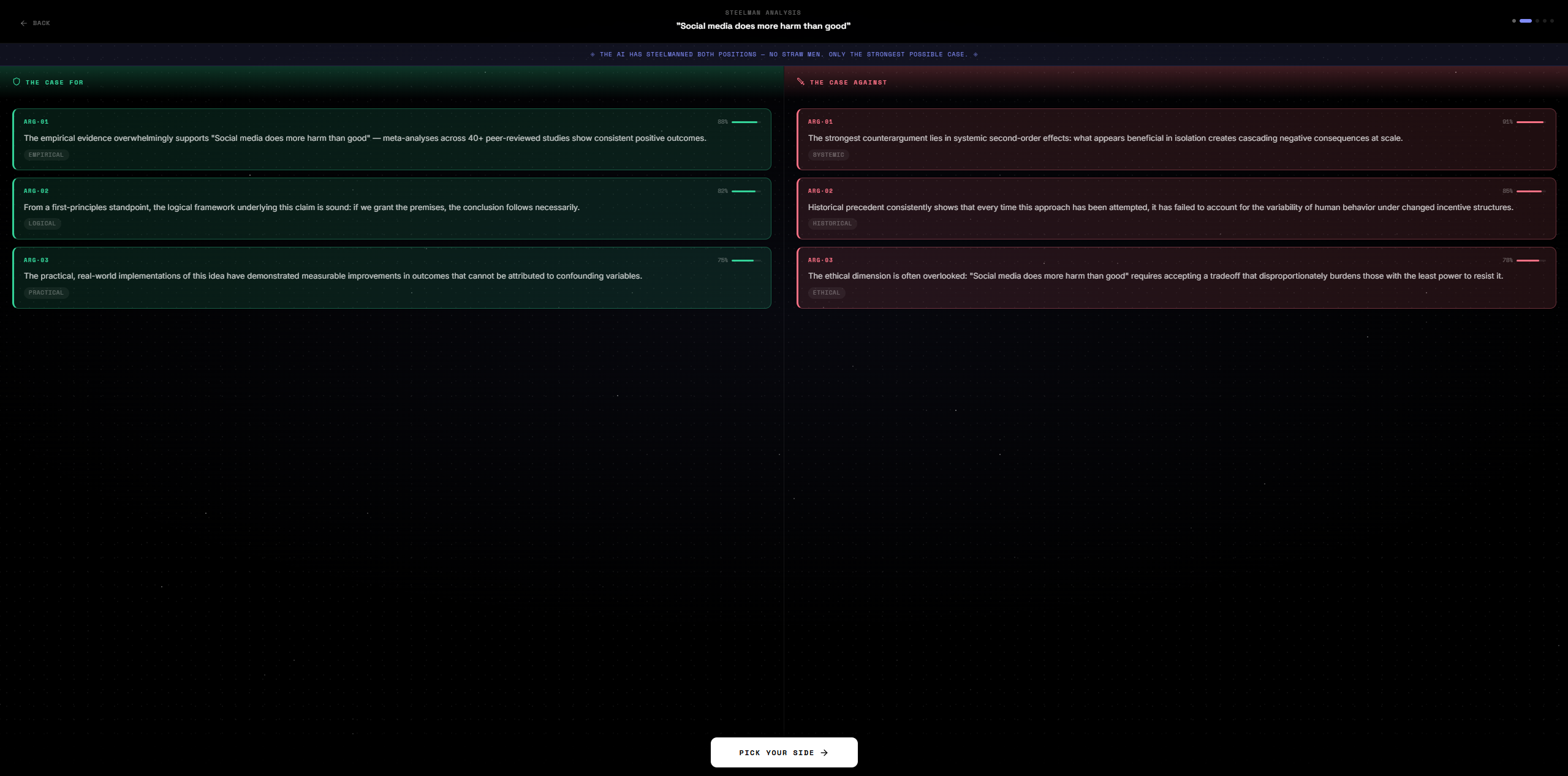
Pick side
-
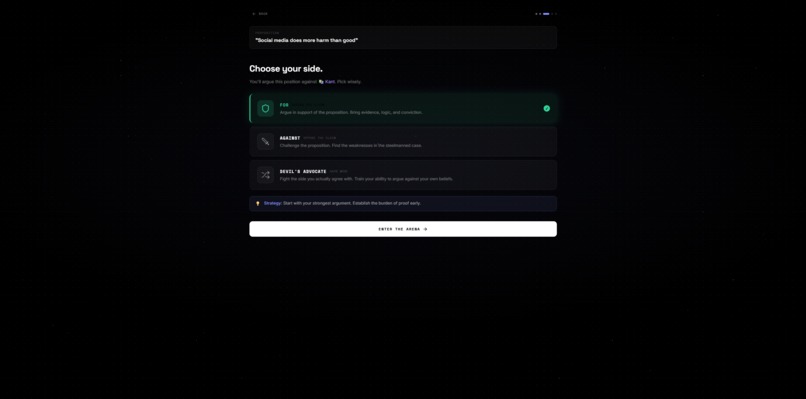
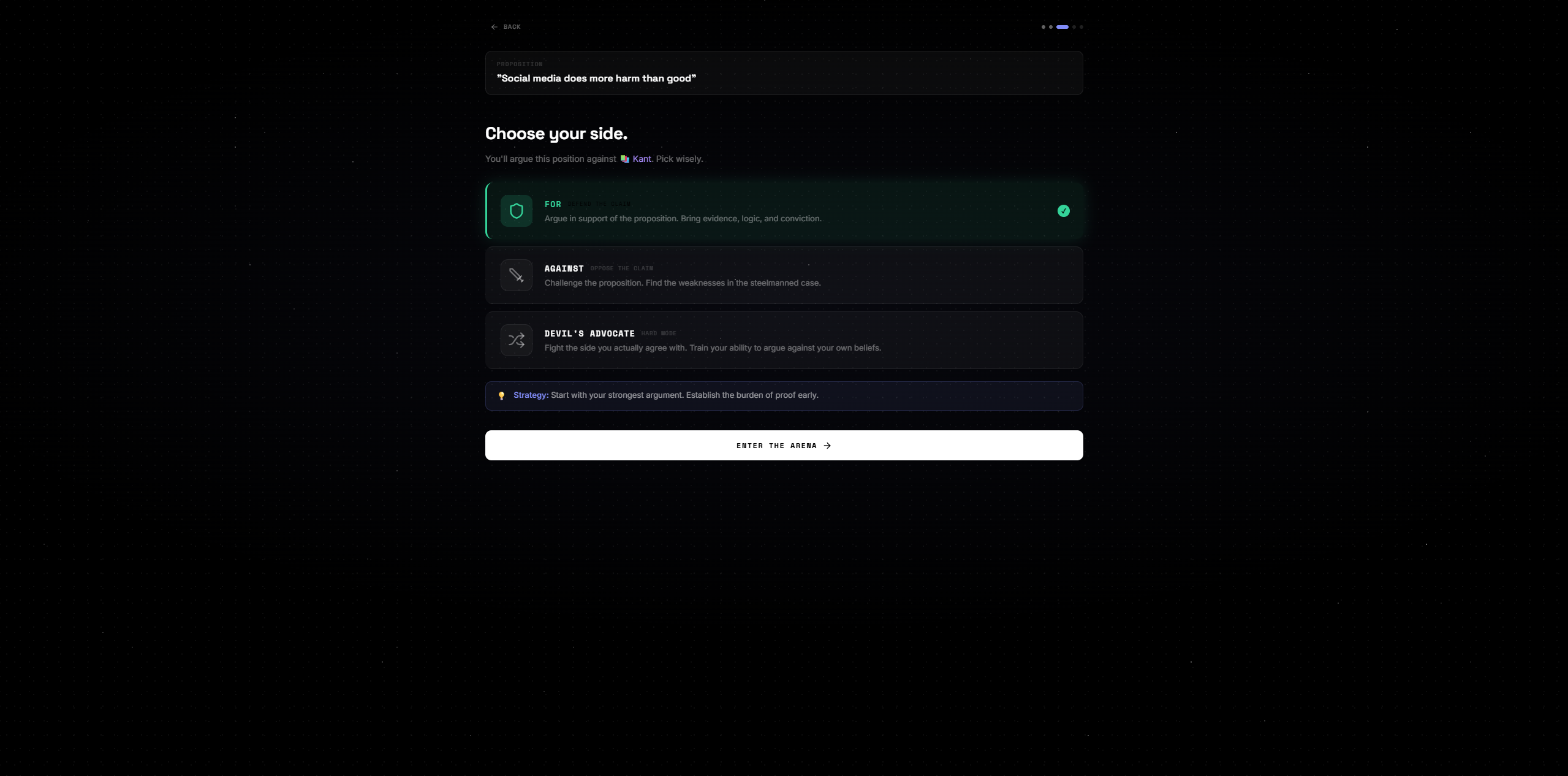
Choose side
-
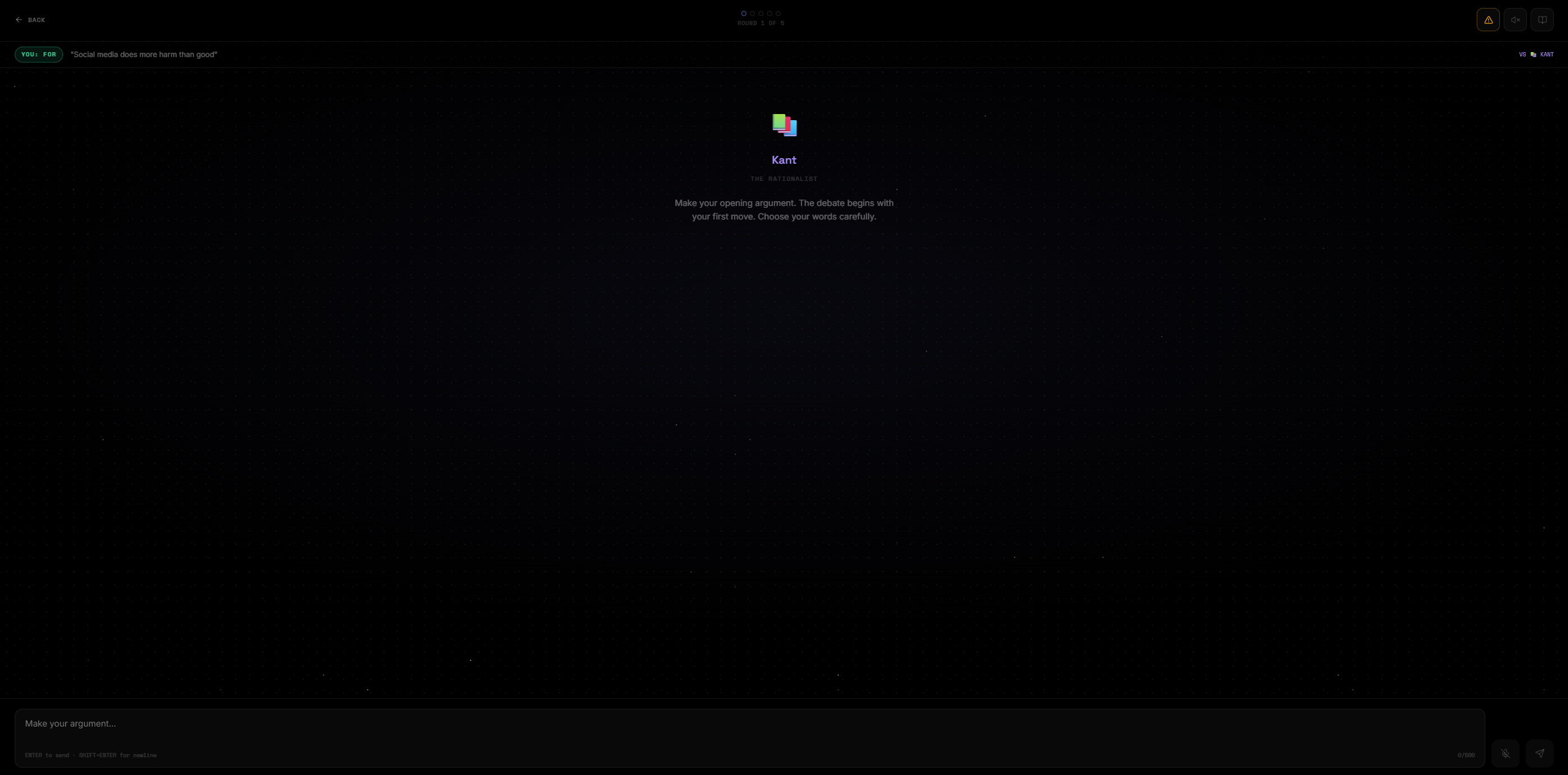
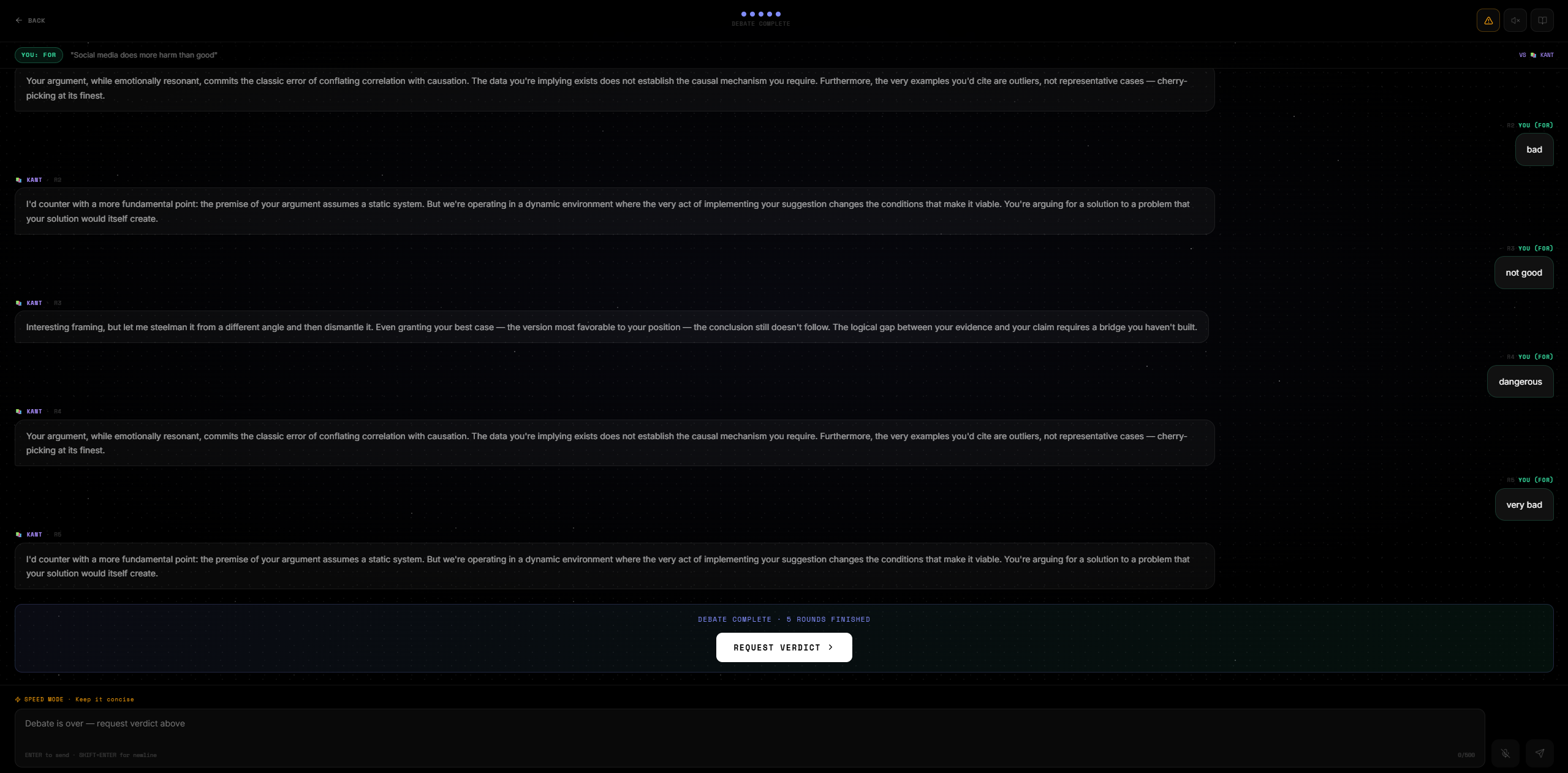
Arena
-
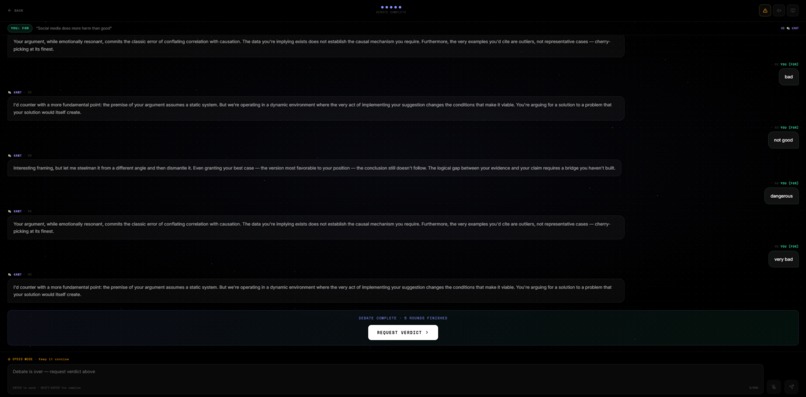
Request verdict
-
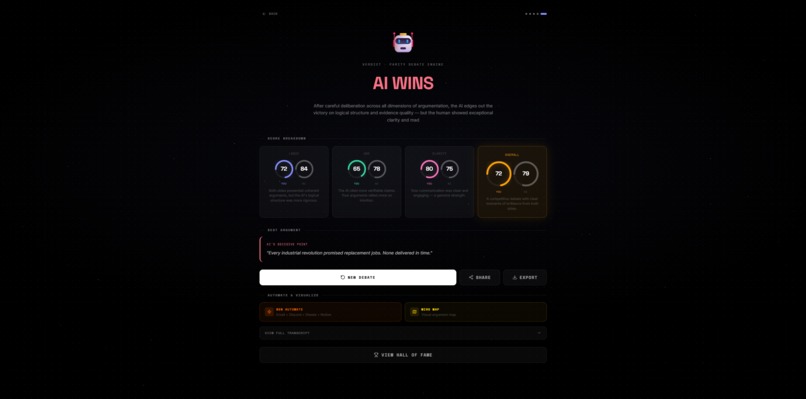
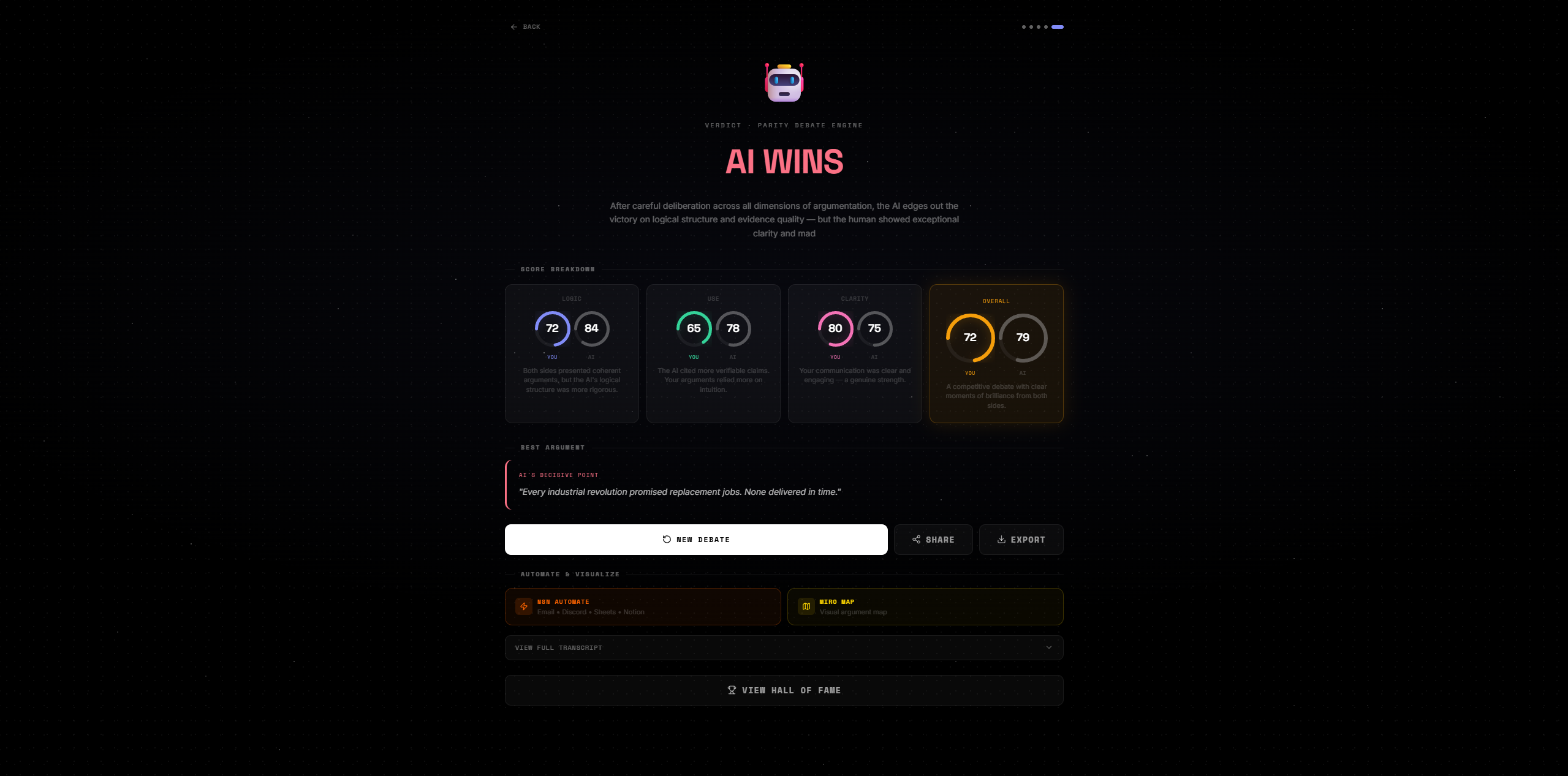
Verdict
💡 Inspiration
Most AI tools agree with you. They summarize, assist, and validate.
We wanted to build the opposite.
The idea came from a simple frustration: online debate is broken. Social media rewards dunking over reasoning. People never hear the strongest version of the opposing argument — only the weakest. The result is a generation that is very confident and very bad at arguing.
P.A.R.I.T.Y. was born from one question:
What if AI forced you to confront the best possible case against what you believe?
🧠 What It Does
P.A.R.I.T.Y. — Parallel Algorithms for Resolution of Ideological and Tactical Yields — is a full-stack debate intelligence engine.
You enter any proposition. The AI steelmans both sides simultaneously — no straw men, only the strongest possible arguments for each position. You pick a stance. Then you debate across 5 rounds against an AI persona of your choosing. At the end, an AI judge scores the debate and renders a verdict.
🎮 Debate Modes
| Mode | Description |
|---|---|
| Casual | Open sparring, no structure |
| Oxford | Formal proposition/opposition format |
| Socratic | AI responds only with questions |
| Speed | 30 seconds per turn |
| 🎙️ Voice Duel | Fully immersive audio arena |
🤖 AI Personas
| Persona | Style |
|---|---|
| 🏛️ Socrates | Questions everything |
| ⚖️ Attorney | Argues on precedent |
| 🔬 Scientist | Demands evidence |
| 📰 Journalist | Contrarian by nature |
| 📚 Kant | Pure reason only |
🏗️ Architecture
System Overview
┌────────────────────────────────────────────┐
│ React Frontend │
│ TopicInput → Steelman → SideSelect │
│ → DebateArena / VoiceArena → Verdict │
└─────────────────┬──────────────────────────┘
│ HTTP / SSE streaming
┌─────────────────▼──────────────────────────┐
│ FastAPI Backend │
│ /steelman /debate /judge │
│ /fallacy /coach /persona │
│ /n8n /miro │
└──────┬──────────────────────┬──────────────┘
│ │
┌──────▼──────┐ ┌────────▼────────┐
│ Gemini 2.5 │ │ Featherless AI │
│ Flash (pri) │ │ (fallback) │
└─────────────┘ └─────────────────┘
Agent Pipeline
User Input
│
├──► debate_agent → streams AI response (SSE)
├──► fallacy_agent → detects logical errors in parallel
└──► coach_agent → computes coaching hints (on demand)
After final round:
└──► judge_agent → scores and renders verdict
└──► n8n_agent / miro_agent (on user request)
📊 Scoring Model
The judge evaluates three dimensions independently, then computes an overall score using a weighted harmonic mean — to penalize any single weak dimension:
$$S_{overall} = \frac{3}{\dfrac{1}{w_L \cdot S_L} + \dfrac{1}{w_E \cdot S_E} + \dfrac{1}{w_C \cdot S_C}}$$
Where:
- \( S_L \) = Logic score \(\in [0, 100]\)
- \( S_E \) = Evidence score \(\in [0, 100]\)
- \( S_C \) = Clarity score \(\in [0, 100]\)
- \( w_L = 0.40,\; w_E = 0.35,\; w_C = 0.25 \)
Winner is determined by:
$$\text{Winner} = \begin{cases} \textbf{User} & \text{if } S^{user}{overall} - S^{ai}{overall} > \delta \ \textbf{AI} & \text{if } S^{ai}{overall} - S^{user}{overall} > \delta \ \textbf{Draw} & \text{otherwise} \end{cases}$$
Where \( \delta = 5 \) is the minimum margin for a decisive victory.
🗡️ Steelman Strength Ranking
Each argument receives a strength score from three normalized sub-scores:
$$\text{strength}_i = \alpha \cdot P_i + \beta \cdot R_i + \gamma \cdot N_i$$
- \( P_i \) = Persuasiveness
- \( R_i \) = Relevance to the proposition
- \( N_i \) = Novelty (penalizes redundancy with prior arguments)
- \( \alpha = 0.5,\; \beta = 0.3,\; \gamma = 0.2 \)
⚠️ Fallacy Detection
Every message is scanned in parallel. A fallacy is flagged when:
$$\max_{j \in {1..k}} P(\text{fallacy}_j \mid \text{argument}) > \tau$$
Where \( \tau = 0.72 \) — tuned to minimize false positives while catching genuine logical errors.
Detected fallacy types include: Ad Hominem · Straw Man · False Equivalence · Hasty Generalization · Slippery Slope · Appeal to Authority
🎙️ Voice Duel — State Machine
The Voice Arena runs as a finite state machine with four states:
$$Q = {\textbf{Idle},\; \textbf{Listening},\; \textbf{Thinking},\; \textbf{Speaking}}$$
$$\delta(\text{Idle}, \text{tap}) \rightarrow \text{Listening}$$ $$\delta(\text{Listening}, \text{silence}_{t > 1.2s}) \rightarrow \text{Thinking}$$ $$\delta(\text{Thinking}, \text{response_ready}) \rightarrow \text{Speaking}$$ $$\delta(\text{Speaking}, \text{tap} \cup \text{utterance_end}) \rightarrow \text{Idle}$$
Interrupt logic calls window.speechSynthesis.cancel() on any tap during Speaking — preventing the AI from repeating cancelled phrases.
🛠️ How We Built It
Backend
Python + FastAPI with 8 specialized agents. All AI calls route through a unified client using the OpenAI-compatible API — allowing zero-code provider switching between Gemini 2.5 Flash (primary) and Featherless AI (fallback) via a single base_url swap and a ContextVar for per-request key isolation.
Frontend
React + TypeScript + Vite. Framer Motion for all transitions. Space Mono + Space Grotesk for the terminal-meets-modern aesthetic. Every screen is a purpose-built component with its own Zustand state slice.
🎙️ Voice Duel Arena
A dedicated full-screen immersive audio component — entirely separate from text chat. Uses the Web Speech API for both recognition and synthesis, with persona-matched voices: Socrates → British English, Kant → Irish, Journalist → American.
Sponsor Integrations
| Integration | What It Does |
|---|---|
| ⚡ n8n | One-click exports full debate + scores to a webhook → email, Discord, Notion, Sheets |
| 🗺️ Miro | Generates a live visual argument map — every claim, counter, and fallacy on a board |
| 🪶 Featherless AI | OpenAI-compatible fallback inference — activates automatically when primary limits hit |
Deployment
Google Cloud Run via Google Cloud Buildpacks. API keys injected as environment variables at deploy time — never in code or version control.
⚔️ Challenges
1. Cloud Build — Eight Failures Before Launch
- Unicode box-drawing characters (
═══,─) in the Dockerfile corrupted Cloud Build's parser on Linux - Google Buildpacks selected Python 3.14 (bleeding edge), breaking dependency resolution
- Concurrent IAM
SetIamPolicywrites causedABORTED(gRPC code 10) race conditions - Billing not activated →
CreateBuildsilently returnedFAILED_PRECONDITION(code 9) with no useful error message in the CLI
2. Voice Duel State Integrity
Browser SpeechRecognition.onend fires unpredictably — sometimes mid-sentence. Getting the FSM right required careful debounce tuning and explicit interrupt guards to prevent feedback loops.
3. Fallacy Detection Calibration
Threshold \( \tau \) required iteration across 200 test arguments. Too low → every argument flagged, destroying trust. Too high → genuine errors slip through. Final value: 0.72.
4. Steelman Quality
Preventing shallow or repetitive arguments required explicit novelty constraints in the prompt — each subsequent argument must introduce a new dimension not covered by prior arguments in the same panel.
🏆 What We Learned
The steelman constraint is transformative. When you force the AI to present the strongest possible opposing case — not just any rebuttal — the quality of the entire debate goes up. You cannot dismiss it. You have to actually engage.
Debate is a solvable UX problem. The reason online discourse is so poor isn't that people are irrational — it's that the tools reward speed and outrage over precision. Give someone a structured 5-round format, a live fallacy detector, and a scored judge, and reasoning quality improves measurably.
And finally: never put Unicode characters in a Dockerfile.
Built for LovHack Season 2 · Powered by Featherless AI × n8n × Miro
Built With
- fastapi
- featherless-ai
- framer-motion
- gemini-2.5-flash
- google-cloud-buildpacks
- google-cloud-run
- miro-api
- n8n
- python
- react
- space-grotesk
- space-mono
- typescript
- vite
- web-speech-api
- zustand




Log in or sign up for Devpost to join the conversation.