-
-
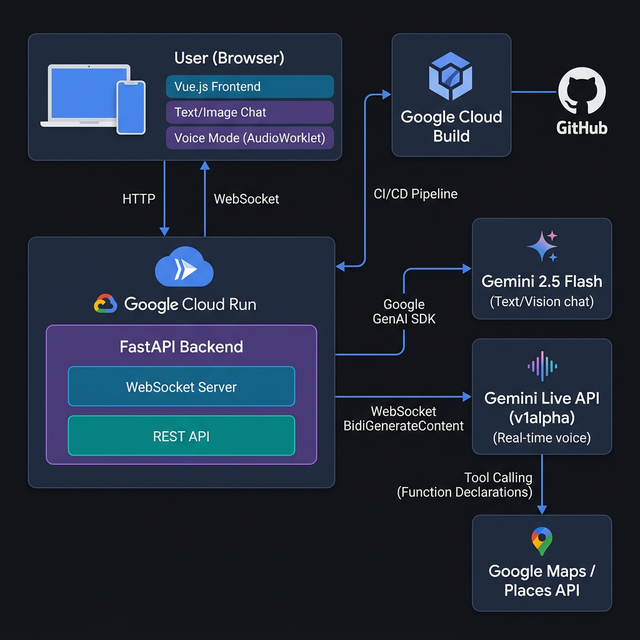
architecture diagram
-
-

-
-
-
-
login page
-

-
Google Cloud run dashboard
-
Google Cloud run
-

User name and password for testing



Inspiration
Paris is one of the most visited, beautiful, and vibrant cities in the world, yet navigating its immense public transit system (the RATP Metro network) and deeply intricate lifestyle scene can be overwhelming for tourists and locals alike. We wanted to build an intelligent, multi-lingual companion that doesn't just "show a map," but actively converses with you like a knowledgeable local Parisian friend. We were inspired by the recent advancements in ultra-low latency, multimodal AI to create an experience where users could simply walk the streets of Paris, point their camera, or speak naturally into their phones to get instant, highly personalized transit and lifestyle guidance.
What it does
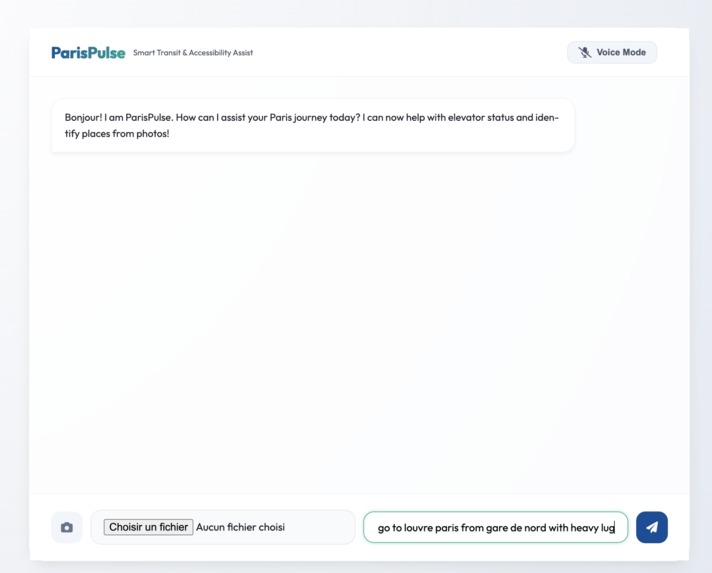
ParisPulse is an Expert Transit & Lifestyle Guide for Paris powered by the latest Gemini 2.5 Flash models. It operates across two core modes:
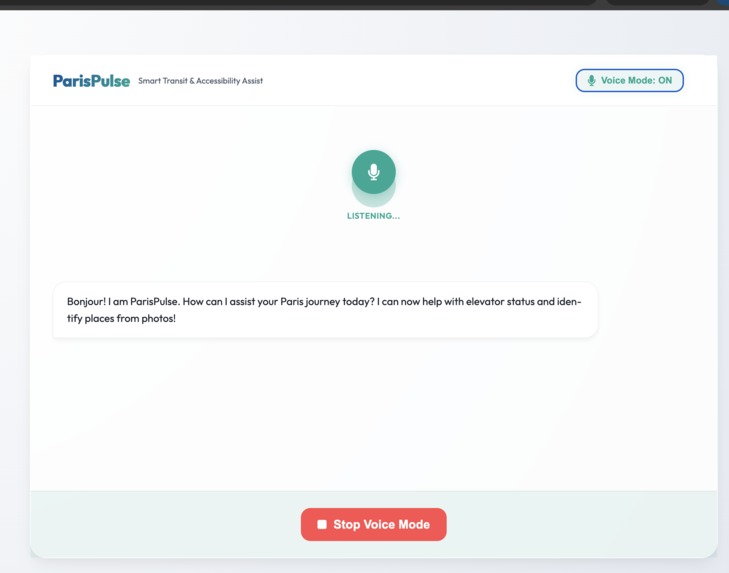
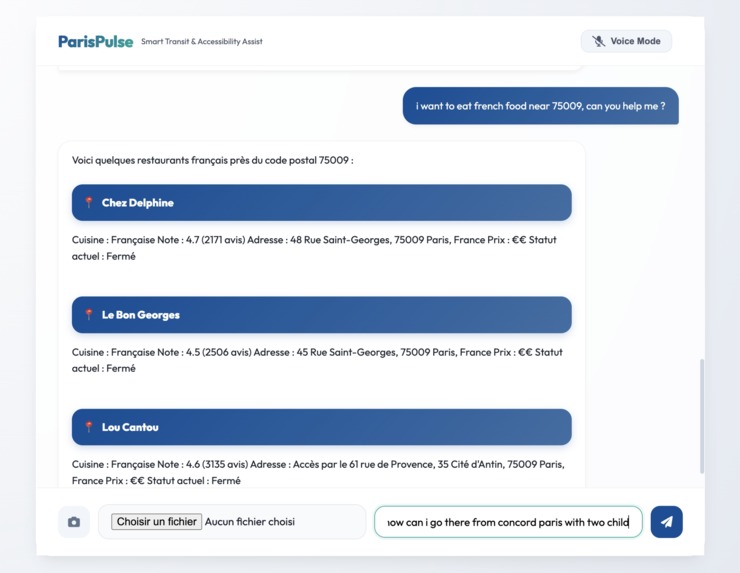
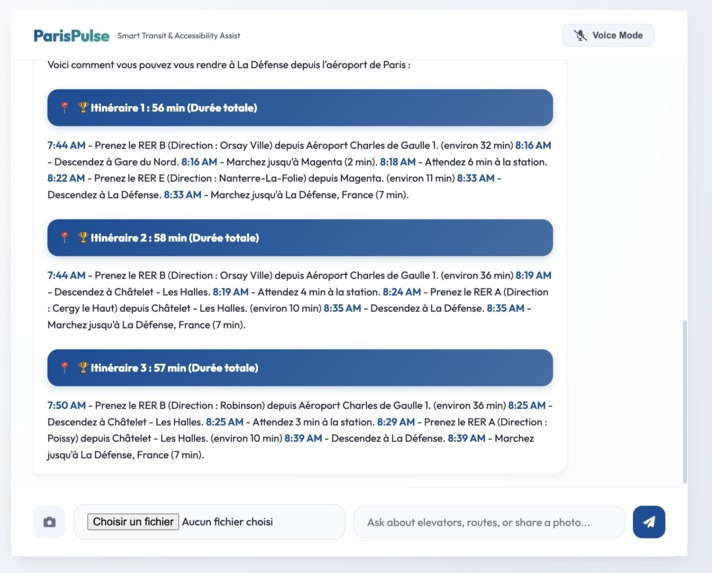
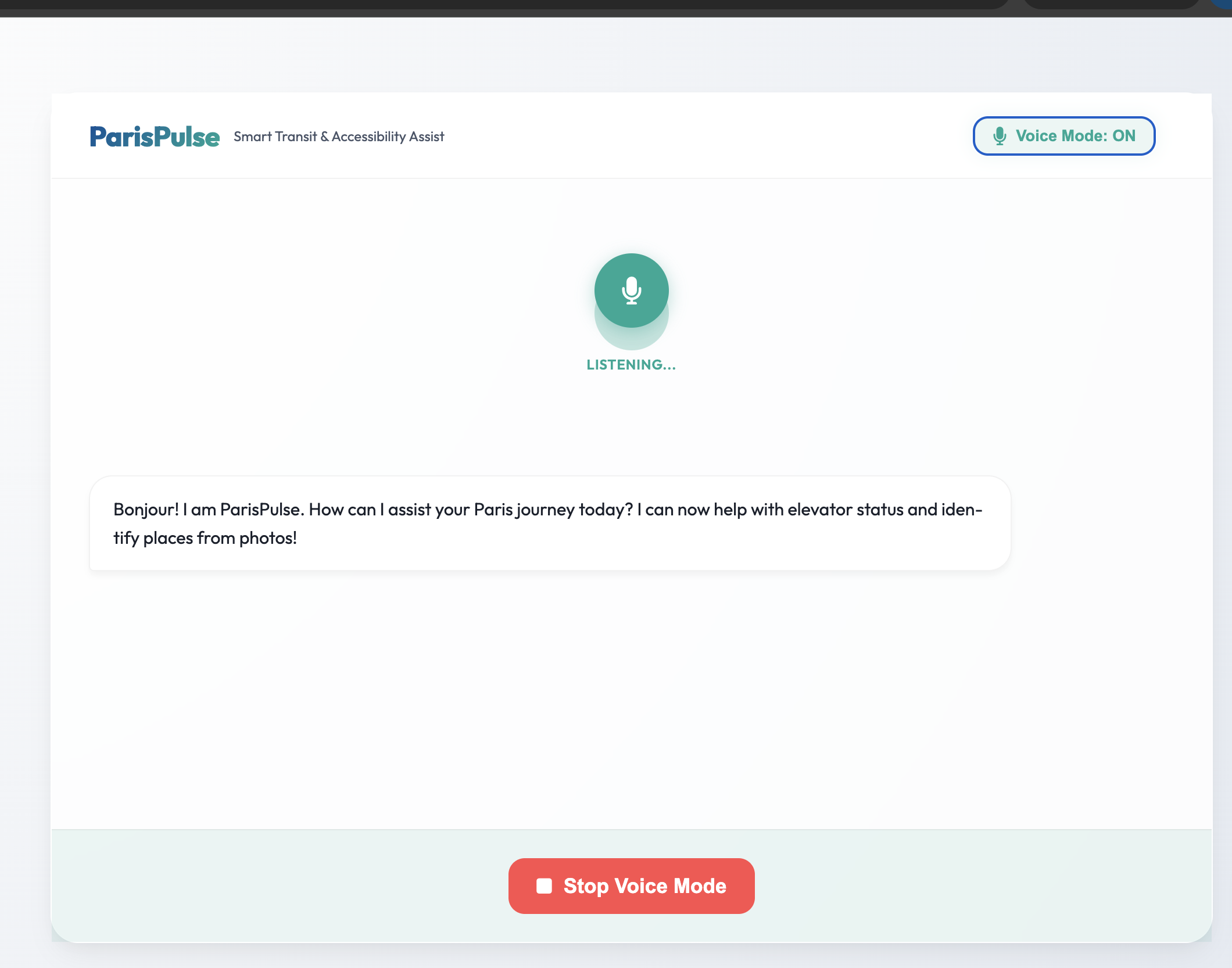
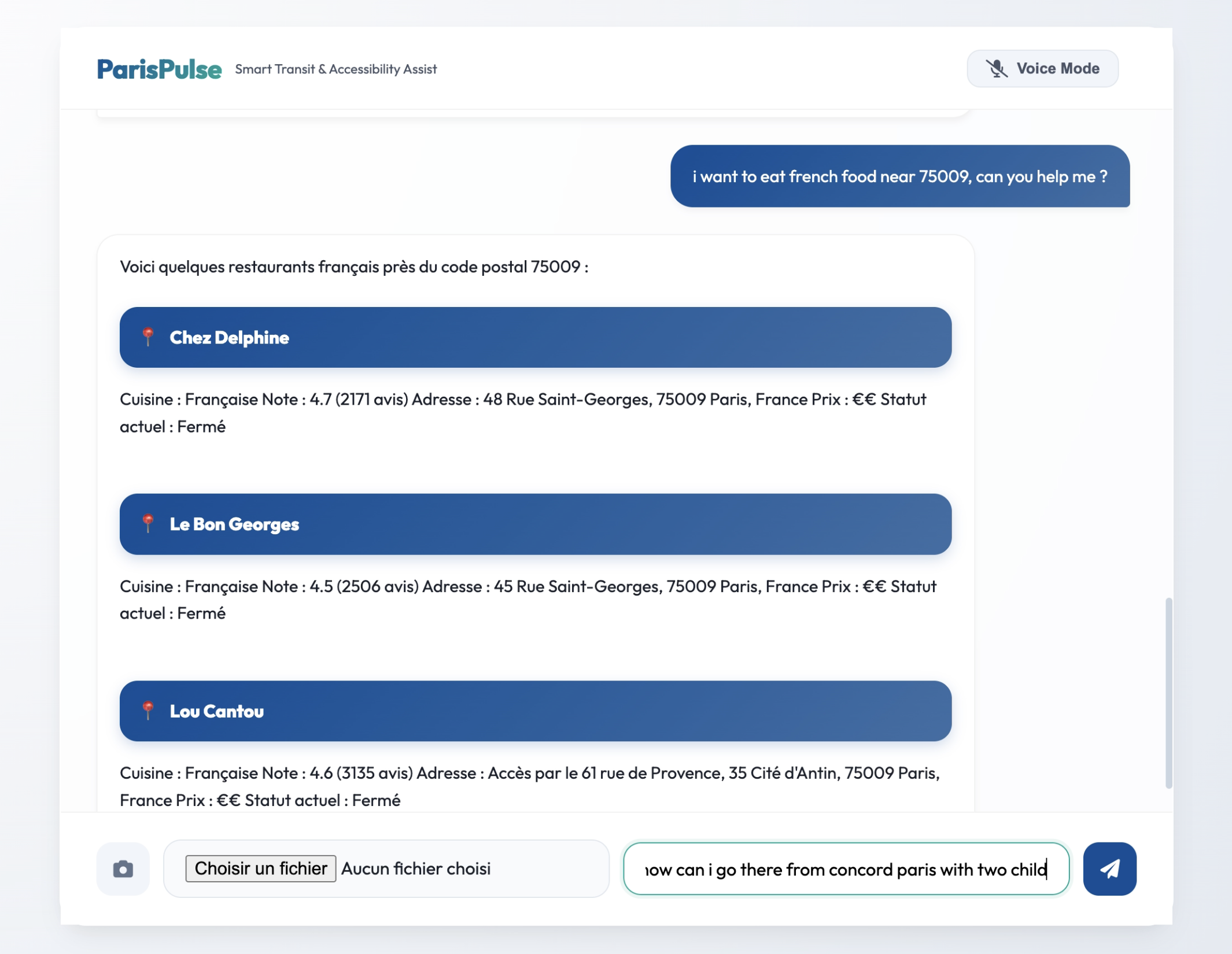
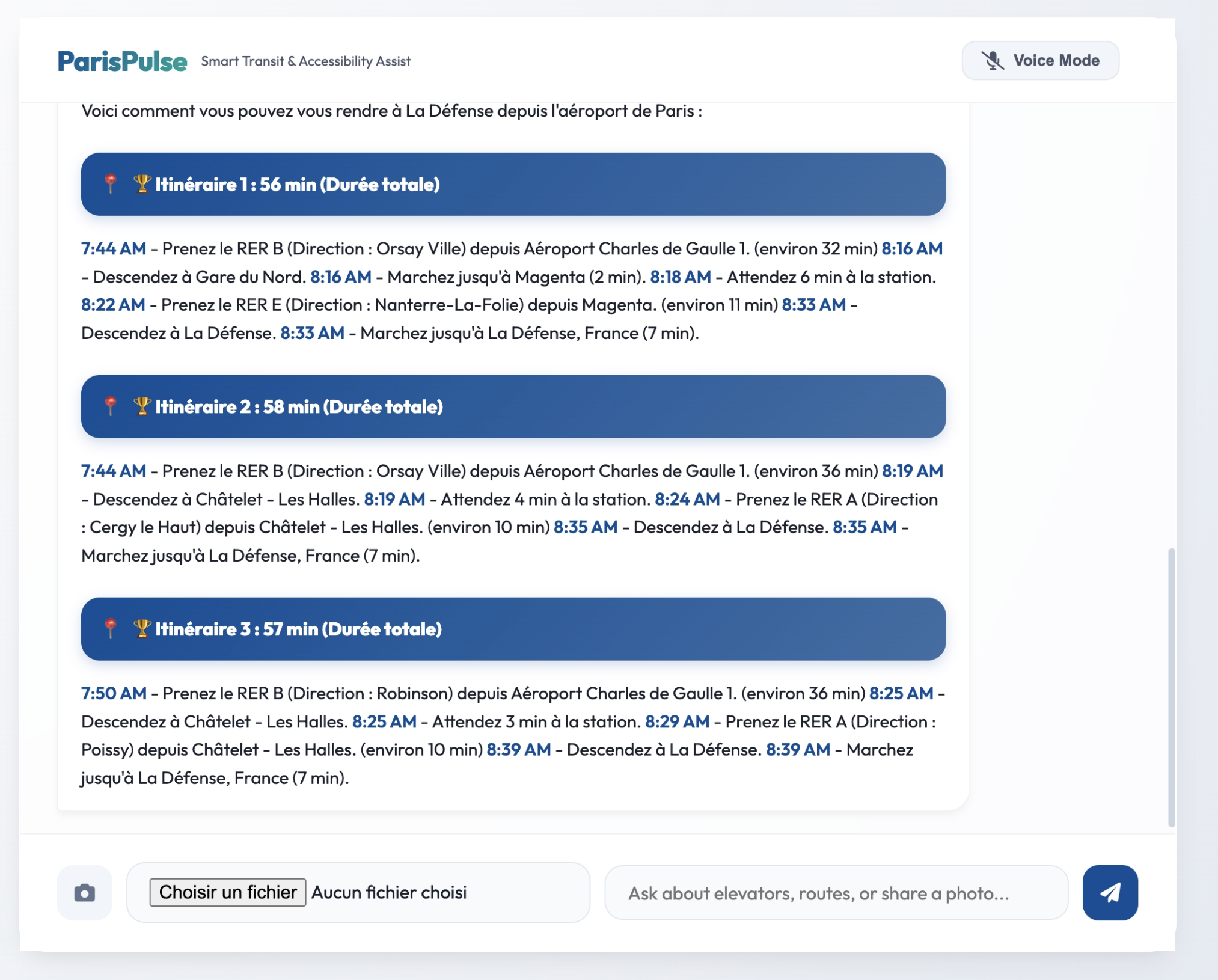
Multimodal Text Chat: Users can ask complex transit questions, upload images (e.g., "What station is this?"), and receive comprehensive, formatted cards detailing the fastest routes, elevator statuses, and premium nearby dining options. Real-time Voice Mode: A continuous, uninterrupted bidirectional voice channel where users can converse naturally with ParisPulse. It features Voice Activity Detection (VAD)—meaning if the AI is speaking and you interrupt it to change your mind, it instantly stops talking and listens to your new request. Crucially, ParisPulse is natively multilingual. It automatically detects and fluently responds in English, French, and Chinese, making it the ultimate tool for international travelers.
How we built it
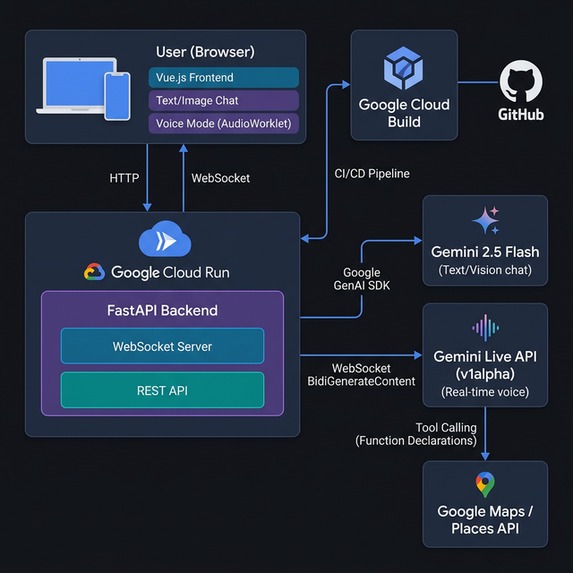
We built ParisPulse using a modern, lightweight, and highly responsive architecture deployed on Google Cloud Run:
Backend: We used Python with FastAPI to build a robust asynchronous server. We integrated the bleeding-edge google-genai SDK (v1alpha), utilizing both standard GenerateContent for text/vision and the new Live API (BidiGenerateContent) over WebSockets for real-time audio streaming. Frontend: We crafted a fluid, mobile-first UI using Vue.js, Vanilla CSS, and modern 100dvh viewport techniques. To handle voice data safely without blocking the browser thread, we migrated from legacy script processors to modern AudioWorkletNodes, feeding raw 16-bit PCM audio directly to the websocket. AI & Tools: We equipped the Gemini model with powerful Function Declarations (Tool Calling), connecting it to APIs to fetch live detailed routes, real-time elevator statuses, and premium food locations.
Challenges we ran into
Building with bleeding-edge APIs meant we were navigating uncharted territory. Integrating the Gemini Live API for real-time voice was easily our biggest mountain to climb. We battled through a gauntlet of complex, undocumented issues:
Modality Conflicts: We discovered that requesting simultaneous AUDIO and TEXT from the bidirectional stream caused 1007 (invalid frame payload) errors, forcing us to rethink our frontend response handlers. The "Silent AI" Bug: The AI refused to speak because we were sending microphone data as ClientContent (which requires manual "Turn Complete" signals) instead of RealtimeInput, causing the AI to wait infinitely. SDK Syntax Overhauls: The new SDK completely deprecated positional arguments in streaming methods in favor of strict kwargs (e.g., audio={"mime_type"...}), requiring us to rewrite our entire backend connection loop based on internal library source code inspections. Frontend Audio Destruction: Raw PCM base64 data returned by the AI was being scrambled by 8-bit charCodeAt parsers fitting into 16-bit integer arrays, creating silent static. We also had to engineer a custom continuous queue (playbackContext.currentTime) to stitch the fragmented audio chunks together smoothly. The "One-Turn" Loop Break: The hardest bug to catch was the Google SDK's session.receive() iterator intentionally breaking its own async loop upon sending a turn_complete flag. We had to implement a custom continuous while True loop to force the WebSocket to re-enter the listening state, finally unlocking infinite back-and-forth conversational mode.
Accomplishments that we're proud of
We are incredibly proud of building a truly real-time, uninterrupted voice architecture from scratch. Getting the Voice Activity Detection (VAD) interception to work perfectly—where the server sends an {"control": "interrupted"} signal that immediately flushes the frontend AudioContext queue—feels like magic. Furthermore, we take pride in seamlessly unifying standard chat, image reasoning, and live PCM audio streaming into one single, beautifully responsive interface that works flawlessly on any mobile device.
What we learned
We gained an incredibly deep, hands-on understanding of WebSockets, PCM Audio Buffering, and the Web Audio API (AudioWorklet). We also learned the crucial importance of diving directly into library source code (like we did with the google.genai.live module) when working with Alpha implementations, rather than relying purely on external documentation.
What's next for ParisPulse
For the future of ParisPulse, we plan to:
- Re-enable Dual Modality: Once the Live API fully supports simultaneous Text and Audio in its release candidate, we will re-enable real-time text transcription alongside the Voice Mode.
Live Camera Mode: Integrate real-time video frame streaming to the WebSocket, allowing users to point their phone camera down a Parisian street and ask, "Is that café open?"
Transit: Directly plug into the live RATP systems for up-to-the-second Metro delays, strikes, and alternative bus routing.
Lifestyle & Dining: Integrate with major European reservation platforms like TheFork (LaFourchette). This will allow ParisPulse to not only find highly-rated food nearby, but also instantly check table availability, fetch aggregate reviews, and book reservations entirely through natural voice conversation.
Built With
- css
- docker
- fastapi
- gemini-2.5-flash
- gemini-api
- gemini-live-api
- google-cloud-build
- google-cloud-run
- google-maps
- html
- javascript
- python
- uvicorn
- vue.js
- websockets



Log in or sign up for Devpost to join the conversation.