
Inspiration
Financial markets are noisy, nonstationary, and heavy-tailed — precisely the conditions where classical feature engineering struggles. The challenge's core hypothesis is that quantum circuits might expose nonlinear structure that classical methods miss. Rather than picking one quantum circuit and hoping it works, we asked: which specific design choices in a quantum feature map actually matter, and can we find the Pareto-optimal combination?
What it does
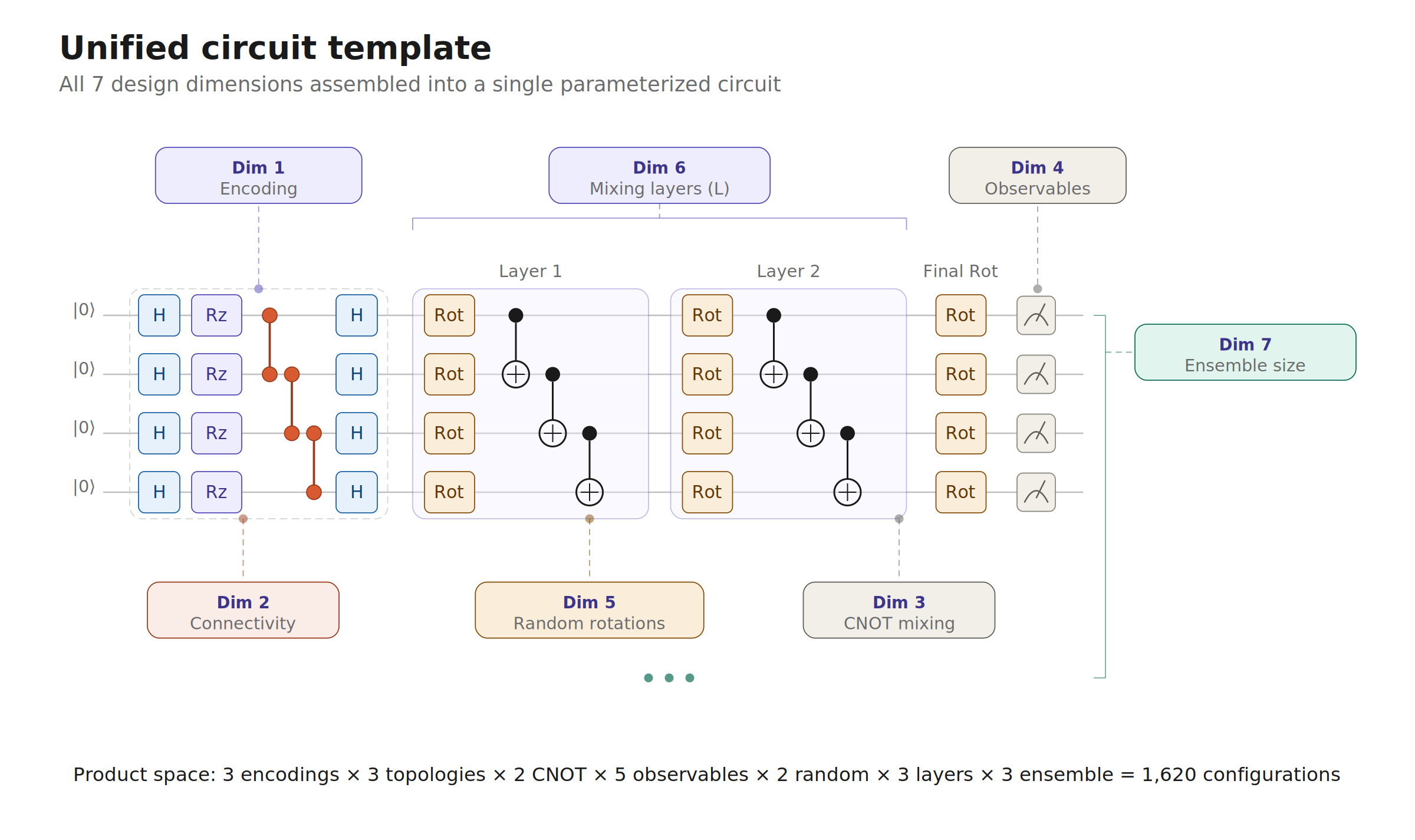
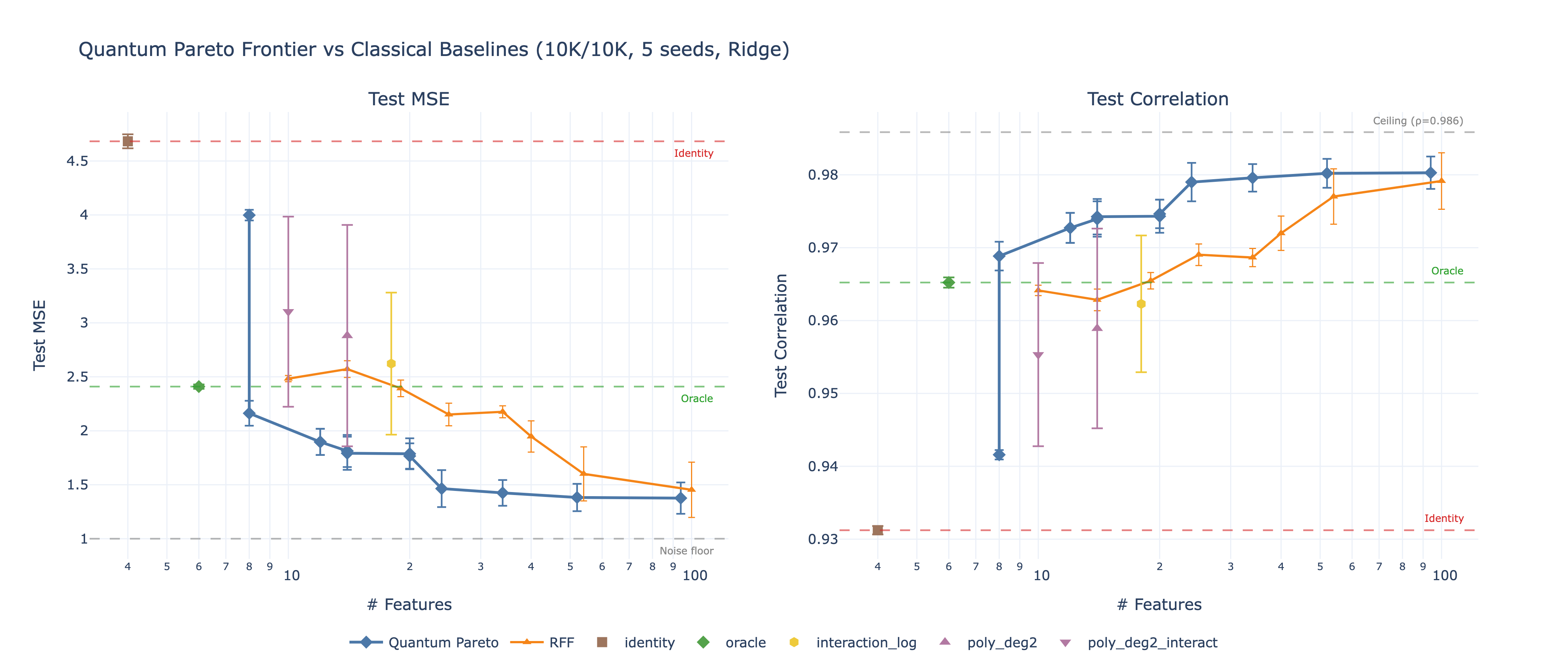
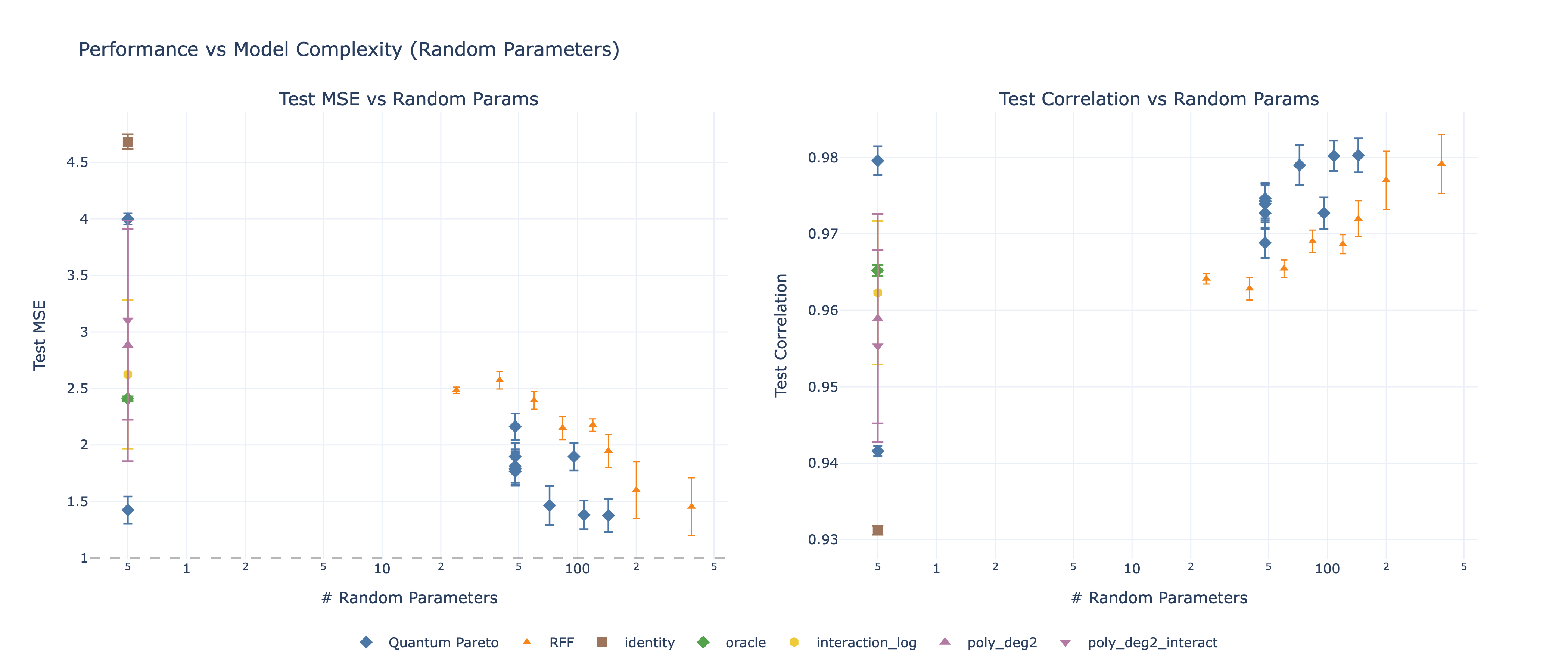
We decompose quantum feature maps into 7 independent design dimensions (encoding, connectivity, entanglement, measurement, randomization, depth, ensemble size), sweep all 1,620 combinations on a regime-switching financial prediction task, and identify the Pareto frontier of MSE vs feature complexity. The winning quantum reservoir strategy beats the best classical baseline (Random Fourier Features) by 5% with lower cross-seed variance and zero trainable parameters.
How we built it
We built a modular experiment framework (src/synthetic/) with pluggable augmenters, consistent fairness controls (shared scaler, identical train/test splits, CV-tuned regularization), and multiprocessing for parallelism. The unified quantum augmenter (quantum_unified.py) parameterizes all 7 dimensions in a single class, enabling clean factorial analysis. We evaluated 8,100+ runs (1,620 configs × 5 seeds) on the synthetic DGP, plus 13 classical baselines on full 10K data, tracking 11 complexity metrics per configuration. All results are stored as structured JSON with interactive Plotly visualizations.
Challenges we ran into
- IQP circuits performed no better than identity — we traced this to missing final Hadamards, periodic encoding saturation on Cauchy-distributed inputs, and diagonal circuit structure that prevents amplitude-level entanglement. Fixing all three still left IQP 2× worse than angle encoding.
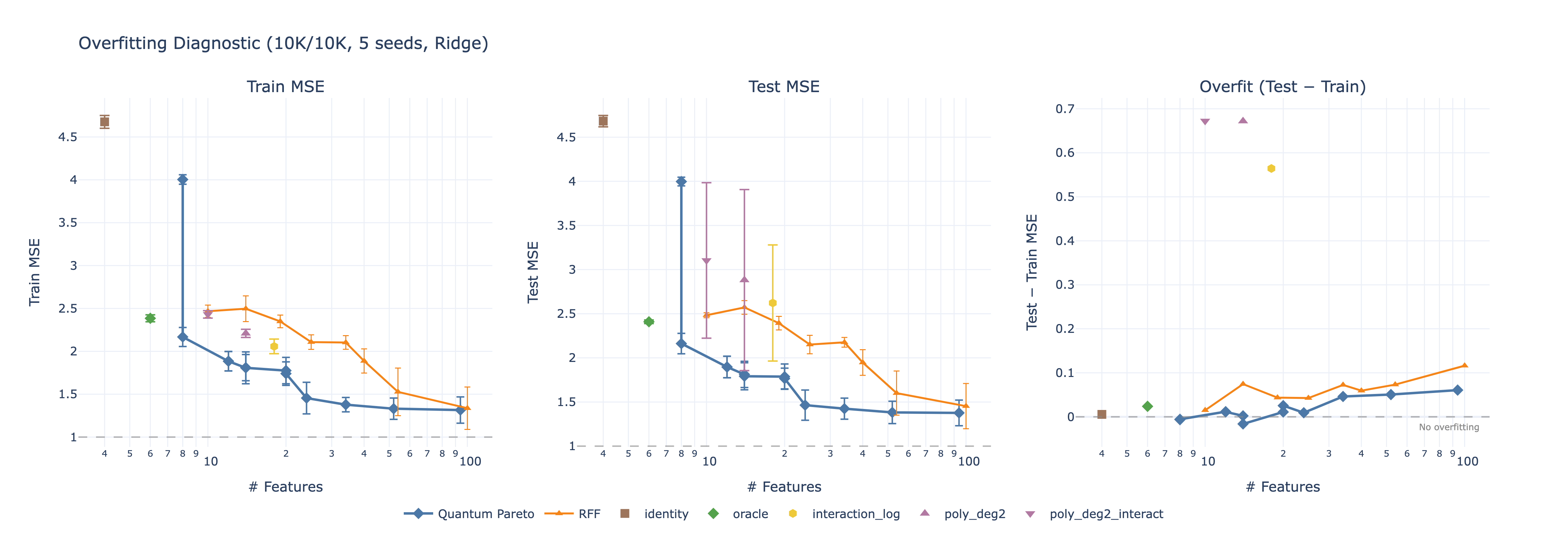
- MLP feature extractors initially overfit catastrophically — full-batch training without learning rate scheduling caused train MSE 2.5 but test MSE 9.0. Adding mini-batching, cosine annealing, early stopping, and weight decay brought test MSE down to 1.17.
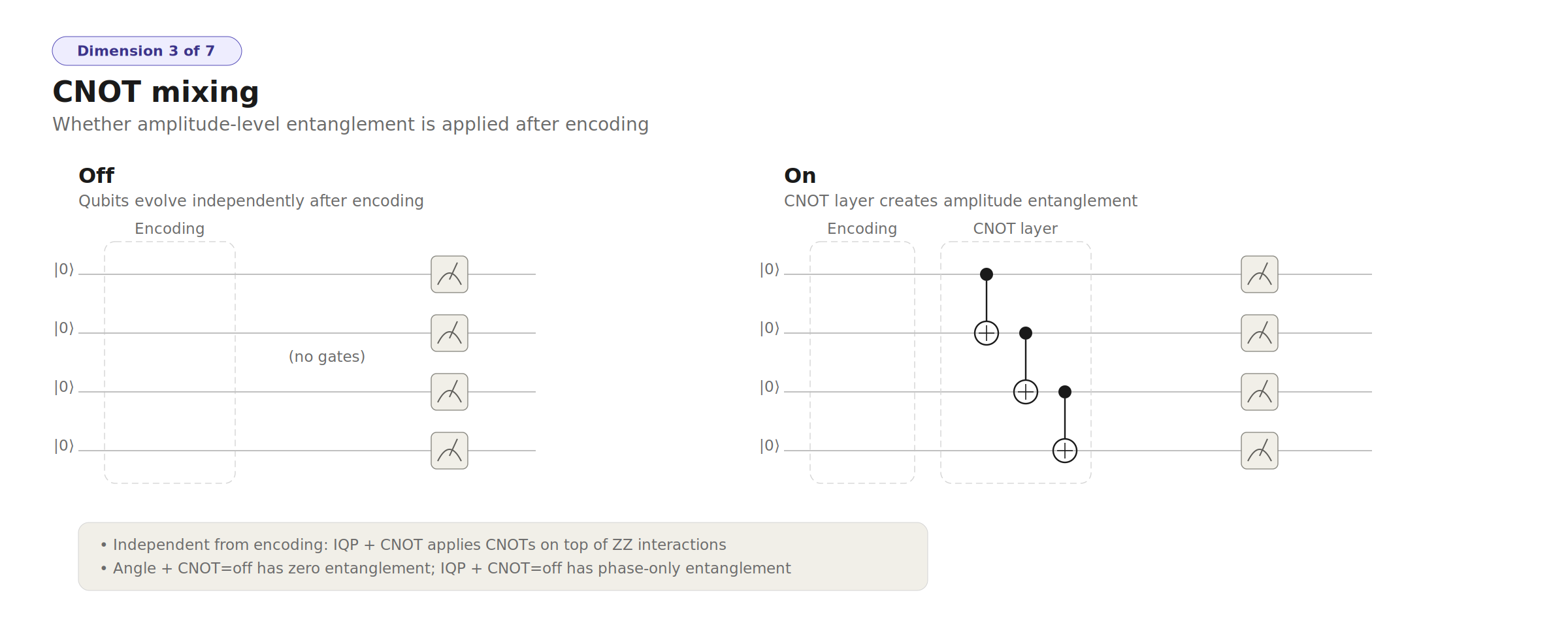
- Bare angle encoding (no post-processing) outperformed angle encoding with StronglyEntanglingLayers — a counterintuitive result showing that random entangling gates can hurt at small qubit counts by destroying clean factorized structure. The ensemble approach (multiple simple circuits) beats one complex circuit.
Accomplishments that we're proud of
- Systematic factorial design covering 1,620 quantum configurations with reproducible, fair comparisons — not cherry-picked circuit architectures
- Quantum reservoir achieves Pareto-optimal MSE at every feature count tested, with 5% improvement over the best classical method and notably lower variance across random seeds
- Per-regime analysis revealing that all methods perform similarly on the linear regime (75% of data) — the quantum advantage concentrates entirely on the nonlinear regime-switching interactions
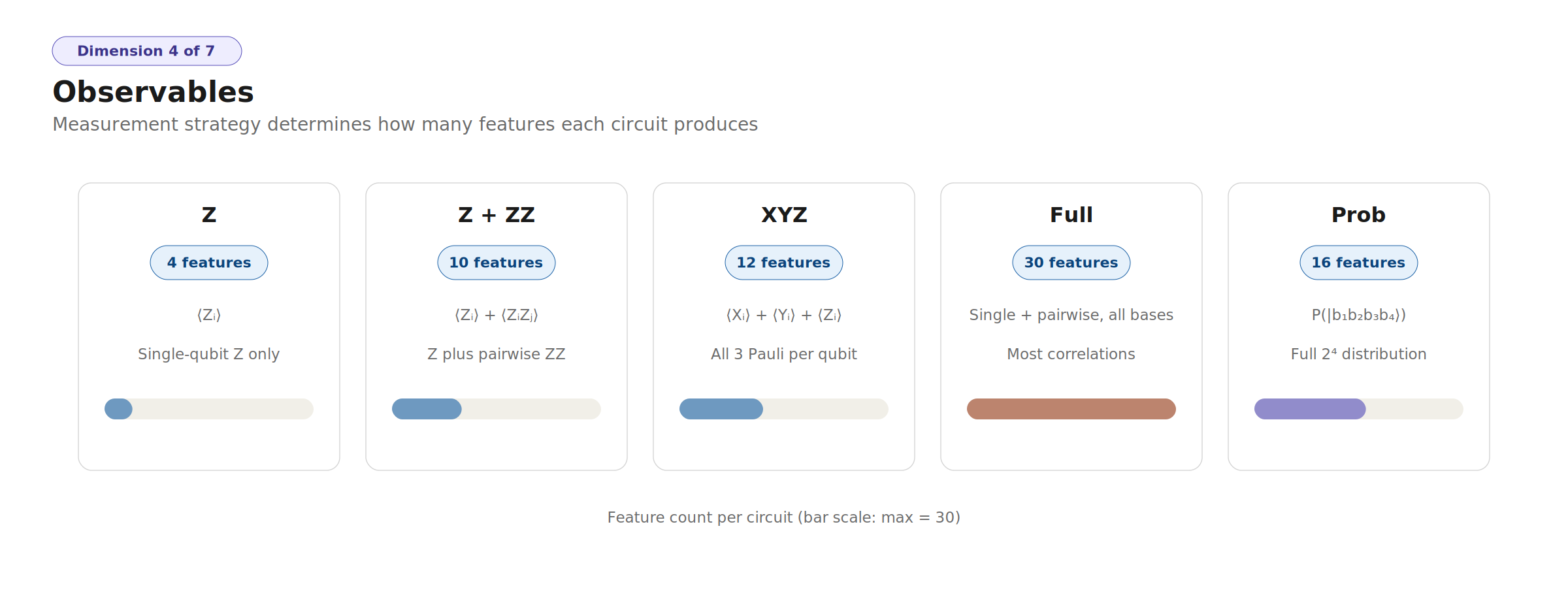
- 11 objective complexity metrics (effective rank, nonlinearity score, feature-target alignment, parameter counts, generalization gap) enabling fair comparison without subjective tier assignments
- Standalone quantum reservoir script (
scripts/quantum_reservoir.py) ready for integration with any sklearn pipeline
What we learned
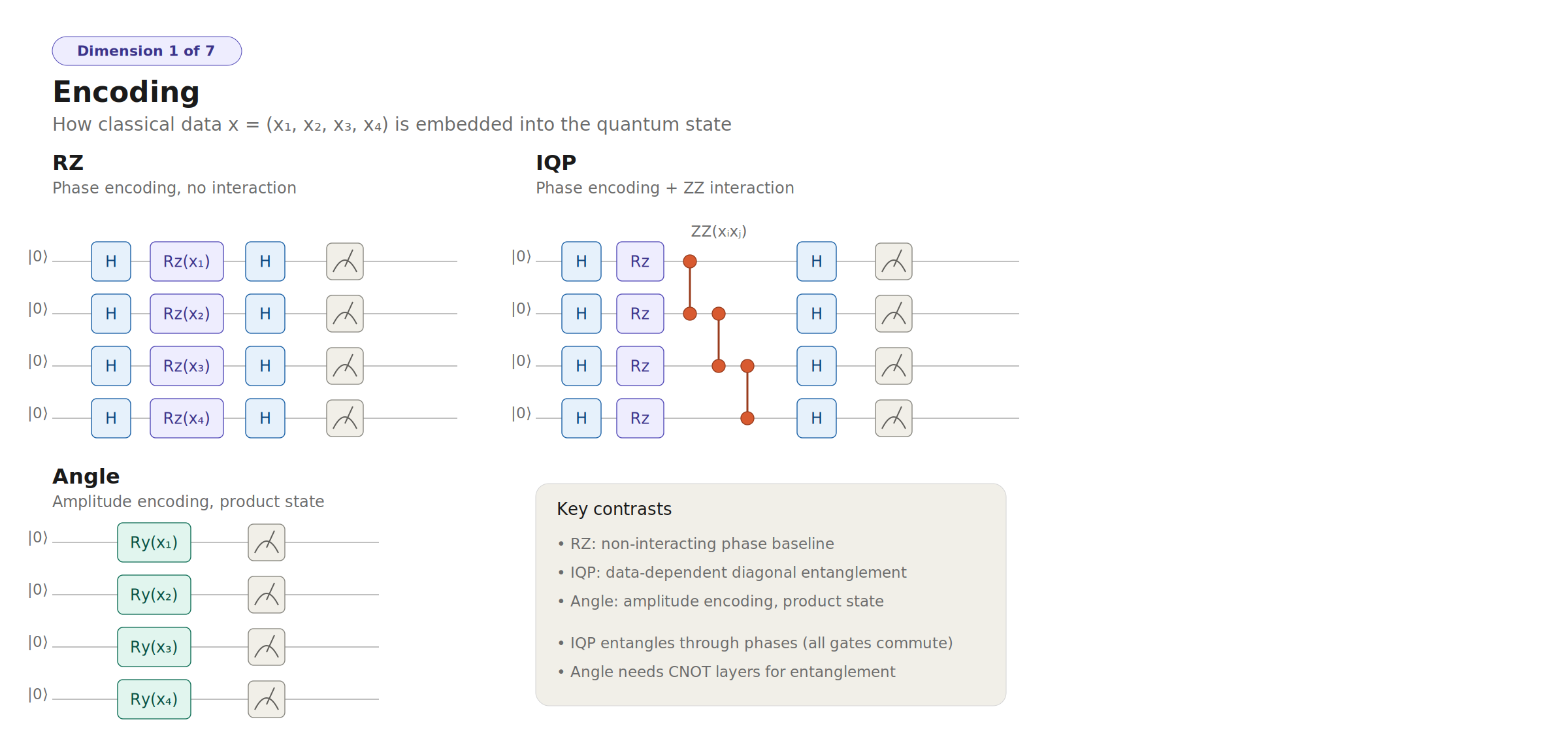
- The encoding axis matters less than randomization — RZ and angle encoding achieve nearly identical performance when both have random post-encoding layers. The critical factor is breaking the periodicity of deterministic encodings.
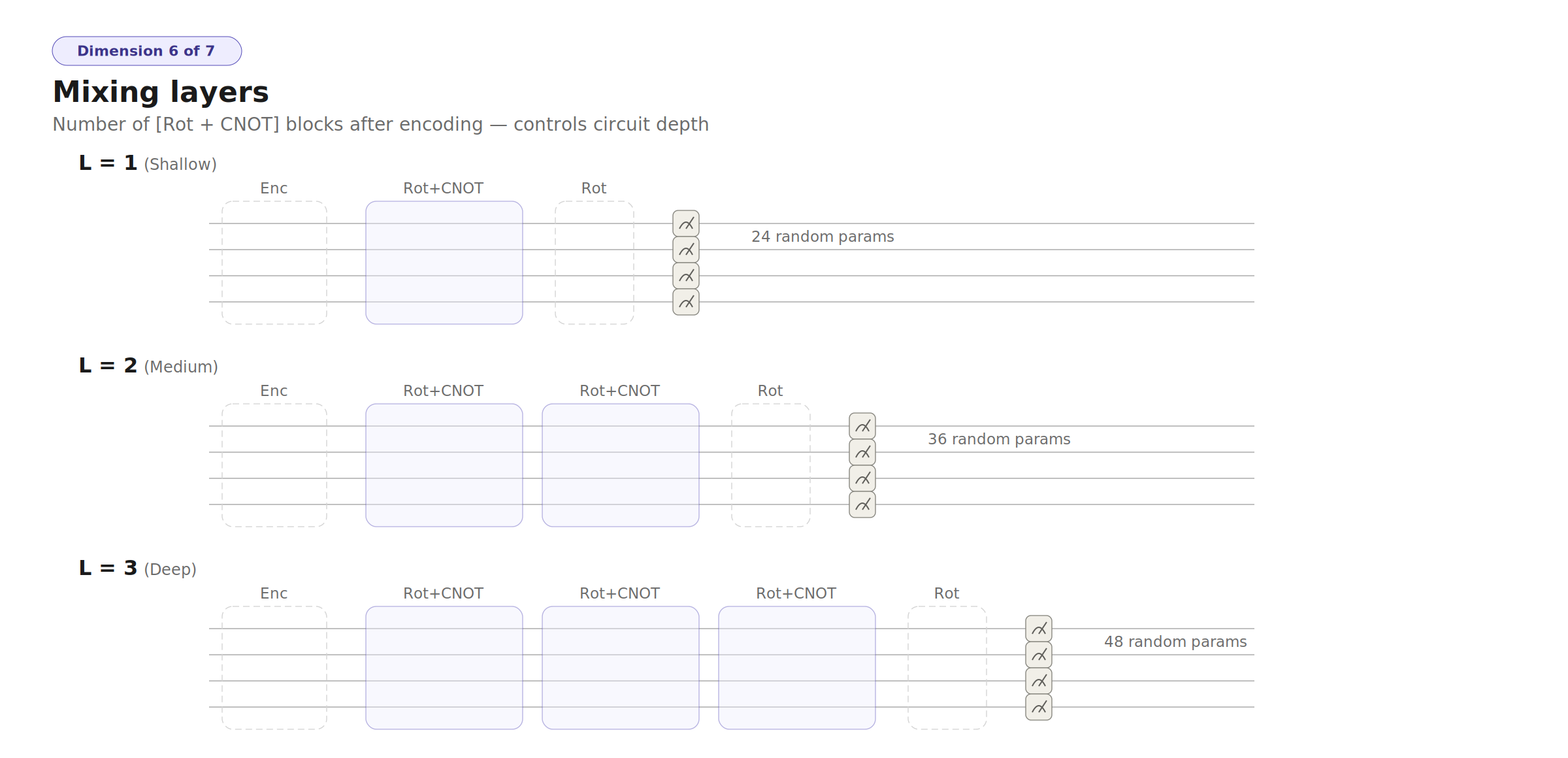
- Ensemble diversity beats circuit depth — 3 shallow circuits (1 layer each) outperform 1 deep circuit (3 layers) at the same total parameter count. The quantum advantage comes from diverse random projections, not from any single circuit's expressiveness.
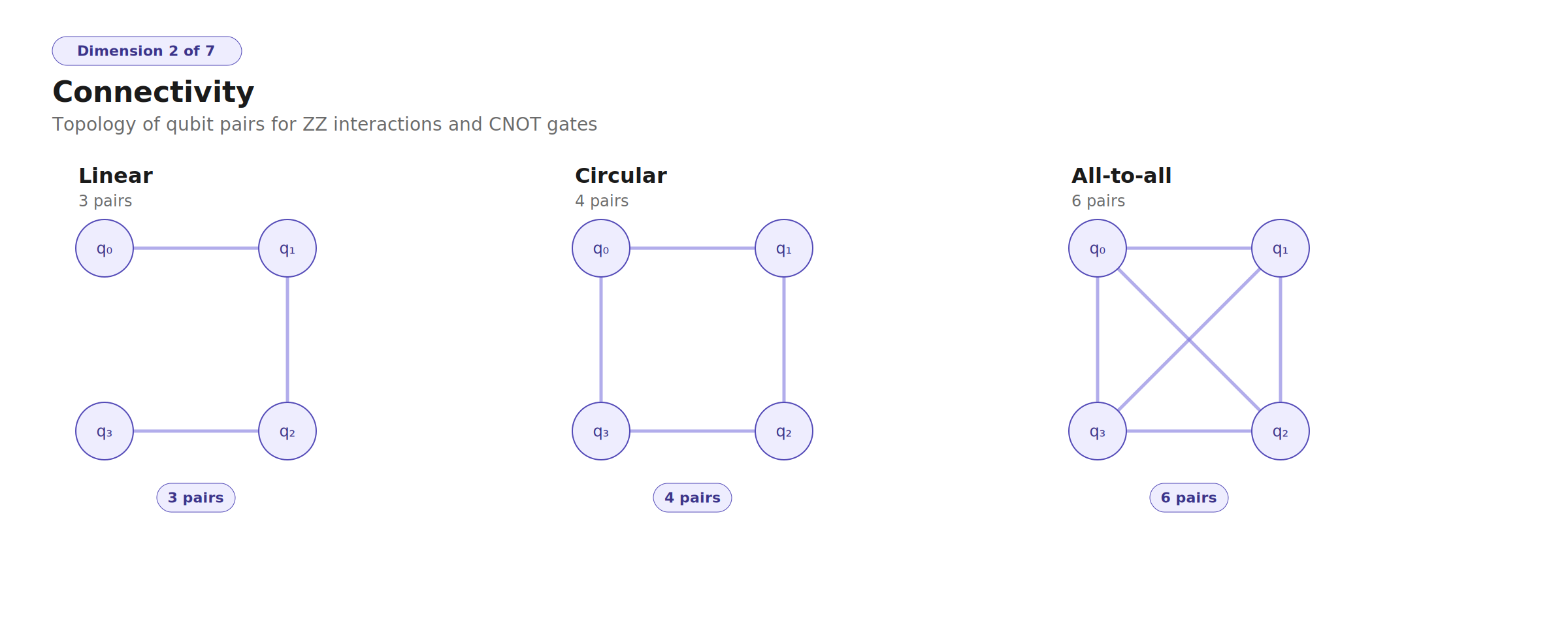
- Entanglement topology barely matters — linear, circular, and all-to-all CNOT patterns give <5% MSE difference. The simplest topology (linear) is sufficient and most hardware-friendly.
- IQP's diagonal structure is fundamentally limited for this class of problems — phase-only entanglement (MultiRZ) cannot create the amplitude correlations that CNOT + random Rot gates produce.
- Classical RFF is a strong competitor — it uses the same random-projection principle as quantum reservoir, just through cosine functions instead of quantum circuits. The quantum advantage is real but modest (~5%).
What's next for Pareto-Optimal Quantum Feature Augmentation
- Real financial data: apply the quantum reservoir to the S&P 500 excess return prediction task with walk-forward backtesting — the second part of the challenge
- Trainable quantum circuits: use the factorial analysis to initialize VQC training from the best static configuration, potentially closing the gap with trained classical methods (MLP achieved MSE 1.17)
- Hardware execution: run the Pareto-optimal circuits on AWS Braket QPU hardware to measure real quantum resource costs (gate fidelity, shot noise, queue time) and compare with simulator results
- Scaling to more qubits: the 5-qubit and 6-qubit reservoir results suggest richer Hilbert spaces help — test 8–12 qubits where classical simulation becomes expensive but quantum hardware is native
Built With
- pennylane
- python

Log in or sign up for Devpost to join the conversation.